谱聚类(Spectral Clustring)原理
谱聚类(spectral clustering)是广泛使用的聚类算法,比起传统的K-Means算法,谱聚类对数据分布的适应性更强,聚类效果也很优秀,同时聚类的计算量也小很多,更加难能可贵的是实现起来也不复杂。在处理实际的聚类问题时,个人认为谱聚类是应该首先考虑的几种算法之一。下面我们就对谱聚类的算法原理做一个总结。
1. 谱聚类概述
谱聚类是从图论中演化出来的算法,后来在聚类中得到了广泛的应用。它的主要思想是把所有的数据看做空间中的点,这些点之间可以用边连接起来。距离较远的两个点之间的边权重值较低,而距离较近的两个点之间的边权重值较高,通过对所有数据点组成的图进行切图,让切图后不同的子图间边权重和尽可能的低,而子图内的边权重和尽可能的高,从而达到聚类的目的。
乍一看,这个算法原理的确简单,但是要完全理解这个算法的话,需要对图论中的无向图,线性代数和矩阵分析都有一定的了解。下面我们就从这些需要的基础知识开始,一步步学习谱聚类。
2. 谱聚类基础之一:无向权重图
由于谱聚类是基于图论的,因此首先温习下图的概念。对于一个图G,一般用点的集合V和边的集合E来描述。即为G(V,E)。其中V即为数据集里面所有的点(v1,v2,...vn)。对于V中的任意两个点,可以有边连接,也可以没有边连接。我们定义权重wij为点vi和点vj之间的权重。由于我们是无向图,所以wij=wji。
对于有边连接的两个点vi和vj,wij>0,对于没有边连接的两个点vi和vj,wij=0。对于图中的任意一个点vi,它的度di定义为和它相连的所有边的权重之和,即:

利用每个点度的定义,我们可以得到一个nxn的度矩阵D,它是一个对角矩阵,只有主对角线有值,对应第i行的第i个点的度数,定义如下:
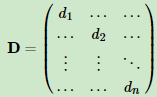
利用所有点之间的权重值,我们可以得到图的邻接矩阵W,它也是一个nxn的矩阵,第i行的第j个值对应我们的权重wij。
除此之外,对于点集V的的一个子集A⊂V,我们定义:
|A|:=子集A中点的个数
3. 谱聚类基础之二:相似矩阵
在上一节我们讲到了邻接矩阵W,它是由任意两点之间的权重值wij组成的矩阵。通常我们可以自己输入权重,但是在谱聚类中,我们只有数据点的定义,并没有直接给出这个邻接矩阵,那么怎么得到这个邻接矩阵呢?
基本思想是,距离较远的两个点之间的边权重值较低,而距离较近的两个点之间的边权重值较高,不过这仅仅是定性,我们需要定量的权重值。一般来说,我们可以通过样本点距离度量的相似矩阵S来获得邻接矩阵W。
构建邻接矩阵W的方法有三类。ϵ-邻近法,K邻近法和全连接法。
对于ϵ-邻近法,它设置了一个距离阈值ϵ,然后用欧式距离sij度量任意两点xi和xj的距离。即相似矩阵的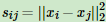 , 然后根据sij和ϵ的大小关系,来定义邻接矩阵W如下:
, 然后根据sij和ϵ的大小关系,来定义邻接矩阵W如下:
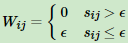
从上式可见,两点间的权重要不就是ϵ,要不就是0,没有其他的信息了。距离远近度量很不精确,因此在实际应用中,我们很少使用ϵ-邻近法。
第二种定义邻接矩阵W的方法是K邻近法,利用KNN算法遍历所有的样本点,取每个样本最近的k个点作为近邻,只有和样本距离最近的k个点之间的wij>0。但是这种方法会造成重构之后的邻接矩阵W非对称,我们后面的算法需要对称邻接矩阵。为了解决这种问题,一般采取下面两种方法之一:
第一种K邻近法是只要一个点在另一个点的K近邻中,则保留Sij
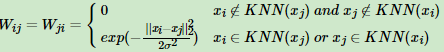
第二种K邻近法是必须两个点互为K近邻中,才能保留Sij
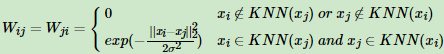
第三种定义邻接矩阵W的方法是全连接法,相比前两种方法,第三种方法所有的点之间的权重值都大于0,因此称之为全连接法。可以选择不同的核函数来定义边权重,常用的有多项式核函数,高斯核函数和Sigmoid核函数。最常用的是高斯核函数RBF,此时相似矩阵和邻接矩阵相同:

