Python面试笔记一
目录
一、MySQL(30题)
二、django(15题)
三、Python部分(46题)
四、RESTful API设计指南(7题)
五、补充
一、MySQL(30题)
1、mysql如何做分页
mysql数据库做分页用limit关键字,它后面跟两个参数startIndex和pageSize
2、mysql引擎有哪些,各自的特点是什么?
innodb和myisam两个引擎,两者区别是
innodb支持事务,myisam不支持
innodb支持外键,myisam不支持
innodb不支持全文索引,myisam支持全文索引
innodb提供提交、回滚、崩溃恢复能力的事物的安全能力,实现并发控制
myisam提供较高的插入和查询记录的效率,主要用于插入和查询
3、数据库怎么建立索引
create index account_index on `table name `(`字段名`(length)
4、一张表多个字段,怎么创建组合索引
create index account_index on `table name `(`字段名`,'字段名')
5、如何应对数据的高并发,大量的数据计算
1.创建索引
2.数据库读写分离,两个数据库,一个作为写,一个作为读
3. 外键去掉
4.django中orm表性能相关的
select_related:一对多使用,查询主动做连表
prefetch_related:多对多或者一对多的时候使用,不做连表,做多次查询
6、数据库内连表、左连表、右连表
内连接是根据某个条件连接两个表共有的数据
左连接是根据某个条件以及左边的表连接数据,右边的表没有数据的话则为null
右连接是根据某个条件以及右边的表连接数据,左边的表没有数据的话则为null
7、视图和表的区别
视图是已经编译好的sql语句,是基于sql语句的结果集的可视化的表,而表不是
视图是窗口,表示内容
视图没有实际的物理记录,而表有
视图的建立和删除只影响视图本身,不影响对应的表
8、关系型数据库的特点
数据集中控制
数据独立性高
数据共享性好
数据冗余度小
数据结构化
统一的数据保护能力
9、mysql数据库都有哪些索引
普通索引:普通索引仅有一个功能:加速查找
唯一索引:唯一索引两个功能:加速查找和唯一约束(可含null)
主键索引:外键索引两个功能:加速查找和唯一约束(不可为null)
联合索引:联合索引是将n个列组合成一个索引,应用场景:同时使用n列来进行查询
10、存储过程
存储过程不允许执行return语句,但是可以通过out参数返回多个值,存储过程一般是作为一个独立的部分来执行,存储过程是一个预编译的SQL语句。
12、char和vachar区别:
首先明确的是,char的长度是不可变的,而varchar的长度是可变的,
定义一个char[10]和varchar[10],如果存进去的是‘abcd’,那么char所占的长度依然为10,除了字符‘abcd’外,后面跟六个空格,而varchar就立马把长度变为4了,取数据的时候,char类型的要用trim()去掉多余的空格,而varchar是不需要的,
char的存取数度还是要比varchar要快得多,因为其长度固定,方便程序的存储与查找;但是char也为此付出的是空间的代价,因为其长度固定,所以难免会有多余的空格占位符占据空间,可谓是以空间换取时间效率,而varchar是以空间效率为首位的。
char的存储方式是,对英文字符(ASCII)占用1个字节,对一个汉字占用两个字节;而varchar的存储方式是,对每个英文字符占用2个字节,汉字也占用2个字节,两者的存储数据都非unicode的字符数据。
13、Mechached与redis
mechached:只支持字符串,不能持久化,数据仅存在内存中,宕机或重启数据将全部失效
不能进行分布式扩展,文件无法异步法。
优点:mechached进程运行之后,会预申请一块较大的内存空间,自己进行管理。
redis:支持服务器端的数据类型,redis与memcached相比来说,拥有更多的数据结构和并发支持更丰富的数据操作,可持久化。
五大类型数据:string、hash、list、set和有序集合,redis是单进程单线程的。
缺点:数据库的容量受到物理内存的限制。
14、sql注入
SQL注入攻击指的是通过构建特殊的输入作为参数传入Web应用程序,而这些输入大都是SQL语法里的一些组合,通过执行SQL语句进而执行攻击者所要的操作,其主要原因是程序没有细致地过滤用户输入的数据,致使非法数据侵入系统。
例如:
select * from users where username='marcofly' and password=md5('test')
SQL注入:select * from users where username=' ' or 1=1 # ' and password=md5('')
“#”在mysql中是注释符
防止:
凡涉及到执行sql中有变量时,切记不要用拼接字符串的方法
永远不要信任用户的输入。对用户的输入进行校验,可以通过正则表达式,或限制长度;对单引号和
双"-"进行转换等。
永远不要使用管理员权限的数据库连接,为每个应用使用单独的权限有限的数据库连接。
不要把机密信息直接存放,加密或者hash掉密码和敏感的信息。
应用的异常信息应该给出尽可能少的提示,最好使用自定义的错误信息对原始错误信息进行包装
15、什么是触发器
触发器是一种特殊的存储过程,主要是通过事件来触发而被执行的,他可以强化约束,来维护数据库的完整性和一致性,可以跟踪数据内的操作从而不允许未经许可的 更新和变化,可以联级运算。
只有表支持触发器,视图不支持触发器
16、游标是什么?
