AI佳作解读系列(一)——深度学习模型训练痛点及解决方法
1 模型训练基本步骤
进入了AI领域,学习了手写字识别等几个demo后,就会发现深度学习模型训练是十分关键和有挑战性的。选定了网络结构后,深度学习训练过程基本大同小异,一般分为如下几个步骤
- 定义算法公式,也就是神经网络的前向算法。我们一般使用现成的网络,如inceptionV4,mobilenet等。
- 定义loss,选择优化器,来让loss最小
- 对数据进行迭代训练,使loss到达最小
- 在测试集或者验证集上对准确率进行评估
下面我们来看深度学习模型训练中遇到的难点及如何解决
2 模型训练难点及解决方法
2.1 收敛速度慢
深度学习其实就是一个反复调整模型参数的过程,得力于GPU等硬件性能的提升,使得复杂的深度学习训练成为了可能。收敛速度过慢,训练时间过长,一方面使得相同总训练时间内的迭代次数变少,从而影响准确率,另一方面使得训练次数变少,从而减少了尝试不同超参数的机会。因此,加快收敛速度是一大痛点。那么怎么解决它呢?
2.1.1 设置合理的初始化权重w和偏置b
深度学习通过前向计算和反向传播,不断调整参数,来提取最优特征,以达到预测的目的。其中调整的参数就是weight和bias,简写为w和b。根据奥卡姆剃刀法则,模型越简单越好,我们以线性函数这种最简单的表达式来提取特征,也就是
f(x) = w * x + b
深度学习训练时几乎所有的工作量都是来求解神经网络中的w和b。模型训练本质上就是调整w和b的过程,如果将他们初始化为一个合理的值,那么就能够加快收敛速度。怎么初始化w和b呢?
我们一般使用截断的正态分布(也叫高斯分布)来初始化w。如下
# 权重weight,标准差0.1。truncated_normal截断的正态分布来初始化weight。权重初始化很有讲究的,会决定学习的快慢
def weight_variable(shape, vname):
initial = tf.truncated_normal(shape, stddev=0.1, name=vname)
return tf.Variable(initial)tf.truncated_normal定义如下
tf.truncated_normal(
shape, # 正态分布输出数据结构,1维tensor
mean=0.0, # 平均值,默认为0.我们一般取默认值0
