hudi clustering 数据聚集(一)
概要
数据湖的业务场景主要包括对数据库、日志、文件的分析,而管理数据湖有两点比较重要:写入的吞吐量和查询性能,这里主要说明以下问题:
1、为了获得更好的写入吞吐量,通常把数据直接写入文件中,这种情况下会产生很多小的数据文件。虽然小文件的使用可以增加写入的并行度,且能够并行读取文件以提高读取速度,但会出现一个数据量很小,需要从多个小文件中读取数据,增加了很多IO。
2、数据按照进入数据湖的方式写入到文件中,在同一个文件上,数据局部性不是最佳的。 数据之间,与传入批次相关,相近的批次的数据会相关联,而不是与经常要查询的数据相关联。所以小文件的大小和缺乏数据局部性会降低查询性能。
3、此外,许多文件系统(包括 hdfs),当有很多小文件时,性能会下降。
hudi clustering
hudi支持clustering功能,在不影响查询性能的情况下提高写入吞吐量。该功能可以以不同方式重写数据:
1、数据先写入小文件,在满足某些条件后(例如经过的时间、小文件数量、commit次数等),将小文件拼接成大文件。
2、通过对不同列上的数据进行排序,来更改磁盘上的数据布局,已提高数据间的相关性,可以提高查询性能。
实现
(用户可以将小文件的限制 hoodie.parquet.small.file.limit 配置为 0,这样可以强制将数据进入新的文件组。)
cow表的timeline
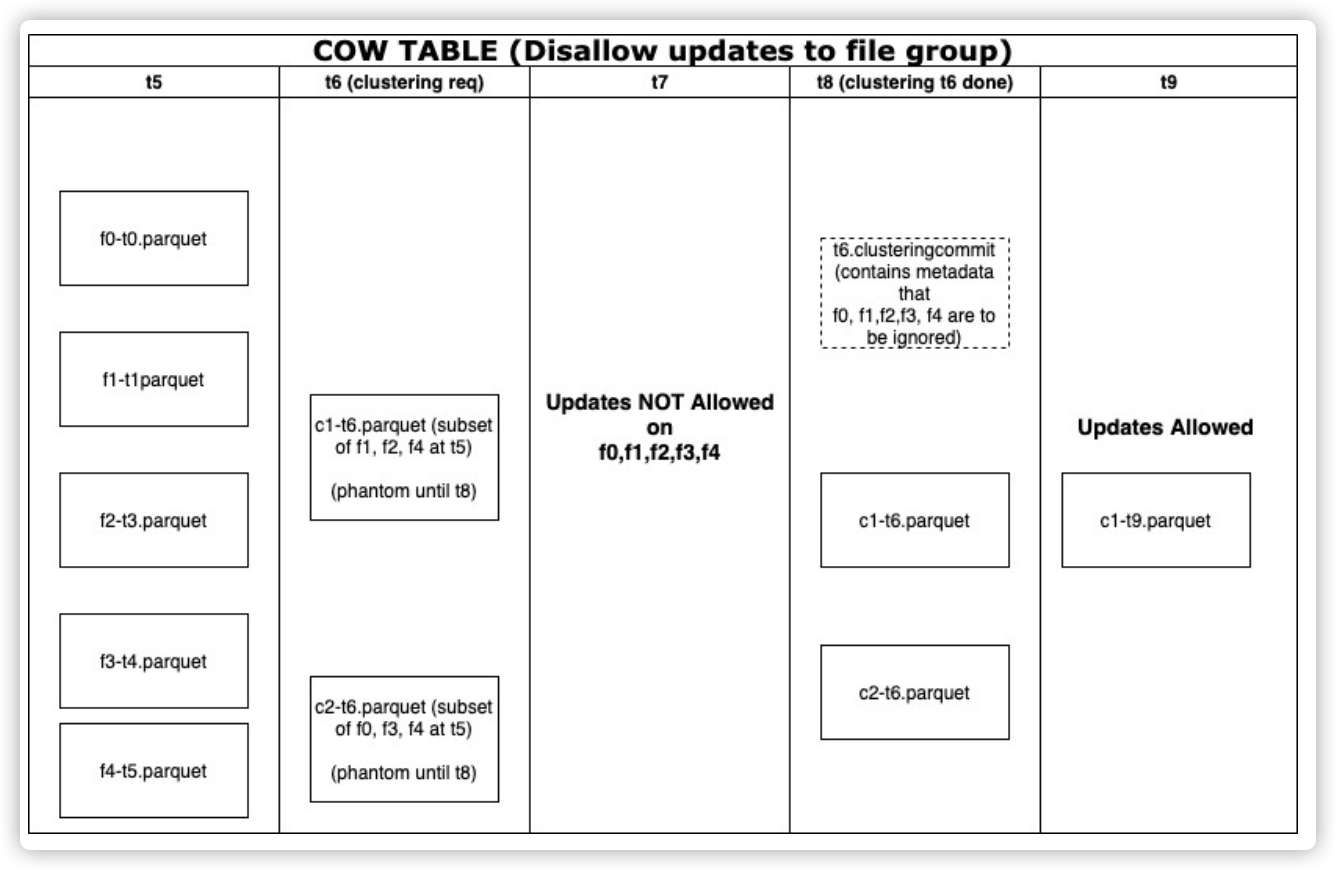
在上面的示例流程图中,显示了随时间(t5 到 t9)的分区状态。 主要有以下步骤:
- 在 t5,表中的一个分区有 5 个文件组 f0、f1、f2、f3、f4,分别在 t0、t1、t2、t3、t4时刻被创建。 假设每个文件组为 100MB。 所以分区中的总数据为 500MB。
- 在 t6 请求 clustering 操作。 与压缩类似,我们在带有“ClusteringPlan”的元数据中创建了一个“t6.clustering.requested”文件,其中包含跨所有分区的集群操作涉及的所有文件组。例如:{ partitionPath: {“datestr”}, oldfileGroups: [ {fileId: “f0”, time: “t0”}, { fileId: “f1”, time: “t1”}, ... ], newFileGroups: [“c1”, “c2”] }