是对查询出来的结果集作为一个单元来有效的处理,游标可以定在该单元中的特定行,从结果集的当前行检索一行或多行,可以对结果集当前行做修改,
一般不使用游标,但是需要逐条处理数据的时候,游标显得十分重要
17、 数据库支持多有标准的SQL数据类型,重要分为三类
数值类型(tinyint,int,bigint,浮点数,bit)
字符串类型(char和vachar,enum,text,set)
日期类型(date,datetime,timestamp)
18、mysql慢查询
慢查询对于跟踪有问题的查询很有用,可以分析出当前程序里哪些sql语句比较耗费资源
慢查询定义:
指mysql记录所有执行超过long_query_time参数设定的时间值的sql语句,慢查询日志就是记录这些sql的日志。
mysql在windows系统中的配置文件一般是my.ini找到mysqld
log-slow-queries = F:\MySQL\log\mysqlslowquery.log 为慢查询日志存放的位置,一般要有可写权限
long_query_time = 2 2表示查询超过两秒才记录
19、memcached命中率
命中:可以直接通过缓存获取到需要的数据
不命中:无法直接通过缓存获取到想要的数据,需要再次查询数据库或者执行其他的操作,原因可能是由于缓存中根本不存在,或者缓存已经过期
缓存的命中率越高则表示使用缓存的收益越高,应额用的性能越好,抗病发能力越强
运行state命令可以查看memcached服务的状态信息,其中cmd—get表示总的get次数,get—hits表示命中次数,命中率=get—hits / cmd—get
20、Oracle和MySQL该如何选择,为什么?
他们都有各自的优点和缺点。考虑到时间因素,我倾向于MySQL
选择MySQL而不选Oracle的原因
MySQL开源
MySQL轻便快捷
MySQL对命令行和图形界面的支持都很好
MySQL支持通过Query Browser进行管理
21、什么情况下适合建立索引?
1.为经常出现在关键字order by、group by、distinct后面的字段,建立索引
2.在union等集合操作的结果集字段上,建立索引,其建立索引的目的同上
3.为经常用作查询选择的字段,建立索引
4.在经常用作表连接的属性上,建立索引
22、数据库底层是用什么结构实现的,你大致画一下:
底层用B+数实现,结构图参考:
http://blog.csdn.net/cjfeii/article/details/10858721
http://blog.csdn.net/tonyxf121/article/details/8393545
23、sql语句应该考虑哪些安全性?
1.防止sql注入,对特殊字符进行转义,过滤或者使用预编译的sql语句绑定变量
2.最小权限原则,特别是不要用root账户,为不同的类型的动作或者组建使用不同的账户
3.当sql运行出错时,不要把数据库返回的错误信息全部显示给用户,以防止泄漏服务器和数据库相关信息
24、数据库事物有哪几种?
隔离性、持续性、一致性、原子性
25、MySQ数据表在什么情况下容易损坏?
服务器突然断电导致数据文件损坏
强制关机,没有先关闭mysq服务器等
26、drop,delete与truncate的区别
drop直接删除表
truncate删除表中数据,再插入时自增长id又从1开始
delete删除表中数据,可以加where子句
27、数据库范式
1.第一范式:就是无重复的列
2.第二范式:就是非主属性非部分依赖于主关键字
3.第三范式:就是属性不依赖于其他非主属性(消除冗余)
28、MySQL锁类型
根据锁的类型分:可以分为共享锁、排他锁、意向共享锁和意向排他锁
根据锁的粒度分:可以分为行锁、表锁
对于mysql而言,事务机制更多是靠底层的存储引擎来实现的,因此,mysql层面只有表锁,
而支持事物的innodb存储引起则实现了行锁(在行相应的索引记录上的锁)
说明:对于更新操作(读不上锁),只有走索引才可能上行锁
MVCC(多版本并发控制)并发控制机制下,任何操作都不会阻塞读取操作,
读取操作也不会阻塞任何操作,只因为读不上锁
共享锁:由读表操作加上的锁,加锁后其他用户只能获取该表或行的共享锁,不能获取排他锁,
也就是说只能读不能写
排他锁:由写表操作加上的锁,加锁后其他用户不能获取该表或该行的任何锁,典型mysql事物中的更新操作
意向共享锁(IS):事物打算给数据行加行共享锁,事物在给一个数据行加共享锁前必须先取得该表的IS锁
意向排他锁(IX):事物打算给数据行加行排他锁,事物在给一个数据行家排他锁前必须先取得该表的IX锁
29、如何解决MYSQL数据库中文乱码问题?
1.在数据库安装的时候指定字符集
2.如果在按完了以后可以更改配置文件
3.建立数据库时候:指定字符集类型
4.建表的时候也指定字符集
30、数据库应用系统设计
1.规划
2.需求分析
3.概念模型设计
4.逻辑设计
5.物理设计
6. 程序编制及调试
7.运行及维护
二、django(15题)
1、中间件
中间件一般做认证或批量请求处理,django中的中间件,其实是一个类,在请求和结束后,django会根据自己的规则在合适的时机执行中间件中相应的方法,
如请求过来 执行process_request, view,process_response方法
2、Django、Tornado、Flask各自的优势
Django:Django无socket,django的目的是简便,快速开发,并遵循MVC设计,多个组件可以很方便的以“插件”形式服务于整个框架,
django有许多功能强大的第三方插件。django具有很强的可扩展性。
Tornado:它是非阻塞式服务器,而且速度相当快,得力于其 非阻塞的方式和对epoll的运用,Future对象,缺点:没有session,需要自定制
Flask:是一个微型的web框架,配合SQLALchemy来使用,jinja2模板, werkzeug接口
3、 django版本,Python版本,linux版本
django:1.11
Python:3.5
linux:6.8
4、django的template的注释是什么样子的
单行:{#注释#}
多行注释:{%comment%}
5、django怎么弄并发的
nginx+uwsig为django提供高并发,nginx的并发能力超过,单台并发能力过完,在纯静态的web服务中更是突出其优越的地方,由于底层使用epoll异步IO模型进行处理。
6、tornodo的ioloop知道是什么吗?
