OOP第三章博客
OO第三单元博客
• (1)梳理JML语言的理论基础、应用工具链情况:
理论基础:
网络资料上面介绍JML有两种主要的用法:
- 开展规格化设计。这样交给代码实现人员的将不是可能带有内在模糊性、二义性的自然语言描述,而是逻辑严格的规格语言描述。
这应该也是我们学习JML的目的,希望我们可以掌握这种逻辑严格的面向对象思想,首先从整体上规范每个类和方法,再去考虑内部的逻辑实现。
- 针对已有的代码实现,书写其对应的规格,从而提高代码的可维护性。这在遗留代码的维护方面具有特别重要的意义。
这一方面,我个人的理解就是从优化的角度来看,三次作业的体会就是,每一次的优化都会导致引入自定义的属性,这时能否符合原始规格是个重要的优化标准,良好的设计应该是新引入的属性不会对原始的规格结果有影响!否则方法或者类的设计就是有漏洞的,而且往往会容易忽视优化对原有的正确性的影响,所以优化后一定要重新测试相关方法和类,保证之前的正确性!
The Java Modeling Language (JML) is a behavioral interface specification language that can be used to specify the behavior of Java modules. It combines the design by contract approach of Eiffel and the model-based specification approach of the Larch family of interface specification languages, with some elements of the refinement calculus.
中文:
Java建模语言(JML)是一种行为接口规范语言,可用于指定Java模块的行为 。它结合了Eiffel的契约方法设计 和Larch 系列接口规范语言的基于模型的规范方法 ,以及细化演算的一些元素。
契约式设计的六大原则,在jml中都有体现:
- 区分命令和查询;
- 将基本查询和派生查询区分开;
- 针对每个派生查询,设定一个后验条件,使用一个或多个基本查询的结果来定义它;
- 对于每个命令都撰写一个后验条件,规定每个基本查询的值;
- 对于每个查询和命令,采用一个合适的先验条件;
- 撰写不变式来定义对象的恒定特性。
工具链:
除了老师和助教推荐的OpenJml,还有多种工具支持:

但是个人发现,windows下可能并不太适合使用,idea也不是亲儿子,所以工具尝试令人沮丧。
• (2)部署SMT Solver,至少选择3个主要方法来尝试进行验证,报告结果

转战WSL后,终于成功的运行了之前手册上面的例子;
首先出现的错误检查后发现时规格书写漏掉了一个“;”
再次运行后WSL不报错,但是idea的报了警告显示方法可能会int溢出

• (3)部署JMLUnitNG/JMLUnit,针对Graph接口的实现自动生成测试用例, 并结合规格对生成的测试用例和数据进行简要分析
经过尝试,终于算是部署成功,可以尝试小规模的测试样例,例如讨论区的伦佬的例子,但对于作业由于各种路径问题,实在是调不出来......
所以放一张实现讨论区的图片吧:
