Hadoop组件
---------Hive--------------------------zooKeeper-------------------------------kafka-----------------------------------sqoop-------------------------------flume-------------------------------------------------------------------------------------Hbase-----------------------------------------------------------------------
Your present circumstances don't determine where you can go; they merely determine where you start.
Hive
https://hive.apache.org/
Hive:由Facebook开源用于解决海量结构化日志的数据统计。
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
本质:将HQL转化成Map Reduce程序
=========Hive处理的数据储存在HDFS
Hive分析数据底层的实现是Map Reduce
执行程序运行在YARN上
Zookeeper
https://zookeeper.apache.org/
Zookeeper:是一个开源的分布式的,为分布式应用提供协调服务的Apache项目。版本:zookeeper-3.4.10
Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经
在Zookeeper上注册的那些观察者做出相应的反应,从而实现集群中类似Master/Slave管理模式
ZooKeeper = 文件系统 + 通知机制
提供的服务:分布式消息同步和协调机制、
服务器节点动态上下线、
统一配置管理、
负载均衡、
集群管理等。
每个znode默认能够存储1MB的数据,znode是其路径的唯一标识
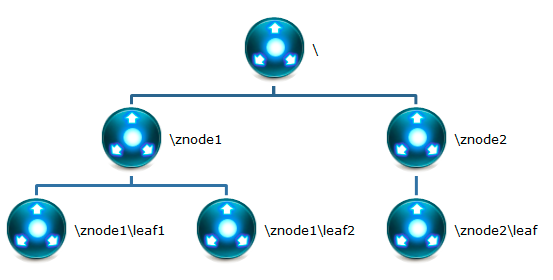
节点类型:
ephemeral(短暂):客户端和服务器断开连接后,创建的节点自己删除
persistent(持久):客户端和服务器断开连接后,创建的表还在
特点
ZooKeeper是一个leader,多个follower组成的集群
集群中只要半数以上的节点存活,zooKeeper集群就能正常服务
全局数据一致:每个服务端保存一份相同的数据副本,客户端 无论连接到哪个server,数据都是一致的
数据更新原子性,一次数据更新要么成功,要么失败
实时性,在一定时间范围内,client能读到最新数据。
Kafka
https://kafka.apache.org/
在流式计算中,Kafka一般用来缓存数据,Storm通过消费Kafka的数据进行计算。
1)Apache Kafka是一个开源消息系统,由Scala写成。是由Apache软件基金会开发的一个开源消息系统项目。
2)Kafka最初是由LinkedIn公司开发,并于2011年初开源。2012年10月从Apache Incubator毕业。该项目的目标是为处理实时数据提供一个统一、高通量、低等待的平台。
3)Kafka是一个分布式消息队列。Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。
4)无论是kafka集群,还是producer和consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性。
kafka的特性:
高吞吐量,低延迟:kafka每秒可以处理几十万条消息,它的延迟最低时只有几毫秒。每个 topic 可以分多个partition,
consumer group对 partition 进行consume操作。
可扩展性:卡夫卡集群支持热扩展
持久性,可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失。
容错性:允许集群中节点失败(若副本数为 3 ,则允许 2个节点毁坏)
高并发:支持数千个客户端同时读写
1.2 消息队列内部实现原理
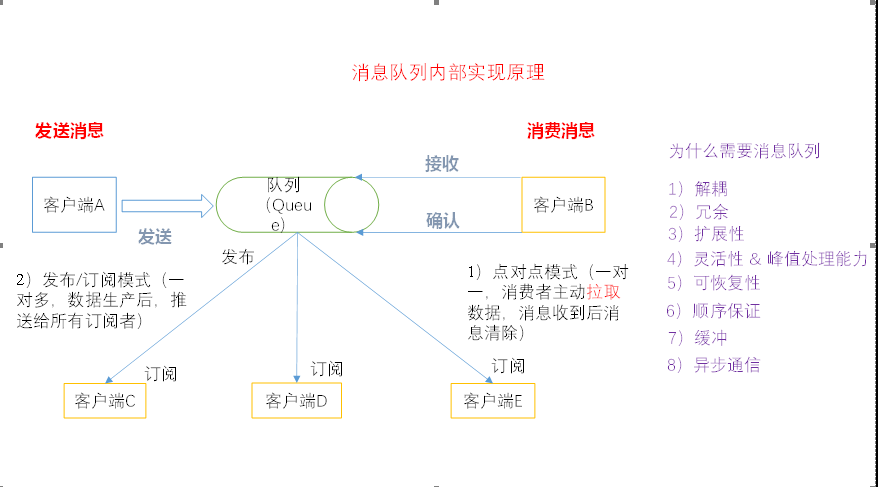