事件循环
7、select_related和prefetch_related,Q和F
select_related:一对多使用,查询主动做连表
prefetch_related:多对多或者一对多的时候使用,不做连表,做多次查询
Q:用于构造复杂查询条件
F:更新时用于获取原来的值,专门取对象中某一列进行操作
8、什么是ORM?
ORM,即Object-Relational Mapping(对象关系映射),它的作用是在关系型数据库和业务实体对象之间做一个映射
ORM优缺点:
优点:摆脱复杂的SQL操作,适应快速开发,让数据结果变得简单,数据库迁移成本更低
缺点:性能较差,不适用于大型应用,复杂的SQL操作还需要通过SQL语句实现
9、CORS跨域资源共享
首先会发送"预检"opption",请求,如果"预检"成功,则发送真实数据。
10、Django的Form主要具有以下功能?
生成HTMl标签,验证用户数据 is_vaild,HTML Form提交保留上次提交数据,初始化页面显示内容
11、CBV和FBV
CBV在指定的类上面加上装饰器或在此方法上面添加装饰器 @method_decorator,并继承view
12、cookie及session
cookie:是保留在客户端上面的一组键值对,cookie不是很安全,别人可以分析存放在本地的cookie
session:是保存在服务器上面的一组键值对,依赖与cookie,安全指数比cookie高
13、django的请求生命周期
请求来了先到uwsgi,把请求做一部分分装给django框架,然后经过所有的中间件,路由,视图,视图处理再返回给中间件,中间件在返回给uwsgi,在返回给用户。
14、uwsgi和wsgi
wsgi:是web服务器网关接口,是pyhton应用程序或框架和web服务器之间的一种接口,其广泛使用的是django框架。
uwsgi:是一个web服务器,它实现了wsgi协议,Nginx中HttpUwsgiModule的作用是与Uwsgi服务器进行交换
15、解释下django - debug -toolbar的使用
使用django开发站点时,可以使用django-debug-toolbar来进行调试,在settings.py中添加 'debug—toolbar.midleware.Debug ToolbarMiddleware'到项目的MIDDLEWARE_CLASSES内。
三、Python部分(46题)
1、 __new__.__init__区别
__new__是一个静态方法,__init__是一个实例方法
__new__返回一个创建的实例,__init__什么都不返回
__new__返回一个cls的实例时后面的__init__才能被调用
当创建一个新实例时调用__new__,初始化一个实例时调用__init__
2、深浅拷贝
浅拷贝只是增加了一个指针指向一个存在的地址,而深拷贝是增加一个指针并且开辟了新的内存,这个增加的指针指向这个新的内存,
采用浅拷贝的情况,释放内存,会释放同一内存,深拷贝就不会出现释放同一内存的错误
#调出copy库
import copy
number=[10,22,56,[33,10,45],99,34]
number2=number.copy() #普通copy
number[1]=200
number2[1]=500
number[3][0]=''
number2[3][1]=''
print(number)
print(number2)
#深度copy,完全复制嵌套列表中的数值,两个列表互不影响
number3=copy.deepcopy(number)
number[3][0]='aaa'
number3[3][1]='jjjj'
print(number)
print(number3)
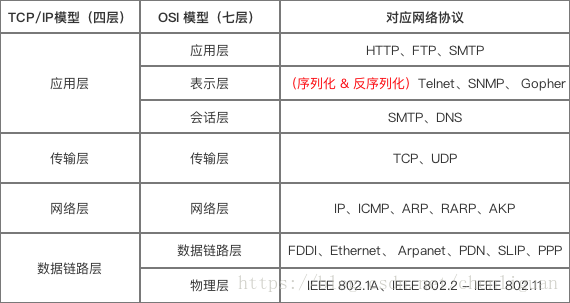
3、HTTP/IP相关协议,分别位于哪层
IP地址是指互联网协议地址,为计算机网络相互连接进行通信而设计的协议,是IP协议提供的一种统一的地址格式,它为互联网上的每一个网络和每一台主机分配一个唯一的网络地址,以此来屏蔽物理地址的差异,位于网络层。
HTTP协议即超文本传送协议(Hypertext Transfer Protocol ),是一个应用层协议,由请求和响应构成,是一个标准的客户端服务器模型,是Web联网的基础,也是手机联网常用的协议之一,HTTP协议是建立在TCP协议之上的一种应用。
HTTP连接最显著的特点是:客户端发送的每次请求都需要服务器回送响应,在请求结束后,会主动释放连接。从建立连接到关闭连接的过程称为“一次连接”。
4.3 HTTP与HTTPS的区别
- HTTPS加密传输协议,HTTP明文传输协议;
- HTTPS需要用SSL证书,HTTP不用;
- HTTPS比HTTP更加安全搜索引擎更友;
- HTTPS标准端口443,HTTP标准端口80;
- HTTPS基于传输层,HTTP基于应用层;
- HTTPS浏览器显示绿色安全锁HTTP没显示。
5、 一次完整的HTTP请求所经历的7个步骤
- 1、建立TCP/IP连接
在HTTP工作开始之前,客户端与服务器通过TCP三次握手建立连接。 - 2、客户端向服务器发送HTTP请求行
建立了TCP连接,客户端向服务器发送HTTP请求行,例如:GET/sample/hello.jsp HTTP/1.1 。 - 3、客户端发送请求头和请求体
客户端向服务器发送请求头信息、请求体内容,最后客户端会发送一空白行表示客户端请求完毕。 - 4、服务器应答响应行
服务器会做出应答,表示对客户端请求的应答, 状态行:HTTP/1.1 200 OK 。 - 5、服务器向客户端发送响应头信息
服务器向客户端发送头信息后,它会发送一个空白行来表示头信息的发送到此为结束。 - 6、服务器向客户端发送响应包体
接着,服务器以Content-Type响应头信息所描述的格式向客户端发送响应包——所请求的实际数据。 - 7、 服务器关闭TCP连接
如果浏览器或者服务器在其头信息加入了这行代码:Connection:keep-alive ,TCP连接在发送后将仍然保持打开状态,客户端可以继续通过相同的连接发送请求。
4、地址栏键输入URL,按下回车之后经历了什么?
