Etcd中linearizable read实现
linearizable

有点疑惑,不确定是现在浏览的版本没开发完全,还是没有按照论文的linearizable来实现。
按照论文所说,在客户端请求的时候,实际上是一个强一致的 exactly once的过程。
在etcd中,只看到了read的 linearizable ,并且用到的地方是在诸如读取节点列表,开始事务等操作中。
可以从2个层面来验证写与读一致性
business data which stored in etcd
因为raft只有leader是写的入口,所以保证数据的顺序是可以在leader做处理的。
业务数据的顺序,etcd并不能保证顺序,因为入口之外的原因太多:
并发,业务方的数据是并发过来的,那么到达leader的先后性无法保证
业务请求策略,业务数据是并发且被路由到不通的follower,到达leader的先后性也是无法保证的
网络延迟,那更无法保证绝对的先后性了
所以leader是无法保证业务数据的绝对先后,这是由client或者说使用方来设计的,和数据库是一样的道理。
leader能保证的是,进入其内部后数据保存的一致性
所以在业务数据层面,etcd无法保证其先后性,除非提供特殊的协议,事务算半种,要绝对的一致性,得是嵌入或者包装业务数据的协议。
所以我理解的是,没有在业务数据层面用写一致的必要。
application config data of etcd
etcd中实现读一致的入口全部都是和应用配置相关的,例如节点列表、事务、降级,下图是使用到的地方
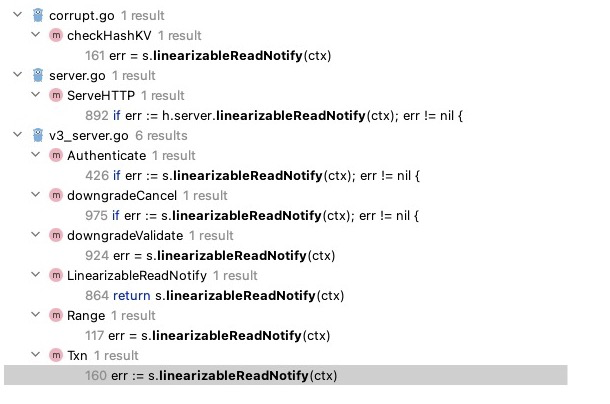
判断读一致的逻辑是
confirmedIndex, err := s.requestCurrentIndex(leaderChangedNotifier, requestId)
if isStopped(err) {
return
}
if err != nil {
nr.notify(err)
continue
}
trace.Step("read index received")
trace.AddField(traceutil.Field{Key: "readStateIndex", Value: confirmedIndex})
appliedIndex := s.getAppliedIndex()
trace.AddField(traceutil.Field{Key: "appliedIndex", Value: strconv.FormatUint(appliedIndex, 10)})
if appliedIndex < confirmedIndex {
select {
case <-s.applyWait.Wait(confirmedIndex):
case <-s.stopping:
return
}
}
// unblock all l-reads requested at indices before confirmedIndex
nr.notify(nil)
requestCurrentIndex会返回当前leader正在处理的commitIndex,这里设计很巧妙,简单来说是返回commitIndex,然后节点和自己的appiledIndex相比较,直到appliedIndex >= commitIndex ,才算做读一致完成。
结合读一致使用的地方以及逻辑这2点,保证的是所有请求时当下leader中在处理的数据在集群内都被处理了,可能后面又变了,例如节点变更了,所以实际上是瞬时一致并且最终一致。
例如txn开启事务,保证了请求时leader的数据都处理好了,因为leader要处理的数据也包括节点变更的配置数据。
所保证的是脏读的场景对于单次请求是有效的,即单次请求是不会有脏读的,但这次请求返回的数据与下次请求返回的数据仍然有可能不一致,所以是最终一致的。
写一致是否有必要在这里实现?如果这次的请求要求写一致,那么下次请求就要依赖于这次请求的写一致,这次请求还没结束,后面的请求全部都要wating,并且无穷级联下去。所以选择了最终一致来应对写一致。这是个典型的base。
结合以上2个层面的分析,写一致在业务数据层面是由使用方来设计,配置数据层面是由最终一致代替。
读一致业务数据层面也是由使用方来设计,配置数据层面保证当次请求的读取没有脏数据,也由最终一致代替。
Raft log replication flow
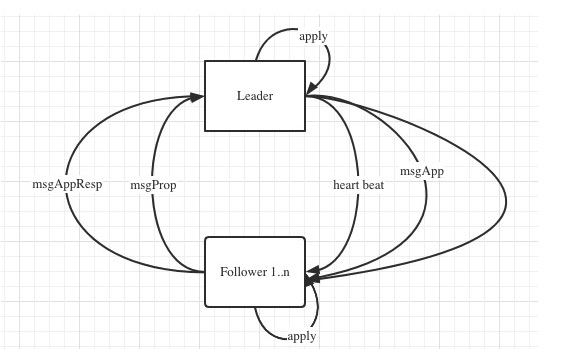
还是得放上这张图,因为整个通讯过程仍然是遵照raft消息的方式,只不过这里用的消息类型是 MsgReadIndex,同proposal的区别是没有commit的过程,仅仅是将MsgReadIndex消息发送给leader,leader会回复ReadIndexResp。
Logic flow
Trigger linearizable read
读一致的入口在上面已列举,此处随意找一个
func (s *EtcdServer) Txn(ctx context.Context, r *pb.TxnRequest) (*pb.TxnResponse, error) {
if isTxnReadonly(r) {
trace := traceutil.New("transaction",
s.Logger(),
traceutil.Field{Key: "read_only", Value: true},
)
ctx = context.WithValue(ctx, traceutil.TraceKey, trace)
if !isTxnSerializable(r) {
err := s.linearizableReadNotify(ctx)
trace.Step("agreement among raft nodes before linearized reading")
if err != nil {
return nil, err
}
}
s.linearizableReadNotify(ctx),等待读一致处理完成
开始读一致的逻辑
func (s *EtcdServer) linearizableReadNotify(ctx context.Context) error {
s.readMu.RLock()
nc := s.readNotifier
