编程艺术第十六~第二十章:全排列/跳台阶/奇偶调序,及一致性Hash算法
第十六~第二十章:全排列,跳台阶,奇偶排序,第一个只出现一次等问题
作者:July、2011.10.16。
出处:http://blog.csdn.net/v_JULY_v。
引言
最近这几天闲职在家,一忙着投简历,二为准备面试而搜集整理各种面试题。故常常关注个人所建的Algorithms1-14群内朋友关于笔试,面试,宣讲会,offer,薪资的讨论以及在群内发布的各种笔/面试题,常感言道:咱们这群人之前已经在学校受够了学校的那种应试教育,如今出来找工作又得东奔西走去参加各种笔试/面试,着实亦不轻松。幻想,如果在企业与求职者之间有个中间面试服务平台就更好了。
ok,闲话少扯。在上一篇文章中,已经说过,“个人正在针对那100题一题一题的写文章,多种思路,不断优化,即成程序员编程艺术系列。”现本编程艺术系列继续开始创作,你而后自会和我有同样的感慨:各种面试题千变万化,层出不穷,但基本类型,解决问题的思路基本一致。
本文为程序员编程艺术第十六章~第二十章,包含以下5个问题:
- 全排列;
- 跳台阶;
- 奇偶排序;
- 第一个只出现一次的字符;
- 一致性哈希算法。
同时,本文会在解答去年微软面试100题的部分题目时,尽量结合今年最近各大IT公司最新的面试题来讲解,两相对比,彼此对照,相信你会更加赞同我上面的话。且本文也不奢望读者能从中学到什么高深技术之类的东西,只求读者看此文看着舒服便可,通顺流畅以致一口气读完而无任何压力。ok,有任何问题,欢迎不吝指正。谢谢。
第十六章、全排列问题
53.字符串的排列。
题目:输入一个字符串,打印出该字符串中字符的所有排列。
例如输入字符串abc,则输出由字符a、b、c 所能排列出来的所有字符串
abc、acb、bac、bca、cab 和cba。
分析:此题最初整理于去年的微软面试100题中第53题,第二次整理于微软、Google等公司非常好的面试题及解答[第61-70题] 第67题。无独有偶,这个问题今年又出现于今年的2011.10.09百度笔试题中。ok,接下来,咱们先好好分析这个问题。
- 一、递归实现
从集合中依次选出每一个元素,作为排列的第一个元素,然后对剩余的元素进行全排列,如此递归处理,从而得到所有元素的全排列。以对字符串abc进行全排列为例,我们可以这么做:以abc为例
固定a,求后面bc的排列:abc,acb,求好后,a和b交换,得到bac
固定b,求后面ac的排列:bac,bca,求好后,c放到第一位置,得到cba
固定c,求后面ba的排列:cba,cab。代码可如下编写所示:
- template <typename T>
- void CalcAllPermutation_R(T perm[], int first, int num)
- {
- if (num <= 1) {
- return;
- }
- for (int i = first; i < first + num; ++i) {
- swap(perm[i], perm[first]);
- CalcAllPermutation_R(perm, first + 1, num - 1);
- swap(perm[i], perm[first]);
- }
- }
或者如此编写,亦可:
- void Permutation(char* pStr, char* pBegin);
- void Permutation(char* pStr)
- {
- Permutation(pStr, pStr);
- }
- void Permutation(char* pStr, char* pBegin)
- {
- if(!pStr || !pBegin)
- return;
- if(*pBegin == '\0')
- {
- printf("%s\n", pStr);
- }
- else
- {
- for(char* pCh = pBegin; *pCh != '\0'; ++ pCh)
- {
- // swap pCh and pBegin
- char temp = *pCh;
- *pCh = *pBegin;
- *pBegin = temp;
