【PHP数据结构】图的存储结构
图的概念介绍得差不多了,大家可以消化消化再继续学习后面的内容。如果没有什么问题的话,我们就继续学习接下来的内容。当然,这还不是最麻烦的地方,因为今天我们只是介绍图的存储结构而已。
图的顺序存储结构:邻接矩阵
什么是邻接矩阵
首先还是来看看如何用顺序结构来存储图。不管是栈、队列、树,我们都可以使用一个简单的数组就可以实现这些数据结构的顺序存储能力。但是图就不一样了,从上篇文章中,我们学到过,一个结点的表示是 <x, y> 这种形式。如果我们把这个结点相像是一个坐标轴上的点,那么我们是不是就可以用一个二维数组来表示它呢?没错,让二维数组的第一维表示为 x 轴,第二维表示为 y 轴,这样我们就可以构建出一张图来了。没错,二维数组这种形式还有一个别名就叫做:矩阵。
在图的术语中,使用二维数组来表示的图的顺序存储结构就叫做邻接矩阵。就像下面这个表格一样。
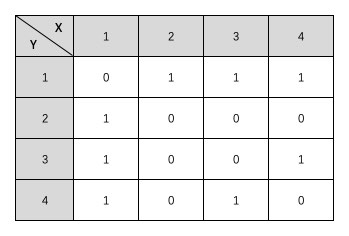
在这个表格中,我们有横竖两个坐标,X1-4 和 Y1-4 表示这个图中一共有 4 个结点,通过它们的对应关系就可以看做是一个结点与另一个结点之间是否有边。比如说 X1 和 Y2 这一对坐标 <X1, Y2> ,它们的值是 1 ,这就说明 结点1 到 结点2 之间有一条边。在这里,我们使用的是无权图,也就是用 0 表示没有边,用 1 表示两个结点之间有边。同时,它还是一张无向图,所以 <Y2, X1> 的值也是 1 ,它的意图是从 结点2 到 结点1 之间也有一条边。如果是有向图,那么就要根据有向箭头的指向来确定这条边是否设置为 1 。
上面的这个邻接矩阵对应的图是什么样子的呢?大家可以自己尝试手动画一画。画不出来也不要紧,因为我们才刚开始学嘛。其实它就是我们最开始展示的那张图的邻接矩阵。
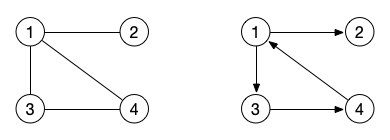
左边的图就是对应的我们上面的那个表格中的邻接矩阵。那么右边那个有向图的邻接矩阵是什么样子的呢?我们也写写试试。
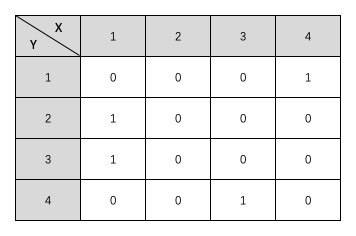
有意思吧?那么如果是有权图呢?其实很简单的我们将图中的 1 直接换成对应边的权值就可以了,不过有可能有的边的权值就是 0 ,所以在有权图中,我们可以定义一个非常大的数,或者定义一个非常小的负数当做 无限数 来表示这两个结点没有边。
构造邻接矩阵
接下来,我们就通过代码来构造这样一个邻接矩阵的存储结构。我们还是用无向图的例子来实现。因为无向图是需要反向的结点也赋值的,所以它比有向图多了一个步骤,其它的基本上都是相似的。
// 邻接矩阵
$graphArr = [];
function CreateGraph($Nv, &$graphArr)
{
$graphArr = [];
for ($i = 1; $i <= $Nv; $i++) {
for ($j = 1; $j <= $Nv; $j++) {
$graphArr[$i][$j] = 0;
}
}
}
// 邻接矩阵
function BuildGraph(&$graphArr)
{
echo '请输入结点数:';
fscanf(STDIN, "%d", $Nv);
CreateGraph($Nv, $graphArr);
if ($graphArr) {
echo '请输入边数:';
fscanf(STDIN, "%d", $Ne);
if ($Ne > 0) {
for ($i = 1; $i <= $Ne; $i++) {
echo '请输入边,格式为 出 入 权:';
fscanf(STDIN, "%d %d %d", $v1, $v2, $weight);
$graphArr[$v1][$v2] = $weight;
// 如果是无向图,还需要插入逆向的边
$graphArr[$v2][$v1] = $weight;
}
}
}
}
在这段代码中,首先我们通过 CreateGraph() 方法来初始化一个二维矩阵。也就是根据我们输入的结点数量,实现一个 X * Y 的二维数组结构,并且定义它的所有值都是 0 ,也就是说,这个图目前还没有边。
然后,在 BuildGraph() 方法调用完 CreateGraph() 之后,我们继续输入边的信息。先输入边的数量,我们有几条边,如果边小于等于 0 的话就不要继续创建了。其实还可以严谨一点根据 无向完全图和有向完全图 的定义来让边不能超过最大的限度。
接下来,我们就循环继续输入边的信息,这里我需要的输入格式是边的 出结点 、入结点 、权值。由于我们的示例是无向图,所以我们除了要为 <x, y> 创建边之外,也要为 <y, x> 创建边。代码的注释中已经说明了。
解释代码可能还是比较抽象。直接运行一下试试吧。
BuildGraph($graphArr);