1):点对点模式式(一对一,消费者主动拉取数据,消息收到后消息清除)
点对点模型通常是一个基于拉取或者轮询的消息传送模型,
这种模型从队列中请求信息,而不是将消息推送到客户端。这个模型的特点是发送到队列的消息被一个且只有一个接受者接受处理,即使有多个监听者也是如此。
2):
发布/订阅模式(一对多,数据生产后,推送给所有订阅者)
发布订阅模型则是一个基于推送的消息传送模型。发布订阅模型可以有多种不同的订阅者,临时订阅者只在主动监听主题时才接收消息,而持久订阅者则监听主题的所有消息,即使当前订阅者不可用,处于离线状态。
1.3 为什么需要消息队列
1)解耦:
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
2)冗余:
消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。许多消息队列所采用的"插入-获取-删除"范式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。
3)扩展性:
因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要另外增加处理过程即可。
4)灵活性 & 峰值处理能力:
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
5)可恢复性:
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
6)顺序保证:
在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。(Kafka保证一个Partition内的消息的有序性)
7)缓冲:
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
8)异步通信:
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
SQOOP
一、什么是Sqoop
Sqoop是一个在结构化数据和Hadoop之间进行批量数据迁移的工具,结构化数据可以是Mysql、Oracle等RDBMS(关系型数据库) 。Sqoop底层用MapReduce程序实现抽取、转换、加载,MapReduce天生的特性保证了并行化和高容错率,而且相比Kettle等传统ETL
【ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过萃取(extract)、转置(transform)、加载(load)至目的端的过程。ETL一词较常用在数据仓库,但其对象并不限于数据仓库。】
工具,任务跑在Hadoop集群上,减少了ETL服务器资源的使用情况。在特定场景下,抽取过程会有很大的性能提升。
如果要用Sqoop,必须正确安装并配置Hadoop,因依赖于本地的hadoop环境启动MR程序;mysql、oracle等数据库的JDBC
【JDBC(Java Data Base Connectivity,java数据库连接)是一种用于执行SQL语句的Java API,可以为多种关系】
驱动也要放到Sqoop的lib目录下。本文针对的是Sqoop1,不涉及到Sqoop2,两者有大区别,感兴趣的读者可以看下官网说明。
Hadoop组件的更多相关文章
- [hadoop in Action] 第3章 Hadoop组件
管理HDFS中的文件 分析MapReduce框架中的组件 读写输入输出数据 1.HDFS文件操作 [命令行方式] Hadoop的文件命令采取的形式为: hadoop fs -cmd < ...
- Hadoop组件构成
Hadoop平台重要组件: 1.ZooKeeper 一个分布式应用程序协调服务. 包含简单的原语集.实现统一命名服务.配置管理.分布式锁服务.集群管理等功能. 2.Cascading 架构在 Hado ...
- Hadoop组件之-HDFS(HA实现细节)
NameNode 高可用整体架构概述 在 Hadoop 1.0 时代,Hadoop 的两大核心组件 HDFS NameNode 和 JobTracker 都存在着单点问题,这其中以 NameNode ...
- hadoop组件启动和关闭命令
一.启动相关组件之前 一般安装完hadoop之后需要格式化一遍hdfs: hdfs namenode -format 然后再进行其他组件的启动,hadoop相关组件都是用位于...hadoop/sbi ...
