比物理线程都好用的C++20的协程,你会用吗?
摘要:事件驱动(event driven)是一种常见的代码模型,其通常会有一个主循环(mainloop)不断的从队列中接收事件,然后分发给相应的函数/模块处理。常见使用事件驱动模型的软件包括图形用户界面(GUI),嵌入式设备软件,网络服务端等。
本文分享自华为云社区《C++20的协程在事件驱动代码中的应用》,原文作者:飞得乐 。
嵌入式事件驱动代码的难题
事件驱动(event driven)是一种常见的代码模型,其通常会有一个主循环(mainloop)不断的从队列中接收事件,然后分发给相应的函数/模块处理。常见使用事件驱动模型的软件包括图形用户界面(GUI),嵌入式设备软件,网络服务端等。
本文以一个高度简化的嵌入式处理模块做为事件驱动代码的例子:假设该模块需要处理用户命令、外部消息、告警等各种事件,并在主循环中进行分发,那么示例代码如下:
#include <iostream>
#include <vector> enum class EventType {
COMMAND,
MESSAGE,
ALARM
}; // 仅用于模拟接收的事件序列
std::vector<EventType> g_events{EventType::MESSAGE, EventType::COMMAND, EventType::MESSAGE}; void ProcessCmd()
{
std::cout << "Processing Command" << std::endl;
} void ProcessMsg()
{
std::cout << "Processing Message" << std::endl;
} void ProcessAlm()
{
std::cout << "Processing Alarm" << std::endl;
} int main()
{
for (auto event : g_events) {
switch (event) {
case EventType::COMMAND:
ProcessCmd();
break;
case EventType::MESSAGE:
ProcessMsg();
break;
case EventType::ALARM:
ProcessAlm();
break;
}
}
return 0;
}
这只是一个极简的模型示例,真实的代码要远比它复杂得多,可能还会包含:从特定接口获取事件,解析不同的事件类型,使用表驱动方法进行分发……不过这些和本文关系不大,可暂时先忽略。
用顺序图表示这个模型,大体上是这样:
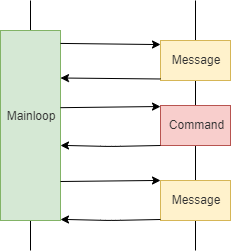
在实际项目中,常常碰到的一个问题是:有些事件的处理时间很长,比如某个命令可能需要批量的进行上千次硬件操作:
void ProcessCmd()
{
for (int i{0}; i < 1000; ++i) {
// 操作硬件接口……
}
}
这种事件处理函数会长时间的阻塞主循环,导致其他事件一直排队等待。如果所有事件对响应速度都没有要求,那也不会造成问题。但是实际场景中经常会有些事件是需要及时响应的,比如某些告警事件出现后,需要很快的执行业务倒换,否则就会给用户造成损失。这个时候,处理时间很长的事件就会产生问题。
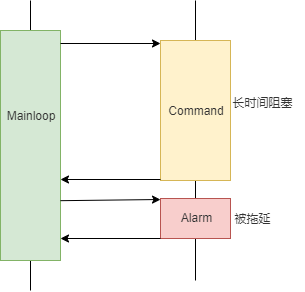
有人会想到额外增加一个线程专用于处理高优先级事件,实践中这确实是个常用方法。然而在嵌入式系统中,事件处理函数会读写很多公共数据结构,还会操作硬件接口,如果并发调用,极容易导致各类数据竞争和硬件操作冲突,而且这些问题常常很难定位和解决。那在多线程的基础上加锁呢?——设计哪些锁,加在哪些地方,也是非常烧脑而且容易出错的工作,如果互斥等待过多,还会影响性能,甚至出现死锁等麻烦的问题。
另一种解决方案是:把处理时间很长的任务切割成很多个小任务,并重新加入到事件队列中。这样就不会长时间的阻塞主循环。这个方案避免了并发编程产生的各种头疼问题,但是却带来另一个难题:如何把一个大流程切割成很多独立小流程?在编码时,这需要程序员解析函数流程的所有上下文信息,设计数据结构单独存储,并建立关联这些数据结构的特殊事件。这往往会带来几倍的额外代码量和工作量。
这个问题几乎在所有事件驱动型软件中都会存在,但在嵌入式软件中尤为突出。这是因为嵌入式环境下的CPU、线程等资源受限,而实时性要求高,并发编程受限。
C++20语言给这个问题提供了一种新的解决方案:协程。
C++20的协程简介
关于协程(coroutine)是什么,在wikipedia[1]等资料中有很好的介绍,本文就不赘述了。在C++20中,协程的关键字只是语法糖:编译器会将函数执行的上下文(包括局部变量等)打包成一个对象,并让未执行完的函数先返回给调用者。之后,调用者使用这个对象,可以让函数从原来的“断点”处继续往下执行。
使用协程,编码时就不再需要费心费力的去把函数“切割”成多个小任务,只用按照习惯的流程写函数内部代码,并在允许暂时中断执行的地方加上co_yield语句,编译器就可以将该函数处理为可“分段执行”。