1.浏览器向DNS服务器请求解析该URL中的域名所对应的IP地址
2.解析出IP地址后,根据IP地址和默认端口80,和服务器建立TCP连接
3.浏览器发出读取文件的http请求,该请求报文作为TCP三次握手的第三个报文的数据发送给服务器
4.服务器对浏览器请求做出响应,并把对应的html文件发送给浏览器
5.释放TCP连接
6.浏览器将该HMTL渲染并显示内容
4、TCP/UDP区别
TCP协议是面向连接,保证高可靠性(数据无丢失,数据无失序,数据无错误,数据无重复达到)
UDP:不可靠的传输,数据丢失,不管数据包的顺序、错误或重发(qq基于udp协议)
5、webscoket
websocket是基于http协议的,可持续化连接
轮询:浏览器每隔几秒就发送一次请求,询问服务器是否有新消息
长轮询:客户端发起连接后,如果没有消息,就一直不返回response给客户端,直到有消息返回,返回完之后,客户端再次发起连接
6、RabbitMQ:
服务器端有Erlang语言来编写,支持多种客户端,只会ajax,用于分布式系统中存储转发消息,在易用性、扩展性、高可用性的方面不俗。
connection是RabbitMQ的socket连接,它封装了socket部分相关协议逻辑
connectionFactroy为connection的制造工厂
channel是我们与RabbitMQ打交道的最重要的一个接口,大部分的业务操作是在chaanel这个接口中完成,包括定义Queue、定义Exchange、
绑定Queue与Exchange,发布消息等
7、装饰器
调用装饰器其实是一个闭包函数,为其他函数添加附加功能,不修改被装饰函数的源代码和其被调用的方式,装饰器的返回值也是一个函数对象。
比如:插入日志、性能测试、事物处理、缓存、权限验证等,有了装饰器,就可以抽离出大量与函数功能本身无关的雷同代码并继续重用。
8、闭包
1.必须有一个内嵌函数
2.内嵌函数必须引用外部函数的变量(该函数包含对外作用域而不是全局作用域名字的引用)
3.外部函数的返回值必须是内嵌函数
9、迭代器与生成器
迭代可迭代对象对应_iter_(方法)和迭代器对应_next_(方法)的一个过程
迭代器就是一个封装了调用函数__next__的循环,让我们不用一步一步调用__next__函数
生成器:包括含有yield这个关键字,生成器也是迭代器,调动next把函数变成迭代器。
生成器,有两种表达方式:
生成器表达式:m=(i for i in range(10)) m.__next__()
生成器函数:其实就是由函数改造而来,具有生成能力的函数,标识:函数内部有yield,相当于return,但是可以执行多次
10、classmethod,staticmethod,property
类方法:由类调用; 至少一个cls参数;执行类方法时,自动将调用该方法的类名赋值给cls;
静态方法:此方法相当于给类扩展一个功能,将类内的函数实例化,给类或对象使用,此时类内的函数就是普通函数,不管是类还是实例化的对象都可以使用
属性:其实是普通方法的变种,具有方法的写作形式,具有字段访问形式;定义时,在普通方法的基础上添加 @property 装饰器,仅有一个self参数,调用时,无需括号;
11、常用的状态码
200--服务器成功返回网页
204--请求收到,但返回信息为空
304--客户端已经执行了GET,但文件未变化
400--错误请求,如语法错误
403--无权限访问
404--请求的页面不存在
500--服务器产生内部错误
12、多进程,多线程,协程,GIL
GIL:全局解释器锁,是锁在cpython解释器上,导致同一时刻,同一进程只能有一个线程被执行
多进程:多进程模块multiprocessing来实现,计算密集型用多进程,因为调用CPU,io密集型不占用CPU;
多线程:多线程模块threading来实现,IO密集型,多线程可以提高效率
协程:依赖于geenlet,对于多线程应用。cpu通过切片的方式来切换线程间的执行,遇到IO操作自动切换,线程切换时需要耗时,
而协程的好处是没有切换的耗时,没有锁定概念。
进程:是资源管理单位,进程是相互独立的,实现高并发
线程:是最小的执行单位,线程的出现为了降低上下文切换的消耗,提供系统的并发性
13、IO多路复用/异步非阻塞
IO多路复用:通过一种机制,可以监听多个描述符 select/poll/epoll
select:连接数受限,查找配对速度慢,数据由内核拷贝到用户态
poll:改善了连接数,但是还是查找配对速度慢,数据由内核拷贝到用户态
epoll:epoll是linux下多路复用IO接口,是select/poll的增强版,它能显著提高程序在大量并发连接中只有少量活跃的情况下的系统CPU利用率
异步非阻塞:异步体现在回调上,回调就是有消息返回时告知一声儿进程进行处理。非阻塞就是不等待,不需要进程等待下去,继续执行其他操作,不管其他进程的状态。
14、PEP8规范,规范的好处是什么?