- Permutation(pStr, pBegin + 1);
- // restore pCh and pBegin
- temp = *pCh;
- *pCh = *pBegin;
- *pBegin = temp;
- }
- }
- }
- 二、字典序排列
把升序的排列(当然,也可以实现为降序)作为当前排列开始,然后依次计算当前排列的下一个字典序排列。
对当前排列从后向前扫描,找到一对为升序的相邻元素,记为i和j(i < j)。如果不存在这样一对为升序的相邻元素,则所有排列均已找到,算法结束;否则,重新对当前排列从后向前扫描,找到第一个大于i的元素k,交换i和k,然后对从j开始到结束的子序列反转,则此时得到的新排列就为下一个字典序排列。这种方式实现得到的所有排列是按字典序有序的,这也是C++ STL算法next_permutation的思想。算法实现如下:
- template <typename T>
- void CalcAllPermutation(T perm[], int num)
- {
- if (num < 1)
- return;
- while (true) {
- int i;
- for (i = num - 2; i >= 0; --i) {
- if (perm[i] < perm[i + 1])
- break;
- }
- if (i < 0)
- break; // 已经找到所有排列
- int k;
- for (k = num - 1; k > i; --k) {
- if (perm[k] > perm[i])
- break;
- }
- swap(perm[i], perm[k]);
- reverse(perm + i + 1, perm + num);
- }
- }
第十七章、跳台阶问题
27.跳台阶问题
题目:一个台阶总共有n 级,如果一次可以跳1 级,也可以跳2 级。
求总共有多少总跳法,并分析算法的时间复杂度。
分析:在九月腾讯,创新工场,淘宝等公司最新面试十三题中第23题又出现了这个问题,题目描述如下:23、人人笔试1:一个人上台阶可以一次上1个,2个,或者3个,问这个人上n层的台阶,总共有几种走法?咱们先撇开这个人人笔试的问题(其实差别就在于人人笔试题中多了一次可以跳三级的情况而已),先来看这个第27题。
首先考虑最简单的情况。如果只有1级台阶,那显然只有一种跳法。如果有2级台阶,那就有两种跳的方法了:一种是分两次跳,每次跳1级;另外一种就是一次跳2级。
现在我们再来讨论一般情况。我们把n级台阶时的跳法看成是n的函数,记为f(n)。当n>2时,第一次跳的时候就有两种不同的选择:一是第一次只跳1级,此时跳法数目等于后面剩下的n-1级台阶的跳法数目,即为f(n-1);另外一种选择是第一次跳2级,此时跳法数目等于后面剩下的n-2级台阶的跳法数目,即为f(n-2)。因此n级台阶时的不同跳法的总数f(n)=f(n-1)+(f-2)。
我们把上面的分析用一个公式总结如下:
/ 1 n=1
f(n)= 2 n=2
\ f(n-1) + f(n-2) n>2
原来上述问题就是我们平常所熟知的Fibonacci数列问题。可编写代码,如下:
- long long Fibonacci_Solution1(unsigned int n)
- {
- int result[2] = {0, 1};
- if(n < 2)
- return result[n];
- return Fibonacci_Solution1(n - 1) + Fibonacci_Solution1(n - 2);
- }
那么,如果是人人笔试那道题呢?一个人上台阶可以一次上1个,2个,或者3个,岂不是可以轻而易举的写下如下公式:
/ 1 n=1
f(n)= 2 n=2
4 n=3 //111, 12, 21, 3
\ f(n-1)+(f-2)+f(n-3) n>3
行文至此,你可能会认为问题已经解决了,但事实上没有:
- 用递归方法计算的时间复杂度是以n的指数的方式递增的,我们可以尝试用递推方法解决。具体如何操作,读者自行思考。
- 有一种方法,能在O(logn)的时间复杂度内求解Fibonacci数列问题,你能想到么?