在实际的应用中,使用第三种全连接法来建立邻接矩阵是最普遍的,而在全连接法中使用高斯径向核RBF是最普遍的。
4. 谱聚类基础之三:拉普拉斯矩阵
单独把拉普拉斯矩阵(Graph Laplacians)拿出来介绍是因为后面的算法和这个矩阵的性质息息相关。它的定义很简单,拉普拉斯矩阵L=D−W。D即为我们第二节讲的度矩阵,它是一个对角矩阵。而W即为我们第二节讲的邻接矩阵,它可以由我们第三节的方法构建出。
拉普拉斯矩阵有一些很好的性质如下:
1)拉普拉斯矩阵是对称矩阵,这可以由D和W都是对称矩阵而得。
2)由于拉普拉斯矩阵是对称矩阵,则它的所有的特征值都是实数。
3)对于任意的向量f,我们有
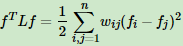
这个利用拉普拉斯矩阵的定义很容易得到如下:
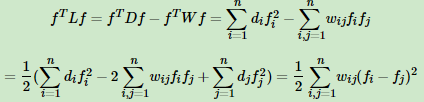
4) 拉普拉斯矩阵是半正定的,且对应的n个实数特征值都大于等于0,即0=λ1≤λ2≤...≤λn, 且最小的特征值为0,这个由性质3很容易得出。
5. 谱聚类基础之四:无向图切图
对于无向图G的切图,我们的目标是将图G(V,E)切成相互没有连接的k个子图,每个子图点的集合为:A1,A2,..Ak,它们满足Ai∩Aj=∅,且A1∪A2∪...∪Ak=V.
对于任意两个子图点的集合A,B⊂V, A∩B=∅, 我们定义A和B之间的切图权重为: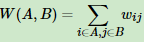
那么对于我们k个子图点的集合:A1,A2,..AkA1,A2,..Ak,我们定义切图cut为:
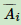 为Ai的补集,意为除Ai子集外其他V的子集的并集。
为Ai的补集,意为除Ai子集外其他V的子集的并集。
那么如何切图可以让子图内的点权重和高,子图间的点权重和低呢?一个自然的想法就是最小化cut(A1,A2,...Ak), 但是可以发现,这种极小化的切图存在问题,如下图:

我们选择一个权重最小的边缘的点,比如C和H之间进行cut,这样可以最小化cut(A1,A2,...Ak), 但是却不是最优的切图,如何避免这种切图,并且找到类似图中"Best Cut"这样的最优切图呢?我们下一节就来看看谱聚类使用的切图方法。
6. 谱聚类之切图聚类
为了避免最小切图导致的切图效果不佳,我们需要对每个子图的规模做出限定,一般来说,有两种切图方式,第一种是RatioCut,第二种是Ncut。下面我们分别加以介绍。
6.1 RatioCut切图
RatioCut切图为了避免第五节的最小切图,对每个切图,不光考虑最小化cut(A1,A2,...Ak),它还同时考虑最大化每个子图点的个数,即:
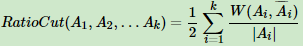
那么怎么最小化这个RatioCut函数呢?牛人们发现,RatioCut函数可以通过如下方式表示。
我们引入指示向量hj={h1,h2,..hk} j=1,2,...k,对于任意一个向量hj, 它是一个n维向量(n为样本数),我们定义hji为:
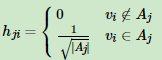
那么我们对于hiTLhi,有:
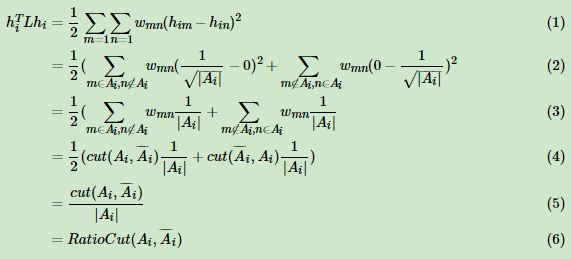
上述第(1)式用了上面第四节的拉普拉斯矩阵的性质3. 第二式用到了指示向量的定义。可以看出,对于某一个子图i,它的RatioCut对应于hiTLhi,那么我们的k个子图呢?对应的RatioCut函数表达式为:

