1. flink 基础
flink word count 程序
1. 数据集模式
pom.xml 文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>deng.com</groupId>
<artifactId>flink_demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.10.1</version>
</dependency> </dependencies> </project>
wordCount 程序
package com.deng;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector; public class WordCount {
public static void main(String[] args) throws Exception {
// 创建执行环境
ExecutionEnvironment env =ExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(8);
// 从文件中读取数据
String inputPath="C:\\Users\\侠客云\\IdeaProjects\\flink_demo\\src\\main\\resources\\hello.txt";
DataSet<String> inputDataSet = env.readTextFile(inputPath);
// 对数据集进行处理,按空格分词展开,转换成(word,1)二元组
DataSet<Tuple2<String,Integer>> resultSets= inputDataSet.flatMap(new MyFlatMaper())
.groupBy(0)//按照第一个位置word 进行分组
.sum(1) //按照 第二个位置上的数据求和
;
resultSets.print();
}
// 自定义类,实现 FlatMapFunction 接口
public static class MyFlatMaper implements FlatMapFunction<String, Tuple2<String,Integer>>{
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
// 按空格分词
String[] words=s.split(" ");
// 遍历所有word,包成二元组
for (String word : words) {
collector.collect(new Tuple2<>(word,1));
}
}
} }
2 流式数据集模式
StreamWordCount 程序
package com.deng;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class StreamWordCount {
public static void main(String[] args) throws Exception {
// 1.创建流处理执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(8);
// 2.
// 从文件中读取数据
// String inputPath="C:\\Users\\侠客云\\IdeaProjects\\flink_demo\\src\\main\\resources\\hello.txt";
// DataStream<String> inPutDataStream = env.readTextFile(inputPath);
// 用parameter tool 从程序启动参数中获取配置项
ParameterTool parameterTool = ParameterTool.fromArgs(args);
String host = parameterTool.get("host");
int port = parameterTool.getInt("port");
// 从socket文件流中获取数据
// DataStream<String> inPutDataStream =env.socketTextStream("hadoop102",7777);
DataStream<String> inPutDataStream =env.socketTextStream(host,port);
DataStream<Tuple2<String, Integer>> resultStream = inPutDataStream.flatMap(new MyFlatMaper())
.keyBy(0)
.sum(1);
resultStream.print();
// 执行任务
env.execute();
}