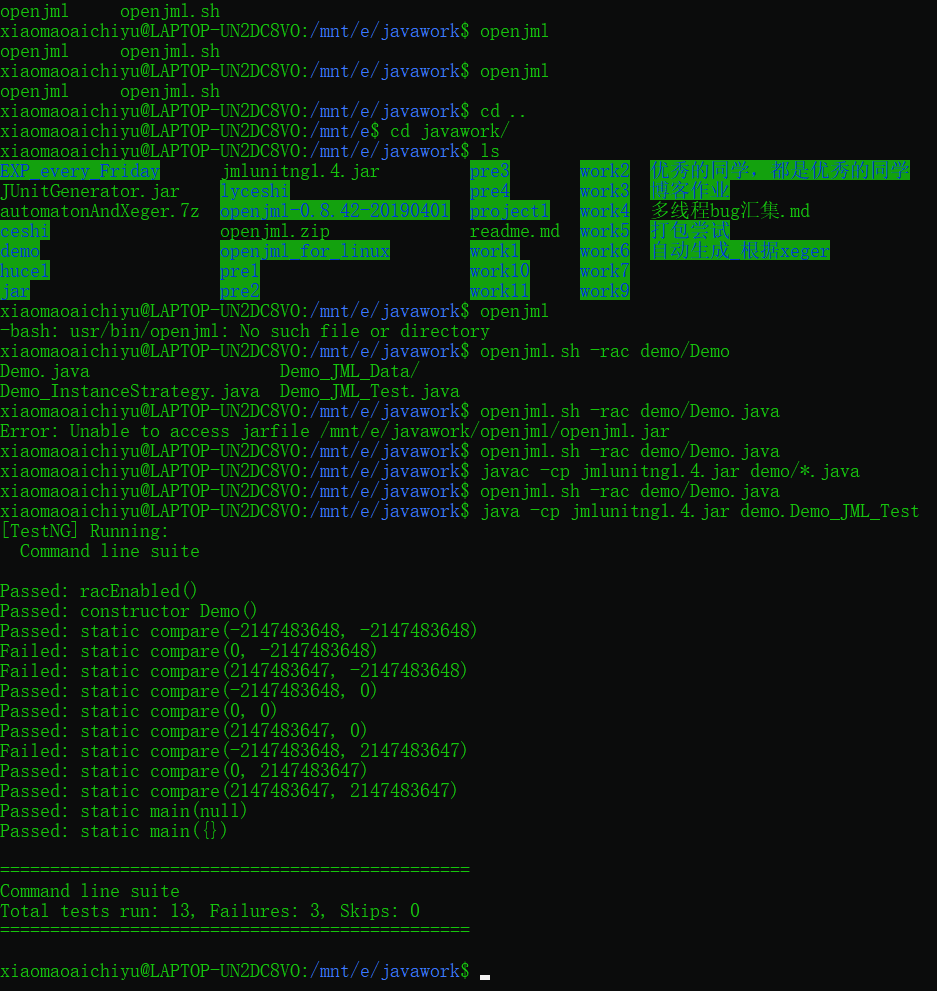
• (4)按照作业梳理自己的架构设计,并特别分析迭代中对架构的重构
第一次作业:
MyPath类的复杂度不高,只存在\(O(n)\)和\(O(1)\)的方法,所以设计时采用了根据规格实现的方式(后期证明这样是极不明智的选择);
MyPathContainer的设计基本也是按照规格实现,但是因为最后的查找不同节点数每次运行都是\(O(n^2)\),所以采用将查询结果保存下来的方式,进一步是把查询的复杂度平均到了add和remove操作中去。这里为了满足SOLID原则,选择自己构建了两个函数用于addPathCountDiffNodes和removePathCountDiffNodes;
第一次作业设计时没有充分考虑到Node这一对象的抽象性,而是选择直接使用Ingeter来代替一个Node的id,所以在后两次作业中对这个地方进行了重构。
第二次作业:
第二次作业的设计整体上看架构不太合理,但是因为新增功能不多,所以也能应付,问题就是在于扩展的不利,导致第三次作业的架构臃肿混乱,是一个败笔。
MyPath类和MyPathContainer直接选择继承,并没有进行修改,而且, 我选择直接实现Graph接口,没有采用继承的结构,在第二次作业来看,确实可行,但是第三次作业证明这样做对于后续的扩展不利。
MyGraph类内部有MypathContainer的属性,以及为了计算Graph属性所必须的地图,采用的是静态数组,利用HashMap来进行index重排。
int[250][250]
同时保存边的信息时,抽象出一个Edge的对象用来保存两点之间的边的信息;
在构建地图的选择上,采用在addPath和removePath的时候同时更新不同的节点和邻接图,更新时会遍历所有的不同节点和之前建立的边权结合来进行权重设置(这里权重只有1)
对于isConnected的判断是通过求最短路来进行判断,若最短路存在,不是MAXINT则说明相连(邻接图初始化为MAXINT);
对于containsEgde的判断同样通过最短路径来判断(其实这里可以优化,使用之前建立的边集合来进行判断)若最短路为1则说明存在这样一条边。特例是两个相同点之间的自环,所以需要特判一下。
在求最短路时,采用的是dijkstra算法,也没有性堆优化,只是朴素的\(O(n^2)\)
这里的架构设计,是直接把地图信息放在Graph类里面,将dijkstra算法包装为一个静态算法进行计算。
第三次作业:
本次作业的整体思路是利用拆点法和堆优化的dijkstra来进行四类运算(最短路,最低价,最小换乘,最小满意度);
在架构上,采用自己包装的HashMap二维数组来进行各种权重地图的建立,将地图信息存放于第二次作业的GraphProcess(地图处理类)中;
所以在railwaySystem中需要保存见图建图所需的边权信息Edge和节点信息Nodes,并且,将Node为一个类(重构之前的设计);
具体实现较为复杂,所以不多赘述,总体上说,在railsystem中实现四个GraphProcess的处理器来处理不同的问题,并且在每次addPath或者removePath时重新构图;在结果的计算上,当不访问时不会进行最短路的计算,每次计算也会把源点到各个点的距离保存下来,后续访问可以直接返回结果。