协程用起来的感觉有点像线程切换,因为函数的栈帧(stack frame)被编译器保存成了对象,可以随时恢复出来接着往下运行。但是实际执行时,协程其实还是单线程顺序运行的,并没有物理线程切换,一切都只是编译器的“魔法”。所以用协程可以完全避免多线程切换的性能开销以及资源占用,也不用担心数据竞争等问题。
可惜的是,C++20标准只提供了协程基础机制,并未提供真正实用的协程库(在C++23中可能会改善)。目前要用协程写实际业务的话,可以借助开源库,比如著名的cppcoro[2]。然而对于本文所述的场景,cppcoro也没有直接提供对应的工具(generator经过适当的包装可以解决这个问题,但是不太直观),因此我自己写了一个切割任务的协程工具类用于示例。
自定义的协程工具
下面是我写的SegmentedTask工具类的代码。这段代码看起来相当复杂,但是它作为可重用的工具存在,没有必要让程序员都理解它的内部实现,一般只要知道它怎么用就行了。SegmentedTask的使用很容易:它只有3个对外接口:Resume、IsFinished和GetReturnValue,其功能可根据接口名字自解释。
#include <optional>
#include <coroutine> template<typename T>
class SegmentedTask {
public:
struct promise_type {
SegmentedTask<T> get_return_object()
{
return SegmentedTask{Handle::from_promise(*this)};
} static std::suspend_never initial_suspend() noexcept { return {}; }
static std::suspend_always final_suspend() noexcept { return {}; }
std::suspend_always yield_value(std::nullopt_t) noexcept { return {}; } std::suspend_never return_value(T value) noexcept
{
returnValue = value;
return {};
} static void unhandled_exception() { throw; } std::optional<T> returnValue;
}; using Handle = std::coroutine_handle<promise_type>; explicit SegmentedTask(const Handle coroutine) : coroutine{coroutine} {} ~SegmentedTask()
{
if (coroutine) {
coroutine.destroy();
}
} SegmentedTask(const SegmentedTask&) = delete;
SegmentedTask& operator=(const SegmentedTask&) = delete; SegmentedTask(SegmentedTask&& other) noexcept : coroutine(other.coroutine) { other.coroutine = {}; } SegmentedTask& operator=(SegmentedTask&& other) noexcept
{
if (this != &other) {
if (coroutine) {
coroutine.destroy();
}
coroutine = other.coroutine;
other.coroutine = {};
}
return *this;
} void Resume() const { coroutine.resume(); }
bool IsFinished() const { return coroutine.promise().returnValue.has_value(); }
T GetReturnValue() const { return coroutine.promise().returnValue.value(); } private:
Handle coroutine;
};
自己编写协程的工具类不光需要深入了解C++协程机制,而且很容易产生悬空引用等未定义行为。因此强烈建议项目组统一使用编写好的协程类。如果读者想深入学习协程工具的编写方法,可以参考Rainer Grimm的博客文章[3]。
接下来,我们使用SegmentedTask来改造前面的事件处理代码。当一个C++函数中使用了co_await、co_yield、co_return中的任何一个关键字时,这个函数就变成了协程,其返回值也会变成对应的协程工具类。在示例代码中,需要内层函数提前返回时,使用的是co_yield。但是C++20的co_yield后必须跟随一个表达式,这个表达式在示例场景下并没必要,就用了std::nullopt让其能编译通过。实际业务环境下,co_yield可以返回一个数字或者对象用于表示当前任务执行的进度,方便外层查询。
协程不能使用普通return语句,必须使用co_return来返回值,而且其返回类型也不直接等同于co_return后面的表达式类型。