- hadoop组件及其作用
1.hadoop有三个主要的核心组件:HDFS(分布式文件存储).MAPREDUCE(分布式的计算).YARN(资源调度),现在云计算包括大数据和虚拟化进行支撑. 在HADOOP(hdfs.MAPRE ...
- 搭建maven开发环境测试Hadoop组件HDFS文件系统的一些命令
1.PC已经安装Eclipse Software,测试平台windows10及Centos6.8虚拟机 2.新建maven project 3.打开pom.xml,maven工程项目的pom文件加载以 ...
- hadoop组件概念理解
一.HADOOP 二.HIVE 三.SQOOP 1.来由和作用 sqoop由一些封装好的MR程序的jar包构成,后演变成框架,但sqoop只有map任务没有reduce任务. 用于 hdfs.hive ...
- 10、Hadoop组件启动方式和SSH无密码登陆
启动方式 一.各个组件逐一启动 hdfs: hadoop-daemon.sh start|stop namenode|datanode|secondnode yarn: yarn-demon.sh s ...
- Hadoop组件详解(随缘摸虾)
1.1. Hadoop组成: Hadoop = hdfs(存储) + mapreduce(计算) + yarn(资源协调) + common(工具包) + ozone(对象存储) + submarin ...
随机推荐
- iOS开发常用第三库
字典转模型 1.(MJExtension) https://github.com/CoderMJLee/MJExtension 2.(YYModel) https://github.com/ibire ...
- react-native项目中集成react-native-camera插件
1. 安装 yarn add react-native-camera 2. 手动关联 (1)在AndroidManifest.xml中添加权限配置 <uses-permission androi ...
- UOJ#395. 【NOI2018】你的名字 字符串,SAM,线段树合并
原文链接https://www.cnblogs.com/zhouzhendong/p/UOJ395.html 题解 记得同步赛的时候这题我爆0了,最暴力的暴力都没调出来. 首先我们看看 68 分怎么做 ...
- CodeForces 959E Mahmoud and Ehab and the xor-MST (MST+找规律)
<题目链接> 题目大意: 给定一个数n,代表有一个0~n-1的完全图,该图中所有边的边权为两端点的异或值,求这个图的MST的值. 解题分析: 数据较大,$10^{12}$个点的完全图,然后 ...
- Physics Experiment 弹性碰撞 [POJ3684]
题意 有一个竖直的管子内有n个小球,小球的半径为r,最下面的小球距离地面h高度,让小球每隔一秒自由下落一个,小球与地面,小球与小球之间可视为弹性碰撞,让求T时间后这些小球的分布 Input The f ...
- Face The Right Way [POJ3276] [开关问题]
题意: 有n头奶牛排成一排,有的朝前(F)有的朝后(B),现在你可以使k头奶牛一次性翻转朝向(n>=k>=1),问你最少的翻转次数和此时对应的k值. Input Line 1: A sin ...
- [TopCoder]棍子
题目描述 你有一堆棍子.每个木棒的长度是一个正整数. 你想要一组棍子所有的棍子都有相同的长度.您可以通过执行零个或多个步骤来更改当前集合.每个步骤必须如下所示: 你选择一根棍子.所选棒的长度必须至少为 ...
- 操作mysql(import pymysql模块)
pymysql模块 import pymysql #1.连上数据库.账号.密码.ip.端口号.数据库 #2.建立游标 #3.执行sql #4.获取结果 #5.关闭游标 #6.连接关闭 #charest ...
- Cmake知识----编写CMakeLists.txt文件编译C/C++程序
1.CMake编译原理 CMake是一种跨平台编译工具,比make更为高级,使用起来要方便得多.CMake主要是编写CMakeLists.txt文件,然后用cmake命令将CMakeLists.txt ...
- StringBuild使用与原理
StringBuild的使用: 1.创建: StringBuilder sb=new StringBuilder(); StringBuilder sb=new StringBuilder(200); ...