// 自定义类,实现 FlatMapFunction 接口
public static class MyFlatMaper implements FlatMapFunction<String, Tuple2<String,Integer>> {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
// 按空格分词
String[] words=s.split(" ");
// 遍历所有word,包成二元组
for (String word : words) {
collector.collect(new Tuple2<>(word,1));
}
}
}
}
测试环境中执行程序传参代码时,如何运行:
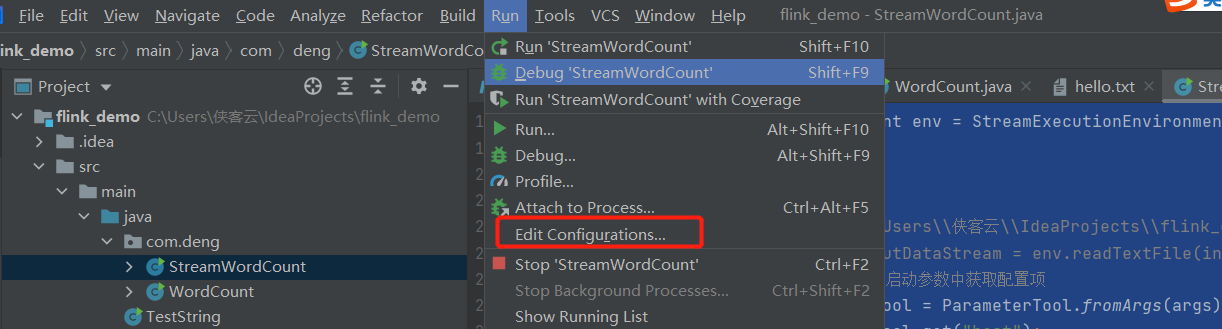
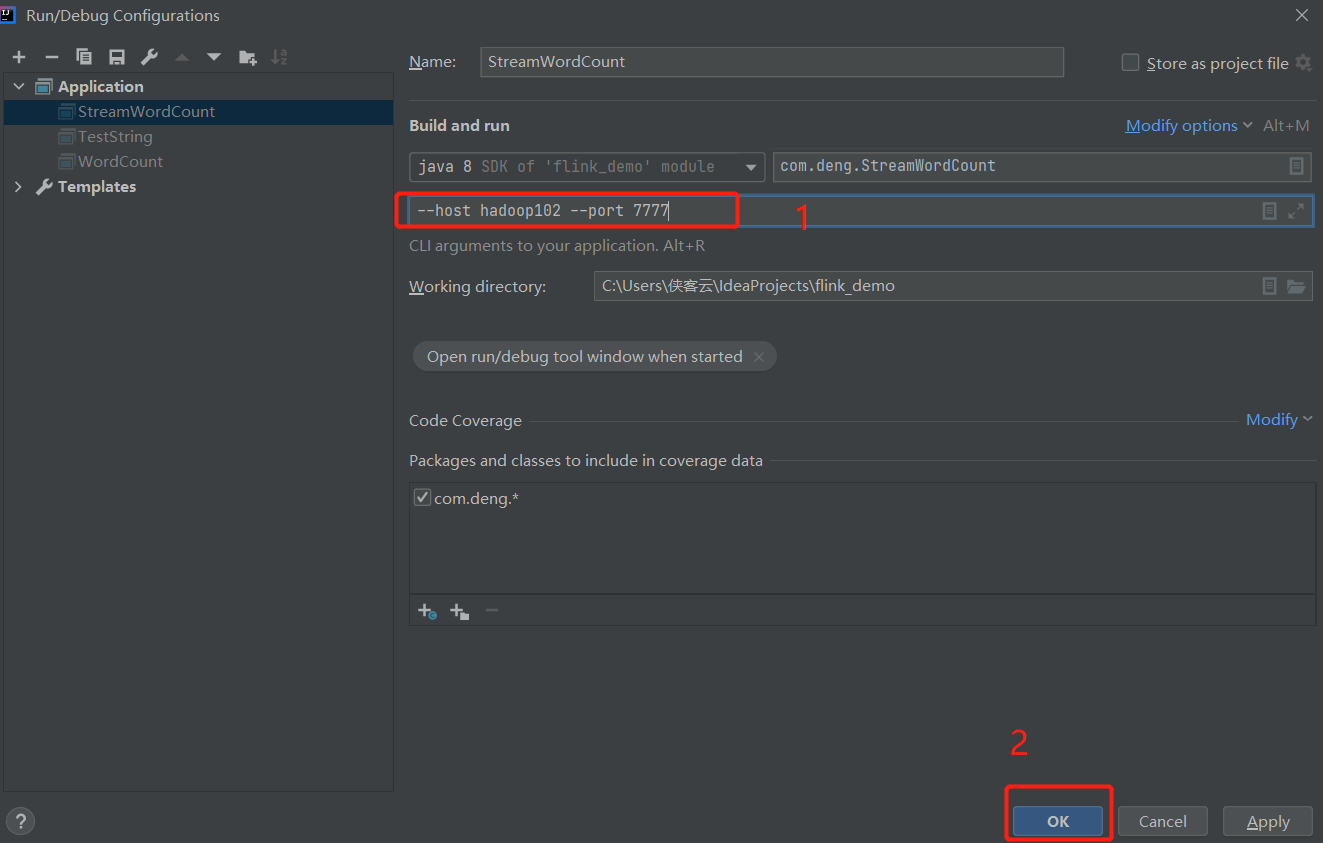
3. 从集合中获取数据
package com.deng.sourceTest;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class SourceTestCollection { public static void main(String[] args) throws Exception { // 获取流执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置并行度
env.setParallelism(4);
//
DataStream<Integer> integerDataStream= env.fromElements(1, 2, 34, 52, 16700);
integerDataStream.print("int=》"); env.execute("deng_flink_job"); }
}
4. 从kafka 获取数据
添加依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>deng.com</groupId>
<artifactId>flink_demo</artifactId>
<version>1.0-SNAPSHOT</version> <properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties> <dependencies> <dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.10.1</version>
</dependency> <dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.12</artifactId>
<version>0.11.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.12</artifactId>
<version>1.10.1</version>
</dependency> </dependencies> </project>
相关代码:
package com.deng.sourceTest; import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011;
import org.apache.kafka.clients.consumer.ConsumerConfig; import java.util.Properties; public class SourceKafkaTest {
public static void main(String[] args) throws Exception {
// 1. 获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2.可以设置并行度
env.setParallelism(1);
// kafka 配置
Properties prop = new Properties();
prop.setProperty("bootstrap.servers","hadoop102:9092");
prop.setProperty("group.id","deng");
// 2. 开启自动提交
prop.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,true);
// 3. 自动提交延时 1s
prop.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,1000);
// 4. KEY, VAULE 反序列化
prop.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