enum class EventType {
COMMAND,
MESSAGE,
ALARM
};
std::vector<EventType> g_events{EventType::COMMAND, EventType::ALARM};
std::optional<SegmentedTask<int>> suspended; // 没有执行完的任务保存在这里
SegmentedTask<int> ProcessCmd()
{
for (int i{0}; i < 10; ++i) {
std::cout << "Processing step " << i << std::endl;
co_yield std::nullopt;
}
co_return 0;
}
void ProcessMsg()
{
std::cout << "Processing Message" << std::endl;
}
void ProcessAlm()
{
std::cout << "Processing Alarm" << std::endl;
}
int main()
{
for (auto event : g_events) {
switch (event) {
case EventType::COMMAND:
suspended = ProcessCmd();
break;
case EventType::MESSAGE:
ProcessMsg();
break;
case EventType::ALARM:
ProcessAlm();
break;
}
}
while (suspended.has_value() && !suspended->IsFinished()) {
suspended->Resume();
}
if (suspended.has_value()) {
std::cout << "Final return: " << suspended->GetReturnValue() << endl;
}
return 0;
}
出于让示例简单的目的,事件队列中只放入了一个COMMAND和一个ALARM,COMMAND是可以分段执行的协程,执行完第一段后,主循环会优先执行队列中剩下的事件,最后再来继续执行COMMAND余下的部分。实际场景下,可根据需要灵活选择各种调度策略,比如专门用一个队列存放所有未执行完的分段任务,并在空闲时依次执行。
本文中的代码使用gcc 10.3版本编译运行,编译时需要同时加上-std=c++20和-fcoroutines两个参数才能支持协程。代码运行结果如下:
Processing step 0
Processing Alarm
Processing step 1
Processing step 2
Processing step 3
Processing step 4
Processing step 5
Processing step 6
Processing step 7
Processing step 8
Processing step 9
Final return: 0
可以看到ProcessCmd函数(协程)的for循环语句并没有一次执行完,在中间插入了ProcessAlm的执行。如果分析运行线程还会发现,整个过程中并没有物理线程的切换,所有代码都是在同一个线程上顺序执行的。
使用了协程的顺序图变成了这样:
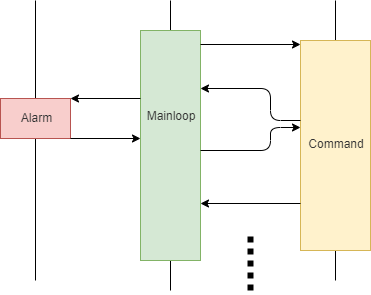
事件处理函数的执行时间长不再是问题,因为可以中途“插入”其他的函数运行,之后再返回断点继续向下运行。
总结
一个较普遍的认识误区是:使用多线程可以提升软件性能。但事实上,只要CPU没有空跑,那么当物理线程数超过了CPU核数,就不再会提升性能,相反还会由于线程的切换开销而降低性能。大多数开发实践中,并发编程的主要好处并非为了提升性能,而是为了编码的方便,因为现实中的场景模型很多都是并发的,容易直接对应成多线程代码。
协程可以像多线程那样方便直观的编码,但是同时又没有物理线程的开销,更没有互斥、同步等并发编程中令人头大的设计负担,在嵌入式应用等很多场景下,常常是比物理线程更好的选择。
相信随着C++20的逐步普及,协程将来会得到越来越广泛的使用。
尾注
[1] https://en.wikipedia.org/wiki/Coroutine
[2] https://github.com/lewissbaker/cppcoro
[3] https://www.modernescpp.com/index.php/tag/coroutines
比物理线程都好用的C++20的协程,你会用吗?的更多相关文章
- python进阶:Python进程、线程、队列、生产者/消费者模式、协程
一.进程和线程的基本理解 1.进程 程序是由指令和数据组成的,编译为二进制格式后在硬盘存储,程序启动的过程是将二进制数据加载进内存,这个启动了的程序就称作进程(可简单理解为进行中的程序).例如打开一个 ...
- Python 中的进程、线程、协程、同步、异步、回调
进程和线程究竟是什么东西?传统网络服务模型是如何工作的?协程和线程的关系和区别有哪些?IO过程在什么时间发生? 一.上下文切换技术 简述 在进一步之前,让我们先回顾一下各种上下文切换技术. 不过首先说 ...