s.readMu.RUnlock()
// signal linearizable loop for current notify if it hasn't been already
select {
case s.readwaitc <- struct{}{}:
default:
}
// wait for read state notification
select {
case <-nc.c:
return nc.err
case <-ctx.Done():
return ctx.Err()
case <-s.done:
return ErrStopped
}
}
这是与 linearizableReadLoop 相互通讯的胶水函数
s.readwaitc 触发linearizableReadLoop逻辑开始查询readindex
s.readNotifier 返回信号表明读一致处理完成
Read loop on server starting
在server 启动时,会启动读一致的自旋,即上面处理读一致的逻辑
func (s *EtcdServer) linearizableReadLoop() {
for {
requestId := s.reqIDGen.Next()
leaderChangedNotifier := s.LeaderChangedNotify()
select {
case <-leaderChangedNotifier:
continue
case <-s.readwaitc:
case <-s.stopping:
return
}
// as a single loop is can unlock multiple reads, it is not very useful
// to propagate the trace from Txn or Range.
trace := traceutil.New("linearizableReadLoop", s.Logger())
nextnr := newNotifier()
s.readMu.Lock()
nr := s.readNotifier
s.readNotifier = nextnr
s.readMu.Unlock()
confirmedIndex, err := s.requestCurrentIndex(leaderChangedNotifier, requestId)
if isStopped(err) {
return
}
if err != nil {
nr.notify(err)
continue
}
trace.Step("read index received")
trace.AddField(traceutil.Field{Key: "readStateIndex", Value: confirmedIndex})
appliedIndex := s.getAppliedIndex()
trace.AddField(traceutil.Field{Key: "appliedIndex", Value: strconv.FormatUint(appliedIndex, 10)})
if appliedIndex < confirmedIndex {
select {
case <-s.applyWait.Wait(confirmedIndex):
case <-s.stopping:
return
}
}
// unblock all l-reads requested at indices before confirmedIndex
nr.notify(nil)
trace.Step("applied index is now lower than readState.Index")
trace.LogAllStepsIfLong(traceThreshold)
}
}
confirmedIndex, err := s.requestCurrentIndex(leaderChangedNotifier, requestId)
requestId每次都会生成,目的是区分每一次的读,因为raft在自旋,读取的操作也可能是并发,所以需要有唯一区分的identity
s.readwaitc,server中专门为读一致创建的channel,生成完requestId后,会block在这里,等待signal来触发读一致的后续逻辑
s.readNotifier 读一致通知的channel,appliedIndex >= confirmedIndex 时,通过这个channel通知调用者,读一致的逻辑已经完成
Request of read current index
func (s *EtcdServer) requestCurrentIndex(leaderChangedNotifier <-chan struct{}, requestId uint64) (uint64, error) {
err := s.sendReadIndex(requestId)
if err != nil {
return 0, err
}
lg := s.Logger()
errorTimer := time.NewTimer(s.Cfg.ReqTimeout())
defer errorTimer.Stop()
retryTimer := time.NewTimer(readIndexRetryTime)
defer retryTimer.Stop()
firstCommitInTermNotifier := s.FirstCommitInTermNotify()
for {
select {
case rs := <-s.r.readStateC:
requestIdBytes := uint64ToBigEndianBytes(requestId)
gotOwnResponse := bytes.Equal(rs.RequestCtx, requestIdBytes)
if !gotOwnResponse {
// a previous request might time out. now we should ignore the response of it and
// continue waiting for the response of the current requests.