其中tr(HTLH)为矩阵的迹。也就是说,我们的RatioCut切图,实际上就是最小化我们的tr(HTLH)。注意到HTH=I,则我们的切图优化目标为:

注意到我们H矩阵里面的每一个指示向量都是n维的,向量中每个变量的取值为0或者1/√1|Aj|,就有2n种取值,有k个子图的话就有k个指示向量,共有k2n种H,因此找到满足上面优化目标的H是一个NP难的问题。那么是不是就没有办法了呢?
注意观察tr(HTLH)中每一个优化子目标hiTLhi,其中h是单位正交基, L为对称矩阵,此时hiTLhi的最大值为L的最大特征值,最小值是L的最小特征值。如果你对主成分分析PCA很熟悉的话,这里很好理解。在PCA中,我们的目标是找到协方差矩阵(对应此处的拉普拉斯矩阵L)的最大的特征值,而在我们的谱聚类中,我们的目标是找到目标的最小的特征值,得到对应的特征向量,此时对应二分切图效果最佳。也就是说,我们这里要用到维度规约的思想来近似去解决这个NP难的问题。
对于hiTLhi,我们的目标是找到最小的L的特征值,而对于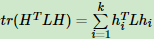 ,则我们的目标就是找到k个最小的特征值,一般来说,k远远小于n,也就是说,此时我们进行了维度规约,将维度从n降到了k,从而近似可以解决这个NP难的问题。
,则我们的目标就是找到k个最小的特征值,一般来说,k远远小于n,也就是说,此时我们进行了维度规约,将维度从n降到了k,从而近似可以解决这个NP难的问题。
通过找到L的最小的k个特征值,可以得到对应的k个特征向量,这k个特征向量组成一个nxk维度的矩阵,即为我们的H。一般需要对H矩阵按行做标准化,即
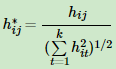
由于我们在使用维度规约的时候损失了少量信息,导致得到的优化后的指示向量h对应的H现在不能完全指示各样本的归属,因此一般在得到nxk维度的矩阵H后还需要对每一行进行一次传统的聚类,比如使用K-Means聚类.
☆☆☆对H进行聚类的原因:
1.注意到H除了是能满足极小化条件的解,还是L的特征向量,也可以理解为W的特征向量,而W则是我们构造出的图,对该图的特征向量做聚类,一方面聚类时不会丢失原图太多信息,另一方面是降维加快计算速度,而且容易发现图背后的模式。
2.由于之前定义的指示向量hi是二值分布,但是由于NP-hard问题的存在导致hihi无法显式求解,只能利用特征向量进行近似逼近,但是特征向量是取任意值,结果是我们对hi的二值分布限制进行放松,但这样一来hi如何指示各样本的所属情况?所以kmeans就登场了,利用kmeans对该向量进行聚类,如果是k=2的情况,那么kmeans结果就与之前二值分布的想法相同了,所以kmeans的意义在此,k等于任意数值的情况做进一步类推即可。
6.2 Ncut切图
Ncut切图和RatioCut切图很类似,但是把Ratiocut的分母|Ai|换成vol(Ai). 由于子图样本的个数多并不一定权重就大,我们切图时基于权重也更合我们的目标,因此一般来说Ncut切图优于RatioCut切图。

对应的,Ncut切图对指示向量h做了改进。注意到RatioCut切图的指示向量使用的是1/√1|Aj|标示样本归属,而Ncut切图使用了子图权重1/√1vol(Aj)来标示指示向量h,定义如下:
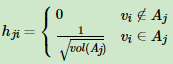
那么我们对于hiTLhi,有:
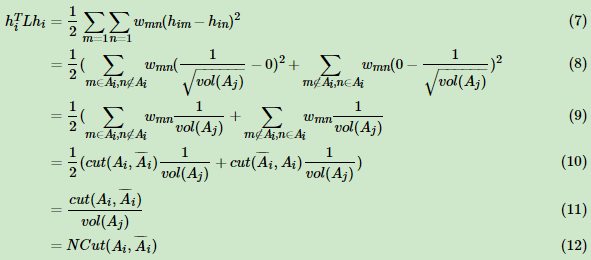
推导方式和RatioCut完全一致。也就是说,我们的优化目标仍然是
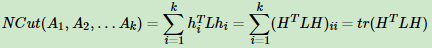
但是此时我们的HTH≠I,而是HTDH=I。推导如下:

也就是说,此时我们的优化目标最终为:

此时我们的H中的指示向量h并不是标准正交基,所以在RatioCut里面的降维思想不能直接用。怎么办呢?其实只需要将指示向量矩阵H做一个小小的转化即可。
我们令H=D−1/2F, 则: 也就是说优化目标变成了:
也就是说优化目标变成了:

可以发现这个式子和RatioCut基本一致,只是中间的L变成了D−1/2LD−1/2。这样我们就可以继续按照RatioCut的思想,求出D−1/2LD−1/2的最小的前k个特征值,然后求出对应的特征向量,并标准化,得到最后的特征矩阵F,最后对FF进行一次传统的聚类(比如K-Means)即可。
一般来说, D−1/2LD−1/2相当于对拉普拉斯矩阵L做了一次标准化,即
7. 谱聚类算法流程
铺垫了这么久,终于可以总结下谱聚类的基本流程了。一般来说,谱聚类主要的注意点为相似矩阵的生成方式(参见第二节),切图的方式(参见第六节)以及最后的聚类方法(参见第六节)。
最常用的相似矩阵的生成方式是基于高斯核距离的全连接方式,最常用的切图方式是Ncut。而到最后常用的聚类方法为K-Means。下面以Ncut总结谱聚类算法流程。
输入:样本集D=(x1,x2,...,xn),相似矩阵的生成方式, 降维后的维度k1, 聚类方法,聚类后的维度k2
输出: 簇划分C(c1,c2,...ck2).
1) 根据输入的相似矩阵的生成方式构建样本的相似矩阵S
2)根据相似矩阵S构建邻接矩阵W,构建度矩阵D
3)计算出拉普拉斯矩阵L
4)构建标准化后的拉普拉斯矩阵D−1/2LD−1/2
5)计算D−1/2LD−1/2最小的k1个特征值所各自对应的特征向量f
6) 将各自对应的特征向量f组成的矩阵按行标准化,最终组成n×k1维的特征矩阵F
7)对F中的每一行作为一个k1维的样本,共n个样本,用输入的聚类方法进行聚类,聚类维数为k2.
8)得到簇划分C(c1,c2,...ck2).
8. 谱聚类算法总结
谱聚类算法是一个使用起来简单,但是讲清楚却不是那么容易的算法,它需要你有一定的数学基础。如果你掌握了谱聚类,相信你会对矩阵分析,图论有更深入的理解。同时对降维里的主成分分析也会加深理解。
下面总结下谱聚类算法的优缺点。
谱聚类算法的主要优点有:
1)谱聚类只需要数据之间的相似度矩阵,因此对于处理稀疏数据的聚类很有效。这点传统聚类算法比如K-Means很难做到
2)由于使用了降维,因此在处理高维数据聚类时的复杂度比传统聚类算法好。
谱聚类算法的主要缺点有:
1)如果最终聚类的维度非常高,则由于降维的幅度不够,谱聚类的运行速度和最后的聚类效果均不好。
2) 聚类效果依赖于相似矩阵,不同的相似矩阵得到的最终聚类效果可能很不同。
本文内容转载自:https://www.cnblogs.com/pinard/p/6221564.html
更详尽可参考:https://blog.csdn.net/yc_1993/article/details/52997074
谱聚类(Spectral Clustring)原理的更多相关文章
- 谱聚类(Spectral Clustering)详解
谱聚类(Spectral Clustering)详解 谱聚类(Spectral Clustering, SC)是一种基于图论的聚类方法——将带权无向图划分为两个或两个以上的最优子图,使子图内部尽量相似 ...
- 【聚类算法】谱聚类(Spectral Clustering)
目录: 1.问题描述 2.问题转化 3.划分准则 4.总结 1.问题描述 谱聚类(Spectral Clustering, SC)是一种基于图论的聚类方法——将带权无向图划分为两个或两个以上的最优子图 ...
- 谱聚类 Spectral Clustering
转自:http://www.cnblogs.com/wentingtu/archive/2011/12/22/2297426.html 如果说 K-means 和 GMM 这些聚类的方法是古代流行的算 ...
- 谱聚类(spectral clustering)原理总结
谱聚类(spectral clustering)是广泛使用的聚类算法,比起传统的K-Means算法,谱聚类对数据分布的适应性更强,聚类效果也很优秀,同时聚类的计算量也小很多,更加难能可贵的是实现起来也 ...
- 基于谱聚类的三维网格分割算法(Spectral Clustering)