- 同时,有朋友指出对于这个台阶问题只需求幂就可以了(求复数幂C++库里有),不用任何循环且复杂度为O(1),如下图所示,是否真如此?:

第十八章、奇偶调序
题目:输入一个整数数组,调整数组中数字的顺序,使得所有奇数位于数组的前半部分,
所有偶数位于数组的后半部分。要求时间复杂度为O(n)。
分析:
- 你当然可以从头扫描这个数组,每碰到一个偶数时,拿出这个数字,并把位于这个数字后面的所有数字往前挪动一位。挪完之后在数组的末尾有一个空位,这时把该偶数放入这个空位。由于碰到一个偶数,需要移动O(n)个数字,只是这种方法总的时间复杂度是O(n2),不符合要求,pass。
- 很简单,维护两个指针,一个指针指向数组的第一个数字,向后移动;一个个指针指向最后一个数字,向前移动。如果第一个指针指向的数字是偶数而第二个指针指向的数字是奇数,我们就交换这两个数字。
- //思路,很简答,俩指针,一首一尾
- //如果第一个指针指向的数字是偶数而第二个指针指向的数字是奇数,
- //我们就交换这两个数字
- // 2 1 3 4 6 5 7
- // 7 1 3 4 6 5 2
- // 7 1 3 5 6 4 2
- //如果限制空间复杂度为O(1),时间为O(N),且奇偶数之间相对顺序不变,就相当于正负数间顺序调整的那道题了。
- //copyright@2010 zhedahht。
- void Reorder(int *pData, unsigned int length, bool (*func)(int));
- bool isEven(int n);
- void ReorderOddEven(int *pData, unsigned int length)
- {
- if(pData == NULL || length == 0)
- return;
- Reorder(pData, length, isEven);
- }
- void Reorder(int *pData, unsigned int length, bool (*func)(int))
- {
- if(pData == NULL || length == 0)
- return;
- int *pBegin = pData;
- int *pEnd = pData + length - 1;
- while(pBegin < pEnd)
- {
- // if *pBegin does not satisfy func, move forward
- if(!func(*pBegin)) //偶数
- {
- pBegin ++;
- continue;
- }
- // if *pEnd does not satisfy func, move backward
- if(func(*pEnd)) //奇数
- {
- pEnd --;
- continue;
- }
- // if *pBegin satisfy func while *pEnd does not,
- // swap these integers
- int temp = *pBegin;
- *pBegin = *pEnd;
- *pEnd = temp;
- }
- }
- bool isEven(int n)
- {
- return (n & 1) == 0;
- }
第十九章、第一个只出现一次的字符
代码,可编写如下:
- #include <iostream>
- using namespace std;
- //查找第一个只出现一次的字符,第1个程序
- //copyright@ Sorehead && July
- //July、updated,2011.04.24.
- char find_first_unique_char(char *str)
- {
- int data[256];
- char *p;
- if (str == NULL)
- return '\0';
- memset(data, 0, sizeof(data)); //数组元素先全部初始化为0
- p = str;
- while (*p != '\0')
- data[(unsigned char)*p++]++; //遍历字符串,在相应位置++,(同时,下标强制转换)
- while (*str != '\0')
- {
- if (data[(unsigned char)*str] == 1) //最后,输出那个第一个只出现次数为1的字符
- return *str;
- str++;
- }
- return '\0';
- }
- int main()
- {
- char *str = "afaccde";
- cout << find_first_unique_char(str) << endl;
- return 0;
- }
当然,代码也可以这么写(测试正确):
- //查找第一个只出现一次的字符,第2个程序
- //copyright@ yansha
- //July、updated,2011.04.24.