stddev=1.0, # 标准差
dtype=tf.float32, # 输出数据类型
seed=None, # 随机分布都会有一个seed来决定分布
name=None
)什么叫截断的正态分布呢,看下图就明白了
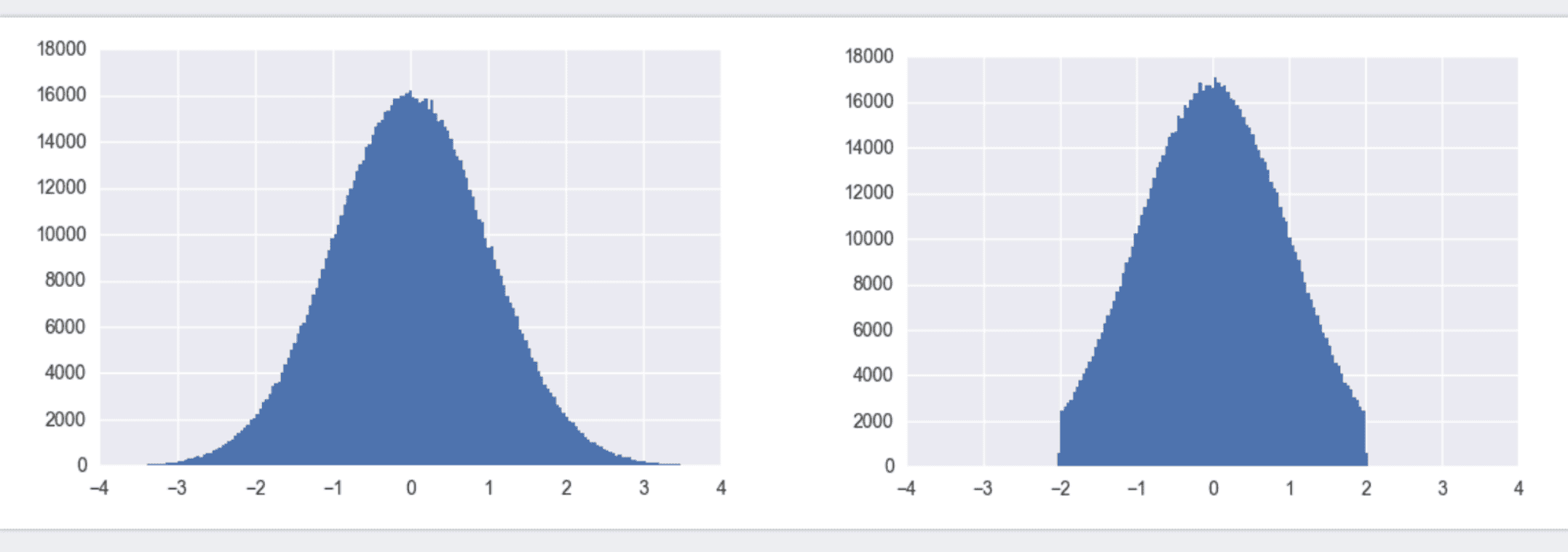
左图为标准正态分布,也叫高斯分布,利用TensorFlow中的tf.random_normal()即可得到x取值范围负无穷到正无穷内的值。所有的y值加起来概率为1。初始化w时,我们没必要将w初始化为很大或很小的数。故更倾向于使用截断正态分布,如右图。它和标准正态分布的区别在于,限制了x取值必须在[-2 x stddev, 2 x stddev]之间。
b由于是加和关系,对收敛速度影响不大。我们一般将它初始化为0,如下。
# 偏置量bias,初始化为0,偏置可直接使用常量初始化
def bias_variable(shape, vname):
initial = tf.constant(0, shape=shape, name=vname)
return tf.Variable(initial)2.1.2 优化学习率
模型训练就是不断尝试和调整不同的w和b,那么每次调整的幅度是多少呢,这个就是学习率。w和b是在一定范围内调整的,那么增大学习率不就减少了迭代次数,也就加快了训练速度了吗?路虽长,步子迈大点不就行了吗?非也,步子迈大了可是会扯到蛋的!深度学习中也是如此,学习率太小,会增加迭代次数,加大训练时间。但学习率太大,容易越过局部最优点,降低准确率。
那有没有两全的解决方法呢,有!我们可以一开始学习率大一些,从而加速收敛。训练后期学习率小一点,从而稳定的落入局部最优解。使用Adam,Adagrad等自适应优化算法,就可以实现学习率的自适应调整,从而保证准确率的同时加快收敛速度。
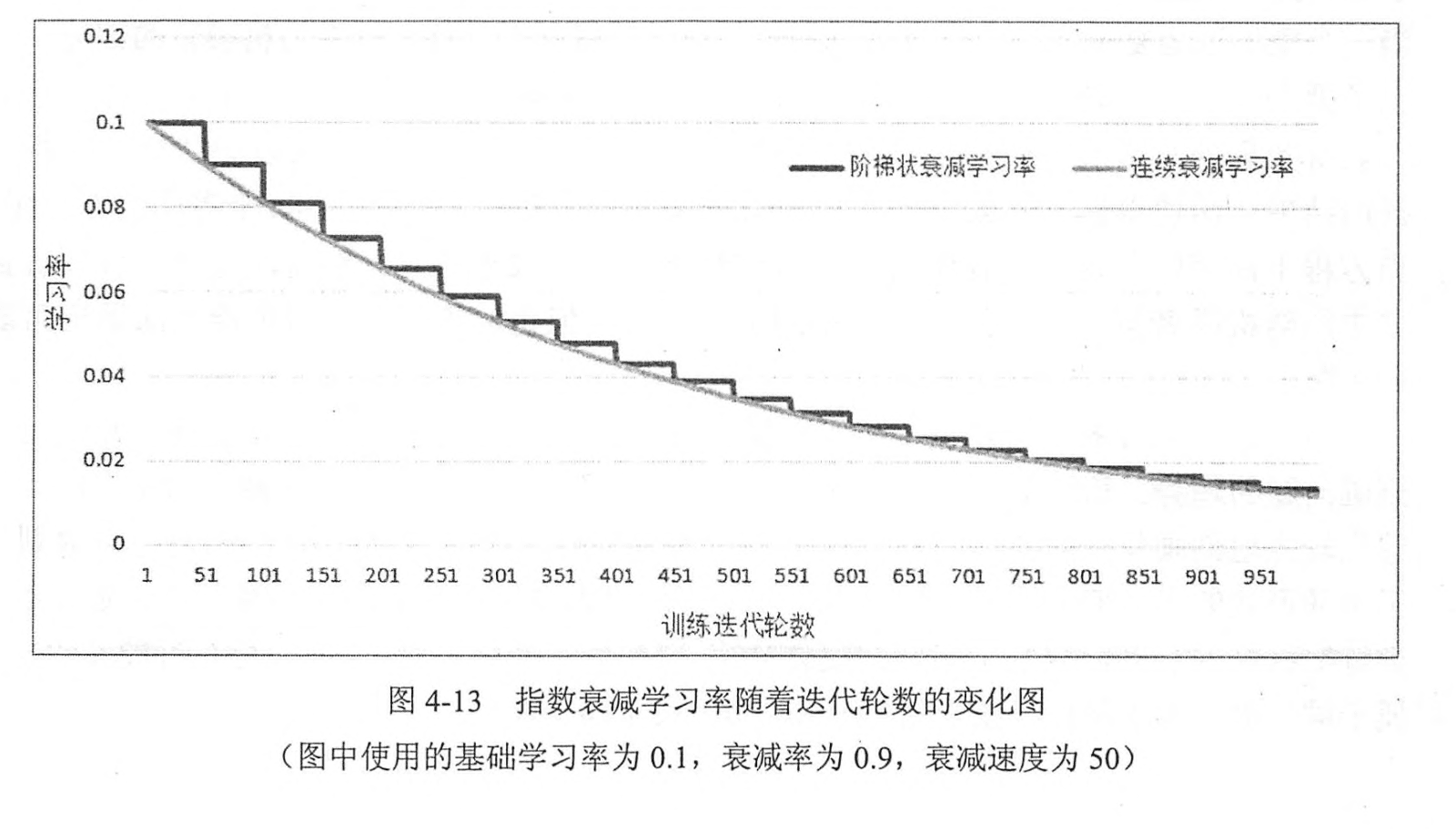
如上图所示,随着迭代次数的增加,学习率从0.1逐步衰减为0.02以下。
2.1.3 网络节点输入值正则化 batch normalization
神经网络训练时,每一层的输入分布都在变化。不论输入值大还是小,我们的学习率都是相同的,这显然是很浪费效率的。而且当输入值很小时,为了保证对它的精细调整,学习率不能设置太大。那有没有办法让输入值标准化得落到某一个范围内,比如[0, 1]之间呢,这样我们就再也不必为太小的输入值而发愁了。