谱聚类(Spectral Clustering)是一种广泛使用的数据聚类算法,[Liu et al. 2004]基于谱聚类算法首次提出了一种三维网格分割方法.该方法首先构建一个相似矩阵用于记录网格上相 ...
- 谱聚类算法(Spectral Clustering)优化与扩展
谱聚类(Spectral Clustering, SC)在前面的博文中已经详述,是一种基于图论的聚类方法,简单形象且理论基础充分,在社交网络中广泛应用.本文将讲述进一步扩展其应用场景:首先是User- ...
- 谱聚类算法(Spectral Clustering)
谱聚类(Spectral Clustering, SC)是一种基于图论的聚类方法--将带权无向图划分为两个或两个以上的最优子图,使子图内部尽量相似,而子图间距离尽量距离较远,以达到常见的聚类的 ...
- 谱聚类(Spectral clustering)(2):NCut
作者:桂. 时间:2017-04-13 21:19:41 链接:http://www.cnblogs.com/xingshansi/p/6706400.html 声明:欢迎被转载,不过记得注明出处哦 ...
- 转:浅谈Spectral Clustering 谱聚类
浅谈Spectral Clustering Spectral Clustering,中文通常称为“谱聚类”.由于使用的矩阵的细微差别,谱聚类实际上可以说是一“类”算法. Spectral Cluste ...
随机推荐
- Windows 循环根据进程名称 存在则删除该进程
@echo off:Looptasklist | findstr /i "javaw.exe" >nul 2>nul && (taskkill -f / ...
- NGS概念大科普(转)
NGS又称为下一代测序技术,高通量测序技术 以高输出量和高解析度为主要特色,能一次并行对几十万到几百万条DNA分子进行序列读取,在提供丰富的遗传学信息的同时,还可大大降低测序费用.缩短测序时间的测序技 ...
- [数据结构] P2.3 Trie树
1.Trie树的概念 Trie树也叫做`字典树`或者`单词查找树`.用于字符串以及字符串元信息的快速查询. 例如:
- 现代 PHP 新特性 —— Zend Opcache (转)
转自:https://laravelacademy.org/post/4396.html 1.概述 字节码缓存不是PHP的新特性,有很多独立的扩展可以实现,比如APC.eAccelerator和Xac ...
- elementUi中的计数器ele-mumber中的change事件传参及事件调用
业务场景是需要在点击业务工作量的时候设置任务工作量这一项的评分不能大于任务质量及任务时限的权重之和除以二 上代码 JS逻辑代码 因出现弹出层提示后设置输入框的值如果大于sum的值,设置输入的值为sum ...
- 老男孩九期全栈Python之基础一
---恢复内容开始--- day1 12.while 体验while的执行方式和效果,用多种方法输出1~100 while 1: print('我们不一样') print('在人间') print(' ...
- @Component, @Repository, @Service的区别
注解 含义 @Component 最普通的组件,可以被注入到spring容器进行管理 @Repository 作用于持久层 @Service 作用于业务逻辑层 @Controller 作用于表现层(s ...
- Python3+unittest使用教程
一.直接使用TestCase 注意所有测试方法都需要以test开头.代码如下: import unittest class Test1(unittest.TestCase): @classmethod ...
- 学号 2018-2019-20175212 实验一 《Java开发环境的熟悉》
学号 2018-2019-20175212 实验一 <Java开发环境的熟悉> 一.实验内容及步骤 1.使用JDK编译.运行简单的Java程序 mkdir 20175212exp1创建20 ...
- 基于Protostuff实现的Netty编解码器
在设计netty的编解码器过程中,有许多组件可以选择,这里由于咱对Protostuff比较熟悉,所以就用这个组件了.由于数据要在网络上传输,所以在发送方需要将类对象转换成二进制,接收方接收到数据后,需 ...