- 假设clustering后的最大文件大小配置为 250MB。 集群会将分区中的所有数据重新分配到两个文件组中:c1、c2。 此时这些文件组是“虚假”的,在 t8 clustering 完成之前,对查询不可见。
- 请注意,文件组中的记录可以拆分为多个文件组。 在此示例中,来自 f4 文件组的一些记录同时转到了新文件组 c1、c2。
- 当集群正在进行时(t6 到 t8),任何涉及到这些文件组的更新插入都会被拒绝。
- 在写入新的数据文件 c1-t6.parquet 和 c2-t6.parquet 后,如果配置了全局索引,我们会在记录级索引中为所有具有新位置的键添加条目。 新的索引条目对其他写入将不可见,因为还没有关联的提交。
- 最后,我们创建一个提交元数据文件“t6.commit”,其中包含由此次提交修改的文件组(f0、f1、f2、f3、f4)。
- 注:文件组(f0 到 f4)不会立即从磁盘中删除。 cleaner 会在归档 t6.commit 之前清理这些文件。 并且,clustering 还会更新所有视图和源数据文件。
mor表的时间线
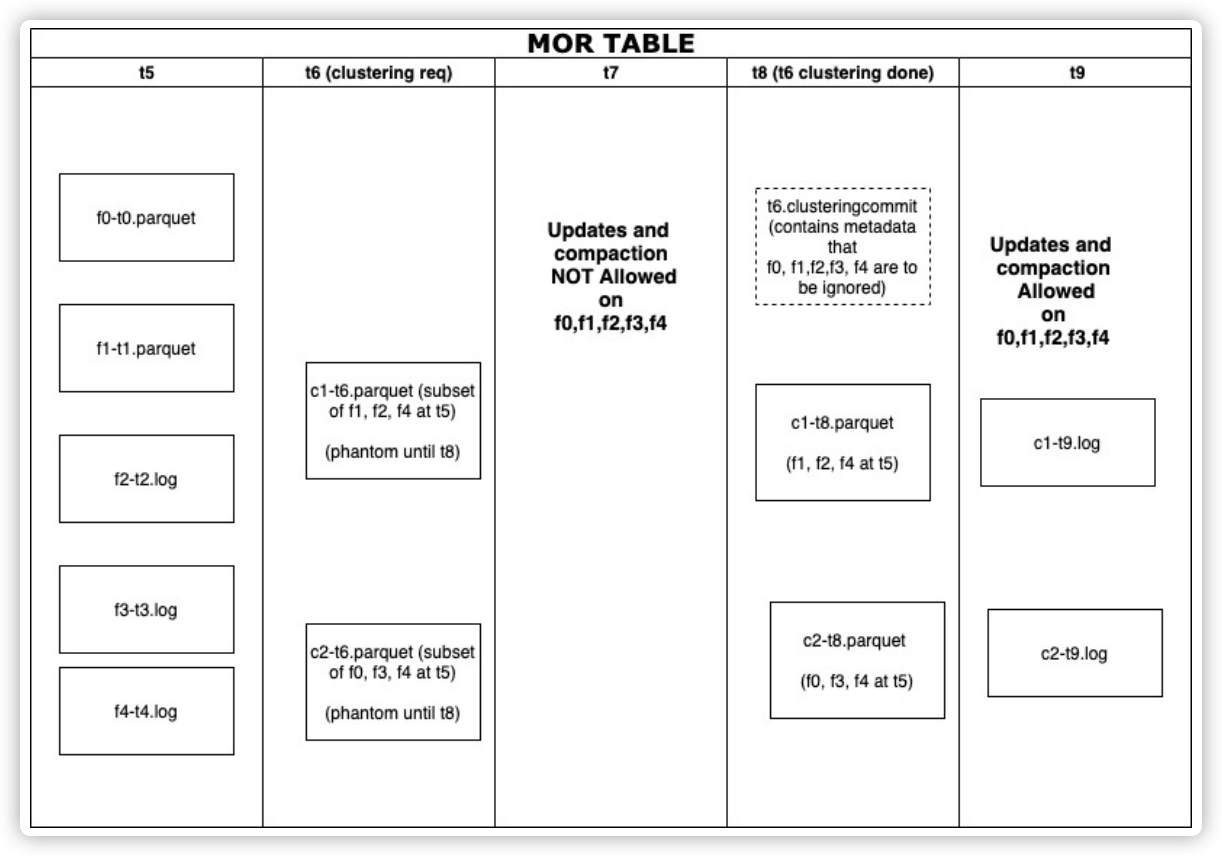
这种方法同样支持mor表,且过程与cow 表非常相似。
clustering 的为 parquet 格式文件。
Clustering 操作步骤
总体来说,需要两步:
- clustering 调度:创建 clustering 计划
- 执行 clustering:执行计划。创建新的文件,并替换旧的文件。
clustering 调度
- 识别符合集群条件的文件
- 过滤特定分区(根据配置优先考虑最新分区或旧分区)
- 任何大小 > targetFileSize 的文件都不符合条件
- 任何有待定压缩/clustering计划的文件都不符合条件
- 任何具有日志文件的文件组都不符合集群条件(该限制以后可能会被取消)
- 根据特定条件对符合聚类条件的文件进行分组。 每个组的数据大小预计是“targetFileSize”的倍数。 分组是作为计划中定义的“策略”的一部分完成的:
- 根据记录键范围对文件进行分组。因为键值范围存储在parquet footer中,这个可用于某些查询/更新。