- GJM : 进程、线程和协程的理解
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- Python之路【第七篇续】:进程、线程、协程
Socket Server模块 SocketServer内部使用 IO多路复用 以及 “多线程” 和 “多进程” ,从而实现并发处理多个客户端请求的Socket服务端.即:每个客户端请求连接到服务器时 ...
- python 进程、线程与协程的区别
进程.线程与协程区别总结 - 1.进程是计算器最小资源分配单位 - 2.线程是CPU调度的最小单位 - 3.进程切换需要的资源很最大,效率很低 - 4.线程切换需要的资源一般,效率一般(当然了在不考虑 ...
- Python线程和协程-day10
写在前面 上课第10天,打卡: 感谢Egon老师细致入微的讲解,的确有学到东西! 一.线程 1.关于线程的补充 线程:就是一条流水线的执行过程,一条流水线必须属于一个车间: 那这个车间的运行过程就是一 ...
- 进程&线程&协程
进程 一.基本概念 进程是系统资源分配的最小单位, 程序隔离的边界系统由一个个进程(程序)组成.一般情况下,包括文本区域(text region).数据区域(data region)和堆栈(stac ...
- python基础===进程,线程,协程的区别(转)
本文转自:http://blog.csdn.net/hairetz/article/details/16119911 进程拥有自己独立的堆和栈,既不共享堆,亦不共享栈,进程由操作系统调度. 线程拥有自 ...
- python进阶——进程/线程/协程
1 python线程 python中Threading模块用于提供线程相关的操作,线程是应用程序中执行的最小单元. #!/usr/bin/env python # -*- coding:utf-8 - ...
随机推荐
- 从yield到yield from再到python协程
yield 关键字 def fib(): a,b = 0,1 while 1: yield b a,b = b,a+b yield是在:PEP 255 -- Simple Generators 这个p ...
- IPFS是什么?IPFS与Filecoin有什么关系?
Filecoin 基于 IPFS 的去中心化存储网络,是 IPFS 上唯一的激励层,是一个基于区块链技术发行的通证.Filecoin 翻译过来就是文件币,简称为 FIL. 在 FIlecoin 网络中 ...
- 《逆向工程核心原理》——IAThook
hook逻辑写入dll中,注入dll. #include "pch.h" #include <tchar.h> #include "windows.h&quo ...
- C语言数组寻址
C语言数组 数组的定义 数组是用来存放数据类型相同且逻辑意义相同的数据 数组的大小 数组的大小不能是变量,必须是常量或者常量表达式,常量表达式由编译器编译时自动求值. 也可以不指定数组大小,但必须对数 ...
- python3表格数据处理
技术背景 数据处理是一个当下非常热门的研究方向,通过对于大型实际场景中的数据进行建模,可以用于预测下一阶段可能出现的情况.比如我们有过去的2002年-2018年的黄金价格的数据: 该数据来源于Gite ...
- Java框架Spring Boot & 服务治理框架Dubbo & 应用容器引擎Docker 实现微服务发布
微服务系统架构实践 开发语言Java 8 框架使用Spring boot 服务治理框架Dubbo 容器部署Docker 持续集成Gitlab CI 持续部署Piplin 注册中心Zookeeper 服 ...
- java面试一日一题:rabbitMQ的工作模式
问题:请讲下rabbitMQ的工作模式 分析:该问题纯属概念题,需要掌握rabbtiMQ的基础知识,同时该题也是切入MQ的一个引子: 回答要点: 主要从以下几点去考虑, 1.rabbitMQ的基本概念 ...
- 记录给树莓派刷Raspberry Pi OS(Raspbian)系统的配置流程
准备材料 树莓派(一定要贴散热片,最好再加个小风扇) TF内存卡 (记得选传输规范为Class10标准的) 读卡器 电脑(这里我使用的电脑是Windows系统,其它系统可能与下面的步骤有出入,还望悉知 ...
- Asp Net Core 5 REST API 使用 RefreshToken 刷新 JWT - Step by Step
翻译自 Mohamad Lawand 2021年1月25日的文章 <Refresh JWT with Refresh Tokens in Asp Net Core 5 Rest API Step ...
- 从零玩转第三方登录之QQ登录
从零玩转第三方登录之QQ登录 前言 在真正开始对接之前,我们先来聊一聊后台的方案设计.既然是对接第三方登录,那就免不了如何将用户信息保存.首先需要明确一点的是,用户在第三方登录成功之后, 我们能拿到的 ...