办法当然是有的,那就是正则化!由于我们学习的是输入的特征分布,而不是它的绝对值,故可以对每一个mini-batch数据内部进行标准化,使他们规范化到[0, 1]内。这就是Batch Normalization,简称BN。由大名鼎鼎的inception V2提出。它在每个卷积层后,使用一个BN层,从而使得学习率可以设定为一个较大的值。使用了BN的inceptionV2,只需要以前的1/14的迭代次数就可以达到之前的准确率,大大加快了收敛速度。
2.1.4 采用更先进的网络结构,减少参数量
训练速度慢,归根结底还是网络结构的参数量过多导致的。减少参数量,可以大大加快收敛速度。采用先进的网络结构,可以用更少的参数量达到更高的精度。如inceptionV1参数量仅仅为500万,是AlexNet的1/12, 但top-5准确率却提高了一倍多。如何使用较少的参数量达到更高的精度,一直是神经网络结构研究中的难点。目前大致有如下几种方式
- 使用小卷积核来代替大卷积核。VGGNet全部使用3x3的小卷积核,来代替AlexNet中11x11和5x5等大卷积核。小卷积核虽然参数量较少,但也会带来特征面积捕获过小的问题。inception net认为越往后的卷积层,应该捕获更多更高阶的抽象特征。因此它在靠后的卷积层中使用的5x5等大面积的卷积核的比率较高,而在前面几层卷积中,更多使用的是1x1和3x3的卷积核。
- 使用两个串联小卷积核来代替一个大卷积核。inceptionV2中创造性的提出了两个3x3的卷积核代替一个5x5的卷积核。在效果相同的情况下,参数量仅为原先的3x3x2 / 5x5 = 18/25
- 1x1卷积核的使用。1x1的卷积核可以说是性价比最高的卷积了,没有之一。它在参数量为1的情况下,同样能够提供线性变换,relu激活,输入输出channel变换等功能。VGGNet创造性的提出了1x1的卷积核
- 非对称卷积核的使用。inceptionV3中将一个7x7的卷积拆分成了一个1x7和一个7x1, 卷积效果相同的情况下,大大减少了参数量,同时还提高了卷积的多样性。