- char FirstNotRepeatChar(char* pString)
- {
- if(!pString)
- return '\0';
- const int tableSize = 256;
- int hashTable[tableSize] = {0}; //存入数组,并初始化为0
- char* pHashKey = pString;
- while(*(pHashKey) != '\0')
- hashTable[*(pHashKey++)]++;
- while(*pString != '\0')
- {
- if(hashTable[*pString] == 1)
- return *pString;
- pString++;
- }
- return '\0'; //没有找到满足条件的字符,退出
- }
第二十章、一致性哈希算法
tencent2012笔试题附加题
问题描述: 例如手机朋友网有n个服务器,为了方便用户的访问会在服务器上缓存数据,因此用户每次访问的时候最好能保持同一台服务器。
已有的做法是根据ServerIPIndex[QQNUM%n]得到请求的服务器,这种方法很方便将用户分到不同的服务器上去。但是如果一台服务器死掉了,那么n就变为了n-1,那么ServerIPIndex[QQNUM%n]与ServerIPIndex[QQNUM%(n-1)]基本上都不一样了,所以大多数用户的请求都会转到其他服务器,这样会发生大量访问错误。
问: 如何改进或者换一种方法,使得:
(1)一台服务器死掉后,不会造成大面积的访问错误,
(2)原有的访问基本还是停留在同一台服务器上;
(3)尽量考虑负载均衡。(思路:往分布式一致哈希算法方面考虑。)
- 最土的办法还是用模余方法:做法很简单,假设有N台服务器,现在完好的是M(M<=N),先用N求模,如果不落在完好的机器上,然后再用N-1求模,直到M.这种方式对于坏的机器不多的情况下,具有更好的稳定性。
- 一致性哈希算法。
下面,本文剩下部分重点来讲讲这个一致性哈希算法。
应用场景
在做服务器负载均衡时候可供选择的负载均衡的算法有很多,包括: 轮循算法(Round Robin)、哈希算法(HASH)、最少连接算法(Least Connection)、响应速度算法(Response Time)、加权法(Weighted )等。其中哈希算法是最为常用的算法.
典型的应用场景是: 有N台服务器提供缓存服务,需要对服务器进行负载均衡,将请求平均分发到每台服务器上,每台机器负责1/N的服务。
常用的算法是对hash结果取余数 (hash() mod N):对机器编号从0到N-1,按照自定义的hash()算法,对每个请求的hash()值按N取模,得到余数i,然后将请求分发到编号为i的机器。但这样的算法方法存在致命问题,如果某一台机器宕机,那么应该落在该机器的请求就无法得到正确的处理,这时需要将当掉的服务器从算法从去除,此时候会有(N-1)/N的服务器的缓存数据需要重新进行计算;如果新增一台机器,会有N /(N+1)的服务器的缓存数据需要进行重新计算。对于系统而言,这通常是不可接受的颠簸(因为这意味着大量缓存的失效或者数据需要转移)。那么,如何设计一个负载均衡策略,使得受到影响的请求尽可能的少呢?
在Memcached、Key-Value Store、Bittorrent DHT、LVS中都采用了Consistent Hashing算法,可以说Consistent Hashing 是分布式系统负载均衡的首选算法。
Consistent Hashing算法描述
下面以Memcached中的Consisten Hashing算法为例说明。
consistent hashing 算法早在 1997 年就在论文 Consistent hashing and random trees 中被提出,目前在 cache 系统中应用越来越广泛;
1 基本场景
比如你有 N 个 cache 服务器(后面简称 cache ),那么如何将一个对象 object 映射到 N 个 cache 上呢,你很可能会采用类似下面的通用方法计算 object 的 hash 值,然后均匀的映射到到 N 个 cache ;
hash(object)%N
一切都运行正常,再考虑如下的两种情况;
- 一个 cache 服务器 m down 掉了(在实际应用中必须要考虑这种情况),这样所有映射到 cache m 的对象都会失效,怎么办,需要把 cache m 从 cache 中移除,这时候 cache 是 N-1 台,映射公式变成了 hash(object)%(N-1) ;
- 由于访问加重,需要添加 cache ,这时候 cache 是 N+1 台,映射公式变成了 hash(object)%(N+1) ;