1.缩进:4个空实现缩进,尽量不使用Tab
2.行:每行最大长度不超过79,换行可以使用反斜杠
3.命名规范:
4.注释规范:
15、range-and-xrange
都在循环时使用,xrange内存性能更好,xrange用法与range完全相同,range一个生成list对象,xrange是生成器
16、with上下文机制原理
_enter_和_exit_,上下文管理协议,即with语句,为了让一个对象兼容with语句,必须在这个对象类中声明_enter_和_exit_方法,
使用with语句的目的就是把代码块放入with中执行,with结束后,自动完成清理工作,无须收到干预
17、经典类、新式类
经典类遵循:深度优先,python2中,默认不继承object类
新式类遵循:广度优先,Python3中,默认继承object类
18、有没有一个工具可以帮助查找Python的bug和进行静态的代码分析?
PyChecker是一个Python代码的静态分析工具,它可以帮助查找Python代码的bug,会对代码的复杂度和格式提出警告,
Pylint是另外一个工具可以进行codingstandard检查
19、 Python是如何进行内存管理的
1.对象引用计数:
引用计数增加的情况:
来保持追踪内存中的对象,所有对象都用引用计数,一个对象分配一个新名称
将其放入一个容器中(列表,字典,元祖)
引用计数减少的情况:
使用del语句对对象别名显示的销毁
引用超出作用域或被重新赋值
sys.getrefcount()函数可以获得对象的当前引用计数
2.标记-清除机制
3.分代技术
20、什么是python?使用python有什么好处?
python是一种编程语言,它有对象、模块、线程、异常处理和自动内存管理。它简洁,简单、方便、容易扩展、有许多自带的数据结果,而且它开源
21、什么是pickling和unpickling?
Pickle模块读入任何python对象,将它们转换成字符串,然后使用dump函数将其转储到一个文件中——这个过程叫做pickling
反之从存储的字符串文件中提取原始python对象的过程,叫做unpickling
22、python是如何被解释的?
Python是一种解释性语言,它的源代码可以直接运行,Python解释器会将源代码转换成中间语言,之后再翻译成机器码再执行
23、数组和元祖之间的区别是什么?
数组和元祖之间的区别:数组内容可以被修改,而元祖内容是只读的,不可被修改的,另外元祖可以被哈希,比如作为字典的key
24、参数按值传递和引用传递是怎么实现的?
python中的一切都是类,所有的变量都是一个对象的引用。引用的值是由函数确定的,因此无法被改变,但是如果一个对象是可以被修改的,你可以改动对象
25、Python都有哪些自带的数据结构?
Python自带的数据结构分为可变和不可变的:可变的有:数组、集合、字典,不可变的是:字符串、元祖、整数
26、什么是python的命名空间?
在python中,所有的名字都存在于一个空间中,它们在改空间中存在和被操作——这就是命名空间,它就好像一个盒子,在每个变量名字都对应装着一个对象,
当查询变量的时候,会从该盒子里面寻找相应的对象
27、python中的unittest是什么?
在python中,unittest是python中的单元测试框架,它拥有支持共享搭建、自动测试、在测试中暂停代码、将不同测试迭代成一组
28、*args与**kwargs
*args代表位置参数,它会接收任意多个参数并把这些参数作为元祖传递给函数。**kwargs代表的关键字参数,返回的是字典,位置参数一定要放在关键字前面
29、在Python中什么是slicing?
slicing是一种在有序的对象类型中(数组、元祖、字符串)节选某一段的语法
30、中的docstring是什么?
Python中文档字符串被称为docstring,它在Python中的作用是为函数、模块和类注释生成文档
31、os与sys区别:
os是模块负责程序与操作系统的交互,提供了访问操作系统底层的接口
sys模块是负责程序与python解释器的交互,提供了一系列的函数和变量,用于操控Python时运行的环境
32、实现一个单例模式
_new_()在 _init_()之前被调用,用于生成实例对象。利用这个方法和类的属性的特点可以实现设计模式的单例模式。
单例模式是指创建唯一对象,单例模式设计的类只能实例,实例化1个对象
class Singleton(object):
__instance=None
def __init__(self):
pass
def __new__(cls, *args, **kwargs):
if Singleton.__instance is None:
Singleton.__instance=object.__new__(cls,*args,**kwargs)
return Singleton.__instance
33、算法(冒泡排序,选择排序,插入排序)
冒泡:首先,列表每两个相邻的数,如果前面的比后边的大,
那么交换这两个数,代码关键点:趟和无序区,
时间复杂度为:O(n2)
import random
def dublue_sort(li):
for i in range(len(li)-1):
exchange= False
for j in range(len(li)-i -1):
if li[j] > li[j+1]:
li[j],li[j+1] = li[j+1],li[j]
exchange = True
if not exchange:
return
return li
li=list(range(100))
random.shuffle(li)
print(li)
print(dublue_sort(li))
选择:一趟遍历记录最小的数,放到第一个位置,再一趟遍历记录剩余列表中最小的数,
继续放置,代码关键点:无序区和最小数的位置,时间复杂度为:O(n2)
def select_sort(li):
for i in range(len(li)-1): #i是趟
min_loc=i
#找i位置到最后位置范围内最小的数
for j in range(i,len(li)):
if li[j] < li[min_loc]:
min_loc = j
#和无序区第一个数作交换
li[min_loc],li[i] = li[i],li[min_loc]
return li
li=list(range(100))
random.shuffle(li)
print(select_sort(li))
插入:列表被分为有序区和无序区两个部分。最初有序区只有一个元素,
每次从无序区选择一个元素,插入到有序区的位置,直到无序区变空,
代码关键点:摸到的牌和手里的牌,时间复杂度为:O(n2)
def insert_sort(li):
for i in range(1,len(li)): #i 代表每次摸到的牌的下标
tmp=li[i]
j = i-1 # j代表手里最后一张牌的下标
while True:
if j < 0 or tmp >= li[j]:
break
li[ j + 1] = li [j]
j -=1
li[j+1] = tmp
li=list(range(100))
print(insert_sort(li))
二分:列表查找:从列表中查找指定元素,输入:列表、待查找元素,输出:元素下标或未查找到元素。
二分查找,从有序列表的候选区data[0:n]开始,通过对待查找的值与候选区中间值的比较,
可以使候选区减少一半。时间复杂为:O(logn)
def bin_search(data,val):
low=0
high=len(data)-1
while low <= high :
mid= (low+high) //2
if data[mid] == val:
return mid
elif data[mid] < high :
low = mid + 1
else:
high = mid - 1
return None
print(bin_search([1,2,3,4,5,6,7,8],4))
1、为什么学习Python?