// 请输入结点数:4
// 请输入边数:4
// 请输入边,格式为 出 入 权:1 2 1
// 请输入边,格式为 出 入 权:1 3 1
// 请输入边,格式为 出 入 权:1 4 1
// 请输入边,格式为 出 入 权:3 4 1
print_r($graphArr);
// Array
// (
// [1] => Array
// (
// [1] => 0
// [2] => 1
// [3] => 1
// [4] => 1
// )
// [2] => Array
// (
// [1] => 1
// [2] => 0
// [3] => 0
// [4] => 0
// )
// [3] => Array
// (
// [1] => 1
// [2] => 0
// [3] => 0
// [4] => 1
// )
// [4] => Array
// (
// [1] => 1
// [2] => 0
// [3] => 1
// [4] => 0
// )
// )
// x
//y 0 1 1 1
// 1 0 0 0
// 1 0 0 1
// 1 0 1 0
在命令行环境中调用我们的 PHP 文件,然后根据提示的内容依次输入相关的信息。最后打印出来的数组内容是不是就和我们上面的表格中一模一样了。简简单单的一段代码,我们就实现了图的顺序存储。
可能有的同学会一时懵圈。因为我第一眼看到的时候也是完全懵了,不过仔细的对比画出来的图和上面的表格其实马上就能想明白了。这次我们真的是进入二维的世界了。是不是感觉图瞬间就把树甩到十万八千里之外了。完全二叉树的时候,我们的思想是二维的,但结构还是一维的,而到邻接矩阵的时候,不管是思想还是代码结构,全部都进化到了二维空间,高大上真不是吹的。
图的链式存储结构:邻接表
说完顺序存储结构,自然不能忽视另一种形式的存储结构,那就是图的链式存储结构。其实对于图来说,链式结构非常简单和清晰,因为我们只需要知道一个结点和那些结点有边就行了。那么我们就让这个结点形成一个单链表,一路往后链接就好了,就像下图这样。(同样以上图无向图为例)
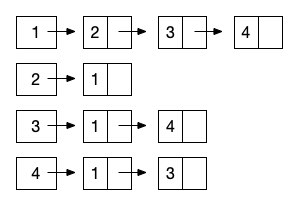
从 结点1 开始,它指向一个后继是 结点2 ,然后继续向后链接 结点3 和 结点4 。这样,与 结点1 相关的边就都描述完成了。由于我们展示的依然是无向图的邻接表表示,所以 结点2 的链表结点指向了 结点 1 。也就是完成了 <y, x> 的反向指向。
对于代码实现来说,我们可以将头结点,也就是正式的 1-4 结点保存在一个顺序表中。然后让每个数组元素的值为第一个结点的内容。这样,我们就可以让链表结点只保存结点名称、权重和下一个结点对象的指向信息就可以了。
// 头结点
class AdjList
{
public $adjList = []; // 顶点列表
public $Nv = 0; // 结点数
public $Ne = 0; // 边数
}
// 边结点
class ArcNode
{
public $adjVex = 0; // 结点
public $nextArc = null; // 链接指向
public $weight = 0; // 权重
}
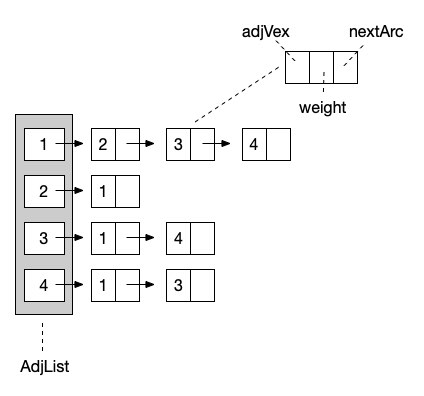
接下来,我们来看看如何使用邻接表这种结构来建立图。
function BuildLinkGraph()
{
fscanf(STDIN, "请输入 结点数 边数:%d %d", $Nv, $Ne);
if ($Nv > 1) {
// 初始化头结点
$adj = new AdjList();
$adj->Nv = $Nv; // 保存下来方便使用
$adj->Ne = $Ne; // 保存下来方便使用
// 头结点列表
for ($i = 1; $i <= $Nv; $i++) {
$adj->adjList[$i] = null; // 全部置为 NULL ,一个无边空图
}
if ($Ne > 0) {
//
for ($i = 1; $i <= $Ne; $i++) {
echo '请输入边,格式为 出 入 权:';
fscanf(STDIN, "%d %d %d", $v1, $v2, $weight);
// 建立一个结点
$p1 = new ArcNode;
$p1->adjVex = $v2; // 结点名称为 入结点
$p1->nextArc = $adj->adjList[$v1]; // 下一跳指向 出结点 的头结点
$p1->weight = $weight; // 设置权重
$adj->adjList[$v1] = $p1; // 让头结点的值等于当前新创建的这个结点
// 无向图需要下面的操作,也就是反向的链表也要建立
