<Python Text Processing with NLTK 2.0 Cookbook>代码笔记
如下是<Python Text Processing with NLTK 2.0 Cookbook>一书部分章节的代码笔记.
|
Tokenizing text into sentences |
|
>>> para = "Hello World. It's good to see you. Thanks for buying this book." >>> from nltk.tokenize import sent_tokenize >>> sent_tokenize(para) # "sent_tokenize"是一个函数,下文很多中间带下划线的标识符都指的是函数。 ['Hello World.', "It's good to see you.", 'Thanks for buying this book.'] |
|
Tokenizing sentences into words |
|
>>> from nltk.tokenize import word_tokenize >>> word_tokenize('Hello World.') ['Hello', 'World', '.'] # 等同于 >>> from nltk.tokenize import TreebankWordTokenizer >>> tokenizer = TreebankWordTokenizer() >>> tokenizer.tokenize('Hello World.') ['Hello', 'World', '.'] # 等同于 >>> import nltk >>> text = "Hello. Isn't this fun?" >>> pattern = r"\w+|[^\w\s]+" # r:regular expression;双引号""可以用单引号''代替;\w表示单词字符,等同于字符集合[a-zA-Z0-9_];+表示一次或者多次,等同于{1,},即c+ 和 c{1,} 是一个意思;"|":二选一,正则表达式中的"或"; [...]:字符集(字符类),其对应的位置可以是字符集中任意字符,例如,a[bcd]表abe、ace和ade;^表示只匹配字符串的开头;\s匹配单个空格,等同于[\f\n\r\t\v]。 >>> print nltk.tokenize.regexp_tokenize(text, pattern) ['Hello', '.', 'Isn', "'", 't', 'this', 'fun', '?'] |
|
Tokenizing sentences using regular expressions |
|
>>> from nltk.tokenize import RegexpTokenizer >>> tokenizer = RegexpTokenizer("[\w']+") >>> tokenizer.tokenize("Can't is a contraction.") ["Can't", 'is', 'a', 'contraction'] # a simple helper function。 the class. >>> from nltk.tokenize import regexp_tokenize >>> regexp_tokenize("Can't is a contraction.", "[\w']+") ["Can't", 'is', 'a', 'contraction'] |
|
Training a sentence tokenizer |
|
>>> from nltk.tokenize import PunktSentenceTokenizer >>> from nltk.corpus import webtext >>> text = webtext.raw('overheard.txt') >>> sent_tokenizer = PunktSentenceTokenizer(text) # Let's compare the results to the default sentence tokenizer, as follows: >>> sents1 = sent_tokenizer.tokenize(text) >>> sents1[0] #请注意,索引从零开始:第0 个元素写作sent[0],其实是第1 个词"word1";而句子的第9 个元素是"word10"。 'White guy: So, do you have any plans for this evening?' >>> from nltk.tokenize import sent_tokenize >>> sents2 = sent_tokenize(text) >>> sents2[0] 'White guy: So, do you have any plans for this evening?' >>> sents1[678] 'Girl: But you already have a Big Mac...' >>> sents2[678] 'Girl: But you already have a Big Mac...\\nHobo: Oh, this is all theatrical.' |
|
Filtering stopwords in a tokenized sentence |
|
>>> from nltk.corpus import stopwords >>> english_stops = set(stopwords.words('english')) >>> words = ["Can't", 'is', 'a', 'contraction'] >>> [word for word in words if word not in english_stops] ["Can't", 'contraction'] |
|
Looking up synsets for a word in WordNet |
|
# 方法一 >>> from nltk.corpus import wordnet >>> syn = wordnet.synsets('cookbook')[0] >>> syn.name() 'cookbook.n.01' >>> syn.definition() 'a book of recipes and cooking directions' # 方法二 >>> from nltk.corpus import wordnet >>> syn = wordnet.synsets('motorcar')[0] >>> syn.name <bound method Synset.name of Synset('car.n.01')> >>> from nltk.corpus import wordnet as wn >>> wn.synsets("motorcar") # 括号内可以是单引号 [Synset('car.n.01')] # WordNet层次结构(词汇关系)——Hypernym /ˈhaɪpənɪm//hyponym/ ˈhaɪpənɪm / relation——上级概念与从属概念的关系 >>> from nltk.corpus import wordnet as wn >>> motorcar = wn.synset('car.n.01') >>> types_of_motorcar = motorcar.hyponyms() #等号两边的表达式不能换位,否则会出现警示:can't assign to function call. >>> types_of_motorcar [Synset('ambulance.n.01'), Synset('beach_wagon.n.01'), Synset('bus.n.04'), Synset('cab.n.03'), Synset('compact.n.03'), Synset('convertible.n.01') ... Synset('stanley_steamer.n.01'), Synset('stock_car.n.01'), Synset('subcompact.n.01'), Synset('touring_car.n.01'), Synset('used-car.n.01')] # 部分整体关系(components (meronyms) holonyms) >>> from nltk.corpus import wordnet as wn >>> wn.synset('tree.n.01').part_meronyms() [Synset('burl.n.02'), Synset('crown.n.07'), Synset('limb.n.02'), Synset('stump.n.01'), Synset('trunk.n.01')] # 反义词关系 >>> wn.lemma('beautiful.a.01.beautiful').antonyms() [Lemma('ugly.a.01.ugly')] # 同义词关系 # 查看词汇关系和同义词集上定义的其它方法 >>> dir(wn.synset('beautiful.a.01')) ['__class__', '__delattr__', '__dict__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__' ... 'substance_holonyms', 'substance_meronyms', 'topic_domains', 'tree', 'unicode_repr', 'usage_domains', 'verb_groups', 'wup_similarity'] # Part-of-Speech (POS) >>> from nltk.corpus import wordnet >>> syn = wordnet.synsets('motorcar')[0] >>> syn.pos() u'n' |
|
Looking up lemmas and synonyms in WordNet |
|
#方法一 >>> from nltk.corpus import wordnet as wn >>> wn.synset('car.n.01').lemma_names() [u'car', u'auto', u'automobile', u'machine', u'motorcar'] #结果字符串有一个u 前缀表示它们是Unicode 字符串 >>> u'motorcar'.encode('utf-8') 'motorcar' #方法二 >>> a = wn.synset('car.n.01').lemma_names() >>> print a [u'car', u'auto', u'automobile', u'machine', u'motorcar'] >>> wn.synset('car.n.01').definition () u'a motor vehicle with four wheels; usually propelled by an internal combustion engine' |
|
Calculating WordNet synset similarity |
|
) >>> from nltk.corpus import wordnet as wn >>> right = wn.synset('right_whale.n.01') >>> minke = wn.synset('minke_whale.n.01') >>> right.path_similarity(minke) 0.25 #量度二:wup_similarity -- wup_similarity is short for Wu-Palmer Similarity, which is a scoring method based on how similar the word senses are and where the synsets occur relative to each other in the hypernym tree. >>> from nltk.corpus import wordnet >>> cb = wordnet.synset('cookbook.n.01') >>> ib = wordnet.synset('instruction_book.n.01') >>> cb.wup_similarity(ib) 0.9166666666666666 |
|
Discovering word collocations (relative to n-gram) |
|
>>> from nltk import bigrams >>> a = "Jaganadh is testing this application" >>> tokens = a.split() >>> bigrams(tokens) [('Jaganadh', 'is'), ('is', 'testing'), ('testing', 'this'), ('this', 'application.')] # 如果已分词,则: >>> bigrams(['more', 'is', 'said', 'than', 'done']) [('more', 'is'), ('is', 'said'), ('said', 'than'), ('than', 'done')] |
|
词频统计 |
|
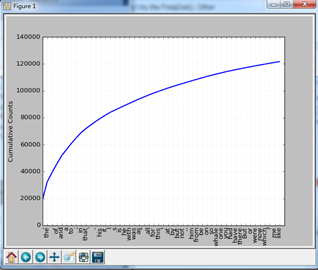