- 根据提交时间对文件进行分组。
- 对自定义列,且具有重叠值的文件进行分组(指定列进行排序)
- 分组随机文件
- 我们可以限制组大小以提高并行性
- 根据特定条件过滤组(类似于 CompactionStrategy 中的 orderAndFilter)
- 最后,clustering计划被保存到timeline中。
执行 clustering
- 读取clustering计划,查看“clusteringGroups”的数量(用于并行性)。
- 创建 inflight状态的 clustering 文件
- 对于每组:
- 使用 strategyParams 实例化适当的策略类(例如:sortColumns)
- 策略类定义了分区器,我们可以用它来创建桶并写入数据。
- 创建 replacecommit:
- operationType 设置为“clustering”。
- 扩展元数据,并存储附加字段以跟踪重要信息(策略类可以返回这些额外的元数据信息)
- 用于合并文件的策略
- 跟踪替换文件
【参考】
https://hudi.apache.org/docs/next/configurations/#hoodieclusteringplanstrategyclass
hudi clustering 数据聚集(一)的更多相关文章
- hudi clustering 数据聚集(二)
小文件合并解析 执行代码: import org.apache.hudi.QuickstartUtils._ import scala.collection.JavaConversions._ imp ...
- hudi clustering 数据聚集(三 zorder使用)
目前最新的 hudi 版本为 0.9,暂时还不支持 zorder 功能,但 master 分支已经合入了(RFC-28),所以可以自己编译 master 分支,提前体验下 zorder 效果. 环境 ...
- 基于Apache Hudi构建数据湖的典型应用场景介绍
1. 传统数据湖存在的问题与挑战 传统数据湖解决方案中,常用Hive来构建T+1级别的数据仓库,通过HDFS存储实现海量数据的存储与水平扩容,通过Hive实现元数据的管理以及数据操作的SQL化.虽然能 ...