- depthwise卷积的使用。mobileNet中将一个3x3的卷积拆分成了串联的一个3x3 depthwise卷积和一个1x1正常卷积。对于输入channel为M,输出为N的卷积,正常情况下,每个输出channel均需要M个卷积核对输入的每个channel进行卷积,并叠加。也就是需要MxN个卷积核。而在depthwise卷积中,输出channel和输入相同,每个输入channel仅需要一个卷积核。而将channel变换的工作交给了1x1的卷积。这个方法在参数量减少到之前1/9的情况下,精度仍然能达到80%。
- 全局平均池化代替全连接层。这个才是大杀器!AlexNet和VGGNet中,全连接层几乎占据了90%的参数量。inceptionV1创造性的使用全局平均池化来代替最后的全连接层,使得其在网络结构更深的情况下(22层,AlexNet仅8层),参数量只有500万,仅为AlexNet的1/12
网络结构的推陈出新,先进设计思想的不断提出,使得减少参数量的同时提高准确度变为了现实。
2.1.5 使用GPU并行计算
深度学习模型训练,基本由卷积计算和矩阵乘法构成,他们都很适合并行计算。使用多块GPU并行加速已经成为了深度学习的主流,可以大大加快收敛速度。要达到相同的精度,50块GPU需要的时间仅为10块的1/4左右。当前Google早已开始了TPU这种专门用于深度学习的Asic芯片的研究,国内的寒武纪等公司也在大张旗鼓的研究专用于AI的芯片。AI芯片的前景也是十分广阔的。
2.2 线性模型的局限性
根据奥卡姆剃刀法则,我们使用了最简单的线性模型,也就是wx+b,来表征了神经网络。线性模型的特点是,任意线性模型的组合仍然是线性模型。不论我们采用如何复杂的神经网络,它仍然是一个线性模型。然而线性模型能够解决的问题毕竟是有限的,所以必须在神经网络中增加一些非线性元素。
2.2.1 激活函数的使用
在每个卷积后,加入一个激活函数,已经是通用的做法,相信大家都知道。激活函数,如relu,tanh,sigmod都是非线性函数,一方面可以增加模型的非线性元素,另一方面可以降低梯度弥散问题(我们后面详细讲解)。目前使用较多的就是relu函数。他模拟了生物学上的阈值响应机制,利用人脑只对大于某个值的信号才产生响应的机制,提出了单侧抑制的理念。它的表达式很简单,f(x)=max(0,x)。当x>0时,y=x, x<0时,y=0. 如下图所示。

相比于tanh和sigmod,relu的优点有:
- 计算速度快,容易收敛。relu就是一个取max的函数,没有复杂的运算,故计算速度很快。相比于tanh,收敛速度可加快6倍