• (5)按照作业分析代码实现的bug和修复情况
第一次作业:
在优化的时候重新写了addpath和removepath,引入了新的没有控制的元素,导致出现了问题,是因为逻辑的错误,导致添加不同节点在每一次addpath都进行(添加相同路时不需要)
第二次作业:
第二次作业没有显而易见的bug;
第三次作业:
第三次作业在时间复杂度上出现了问题,原因有两点:
1:在拆点法中,对于相同的节点,采用每两个节点均相连,所以邻接图的边较多,导致dijkstra的时间复杂度上升;
2:在自己包装的二维数组中,判断是否存在某一边,会进行一次冗杂的判断,时间度几乎翻倍;
解决以上两点后,时间复杂度便没有问题了。
• (6)阐述对规格撰写和理解上的心得体会
首先谈一下个人对于规格的理解:
规格符合契约式设计原则,对于面向对象的类和方法的设计提出了前置条件和后验条件,以保证一个方法或者一个类在合法输入的情况下一定会输出满足条件的结果;
但是在三次作业中,我都发现这样一个问题,规格只用来限制前置条件和后验条件即可,并不是对方法的实现限制,因为实际的设计中,我发现,优化往往会导致某一方法中的某些元素是被另一个方法的规格所约束的,这种组合嵌套的关系导致规格不是那么清晰,而且还需要为了规格而设计相应的占位方法;
所以这种情况下,我理解的规格就是限制输入和满足输出的契约,在这种情况下,通过单元测试和层次分离,尽量把结构设计的高内聚低耦合,这样在优化时的逻辑首先是可寻的,可控的,复杂凌乱的设计将导致优化会引入更多的问题,所以一个良好的架构是规格发挥最大效果的基础(个人理解!)
写在最后:
目前而言,OO学习已经度过了12周,从最初的输入输出处理,到多线程debug,以及之前的jml规格,每一次都能够学到一些新的知识,尽管暴露出很多问题,但是整体感觉本届的OO改革算是成功的,希望课题组能够保持下去,给下一届一个良好的“教训”。
OOP第三章博客的更多相关文章
- OOP第四章博客
OOP第四章博客作业 (1)本单元作业架构设计 1)针对于第一次作业,我是将所给类进行了自己的封装,在MyUmlInteraction类里面进行关系的建立,这里把所给的UmlClass建立好,同时有i ...
- 第65章 博客帖子 - Identity Server 4 中文文档(v1.0.0)
第65章 博客帖子 65.1 团队帖子 65.1.1 2019 IdentityServer中的范围和声明设计 尝试使用IdentityServer4的设备流程 OAuth2中隐含流的状态 另一种保护 ...
- [BUAA OO]第三次博客作业
OO第三次博客作业 1. 规格化设计的发展 我认为,规格化设计主要源自于软件设计的两次危机.第一次是由于大量存在的goto语句,让当时被广泛应用的面向过程式的编程语言臃肿不堪,在逻辑性上与工程规模上鱼 ...
- OO第三次博客作业——规格
OO第三次博客作业——规格 一.调研结果: 规格的历史: 引自博文链接:http://blog.sina.com.cn/s/blog_473d5bba010001x9.html 传统科学的特点是发现世 ...