>>> from nltk.book import text1 *** Introductory Examples for the NLTK Book *** Loading text1, ..., text9 and sent1, ..., sent9 Type the name of the text or sentence to view it. Type: 'texts()' or 'sents()' to list the materials. text3: The Book of Genesis text4: Inaugural Address Corpus text5: Chat Corpus text6: Monty Python and the Holy Grail text7: Wall Street Journal text8: Personals Corpus >>> from nltk import FreqDist >>> fdist1 = FreqDist(text1) >>> print fdist1 <FreqDist with 19317 samples and 260819 outcomes> >>> fdist1 FreqDist({u',': 18713, u'the': 13721, u'.': 6862, u'of': 6536, u'and': 6024, u'a': 4569, u'to': 4542, u';': 4072, u'in': 3916, u'that': 2982, ...}) >>> fdist1.most_common(50) [(u',', 18713), (u'the', 13721), (u'.', 6862), (u'of', 6536), (u'and', 6024), (u'a', 4569), (u'to', 4542), (u';', 4072), (u'in', 3916), (u'that', 2982), (u"'", 2684), (u'-', 2552), (u'his', 2459), (u'it', 2209), (u'I', 2124), (u's', 1739), (u'is', 1695), (u'he', 1661), (u'with', 1659), (u'was', 1632), (u'as', 1620), (u'"', 1478), (u'all', 1462), (u'for', 1414), (u'this', 1280), (u'!', 1269), (u'at', 1231), (u'by', 1137), (u'but', 1113), (u'not', 1103), (u'--', 1070), (u'him', 1058), (u'from', 1052), (u'be', 1030), (u'on', 1005), (u'so', 918), (u'whale', 906), (u'one', 889), (u'you', 841), (u'had', 767), (u'have', 760), (u'there', 715), (u'But', 705), (u'or', 697), (u'were', 680), (u'now', 646), (u'which', 640), (u'?', 637), (u'me', 627), (u'like', 624)] # 绘制累积频率图 >>> import matplotlib # 不能直接运行from matplotlib import plot。 >>> fdist1.plot(50, cumulative=True) # 可能处理的时间比较长。
|
|
Stemming words |
|
# 单个 >>> from nltk.stem import PorterStemmer # "Poter"是一种词干提取的算法。 >>> stemmer = PorterStemmer() >>> stemmer.stem('cooking') u'cook' >>> stemmer.stem('cookery') u'cookeri' # The resulting stem is not always a valid word. For example, the stem of "cookery" is "cookeri". This is a feature, not a bug. # 多个 >>> import nltk >>> stemmer = nltk.PorterStemmer() >>> verbs = ['appears', 'appear', 'appeared', 'calling', 'called'] >>> stems = [] >>> for verb in verbs: stemmed_verb = stemmer.stem(verb) stems.append(stemmed_verb) # 一定要按两次回车键,然后再输入下面的语句。 >>> sorted(set(stems)) [u'appear', u'call'] |
|
Lemmatizing words with WordNet |
|
>>> from nltk.stem import WordNetLemmatizer >>> lemmatizer = WordNetLemmatizer() >>> lemmatizer.lemmatize('cooking') 'cooking' >>> lemmatizer.lemmatize('cooking', pos='v') u'cook' >>> lemmatizer.lemmatize('cookbooks') u'cookbook' |
|
Replacing words matching regular expressions |
|
# 第一步:新建一个名为"replacers.py"的模块(不是在控制台上操作),放置于安装Python的目录下的"Lib"文件夹,也可置于安装Python的根目录下,但最好放在"Lib"下,以表明这是一个库(即Python中的模块)。 import re replacement_patterns = [ (r'won\'t', 'will not'), (r'can\'t', 'cannot'), (r'i\'m', 'i am'), (r'ain\'t', 'is not'), (r'(\w+)\'ll', '\g<1> will'), (r'(\w+)n\'t', '\g<1> not'), (r'(\w+)\'ve', '\g<1> have'), (r'(\w+)\'s', '\g<1> is'), (r'(\w+)\'re', '\g<1> are'), (r'(\w+)\'d', '\g<1> would') ] class RegexpReplacer(object): def __init__(self, patterns=replacement_patterns): self.patterns = [(re.compile(regex), repl) for (regex, repl) in patterns] def replace(self, text): s = text for (pattern, repl) in self.patterns: s = re.sub(pattern, repl, s) return s # 第二步 >>> from replacers import RegexpReplacer >>> replacer = RegexpReplacer() >>> replacer.replace("can't is a contraction") 'cannot is a contraction' >>> replacer.replace("I should've done that thing I didn't do") 'I should have done that thing I did not do' |
|