- 梯度不会大幅缩小。x>0时,relu的梯度为1(梯度还不懂是啥意思的同学最好翻下数学书,梯度简单理解就是偏导数),故相比sigmod这种x稍微远离0,梯度就会大幅减小的函数,不会使得梯度缩小,从而引发多层传播后的梯度弥散问题。
2.2.2 两个小卷积核的叠加代替一个大卷积核
激活函数可是一个增加非线性的大法宝,但我们一般只能在卷积完之后再使用它。那怎么增加它的使用场景呢?增加卷积层不就行了吗。inception V2创造性的提出了用两个3x3的卷积核代替一个5x5的卷积核。每次卷积后,都使用一次relu非线性激活。如下图。

2.2.3 1x1小卷积核的使用
1x1的卷积核应该是性价比最高的卷积,它在参数量为1的情况下,同样能够提供线性变换,relu激活,输入输出channel变换等功能。inceptionV1利用Network in Network的思想,提出了inception module这一结构,它在每个并行分支的最前面,使用了一个1x1的卷积,卷积后紧跟一个relu激活。从而大大增加了relu的使用率。从而提高了模型的非线性特征。
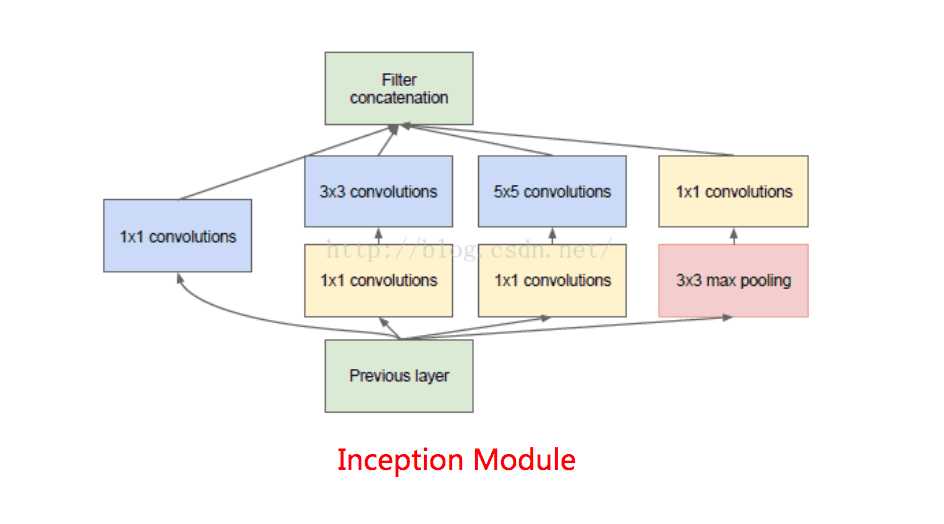
2.3 过拟合问题
过拟合在机器学习中广泛存在,指的是经过一定次数的迭代后,模型准确度在训练集上越来越好,但在测试集上却越来越差。究其原因,就是模型学习了太多无关特征,将这些特征认为是目标所应该具备的特征。如下图
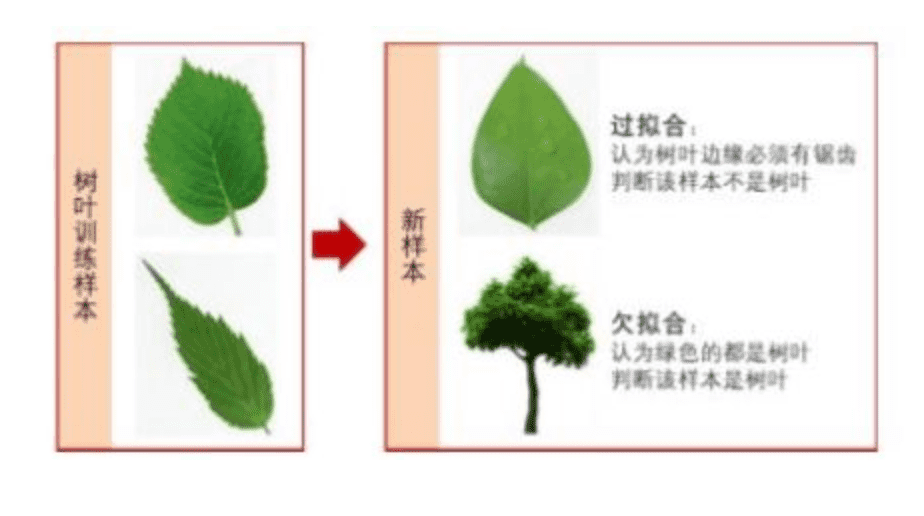
如上图所示,树叶训练样本中边缘带有锯齿,模型学习了锯齿这一特征,认为树叶必须带有锯齿,从而判定右侧的不带锯齿的树叶不是树叶。这就是典型的过拟合问题。神经网络中,因为参数众多,经常出现参数比输入样本数据还多的情况,这就导致很容易出现模型只记住了训练集特征的情况。我们有两个思路来解决这个问题。一是增大样本量,另外就是减少特征量。
2.3.1 输入增强,增大样本量
收集更多且更全的样本,能有效降低过拟合。但寻找样本本来就是一件很费力的事情,我们到哪儿去寻找更多更全的样本呢。素材整理和数据获取成为了深度学习的一大瓶颈,否则再牛逼的神经网络结构,也会称为无米之炊。这也是当前迁移学习变得比较火热的一大原因(这是后话,就不详细展开了)。那我们有没有办法简单快捷的增加样本量呢?