python是目前市面上,我个人认为是最简洁&&最优雅&&最有钱途&&最全能的编程语言,没有之一。
python是全能语言,社区庞大,有太多的库和框架。你只需要找到合适的工具来实现想法,省去了造轮子的精力。
coder可以写尽可能少的代码来实现同等的功能。
如果实现一个中等业务复杂度的项目,在相同的时间要求内,用java实现要4-5个码农的话,用python实现也许只需要1个。这就是python最大的优势了。
2、通过什么途径学习的Python?
3、Python和Java、PHP、C、C#、C++等其他语言的对比?
coder可以写尽可能少的代码来实现同等的功能。
如果实现一个中等业务复杂度的项目,在相同的时间要求内,用java实现要4-5个码农的话,用python实现也许只需要1个。这就是python最大的优势了。
4、简述解释型和编译型编程语言?
解释型语言编写的程序不需要编译,在执行的时候,专门有一个解释器能够将Python语言翻译成机器语言,每个语句都是执行的时候才翻译。这样解释型语言每执行一次就要翻译一次,效率比较低。
用编译型语言写的程序执行之前,需要一个专门的编译过程,通过编译系统,把源高级程序编译成为机器语言文件,翻译只做了一次,运行时不需要翻译,所以编译型语言的程序执行效率高,但也不能一概而论,
部分解释型语言的解释器通过在运行时动态优化代码,甚至能够使解释型语言的性能超过编译型语言。
5、Python解释器种类以及特点?
Python是一门解释器语言,代码想运行,必须通过解释器执行,Python存在多种解释器,分别基于不同语言开发,每个解释器有不同的特点,但都能正常运行Python代码,以下是常用的五种Python解释器:
CPython
Cpython,这个解释器是用C语言开发的,所以叫 CPython,在命名行下运行python,就是启动CPython解释器,CPython是使用最广的Python解释器。
IPython
IPython是基于CPython之上的一个交互式解释器,也就是说,IPython只是在交互方式上有所增强,但是执行Python代码的功能和CPython是完全一样的,好比很多国产浏览器虽然外观不同,但内核其实是调用了IE。
PyPy
PyPy是另一个Python解释器,它的目标是执行速度,PyPy采用JIT技术,对Python代码进行动态编译,所以可以显著提高Python代码的执行速度。
Jython
Jython是运行在Java平台上的Python解释器,可以直接把Python代码编译成Java字节码执行。
IronPython
IronPython和Jython类似,只不过IronPython是运行在微软.Net平台上的Python解释器,可以直接把Python代码编译成.Net的字节码。
在Python的解释器中,使用广泛的是CPython,对于Python的编译,除了可以采用以上解释器进行编译外,技术高超的开发者还可以按照自己的需求自行编写Python解释器来执行Python代码,十分的方便!
6、位和字节的关系?
位:我们常说的bit,位就是传说中提到的计算机中的最小数据单位:在计算机中的二进制数系统中,位,简记为b,也称为比特,每个0或1就是一个位。说白了就是0或者1;
字节:英文单词:(byte),byte是存储空间的基本计量单位。1byte 存1个英文字母,utf8编码中3个byte存一个汉字,gbk编码中2个字节一个汉字。规定上是1个字节等于8个比特(1Byte = 8bit),可区别256(2的8次方)个数字,取值范围:0到255。 Byte是从0-255的无符号类型,所以不能表示负数。
数据存储是以“字节”(Byte)为单位,数据传输是以大多是以“位”(bit,又名“比特”)为单位,一个位就代表一个0或1(即二进制),每8个位(bit,简写为b)组成一个字节(Byte,简写为B),是最小一级的信息单位。
7、b、B、KB、MB、GB 的关系?
KB 1KB=1024B
MB 1MB=1024KB
GB 1GB=1024MB
TB 1TB=1024GB
1PB = 1000TB
1EB = 1000PB
8、请至少列举5个 PEP8 规范(越多越好)。
1. 分号:不要在行尾加分号, 也不要用分号将两条命令放在同一行。
2. 行长度:
- 每行不超过80个字符(长的导入模块语句和注释里的URL除外)
- 不要使用反斜杠连接行。Python会将圆括号, 中括号和花括号中的行隐式的连接起来 :
- 如果一个文本字符串在一行放不下, 可以使用圆括号来实现隐式行连接:
- 在注释中,如果必要,将长的URL放在一行上。
3. 括号:宁缺毋滥的使用括号,除非是用于实现行连接, 否则不要在返回语句或条件语句中使用括号. 不过在元组两边使用括号是可以的.