prop.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer"); prop.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");
DataStreamSource<String> dataStream = env.addSource(new FlinkKafkaConsumer011<String>("first", new SimpleStringSchema(), prop));
dataStream.print();
env.execute("deng_flink_job");
}
}
5. 自定义SourceFunction
package com.deng.flink; import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction; import java.util.HashMap;
import java.util.Random; class SensorReading {
private String key;
private Double temp;
private Long t; public SensorReading(String k, Long time, Double tp) {
key =k;
temp=tp;
t=time;
} @Override
public String toString() {
return "SensorReading{" +
"key='" + key + '\'' +
", temp=" + temp +
", t=" + t +
'}';
}
} public class SourceTestUDF {
public static void main(String[] args) throws Exception { // 1. 获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2.可以设置并行度
env.setParallelism(1);
DataStreamSource<SensorReading> sensorReadingDataStreamSource = env.addSource(new MySensorSource());
sensorReadingDataStreamSource.print();
env.execute();
} // 自定义SourceFunction
public static class MySensorSource implements SourceFunction<SensorReading> {
// 定义一个标志位
private boolean running = true; @Override
public void run(SourceContext<SensorReading> ctx) throws Exception {
// 定义一个随机数发生器
Random random = new Random();
// 设置10个传感器的初始温度
HashMap<String, Double> sensorTempMap = new HashMap<>();
for (int i = 0; i < 10; ++i) {
sensorTempMap.put("sensor_" + i, 60 + random.nextGaussian() * 20);
}
while (running) {
for (String key : sensorTempMap.keySet()) {
//当前温度基础上随机波动
Double nextTemp = sensorTempMap.get(key) + random.nextGaussian();
sensorTempMap.put(key, nextTemp);
ctx.collect(new SensorReading(key, System.currentTimeMillis(), nextTemp)); }
// 控制输出频率
Thread.sleep(1000L); }
} @Override
public void cancel() {
running = false;
}
} }
1. flink 基础的更多相关文章
- Flink资料(1)-- Flink基础概念(Basic Concept)
Flink基础概念 本文描述Flink的基础概念,翻译自https://ci.apache.org/projects/flink/flink-docs-release-1.0/concepts/con ...
- Flink基础:实时处理管道与ETL
往期推荐: Flink基础:入门介绍 Flink基础:DataStream API Flink深入浅出:资源管理 Flink深入浅出:部署模式 Flink深入浅出:内存模型 Flink深入浅出:J ...