- [2017BUAA软工]第三次博客作业:案例分析
第三次博客作业:案例分析 1. 调研和评测 1.1 BUG及设计缺陷描述 主要测试博客园在手机端上的使用情况. [BUG 01] 不能后退到上一界面(IOS) 重现步骤:打开博客首页中任意博文,点击博 ...
- OOP第二章博客
OO第二次博客作业 (1)作业分析 三次作业在处理多线程的协同配合时都是使用将同步放在自己写的"线程安全类"(经测试有些许漏洞_,但是不影响结果就是了): 我个人倾向于把wait( ...
- java三篇博客转载 详解-vector,stack,queue,deque
博客一:转载自http://shmilyaw-hotmail-com.iteye.com/blog/1825171 java stack的详细实现分析 简介 我们最常用的数据结构之一大概就是stack ...
- 【作业3.0】HansBug的第三次博客规格总结
转眼间第三次作业了,似乎需要说点啥,那就说点. 规格&工业 说到这个,不得不提一下软件开发的发展史. 历史的进程 早在上世纪50年代,就已经有早期的编程语言出现,也开始有一些程序编写者出现(多 ...
- 第三周博客总结 <西北师范大学| 周安伟>
一,本周助教小结 工作稳步推进,时间分配合理,点评效率有所提高,主要进行了评分工作,工作情况都汇总到了Excel中. 二,助教本人博客 https://home.cnblogs.com/u ...
随机推荐
- MySQL语法基础
一.通用语法 1.MySQL数据库的SQL语句不区分大小写 2.可以用/**/完成注释 3.常用数据类型 类型 描述 int 整型 double 浮点型 varchar 字符串型 date 日期类型, ...
- 《逆向工程核心原理》——API HOOK
编写dll处理hook逻辑,注入到目标进程,实现api hook. Windows10 notepad,通过hook kernel32.dll.WriteFile,实现小写字母转大写保存到文件. ho ...
- 微信开发者工具导入 wepy 项目“app.json 未找到”报错解决方法
版本信息: 微信开发者工具:1.03.2101150 wepy:2.0 wepy/cli:6.14.8 问题描述 按照 wepy 文档中的步骤新建项目: $ npm install @wepy/cli ...
- MarkDown-简单学习
标题 注意:首部添加1-6个"#"号来设置标题大小: 字体 1:粗体 (注意:首尾同时添加2个"*"号来设置) 2:斜体 (注意:首尾同时添加1个"* ...
- 极简实用的Asp.NetCore模块化框架决定免费开源了
背景 在开发这个框架之前,前前后后看过好几款模块化的框架,最后在一段时间内对ABP VNext痛下狠心,研究一段时间后,不得不说 ABP VNext的代码层面很规范,也都是一些最佳实践,开发出一个模块 ...
- [深搜]A. 【例题1】拔河比赛
A . [ 例 题 1 ] 拔 河 比 赛 A. [例题1]拔河比赛 A.[例题1]拔河比赛 解析 模板题,选与不选 Code #include <bits/stdc++.h> #defi ...
- [矩阵乘法]裴波拉契数列III
[ 矩 阵 乘 法 ] 裴 波 拉 契 数 列 I I I [矩阵乘法]裴波拉契数列III [矩阵乘法]裴波拉契数列III Description 求数列f[n]=f[n-1]+f[n-2]+1的第N ...
- 数据结构与算法-江西师范大学865(针对考研or面试)
可以加我微信chenyoudea免费要江西师范大学865资料全套pdf 目录 第一篇 数据结构与算法(针对考研or面试) 第二篇 真题演练 第三篇 复试 第四篇 推荐阅读 第一篇 数据结构与算法(针对 ...
- 使用docker快速安装软件
安装mysql mkdir /opt/mysql /opt/mysql/etc /opt/mysql/data docker run -itd --name mariadb -e MYSQL_ROOT ...
- Vue学习(三)-Vue-router路由的简单使用
一.Vue-Router环境的安装: 如果使用vue-cli脚手架搭建,项目创建过程中会提示你自否选择使用vue-router,选择使用即可, 二.路由学习 1.路由的配置 vue-cli项目自 ...