Accessing Corpora |
|
>>> from nltk.corpus import gutenberg >>> for filename in gutenberg.fileids(): r = gutenberg.raw(filename) w = gutenberg.words(filename) s = gutenberg.sents(filename) v = set(w) print filename, len(r)/len(w), len(w)/len(s), len(w)/len(v) # 要按两次回车键才能显示结果。 austen-emma.txt 4 24 24 #语料库的文件名,平均字长,平均句长,每个词平均出现的次数,下同。 ... ... |
|
>>> from nltk.book import * *** Introductory Examples for the NLTK Book *** Loading text1, ..., text9 and sent1, ..., sent9 Type the name of the text or sentence to view it. Type: 'texts()' or 'sents()' to list the materials. ... ... text9: The Man Who Was Thursday by G . K . Chesterton 1908 >>> text1.concordance("monstrous") Displaying 11 of 11 matches: ong the former , one was of a most monstrous size . ... This came towards us , ON OF THE PSALMS . " Touching that monstrous bulk of the whale or ork we have r ... ... ght have been rummaged out of this monstrous cabinet there is no telling . But of Whale - Bones ; for Whales of a monstrous size are oftentimes cast up dead u |
|
外部文档操作 |
|
# 外部文档操作 # 读取一个txt文件(已经新建一个"good.txt"文件在D:/Python27下) >>> f = open('document.txt') >>> raw = f.read() #打印"good.txt"内容。# 即使打印Walden这样比较大的文件也比较快 >>> f = open ('good.txt') >>> print f.read() happy Lucy Lilei >>> # -*- coding:utf-8 -*- >>> f = open ('语言学.txt') >>> print f.read() 计算语言学 自然语言处理 # 建立自己的语料库,并对语料库里的文件进行检索 # 第一步 >>> corpus_root = 'D:/Python27/my own data' >>> from nltk.corpus import PlaintextCorpusReader >>> corpus_root = 'D:/Python27/my own data' >>> wordlists = PlaintextCorpusReader(corpus_root, 'Walden.txt') >>> wordlists.fileids() ['Walden.txt'] #注意: >>> from nltk.corpus import PlaintextCorpusReader >>> corpus_root = 'D:/Python27/my own data' >>> wordlists = PlaintextCorpusReader(corpus_root, '.*') # .*具有贪婪的性质,首先匹配到不能匹配为止,根据后面的正则表达式,会进行回溯。 >>> wordlists.fileids() ['Gone with the Wind.txt', 'Walden.txt'] # 第二步 >>> n = nltk.word_tokenize(wordlists.raw(fileids="Walden.txt")) >>> complete_Walden = nltk.Text(n) >>> complete_Walden.concordance("love") Displaying 25 of 40 matches: r even to found a school , but so to love wisdom as to live according to its d , perhaps we are led oftener by the love of novelty and a regard for the opin ... ... eed have you to employ punishments ? Love virtue , and the people will be virt abardine dressed . '' `` Come ye who love , And ye who hate , Children of the # 获取网络文本 >>> from urllib import urlopen >>> url = "http://news.bbc.co.uk/2/hi/health/2284783.stm" >>> html = urlopen(url).read() >>> html[:60] '<!doctype html public "-//W3C//DTD HTML 4.0 Transitional//EN' # 接下来如果输入print html可以看到HTML 的全部内容,包括meta 元标签、图像标签、map 标 签、JavaScript、表单和表格。 # NLTK本来提供了一个辅助函数nltk.clean_html()将HTML 字符串作为参数,返回原始文本;但现在这个函数已经不被支持了,而是用BeautifulSoup的函数get_text()。 >>> import urllib >>> from bs4 import BeautifulSoup >>> url = "http://news.bbc.co.uk/2/hi/health/2284783.stm" >>> html = urllib.urlopen(url).read() >>> soup = BeautifulSoup(html) >>> print soup.get_text() # 对网络文本分词 >>> import urllib >>> from bs4 import BeautifulSoup >>> url = "http://news.bbc.co.uk/2/hi/health/2284783.stm" >>> html = urllib.urlopen(url).read() >>> soup = BeautifulSoup(html) >>> raw = BeautifulSoup.get_text(soup) >>> from nltk.tokenize import word_tokenize >>> token = nltk.word_tokenize(raw) >>> token # 可以在token前加上"print"。 [u'BBC', u'NEWS', u'|', u'Health', u'|', u'Blondes', u"'to", u'die', u'out', u'in', u'200', u"years'", u'NEWS', u'SPORT', u'WEATHER', u'WORLD', u'SERVICE', u'A-Z', u'INDEX', ...] # 重点 >>> s = [u'r118', u'BB'] >>> [str(item) for item in s] ['r118', 'BB'] |
|
Default tagging |
|
# 版本一 >>> import nltk >>> text=nltk.word_tokenize("We are going out.Just you and me.") >>> print nltk.pos_tag(text) [('We', 'PRP'), ('are', 'VBP'), ('going', 'VBG'), ('out.Just', 'JJ'), ('you', 'PRP'), ('and', 'CC'), ('me', 'PRP'), ('.', '.')] # 版本二 >>> sentence = """At eight o'clock on Thursday morning Arthur didn't feel very good.""" >>> tokens = nltk.word_tokenize(sentence) >>> tokens ['At', 'eight', "o'clock", 'on', 'Thursday', 'morning', 'Arthur', 'did', "n't", 'feel', 'very', 'good', '.'] >>> tagged = nltk.pos_tag(tokens) >>> tagged [('At', 'IN'), ('eight', 'CD'), ("o'clock", 'JJ'), ('on', 'IN'), ('Thursday', 'NNP'), ('morning', 'NN'), ('Arthur', 'NNP'), ('did', 'VBD'), ("n't", 'RB'), ('feel', 'VB'), ('very', 'RB'), ('good', 'JJ'), ('.', '.')] >>> tagged[0:6] [('At', 'IN'), ('eight', 'CD'), ("o'clock", 'JJ'), ('on', 'IN'), ('Thursday', 'NNP'), ('morning', 'NN')] |
|
Chunking and chinking with regular expressions |
|
# Chunking & Parsing # Chart Parsing 是描述CFG(Context Free Grammar)语法的一种方法,两者不是平行关系。 import nltk grammar = r""" NP: {<DT|PP\$>?<JJ>*<NN>} # chunk determiner/possessive, adjectives and nouns {<NNP>+} # chunk sequences of proper nouns """ cp = nltk.RegexpParser(grammar) tagged_tokens = [("Rapunzel", "NNP"), ("let", "VBD"), ("down", "RP"), ("her", "PP$"), ("golden", "JJ"), ("hair", "NN")] # 实际运用中,需先对"Rapunzel let down her golden hair."这句进行tokenization. print cp.parse(tagged_tokens) # CFG Parsing >>> import nltk # 这两行代码也可以写成:from nltk import CFG; groucho_grammar = CFG.fromstring(""" >>> groucho_grammar = nltk.CFG.fromstring(""" S -> NP VP PP -> P NP NP -> D N | D N PP | 'I' VP -> V NP | V PP D -> 'an' | 'a' | 'my' | 'the' N -> 'elephant' | 'pajamas' V -> 'shot' P -> 'in' """) >>> sent = "I shot an elephant in my pajamas".split() # 有可能实现就分好词了,即:sent = ['I','shot','an','elephant','in','my','pajamas'] >>> parser = nltk.ChartParser(groucho_grammar) # Chart Parsing 是描述CFG语法的一种方法。 >>> all_the_parses = parser.parse(sent) >>> all_the_parses <generator object parses at 0x030E8AD0> >>> for parse in all_the_parses: print(parse) (S (NP I) (VP (V shot) (NP (D an) (N elephant) (PP (P in) (NP (D my) (N pajamas)))))) |
<Python Text Processing with NLTK 2.0 Cookbook>代码笔记的更多相关文章
- 【代码笔记】iOS-使用MD5加密
一,代码. - (void)viewDidLoad { [super viewDidLoad]; // Do any additional setup after loading the view, ...
- 【代码笔记】iOS-旋转的风扇
一,效果图. 二,工程图. 三,代码. AppDelegate.m #import "AppDelegate.h" //加入头文件 #import "RoundDiskV ...
- 探索 Python、机器学习和 NLTK 库 开发一个应用程序,使用 Python、NLTK 和机器学习对 RSS 提要进行分类
挑战:使用机器学习对 RSS 提要进行分类 最近,我接到一项任务,要求为客户创建一个 RSS 提要分类子系统.目标是读取几十个甚至几百个 RSS 提要,将它们的许多文章自动分类到几十个预定义的主题领域 ...