- KLOOK客路旅行基于Apache Hudi的数据湖实践
1. 业务背景介绍 客路旅行(KLOOK)是一家专注于境外目的地旅游资源整合的在线旅行平台,提供景点门票.一日游.特色体验.当地交通与美食预订服务.覆盖全球100个国家及地区,支持12种语言和41种货 ...
- 【mongoDB高级篇②】大数据聚集运算之mapReduce(映射化简)
简述 mapReduce从字面上来理解就是两个过程:map映射以及reduce化简.是一种比较先进的大数据处理方法,其难度不高,从性能上来说属于比较暴力的(通过N台服务器同时来计算),但相较于grou ...
- MySQL必知必会(汇总数据, 聚集函数)
SELECT AVG(prod_price) AS avg_price FROM products; #AVG只能用于单个列求平均值,如想计算多个列,必须用多个AVG() SELECT AVG(pro ...
- 对话Apache Hudi VP, 洞悉数据湖的过去现在和未来
Apache Hudi是一个开源数据湖管理平台,用于简化增量数据处理和数据管道开发,该平台可以有效地管理业务需求,例如数据生命周期,并提高数据质量.Hudi的一些常见用例是记录级的插入.更新和删除.简 ...
- 一文彻底掌握Apache Hudi异步Clustering部署
1. 摘要 在之前的一篇博客中,我们介绍了Clustering(聚簇)的表服务来重新组织数据来提供更好的查询性能,而不用降低摄取速度,并且我们已经知道如何部署同步Clustering,本篇博客中,我们 ...
- 基于Apache Hudi 的CDC数据入湖
作者:李少锋 文章目录: 一.CDC背景介绍 二.CDC数据入湖 三.Hudi核心设计 四.Hudi未来规划 1. CDC背景介绍 首先我们介绍什么是CDC?CDC的全称是Change data Ca ...
随机推荐
- centos查找大文件
首先到相当的目录下面,按下面方式查找 find . -type f -size +800M -print0 | xargs -0 ls -lah或者从根目录(/)开始查找find / -type f ...
- 三分钟图解 MVCC,看一遍就懂
前文我们介绍了 InnoDB 存储引擎在事务隔离级别 READ COMMITTED 和 REPEATABLE READ(默认)下会开启一致性非锁定读,简单回顾下:所谓一致性非锁定读就是每行记录可能存在 ...
- CF39C-Moon Craters【dp】
正题 题目链接:https://www.luogu.com.cn/problem/CF39C 题目大意 坐标轴上有\(n\)个圆,给出每个圆的位置\(c_i\)和半径\(r_i\). 要求选出最多的圆 ...
- CF835E-The penguin‘s game【交互】
正题 题目链接:https://www.luogu.com.cn/problem/CF835E 题目大意 长度为\(n\)的序列中有两个\(y\)其他都是\(x\),给出\(n,x,y\).你每次可以 ...
- 国庆七天假 不如来学学Vue-Router
Vue-Router 基本介绍 Vue-Router是Vue全家桶中至关重要的一个扩展化插件,使用它能够让我们的组件切换更加的方便,更加容易的开发前后端分离项目,目前Vue-Router版本已更新到4 ...
- 基于C++的ButeBuf封装
目录 1.说明 2.代码 1.说明 netty 的 ByteBuf 中的 readerIndex 和 writerIndex 的设置十分巧妙,它内部对读取和写入位置进行控制,避免自己处理index的时 ...
- NOIP 模拟 十一
T1 math 分析性质,对于 $$ ax+by=c$$ 有 $$ gcd(x,y)|c$$ 所以 $$ gcd(a_1,a_2 .....,a_n)|num$$ 换句话说就是最后得到的数一定是 GC ...
- ☠全套Java教程_Java基础入门教程,零基础小白自学Java必备教程👾#010 #第十单元 Scanner类、Random类 #
一.本单元知识点概述 (Ⅰ)知识点概述 二.本单元教学目标 (Ⅰ)重点知识目标 1.API的使用2.Scanner类的使用步骤3.Random类的使用 (Ⅱ)能力目标 1.掌握API的使用步骤2.使用 ...
- 洛谷5024 保卫王国 (动态dp)
qwq非正解. 但是能跑过. 1e5 log方还是很稳的啊 首先,考虑最普通的\(dp\) 令\(dp1[x][0]表示不选这个点,dp1[x][1]表示选这个点的最大最小花费\) 那么 \(dp1[ ...
- [no code][scrum meeting] Beta 10
$( "#cnblogs_post_body" ).catalog() 例会时间:5月25日15:00,主持者:伦泽标 下次例会时间:5月26日11:30,主持者: 一.工作汇报 ...