1 和 2 意味着什么?这意味着突然之间几乎所有的 cache 都失效了。对于服务器而言,这是一场灾难,洪水般的访问都会直接冲向后台服务器;再来考虑第三个问题,由于硬件能力越来越强,你可能想让后面添加的节点多做点活,显然上面的 hash 算法也做不到。
有什么方法可以改变这个状况呢,这就是consistent hashing。
2 hash 算法和单调性
Hash 算法的一个衡量指标是单调性( Monotonicity ),定义如下:
单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
容易看到,上面的简单 hash 算法 hash(object)%N 难以满足单调性要求。
3 consistent hashing 算法的原理
consistent hashing 是一种 hash 算法,简单的说,在移除 / 添加一个 cache 时,它能够尽可能小的改变已存在 key 映射关系,尽可能的满足单调性的要求。
下面就来按照 5 个步骤简单讲讲 consistent hashing 算法的基本原理。
3.1 环形hash 空间
考虑通常的 hash 算法都是将 value 映射到一个 32 为的 key 值,也即是 0~2^32-1 次方的数值空间;我们可以将这个空间想象成一个首( 0 )尾( 2^32-1 )相接的圆环,如下面图 1 所示的那样。

图 1 环形 hash 空间
3.2 把对象映射到hash 空间
接下来考虑 4 个对象 object1~object4 ,通过 hash 函数计算出的 hash 值 key 在环上的分布如图 2 所示。
hash(object1) = key1;
… …
hash(object4) = key4;

图 2 4 个对象的 key 值分布
3.3 把cache 映射到hash 空间
Consistent hashing 的基本思想就是将对象和 cache 都映射到同一个 hash 数值空间中,并且使用相同的hash 算法。
假设当前有 A,B 和 C 共 3 台 cache ,那么其映射结果将如图 3 所示,他们在 hash 空间中,以对应的 hash值排列。
hash(cache A) = key A;
… …
hash(cache C) = key C;

图 3 cache 和对象的 key 值分布
说到这里,顺便提一下 cache 的 hash 计算,一般的方法可以使用 cache 机器的 IP 地址或者机器名作为hash 输入。
3.4 把对象映射到cache
现在 cache 和对象都已经通过同一个 hash 算法映射到 hash 数值空间中了,接下来要考虑的就是如何将对象映射到 cache 上面了。
在这个环形空间中,如果沿着顺时针方向从对象的 key 值出发,直到遇见一个 cache ,那么就将该对象存储在这个 cache 上,因为对象和 cache 的 hash 值是固定的,因此这个 cache 必然是唯一和确定的。这样不就找到了对象和 cache 的映射方法了吗?!
依然继续上面的例子(参见图 3 ),那么根据上面的方法,对象 object1 将被存储到 cache A 上; object2和 object3 对应到 cache C ; object4 对应到 cache B ;
3.5 考察cache 的变动
前面讲过,通过 hash 然后求余的方法带来的最大问题就在于不能满足单调性,当 cache 有所变动时,cache 会失效,进而对后台服务器造成巨大的冲击,现在就来分析分析 consistent hashing 算法。
3.5.1 移除 cache
考虑假设 cache B 挂掉了,根据上面讲到的映射方法,这时受影响的将仅是那些沿 cache B 顺时针遍历直到下一个 cache ( cache C )之间的对象,也即是本来映射到 cache B 上的那些对象。
因此这里仅需要变动对象 object4 ,将其重新映射到 cache C 上即可;参见图 4 。

图 4 Cache B 被移除后的 cache 映射
3.5.2 添加 cache
再考虑添加一台新的 cache D 的情况,假设在这个环形 hash 空间中, cache D 被映射在对象 object2 和object3 之间。这时受影响的将仅是那些沿 cache D 逆时针遍历直到下一个 cache ( cache B )之间的对象(它们是也本来映射到 cache C 上对象的一部分),将这些对象重新映射到 cache D 上即可。
因此这里仅需要变动对象 object2 ,将其重新映射到 cache D 上;参见图 5 。

图 5 添加 cache D 后的映射关系
4 虚拟节点
考量 Hash 算法的另一个指标是平衡性 (Balance) ,定义如下:
平衡性