答案是有的,可以使用输入增强方法。对样本进行旋转,裁剪,加入随机噪声等方式,可以大大增加样本数量和泛化性。目前TensorFlow就提供了大量方法进行数据增强,大大方便了我们增加样本数量。
2.3.2 dropout,减少特征量
使用dropout,将神经网络某一层的输出节点数据随机丢弃,从而减少特征量。这其实相当于创造了很多新的随机样本。我们可以理解为这是对特征的一次采样。一般在神经网络的全连接层使用dropout。
2.4 梯度弥散, 无法使用更深的网络
深度学习利用正向传播来提取特征,同时利用反向传播来调整参数。反向传播中梯度值逐渐减小,神经网络层数较多时,传播到前面几层时,梯度接近于0,无法对参数做出指导性调整了,此时基本起不到训练作用。这就称为梯度弥散。梯度弥散使得模型网络深度不能太大,但我们都知道网络越深,提取的特征越高阶,泛化性越好。因此优化梯度弥散问题就很重要了
2.4.1 relu代替sigmoid激活函数
sigmoid函数值在[0,1],ReLU函数值在[0,+无穷]。relu函数,x>0时的导数为1, 而sigmoid函数,当x稍微远离0,梯度就会大幅减小,几乎接近于0,所以在反向传播中无法指导参数更新。
2.4.2 残差网络
大名鼎鼎的resNet将一部分输入值不经过正向传播网络,而直接作用到输出中。这样可以提高原始信息的完整性了,从而在反向传播中,可以指导前面几层的参数的调整了。如下图所示。
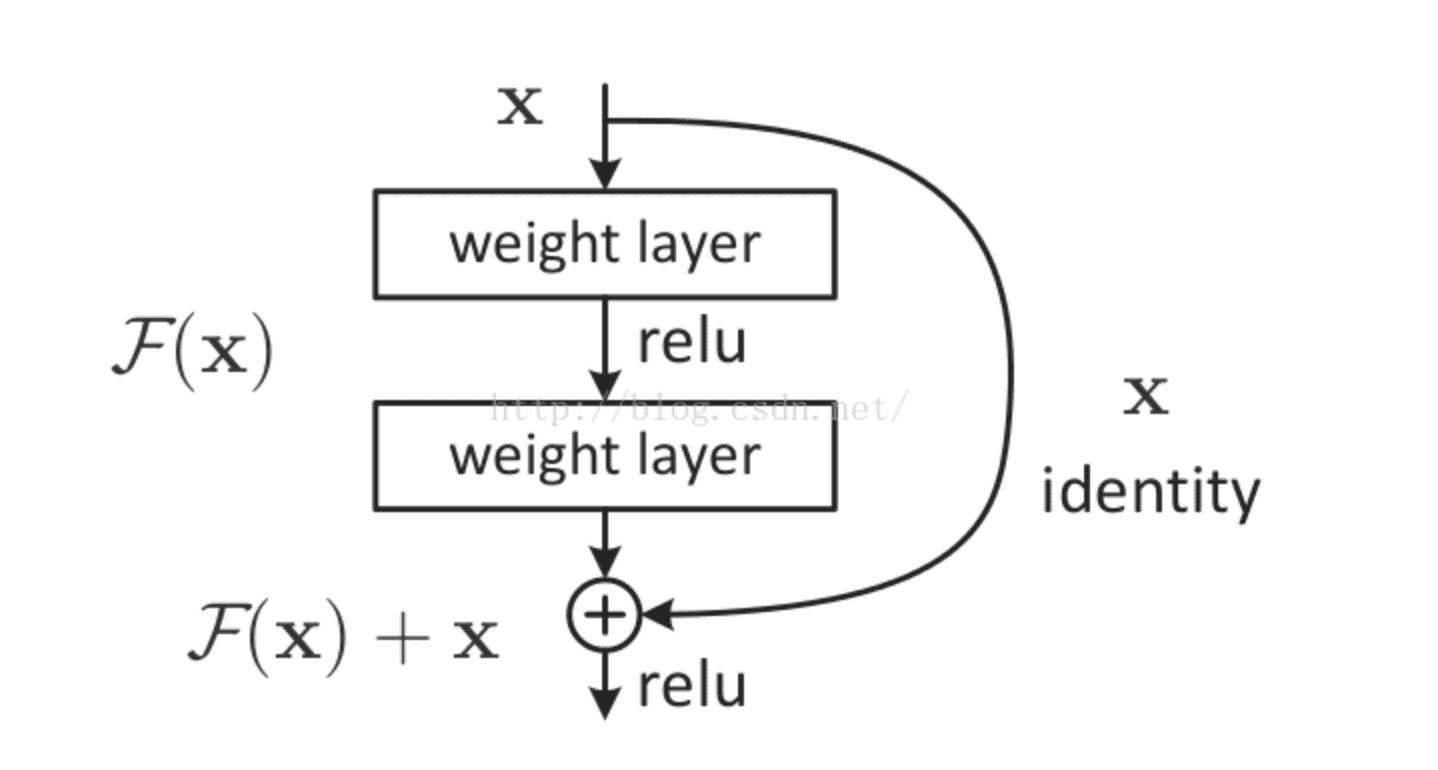
使用了残差网络的resNet,将网络深度提高到了152层,大大提高了模型的泛化性,从而提高了预测准确率,并一举问鼎当年的imageNet冠军!