responseId := uint64(0)
if len(rs.RequestCtx) == 8 {
responseId = binary.BigEndian.Uint64(rs.RequestCtx)
}
lg.Warn(
"ignored out-of-date read index response; local node read indexes queueing up and waiting to be in sync with leader",
zap.Uint64("sent-request-id", requestId),
zap.Uint64("received-request-id", responseId),
)
slowReadIndex.Inc()
continue
}
return rs.Index, nil
case <-leaderChangedNotifier:
readIndexFailed.Inc()
// return a retryable error.
return 0, ErrLeaderChanged
case <-firstCommitInTermNotifier:
firstCommitInTermNotifier = s.FirstCommitInTermNotify()
lg.Info("first commit in current term: resending ReadIndex request")
err := s.sendReadIndex(requestId)
if err != nil {
return 0, err
}
retryTimer.Reset(readIndexRetryTime)
continue
case <-retryTimer.C:
lg.Warn(
"waiting for ReadIndex response took too long, retrying",
zap.Uint64("sent-request-id", requestId),
zap.Duration("retry-timeout", readIndexRetryTime),
)
err := s.sendReadIndex(requestId)
if err != nil {
return 0, err
}
retryTimer.Reset(readIndexRetryTime)
continue
case <-errorTimer.C:
lg.Warn(
"timed out waiting for read index response (local node might have slow network)",
zap.Duration("timeout", s.Cfg.ReqTimeout()),
)
slowReadIndex.Inc()
return 0, ErrTimeout
case <-s.stopping:
return 0, ErrStopped
}
}
}
s.sendReadIndex(requestId),包裹requestId,将消息向raft模块传递
func (n *node) ReadIndex(ctx context.Context, rctx []byte) error {
return n.step(ctx, pb.Message{Type: pb.MsgReadIndex, Entries: []pb.Entry{{Data: rctx}}})
}
会将消息下放到raft模块中stepFunc来处理
如果是follower,会发送至leader
case pb.MsgReadIndex:
if r.lead == None {
r.logger.Infof("%x no leader at term %d; dropping index reading msg", r.id, r.Term)
return nil
}
m.To = r.lead
r.send(m)
如果是leader
case pb.MsgReadIndex:
// only one voting member (the leader) in the cluster
if r.prs.IsSingleton() {
if resp := r.responseToReadIndexReq(m, r.raftLog.committed); resp.To != None {
r.send(resp)
}
return nil
}
// Postpone read only request when this leader has not committed
// any log entry at its term.
if !r.committedEntryInCurrentTerm() {
r.pendingReadIndexMessages = append(r.pendingReadIndexMessages, m)
return nil
}
sendMsgReadIndexResponse(r, m)
return nil
sendMsgReadIndexResponse(r, m) 回复read index给请求者
func sendMsgReadIndexResponse(r *raft, m pb.Message) {
// thinking: use an internally defined context instead of the user given context.
// We can express this in terms of the term and index instead of a user-supplied value.