- Flink基础:时间和水印
往期推荐: Flink基础:入门介绍 Flink基础:DataStream API Flink基础:实时处理管道与ETL Flink深入浅出:资源管理 Flink深入浅出:部署模式 Flink深入 ...
- Flink入门-第一篇:Flink基础概念以及竞品对比
Flink入门-第一篇:Flink基础概念以及竞品对比 Flink介绍 截止2021年10月Flink最新的稳定版本已经发展到1.14.0 Flink起源于一个名为Stratosphere的研究项目主 ...
- flink基础篇
Flink面试--核心概念和基础考察 1.简单介绍一下 Flink 2.Flink 相比传统的 Spark Streaming 有什么区别? 3.Flink 的组件栈有哪些? 面试知识 ...
- flink基础教程读书笔记
数据架构设计领域发生了重大的变化,基于流的处理是变化的核心. 分布式文件系统用来存储不经常更新的数据,他们也是大规模批量计算所以来的数据存储方式. 批处理架构(lambda架构)实现计数的方式:持续摄 ...
- 【Flink】Flink基础之WordCount实例(Java与Scala版本)
简述 WordCount(单词计数)作为大数据体系的标准示例,一直是入门的经典案例,下面用java和scala实现Flink的WordCount代码: 采用IDEA + Maven + Flink 环 ...
- Flink基础
一.抽象层次 Flink提供不同级别的抽象来开发流/批处理应用程序. 最低级抽象只提供有状态流.它 通过Process Function嵌入到DataStream API中.它允许用户自由处理来自 ...
- Flink基础概念入门
Flink 概述 什么是 Flink Apache Apache Flink 是一个开源的流处理框架,应用于分布式.高性能.高可用的数据流应用程序.可以处理有限数据流和无限数据,即能够处理有边界和无边 ...
随机推荐
- 【LeetCode】102. Binary Tree Level Order Traversal 二叉树的层序遍历 (Python&C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客:http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 BFS DFS 日期 题目地址:https://lee ...
- C. Watching Fireworks is Fun(Codeforces 372C)
C. Watching Fireworks is Fun time limit per test 4 seconds memory limit per test 256 megabytes input ...
- CRB and His Birthday(hdu 5410)
CRB and His Birthday Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Oth ...
- CoGAN
目录 概 主要内容 代码 Liu M., Tuzel O. Coupled Generative Adversarial Networks. NIPS, 2016. 概 用GAN和数据(从边缘分布中采 ...
- 编写Java程序,将JButton按钮按网格布局管理器格式放置
返回本章节 返回作业目录 需求说明: 将JButton按钮按网格布局管理器格式放置 实现思路: 实现代码: public void init(){ setLayout(new GridLayout(4 ...
- 编写Java程序,利用List维护用户信息
返回本章节 返回作业目录 需求说明: 将新增的用户信息添加到List集合. 用户信息包括用户编号.姓名和性别. 按照姓名和性别查找用户信息. 实现思路: 创建类UserInfo,在该类中定义3个Str ...
- Linux下如何部署FTP服务器
FTP 是 File Transfer Protocol 的缩写,即文件传输协议,它通过网络在服务器和客户端之间传输文件,现在已经成为一种广泛使用的标准工具 vsftpd 是 very secure ...
- 利用js 引用的方式 鼠标经过弹出效果
js引用的是此网站代码: https://www.cnblogs.com/jq-growup/p/15609469.html <!DOCTYPE html> <html lang=& ...
- IdentityServer4 综合应用实战系列 (一)登录
这篇文章主要说登录,这里抛开IdentityServer4的各种模式,这里只说登录 我们要分别实现 4中登录方式来说明, IdentityServer4本地登陆 . Windows账户登录(本地的电 ...
- Hadoop HA(高可用) 详细安装步骤
什么是HA? HA是High Availability的简写,即高可用,指当当前工作中的机器宕机后,会自动处理这个异常,并将工作无缝地转移到其他备用机器上去,以来保证服务的高可用.(简言之,有两台机器 ...