4. 缩进:用4个空格来缩进代码,不要用tab, 也不要tab和空格混用. 对于行连接的情况, 你应该要么垂直对齐换行的元素(见 :ref:行长度 <line_length> 部分的示例), 或者使用4空格的悬挂式缩进(这时第一行不应该有参数):
5. 空行:顶级定义之间空2行, 方法定义之间空1行,顶级定义之间空两行, 比如函数或者类定义. 方法定义, 类定义与第一个方法之间, 都应该空一行. 函数或方法中, 某些地方要是你觉得合适, 就空一行.
6. 空格:
- 按照标准的排版规范来使用标点两边的空格,括号内不要有空格,按照标准的排版规范来使用标点两边的空格
- 不要在逗号, 分号, 冒号前面加空格, 但应该在它们后面加(除了在行尾).
- 参数列表, 索引或切片的左括号前不应加空格.
- 在二元操作符两边都加上一个空格, 比如赋值(=), 比较(==, <, >, !=, <>, <=, >=, in, not in, is, is not), 布尔(and, or, not). 至于算术操作符两边的空格该如何使用, 需要你自己好好判断. 不过两侧务必要保持一致.
- 当’=’用于指示关键字参数或默认参数值时, 不要在其两侧使用空格.
- 不要用空格来垂直对齐多行间的标记, 因为这会成为维护的负担(适用于:, #, =等):
7. 注释:
- 文档字符串: Python有一种独一无二的的注释方式: 使用文档字符串。文档字符串是包, 模块, 类或函数里的第一个语句. 这些字符串可以通过对象的doc成员被自动提取, 并且被pydoc所用。 对文档字符串的惯例是使用三重双引号”“”。
- 函数和方法: 每节应该以一个标题行开始. 标题行以冒号结尾. 除标题行外, 节的其他内容应被缩进2个空格. 列出每个参数的名字, 并在名字后使用一个冒号和一个空格, 分隔对该参数的描述.如果描述太长超过了单行80字符,使用2或者4个空格的悬挂缩进(与文件其他部分保持一致). 描述应该包括所需的类型和含义. 如果一个函数接受*foo(可变长度参数列表)或者**bar (任意关键字参数), 应该详细列出*foo和**bar.
- Returns: (或者 Yields: 用于生成器) 描述返回值的类型和语义. 如果函数返回None, 这一部分可以省略.
- 类: 类应该在其定义下有一个用于描述该类的文档字符串. 如果你的类有公共属性(Attributes), 那么文档中应该有一个属性(Attributes)段. 并且应该遵守和函数参数相同的格式.
- 块注释和行注释: 最需要写注释的是代码中那些技巧性的部分. 如果你在下次 代码审查 的时候必须解释一下, 那么你应该现在就给它写注释. 对于复杂的操作, 应该在其操作开始前写上若干行注释. 对于不是一目了然的代码, 应在其行尾添加注释.为了提高可读性, 注释应该至少离开代码2个空格.
8、字符串:
- 避免在循环中用+和+=操作符来字符串拼接. 由于字符串是不可变的, 这样做会创建不必要的临时对象, 并且导致二次方而不是线性的运行时间. 作为替代方案, 你可以将每个子串加入列表, 然后在循环结束后用 ” .join(列表对象,连接符号) 连接列表. (也可以将每个子串写入一个 cStringIO.StringIO 缓存中.)
- 在同一个文件中, 保持使用字符串引号的一致性. 使用单引号’或者双引号”之一用以引用字符串, 并在同一文件中沿用. 在字符串内可以使用另外一种引号, 以避免在字符串中使用. PyLint已经加入了这一检查.
- 为多行字符串使用三重双引号”“”而非三重单引号”’. 当且仅当项目中使用单引号’来引用字符串时, 才可能会使用三重”’为非文档字符串的多行字符串来标识引用. 文档字符串必须使用三重双引号”“”. 不过要注意, 通常用隐式行连接更清晰, 因为多行字符串与程序其他部分的缩进方式不一致.
9、文件和sockets
- 在文件和sockets结束时, 需要显式的关闭它.
10、导入格式:每个导入应该独占一行
11、命名:
应该避免的名称:
单字符名称, 除了计数器和迭代器.
包/模块名中的连字符(-)
双下划线开头并结尾的名称(Python保留, 例如init)命名约定:
所谓”内部(Internal)”表示仅模块内可用, 或者, 在类内是保护或私有的.
用单下划线(_)开头表示模块变量或函数是protected的(使用import * from时不会包含).
用双下划线(__)开头的实例变量或方法表示类内私有.
将相关的类和顶级函数放在同一个模块里. 不像Java, 没必要限制一个类一个模块.
对类名使用大写字母开头的单词(如CapWords, 即Pascal风格), 但是模块名应该用小写加下划线的方式(如lower_with_under.py). 尽管已经有很多现存的模块使用类似于CapWords.py这样的命名, 但现在已经不鼓励这样做, 因为如果模块名碰巧和类名一致, 这会让人困扰.
12、Main:
- 即使是一个打算被用作脚本的文件, 也应该是可导入的. 并且简单的导入不应该导致这个脚本的主功能(main functionality)被执行, 这是一种副作用. 主功能应该放在一个main()函数中.