$p2 = new ArcNode;
// 注意下面两行与上面代码的区别
$p2->adjVex = $v1; // 这里是入结点
$p2->nextArc = $adj->adjList[$v2]; // 这里是出结点
$p2->weight = $weight;
$adj->adjList[$v2] = $p2;
}
return $adj;
}
}
return null;
}
代码中的注释已经写得很清楚了。可以看出,在邻接表的操作中,无向图也是一样的比有向图多一步操作的,如果只是建立有向图的话,可以不需要 p2 结点的操作。特别需要注意的就是,在这段代码中,我们使用的是链表操作中的 头插法 。也就是最后一条数据会插入到 头结点 上,而最早的那个边会在链表的最后。大家看一下最后建立完成的数据结构的输出就明白了。
print_r(BuildLinkGraph());
// AdjList Object
// (
// [adjList] => Array
// (
// [1] => ArcNode Object
// (
// [adjVex] => 4
// [nextArc] => ArcNode Object
// (
// [adjVex] => 3
// [nextArc] => ArcNode Object
// (
// [adjVex] => 2
// [nextArc] =>
// [weight] => 1
// )
// [weight] => 1
// )
// [weight] => 1
// )
// [2] => ArcNode Object
// (
// [adjVex] => 1
// [nextArc] =>
// [weight] => 1
// )
// [3] => ArcNode Object
// (
// [adjVex] => 4
// [nextArc] => ArcNode Object
// (
// [adjVex] => 1
// [nextArc] =>
// [weight] => 1
// )
// [weight] => 1
// )
// [4] => ArcNode Object
// (
// [adjVex] => 3
// [nextArc] => ArcNode Object
// (
// [adjVex] => 1
// [nextArc] =>
// [weight] => 1
// )
// [weight] => 1
// )
// )
// [Nv] => 4
// [Ne] => 4
// )
使用邻接表来建立的图的链式存储结构是不是反而比邻接矩阵更加的清晰明了一些。就像树的链式和顺序结构一样,在图中它们的优缺点也是类似的。邻接矩阵占用的物理空间更多,因为它需要两层一样多元素的数组,就像上面的表格一样,需要占据 4 * 4 的物理格子。而邻接表我们可以直接数它的结点数,只需要 12 个格子就完成了。而且,更主要的是,链式的邻接表可以随时扩展边结点和边数,不需要重新地初始化,我们只需要简单地修改上面的测试代码就能够实现,而邻接矩阵如果要修改结点数的话,就得要重新初始化整个二维数组了。
总结
对于图来说,除了邻接矩阵和邻接表之外,还有其它的一些存储形式,不过都是链式的邻接表的一些优化和变形而已。大家有兴趣的可以自己去了解一下 十字链表 、邻接多重表 这两种存储结构。
好了,基础的存储结构已经铺垫完了,关于图的概念也都熟悉掌握了,接下来,我们就要准备去做最重要的操作了,那就是如何来对图进行遍历。
测试代码:
https://github.com/zhangyue0503/Data-structure-and-algorithm/blob/master/5.图/source/5.2图的存储结构.php
参考资料:
《数据结构》第二版,严蔚敏
《数据结构》第二版,陈越
《数据结构高分笔记》2020版,天勤考研
关注公众号:【硬核项目经理】获取最新文章
添加微信/QQ好友:【xiaoyuezigonggong/149844827】免费得PHP、项目管理学习资料
知乎、公众号、抖音、头条搜索【硬核项目经理】
B站ID:482780532
【PHP数据结构】图的存储结构的更多相关文章
- 图的存储结构大赏------数据结构C语言(图)
图的存储结构大赏------数据结构C语言(图) 本次所讲的是常有的四种结构: 邻接矩阵 邻接表 十字链表 邻接多重表 邻接矩阵 概念 两个数组,一个表示顶点的信息,一个用来表示关联的关系. 如果是无 ...
- 图的存储结构(邻接矩阵与邻接表)及其C++实现
一.图的定义 图是由顶点的有穷非空集合和顶点之间边的集合组成,通常表示为: G=(V,E) 其中:G表示一个图,V是图G中顶点的集合,E是图G中顶点之间边的集合. 注: 在线性表中,元素个数可以为零, ...