- Python Flask高级编程之从0到1开发《鱼书》精品项目 ☝☝☝
Python Flask高级编程之从0到1开发<鱼书>精品项目 ☝☝☝ 一 .安装环境我们使用 flask web框架,并用 sqlalchemy来做数据库映射,并使用 migrate做数 ...
- Python Flask高级编程之从0到1开发《鱼书》精品项目 ✍✍✍
Python Flask高级编程之从0到1开发<鱼书>精品项目 一 .安装环境我们使用 flask web框架,并用 sqlalchemy来做数据库映射,并使用 migrate做数据迁移 ...
- 《Data-Intensive Text Processing with mapReduce》读书笔记之一:前言
暑假闲得蛋痒,混混沌沌,开始看<Data-Intensive Text Processing with mapReduce>,尽管有诸多单词不懂,还好六级考多了,虽然至今未过:再加上自己当 ...
- 《Data-Intensive Text Processing with mapReduce》读书笔记之二:mapreduce编程、框架及运行
搜狐视频的屌丝男士第二季大结局了,惊现波多野老师,怀揣着无比鸡冻的心情啊,可惜随着剧情的推进发展,并没有出现期待中的屌丝奇遇,大鹏还是没敢冲破尺度的界线.想百度些种子吧,又不想让电脑留下污点证据,要知 ...
- NHibernate.3.0.Cookbook第一章第六节Handling versioning and concurrency的翻译
NHibernate.3.0.Cookbook第一章第六节Handling versioning and concurrency的翻译 第一章第二节Mapping a class with XML ...
- Python 全栈开发【第0篇】:目录
Python 全栈开发[第0篇]:目录 第一阶段:Python 开发入门 Python 全栈开发[第一篇]:计算机原理&Linux系统入门 Python 全栈开发[第二篇]:Python基 ...
随机推荐
- JAVA循环的语法
一,有几种循环的语法 1while. while(循环条件){ 循环操作 } while(循环条件){ 循环操作 } 2.do-while do{ 循环操作 }while(循环条件); do{ 循环操 ...
- vue+vuex 回退定位到初始位置
先放出两张图(没错,你还在9012,做为一名资深设计师我唯一的技能点就是留白),简单说明下问题未做回退定位(从落地页回退,每次都回到A位置)想死啊有木有,每次都需要手动重新定位来选择,你大哥看到你做个 ...
- Docker介绍及使用
什么是容器? 容器就是在隔离的环境运行的一个进程,如果进程停止,容器就会销毁.隔离的环境拥有自己的系统文件,ip地址,主机名等,kvm虚拟机,linux,系统文件 程序:代码,命令 进程:正在运行的程 ...
- OO第四次博客作业!
oo第四次博客作业 一.测试与正确性论证比较 测试只是单方面片面的证明对于当前的输入程序是正确的,测试只能证明程序有错误,不能说明程序是对的. 正确性论证是程序达到预期目的的一般性陈述,是通过规范化的 ...
- day1——分割数组
// 小白一名,0算法基础,艰难尝试算法题中,若您发现本文中错误, 或有其他见解,往不吝赐教,感激不尽,拜谢. 领扣 第915题 今日算法题干//给定一个数组 A,将其划分为两个不相交(没有公共元素) ...
- Poj2018 Best Cow Fences
传送门 题目大意就是给定一个长度为 n 的正整数序列 A ,求一个平均数最大的,长度不小于 L 的子序列. 思路: 二分答案. Code: #include<iostream> #incl ...
- winform SerialPort串口通信问题
一.串口通信简介串行接口(串口)是一种可以将接受来自CPU的并行数据字符转换为连续的串行数据流发送出去,同时可将接受的串行数据流转换为并行的数据字符供给CPU的器件.一般完成这种功能的电路,我们称为串 ...
- vue history模式
注意: 1.前端:config.js路径问题 2.后台:配置nginx
- 2018-2019-2 20165303《网络对抗技术》Exp2 后门原理与实践
实验内容 (1)使用netcat获取主机操作Shell,cron启动 (0.5分) (2)使用socat获取主机操作Shell, 任务计划启动 (0.5分) (3)使用MSF meterpreter( ...
- ASP.NET MVC CSRF (XSRF) security
CSRF(Cross-site request forgery)跨站请求伪造,也被称为“One Click Attack”或者Session Riding,通常缩写为CSRF或者XSRF,是一种对网站 ...