平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。
hash 算法并不是保证绝对的平衡,如果 cache 较少的话,对象并不能被均匀的映射到 cache 上,比如在上面的例子中,仅部署 cache A 和 cache C 的情况下,在 4 个对象中, cache A 仅存储了 object1 ,而 cache C 则存储了 object2 、 object3 和 object4 ;分布是很不均衡的。
为了解决这种情况, consistent hashing 引入了“虚拟节点”的概念,它可以如下定义:
“虚拟节点”( virtual node )是实际节点在 hash 空间的复制品( replica ),一实际个节点对应了若干个“虚拟节点”,这个对应个数也成为“复制个数”,“虚拟节点”在 hash 空间中以 hash 值排列。
仍以仅部署 cache A 和 cache C 的情况为例,在图 4 中我们已经看到, cache 分布并不均匀。现在我们引入虚拟节点,并设置“复制个数”为 2 ,这就意味着一共会存在 4 个“虚拟节点”, cache A1, cache A2 代表了 cache A ; cache C1, cache C2 代表了 cache C ;假设一种比较理想的情况,参见图 6 。

图 6 引入“虚拟节点”后的映射关系
此时,对象到“虚拟节点”的映射关系为:
objec1->cache A2 ; objec2->cache A1 ; objec3->cache C1 ; objec4->cache C2 ;
因此对象 object1 和 object2 都被映射到了 cache A 上,而 object3 和 object4 映射到了 cache C 上;平衡性有了很大提高。
引入“虚拟节点”后,映射关系就从 { 对象 -> 节点 } 转换到了 { 对象 -> 虚拟节点 } 。查询物体所在 cache时的映射关系如图 7 所示。
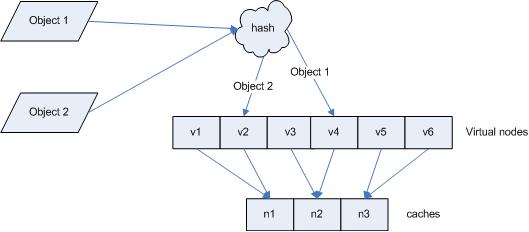
图 7 查询对象所在 cache
“虚拟节点”的 hash 计算可以采用对应节点的 IP 地址加数字后缀的方式。例如假设 cache A 的 IP 地址为202.168.14.241 。
引入“虚拟节点”前,计算 cache A 的 hash 值:
Hash(“202.168.14.241”);
引入“虚拟节点”后,计算“虚拟节”点 cache A1 和 cache A2 的 hash 值:
Hash(“202.168.14.241#1”); // cache A1
Hash(“202.168.14.241#2”); // cache A2
后记
- 以上部分代码思路有参考自此博客:http://zhedahht.blog.163.com/blog/。特此注明下。
- 上文第五部分来源:http://blog.csdn.net/sparkliang/article/details/5279393;
- 行文仓促,若有任何问题或漏洞,欢迎不吝指正或赐教。谢谢。转载,请注明出处。完。
编程艺术第十六~第二十章:全排列/跳台阶/奇偶调序,及一致性Hash算法的更多相关文章
- VS2010/MFC编程入门之三十六(工具栏:工具栏资源及CToolBar类)
上一节中鸡啄米讲了菜单及CMenu类的使用,这一节讲与菜单有密切联系的工具栏. 工具栏简介 工具栏一般位于主框架窗口的上部,菜单栏的下方,由一些带图片的按钮组成.当用户用鼠标单击工具栏上某个按钮时,程 ...
- 《windows核心编程系列》十六谈谈内存映射文件
内存映射文件允许开发人员预订一块地址空间并为该区域调拨物理存储器,与虚拟内存不同的是,内存映射文件的物理存储器来自磁盘中的文件,而非系统的页交换文件.将文件映射到内存中后,我们就可以在内存中操作他们了 ...
- VS2010/MFC编程入门之四十六(MFC常用类:MFC异常处理)
上一节中鸡啄米讲了CFile文件操作类,本节主要来说说MFC异常处理. 在鸡啄米C++编程入门系列的最后一节鸡啄米:C++编程入门系列之五十(异常处理)中,鸡啄米讲了C++标准异常的处理机制,如果你还 ...
- Java编程思想学习(十六) 并发编程
线程是进程中一个任务控制流序列,由于进程的创建和销毁需要销毁大量的资源,而多个线程之间可以共享进程数据,因此多线程是并发编程的基础. 多核心CPU可以真正实现多个任务并行执行,单核心CPU程序其实不是 ...
- JavaScript DOM编程艺术-学习笔记(第十章、第十一章)
第十章 1.动画中,因为js的效率高,所以看不见过渡效果 2.题外话:①国外人写书,总是先感谢一遍亲朋好友,最后感谢自己的家人. 3."除非允许用户'冻结'移动的内容,否则应该避免让内容在页 ...