3 总结
深度学习模型训练是一个很费时间,但也很有技巧的过程。模型训练中有梯度弥散,过拟合等各种痛点,正是为了解决这些问题,不断涌现出了各种设计精巧的网络结构。学习时,我们不仅要学习网络结构的设计方式,还要掌握它们的设计思想,了解它们是为了解决哪些问题而产生的,以及准确率和性能为何能够得到提升。
本文主体内容参考链接:https://yq.aliyun.com/articles/598429?spm=a2c4e.11153940.blogrightarea598428.36.640a783bV593ki
AI佳作解读系列(一)——深度学习模型训练痛点及解决方法的更多相关文章
- AI佳作解读系列(三)——深度学习中的合成数据研究
Below are some investigation resources for synthetic datasets: 1. Synthetic datasets vs. real images ...
- AI佳作解读系列(二)——目标检测AI算法集杂谈:R-CNN,faster R-CNN,yolo,SSD,yoloV2,yoloV3
1 引言 深度学习目前已经应用到了各个领域,应用场景大体分为三类:物体识别,目标检测,自然语言处理.本文着重与分析目标检测领域的深度学习方法,对其中的经典模型框架进行深入分析. 目标检测可以理解为是物 ...
- AI佳作解读系列(六) - 生成对抗网络(GAN)综述精华
注:本文来自机器之心的PaperWeekly系列:万字综述之生成对抗网络(GAN),如有侵权,请联系删除,谢谢! 前阵子学习 GAN 的过程发现现在的 GAN 综述文章大都是 2016 年 Ian G ...