// This would allow multiple reads to piggyback on the same message.
switch r.readOnly.option {
// If more than the local vote is needed, go through a full broadcast.
case ReadOnlySafe:
r.readOnly.addRequest(r.raftLog.committed, m)
// The local node automatically acks the request.
r.readOnly.recvAck(r.id, m.Entries[0].Data)
r.bcastHeartbeatWithCtx(m.Entries[0].Data)
case ReadOnlyLeaseBased:
if resp := r.responseToReadIndexReq(m, r.raftLog.committed); resp.To != None {
r.send(resp)
}
}
}
可以得知,不论哪种情况,leader都会将 commited index 作为read index 回复给请求者
func (r *raft) responseToReadIndexReq(req pb.Message, readIndex uint64) pb.Message {
if req.From == None || req.From == r.id {
r.readStates = append(r.readStates, ReadState{
Index: readIndex,
RequestCtx: req.Entries[0].Data,
})
return pb.Message{}
}
return pb.Message{
Type: pb.MsgReadIndexResp,
To: req.From,
Index: readIndex,
Entries: req.Entries,
}
}
Response of read current index
当follower接收到 MsgReadIndexResp后
case pb.MsgReadIndexResp:
if len(m.Entries) != 1 {
r.logger.Errorf("%x invalid format of MsgReadIndexResp from %x, entries count: %d", r.id, m.From, len(m.Entries))
return nil
}
r.readStates = append(r.readStates, ReadState{Index: m.Index, RequestCtx: m.Entries[0].Data})
RequestCtx: m.Entries[0].Data} 这里放的就是 requestId
回到 request current index
for {
select {
case rs := <-s.r.readStateC:
requestIdBytes := uint64ToBigEndianBytes(requestId)
gotOwnResponse := bytes.Equal(rs.RequestCtx, requestIdBytes)
if !gotOwnResponse {
// a previous request might time out. now we should ignore the response of it and
// continue waiting for the response of the current requests.
responseId := uint64(0)
if len(rs.RequestCtx) == 8 {
responseId = binary.BigEndian.Uint64(rs.RequestCtx)
}
lg.Warn(
"ignored out-of-date read index response; local node read indexes queueing up and waiting to be in sync with leader",
zap.Uint64("sent-request-id", requestId),
zap.Uint64("received-request-id", responseId),
)
slowReadIndex.Inc()
continue
}
return rs.Index, nil
s.r.readStateC 是在 raft Ready里面传过来的
if len(rd.ReadStates) != 0 {
select {
case r.readStateC <- rd.ReadStates[len(rd.ReadStates)-1]:
case <-time.After(internalTimeout):
r.lg.Warn("timed out sending read state", zap.Duration("timeout", internalTimeout))
case <-r.stopped:
return
}
}
因为 read current index中的for循环,直到 requestId相等,返回readIndex至 linearizableReadLoop
再回到 linearizableReadLoop
for {
requestId := s.reqIDGen.Next()
leaderChangedNotifier := s.LeaderChangedNotify()
select {
case <-leaderChangedNotifier:
continue
case <-s.readwaitc:
case <-s.stopping:
return
}
//省略若干
if appliedIndex < confirmedIndex {
select {
case <-s.applyWait.Wait(confirmedIndex):
case <-s.stopping:
return
}
}
// unblock all l-reads requested at indices before confirmedIndex
nr.notify(nil)
}
s.applyWait.Wait(confirmedIndex)
leader虽然返回了read index,但还没有在本节点apply,一定要apply之后才会通知读一致完成
因为apply 才会存储,如果没有存储,如果集群出现宕机,仍然会有脏读的可能。
// unblock all l-reads requested at indices before confirmedIndex
nr.notify(nil)
通知读一致处理完成。
Summary
从follower读取leader当前的commited index,follower接收到后,直到apply完成,这几个步骤构成了避免的脏读的过程。
所以返回的数据是当前时间点内部一致的。
Etcd中linearizable read实现的更多相关文章
- etcd学习(7)-etcd中的线性一致性实现
线性一致性 CAP 什么是CAP CAP的权衡 AP wihtout C CA without P CP without A 线性一致性 etcd中如何实现线性一致性 线性一致性写 线性一致性读 1. ...