- C#编程(四十六)----------正则表达式
正则表达式 1.定义一个Regex类的实例 Regex regex=new Regex(“”); 这里初始化参数就是一个正则表达式,”\d”表示配置数字 2.判断是否匹配 判断一个字符串,是否匹配一个 ...
- VS2010/MFC编程入门之十六(对话框:消息对话框)
前面几节鸡啄米讲了属性页对话框,我们可以根据所讲内容方便的建立自己的属性页对话框.本节讲解Windows系统中最常用最简单的一类对话框--消息对话框. 我们在使用Windows系统的过程中经常会见到消 ...
- python编程基础之三十六
文件处理:文件处理包括读文件,写文件 读文件: 1.打开文件 2.读取文件 3.关闭文件 写文件: 1.打开文件 2.写如文件 3.关闭文件 无论是读取文件还是写文件都时需要打开文件,和关闭文件 打开 ...
- MFC编程入门之十六(对话框:消息对话框)
前面几节讲了属性页对话框,我们可以根据所讲内容方便的建立自己的属性页对话框.本节讲解Windows系统中最常用最简单的一类对话框--消息对话框. 我们在使用Windows系统的过程中经常会见到消息对话 ...
随机推荐
- CSP-S 2021 遗言
感谢€€£,谢谢宁嘞! 第一题,€€£给了很多限制条件,什么"先到先得"."只有一个跑道",让它看起来很好做,然后来骗,来偷袭,广大"消费者" ...
- 笔记本加装SSD并装系统
1,首先了解笔记本配置信息 一般加装SSD都是120~256左右,并使用原有的机械硬盘:首先确定加装位置:1,是否支持M.2接口:假如支持,可以直接购买,拆机装上:我的笔记本不支持:所以考虑2,光驱的 ...
- linux shell 提示符
当我们打开或者登陆到一个终端的时候都会显示一长串提示符 void@void-ThinkPad-E450:~$ 提示符一般包含当前登陆的用户名 ,主机名,以及当前工作路径路径,最后都是以 $ 或者 # ...
- insertion-sort-list leetcode C++
Sort a linked list using insertion sort. C++ /** * Definition for singly-linked list. * struct ListN ...
- openstack 虚机热迁移问题:虚机状态一直处于迁移中的情况处理
前提:在偶尔的虚机热迁移中,发现虚机一直属于迁移状态中. 但是查看后台流量监控,发现没有流量已经下来了.然后在目标机器上查看,发现kvm已经在目标机器上. 1.查看kvm 实际所处宿主机方法: a.拿 ...
- Linux下软链接与硬链接的区别
由于下面会说到inode,所以如果没有了解过,请务必搞懂inode的真正含义,厚颜无耻的推荐我的一篇博客:Linux磁盘与文件系统管理 如果我们在系统中新建一个文件,我们看到的文件名实际上只是表面现象 ...
- jacoco-统计代码覆盖率并生成报告
一.概述: 作为一个合格的测试人员,保证产品的软件质量是其工作首要目标,为了这个目标,测试人员常常会通过很多手段或工具来加以保证,覆盖率就是其中一环比较重要的环节. 通常我们会将测试覆盖率分为两个部分 ...
- Jmeter下载安装(一)
一.JMeter介绍 JMeter使用了不同技术和协议,是一款可以进行配置和执行负载测试.性能测试和压力测试的工具.负载测试.性能测试和压力测试概念: 负载测试: 这类测试使系统或者应用程 ...
- LeetCode88 合并有序数组
1. 这道题为简单题目,但是还有需要好好思考的 2. 首先不能使用额外数组合并,不然就没得后文了 3. nums1后面有0填充,且填充数量正好是n,整个数组大小即m+n能够容纳合并后的数据 4.既然要 ...
- springboot入门之版本依赖和自动配置原理
前言 Spring Boot makes it easy to create stand-alone, production-grade Spring based Applications that ...