- AI佳作解读系列(五) - 目标检测二十年技术综述
计算机视觉中的目标检测,因其在真实世界的大量应用需求,比如自动驾驶.视频监控.机器人视觉等,而被研究学者广泛关注. 上周四,arXiv新出一篇目标检测文献<Object Detection ...
- AI佳作解读系列(四)——数据增强篇
前言 在深度学习的应用过程中,数据的重要性不言而喻.继上篇介绍了数据合成(个人认为其在某种程度上可被看成一种数据增强方法)这个主题后,本篇聚焦于数据增强来介绍几篇杰作! (1)NanoNets : H ...
- 深度学习模型训练技巧 Tips for Deep Learning
一.深度学习建模与调试流程 先看训练集上的结果怎么样(有些机器学习模型没必要这么做,比如决策树.KNN.Adaboost 啥的,理论上在训练集上一定能做到完全正确,没啥好检查的) Deep Learn ...
- 深度学习模型调优方法(Deep Learning学习记录)
深度学习模型的调优,首先需要对各方面进行评估,主要包括定义函数.模型在训练集和测试集拟合效果.交叉验证.激活函数和优化算法的选择等. 那如何对我们自己的模型进行判断呢?——通过模型训练跑代码,我们可以 ...
- 让AI简单且强大:深度学习引擎OneFlow技术实践
本文内容节选自由msup主办的第七届TOP100summit,北京一流科技有限公司首席科学家袁进辉(老师木)分享的<让AI简单且强大:深度学习引擎OneFlow背后的技术实践>实录. 北京 ...
- 用 Java 训练深度学习模型,原来可以这么简单!
本文适合有 Java 基础的人群 作者:DJL-Keerthan&Lanking HelloGitHub 推出的<讲解开源项目> 系列.这一期是由亚马逊工程师:Keerthan V ...
随机推荐
- [MySQL] mysql的事务隔离和幻读和死锁问题
1.系统要通过严格的ACID测试,ACID表示原子性/一致性/隔离性/持久性原子性:一个事务必须被视为一个不可分割的最小工作单元一致性:数据库总是从一个一致性的状态转换到另外一个一致性的状态隔离性:通 ...
- WEB前端学习代码片段记录
1.JS设计模式片段 Function.prototype.addMethod = function (name,fn) { this.prototype[name] = fn; return thi ...
- Dynamics 365创建用户提示:您正在尝试使用已由其他用户使用的域登录来创建用户。如何解决。
摘要: 本人微信公众号:微软动态CRM专家罗勇 ,回复287或者20181128可方便获取本文,同时可以在第一间得到我发布的最新博文信息,follow me!我的网站是 www.luoyong.me ...
- 免费开源ERP Odoo实施指南 连载二:POSTGRESQL概述
PostgreSQL是Odoo支持的数据库.PostgreSQL是起源于大学的一个历史很长的开源数据库系统.包括美国航天局NASA.德国证券交易中心.中国的平安.腾讯的微信支付.阿里巴巴的阿里云都在用 ...
- pip 使用豆瓣源
pip 使用豆瓣源 由于pip 默认使用Python的官方源pypi.python.org/pypi,导致我们经常使用pip装包时速度过慢或者无法安装(请求超时)等问题, 所以国内用户建议使用pip ...
- Android 反射获取一个方法(方法的参数不一样)
private Method forget; private Method connect_netID; private Method connect_wifiConfig; private Meth ...
- Android为TV端助力context转换类型
- Visual Studio 2019 RC入门
介绍 在本文中,让我们看看如何开始使用Visual Studio 2019 RC.Microsoft现已发布Visual Studio Release Candidate,现在可以下载了.最初,Mic ...
- dotNet core 应用部署至 centos(超详解附截图)
文章来源:公众号-智能化IT系统. 需要安装的插件以及支撑架构 1.dotnetSDK dotnet 相关命令是属于 .NET Core command-line (CLI) 的一部分,Microso ...
- c/c++ 重载运算符 类型转换运算符
重载运算符 类型转换运算符 问题:能不能把一个类型A的对象a,转换成另一个类型B的对象b呢?? 是可以的.这就必须要用类型A的类型转换运算符(conversion operator) 下面的opera ...