- C++编程练习(9)----“图的存储结构以及图的遍历“(邻接矩阵、深度优先遍历、广度优先遍历)
图的存储结构 1)邻接矩阵 用两个数组来表示图,一个一维数组存储图中顶点信息,一个二维数组(邻接矩阵)存储图中边或弧的信息. 2)邻接表 3)十字链表 4)邻接多重表 5)边集数组 本文只用代码实现用 ...
- K:图的存储结构
常用的图的存储结构主要有两种,一种是采用数组链表(邻接表)的方式,一种是采用邻接矩阵的方式.当然,图也可以采用十字链表或者边集数组的方式来进行表示,但由于不常用,为此,本博文不对其进行介绍. 邻接 ...
- 【algo&ds】6.图及其存储结构、遍历
1.什么是图 图表示"多对多"的关系 包含 一组顶点:通常用 V(Vertex)表示顶点集合 一组边:通常用 E(Edge)表示边的集合 边是顶点对:(v,w)∈ E,其中 v,w ...
- js数据结构与算法存储结构
数据结构(程序设计=数据结构+算法) 数据结构就是关系,没错,就是数据元素相互之间存在的一种或多种特定关系的集合. 传统上,我们把数据结构分为逻辑结构和物理结构. 逻辑结构:是指数据对象中数据元素之间 ...
- 图的存储结构与操作--C语言实现
图(graph)是一种比树结构还要复杂的数据结构,它的术语,存储方式,遍历方式,用途都比较广,所以如果想要一次性完成所有的代码,那代码会非常长.所以,我将分两次来完成图的代码.这一次,我会完成图的五种 ...
- 图的存储结构:邻接矩阵(邻接表)&链式前向星
[概念]疏松图&稠密图: 疏松图指,点连接的边不多的图,反之(点连接的边多)则为稠密图. Tips:邻接矩阵与邻接表相比,疏松图多用邻接表,稠密图多用邻接矩阵. 邻接矩阵: 开一个二维数组gr ...
- 图的存储结构的实现(C/C++实现)
存档: #include <stdio.h> #include <stdlib.h> #define maxv 10 #define max 10 typedef char e ...
随机推荐
- Vue系列-03-vue-cli自动化工具
使用Vue-CLI创建项目 安装vue-cli脚手架 Mac安装vue-cli脚手架 lichengguo@lichengguodeMacBook-Pro ~ % sudo npm install - ...
- SIM900A—基础指令
文章目录 1.ATE指令设置回显 2.ATQ指令设置返回 3.ATV指令设置返回格式 4.AT+CFUN设置模块功能 5.AT+IPR设置波特率 6.AT+CMEE设置上报错误格式 7.各种码(IME ...
- SSM自学笔记(三)
5.Spring JdbcTemplate 1.Spring JdbcTemplate基本使用 1.1 JdbcTemplate概述 它是spring框架中提供的一个对象,是对原始繁琐的Jdbc AP ...
- 【spring 注解驱动开发】spring组件注册
尚学堂spring 注解驱动开发学习笔记之 - 组件注册 组件注册 1.@Configuration&@Bean给容器中注册组件 2.@ComponentScan-自动扫描组件&指定扫 ...
- 【小技巧】排名前 16 的 Java 工具类!
转自java技术栈: https://mp.weixin.qq.com/s?__biz=MzI3ODcxMzQzMw==&mid=2247485460&idx=1&sn=cef ...
- 【转】Linux tar命令详解
参考:https://blog.csdn.net/kkw1992/article/details/80000653 linux下最常用的打包程序就是tar了,使用tar程序打出来的包我们常称为tar包 ...
- 一:Tomcat安装、配置和部署笔记
Tomcat安装(绿色版安装) 1.将下载的Tomcat解压到指定目录,如:D:\WorkSpaceByJava\DevtTools\Apache-Tomcat-8.0.23 2.Tomcat的目录结 ...
- Supervisor服务开机自启动
要解决的问题 在机器上部署自己编写的服务时候,我们可以使用Supervisor作为进程检活工具,用来自动重启服务. 但是当机器重启后,Supervisor却不能自动重启,那么谁来解决这个问题呢? 答案 ...
- 运行uni-app到微信开发者工具
1.工具及环境 HBuilder X 微信开发者工具 Node.js,测试:node -v(node安装) 和 npm -v(自带的npm也安装成功) 2.创建uni-app项目: 在点击工具栏里的文 ...
- 剑指 Offer 32 - III. 从上到下打印二叉树 III
剑指 Offer 32 - III. 从上到下打印二叉树 III 请实现一个函数按照之字形顺序打印二叉树,即第一行按照从左到右的顺序打印,第二层按照从右到左的顺序打印,第三行再按照从左到右的顺序打印, ...