- 注册服务到etcd中
如上存放一些服务的key到etcd中,商品有两个,主要是为了负载均衡的key func NewService() *Service { config := clientv3.Config{ Endpo ...
- Etcd中Raft joint consensus的实现
Joint consensus 分为2个阶段,first switches to a transitional configuration we call joint consensus; once ...
- etcd中watch源码解读
etcd中watch的源码解析 前言 client端的代码 Watch newWatcherGrpcStream run newWatchClient serveSubstream server端的代 ...
- etcd学习(8)-etcd中Lease的续期
etcd中的Lease 前言 Lease Lease 整体架构 key 如何关联 Lease Lease的续期 过期 Lease 的删除 checkpoint 机制 总结 参考 etcd中的Lease ...
- etcd学习(9)-etcd中的存储实现
etcd中的存储实现 前言 V3和V2版本的对比 MVCC treeIndex 原理 MVCC 更新 key MVCC 查询 key MVCC 删除 key 压缩 周期性压缩 版本号压缩 boltdb ...
- Etcd中Raft日志复制的实现
Raft state of log commitIndex : A log entry is committed once the leader that created the entry has ...
- 如何查看k8s存在etcd中的数据(转)
原文 https://yq.aliyun.com/articles/561888 一直有这个冲动, 想知道kubernetes往etcd里放了哪些数据,是如何组织的. 能看到,才有把握知道它的实现和细 ...
- 部署etcd中使用ansible进行变量初始化
ansible-playbook 要进行默认变量的生产,可以依靠jinja 的模板渲染功能 看几个官方给出的例子 调用setup 中的变量 例如 setup 中的变量层级为 ansible_eth0_ ...
随机推荐
- SQLFlow使用中的注意事项--设置篇
SQLFlow 是用于追溯数据血缘关系的工具,它自诞生以来以帮助成千上万的工程师即用户解决了困扰许久的数据血缘梳理工作. 数据库中视图(View)的数据来自表(Table)或其他视图,视图中字段(Co ...
- MySQL中几种常见的日志
前言: 在 MySQL 系统中,有着诸多不同类型的日志.各种日志都有着自己的用途,通过分析日志,我们可以优化数据库性能,排除故障,甚至能够还原数据.这些不同类型的日志有助于我们更清晰的了解数据库,在日 ...
- Django(24)永久重定向和临时重定向
重定向 重定向分为永久重定向和临时重定向,在页面上体现的操作就是浏览器会从一个页面自动跳转到另外一个页面.比如用户访问了一个需要权限的页面,但是该用户当前并没有登录,因此我们应该给他重定向到登录页面. ...
- Spring context的refresh函数执行过程分析
今天看了一下Spring Boot的run函数运行过程,发现它调用了Context中的refresh函数.所以先分析一下Spring context的refresh过程,然后再分析Spring boo ...
- mysql unique key
create table b1(id int,name char unique)这样name字段就唯一了 或者create table b1(id int,name char,unique(id),u ...
- Flink使用二次聚合实现TopN计算-乱序数据
一.背景说明: 在上篇文章实现了TopN计算,但是碰到迟到数据则会无法在当前窗口计算,需要对其中的键控状态优化 Flink使用二次聚合实现TopN计算 本次需求是对数据进行统计,要求每隔5秒,输出最近 ...
- centos7 启动引导顺序
查看默认启动项 grub2-editenv list 查看启动项列表 awk -F\' '$1=="menuentry " {print $2}' /etc/grub2.cfg 设 ...
- [Linux] Linux命令行与Shell脚本编程大全 Part.2
进程 Linux是多用户系统,多个用户可以在不同地方通过网络连接到一个Linux系统上进行操作 w:显示登录人员信息 date:显示当前日期.时间和时区 up:从开机登录到现在经过的时间 load a ...
- swagger上的接口写入数据库
一.依赖 virtualenv -p python3.6 xx pip install scrapy pip install pymysql 二. 1.创建项目和spider1 scrapy star ...
- openstack总结复习
一.云计算概念 1.云计算是一种按使用量付费的模式,这种模式提供可用的.便捷的.按需的网络访问, 通过互联网进入可配置的计算资源共享池(资源包括网络,计算,存储,应用软件,服务) 2.云计算所包含的几 ...