- 在Python中, pydoc以及单元测试要求模块必须是可导入的. 你的代码应该在执行主程序前总是检查 if name == ‘main’ , 这样当模块被导入时主程序就不会被执行.
- 所有的顶级代码在模块导入时都会被执行. 要小心不要去调用函数, 创建对象, 或者执行那些不应该在使用pydoc时执行的操作.
9、通过代码实现如下转换:
二进制转换成十进制:v = “0b1111011”
十进制转换成二进制:v = 18
八进制转换成十进制:v = “011”
十进制转换成八进制:v = 30
十六进制转换成十进制:v = “0x12”
十进制转换成十六进制:v = 87

#bin()接受一个十进制,转换成一个二进制
print(bin(8))#结果为0b1000,0b为二进制标识,8的二进制为1000
#oct()十进制转八进制
print(oct(9))#结果为0o11,0o标识八进制
#hex()十进制转十六进制
print(hex(15))#结果为0xf,0x标识十六进制
11、python递归的最大层数?
import sys
sys.setrecursionlimit(100000)
def func(n):
print(n)
n += 1
func(n)
if __name__ == "__main__":
func(1)
#默认是996左右,加上sys之后3924-3929之间浮动
13、ascii、unicode、utf-8、gbk 区别?
ascii
开始计算机只在美国用。八位的字节一共可以组合出256(2的8次方)种不同的状态。所有的空 格、标点符号、数字、大小写字母分别用连续的字节状态表示,一直编到了第127号,这样计算机就可以用不同字节来存储英语的文字了;于是大家都把这个方案叫做 ANSI 的”Ascii”编码(American Standard Code for Information Interchange,美国信息互换标准代码)。
后来,世界各地的都开始使用计算机,但是很多国家用的不是英文,他们的字母里有许多是ASCII里没有的,为了可以在计算机 保存他们的文字,他们决定采用 127号之后的空位来表示这些新的字母、符号,还加入了很多画表格时需要用下到的横线、竖线、交叉等形状,一直把序号编到了最后一个状态255。从128 到255这一页的字符集被称”扩展字符集“。
unicode
ISO (国际标谁化组织)废了所有的地区性编码方案,重新搞一个包括了地球上所有文化、所有字母和符号 的编码,简称 UCS, 俗称 “unicode“。在unicode中,无论是半角的英文字母,还是全角的汉字,它们都是统一的”一个字符“!同时,也都是统一的”两个字节“,一个汉字算两个英文字符的时代已经快过去了。
utf-8
unicode同样也不完美,这里就有两个的问题,一个是,如何才能区别unicode和ascii?计算机怎么知道三个字节表示一个符号,而不是 分别表示三个符号呢?第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果unicode统一规定,每个符号用三个或四个字节表示,那么每 个英文字母前都必然有二到三个字节是0,这对于存储空间来说是极大的浪费,文本文件的大小会因此大出二三倍,这是难以接受的。unicode在很长一段时间内无法推广,直到互联网的出现,为解决unicode如何在网络上传输的问题,于是面向传输的众多UTF(UCS Transfer Format)标准出现了
UTF-8就是每次8个位传输数据,最大的一个特点就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度,当字符在ASCII 码的范围时,就用一个字节表示,保留了ASCII字符一个字节的编码做为它的一部分,注意的是unicode一个中文字符占2个字节,而UTF-8一个中 文字符占3个字节)。从unicode到uft-8并不是直接的对应,而是要过一些算法和规则来转换。
GBK
把那些127号之后的奇异符号们直接取消掉, 规定:一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,这样我们就可以组合出大约7000多个简体汉字了,我们还把数学符号、罗马希腊的 字母、日文的假名们都编进去了,连在 ASCII 里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的”全角”字符,而原来在127号以下的那些就叫”半角”字符了。 中国人民看到这样很不错,于是就把这种汉字方案叫做“GB2312“。GB2312 是对 ASCII 的中文扩展。但是中国的汉字太多了,我们很快就就发现有许多人的人名没有办法在这里打出来,继续把 GB2312 没有用到的码位找出来不客气地用上,只要第一个字节是大于127就固定表示这是一个汉字的开始,不管后面跟的是不是扩展字 符集里的内容。结果扩展之后的编码方案被称为 GBK 标准,GBK包括了GB2312 的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。
四、RESTful API设计指南(7题)
1、协议
API与用户的通信协议,总是使用HTTPs协议
2、域名
应该尽量将API部署在专用域名之下
https://api.example.com
如果确定API很简单,不会有进一步扩展,可以考虑放在主域名下
https://example.org/api/
3、版本
应该将API的版本号放入URL
https://api.example.com/v1/
另一种做法是:将版本号放在HTTP头信息中,
4、路径
https://api.example.com/v1/zoos
https://api.example.com/v1/animals
https://api.example.com/v1/employees
5、动词
对于资源的具体操作类型,由HTTP动词表示
GET(SELECT):从服务器取出资源(一项或多项)。
POST(CREATE):在服务器新建一个资源。
PUT(UPDATE):在服务器更新资源(客户端提供改变后的完整资源)。
PATCH(UPDATE):在服务器更新资源(客户端提供改变的属性)。
DELETE(DELETE):从服务器删除资源。
还有两个不常用的HTTP动词
GET /zoos:列出所有动物园
POST /zoos:新建一个动物园
GET /zoos/ID:获取某个指定动物园的信息
PUT /zoos/ID:更新某个指定动物园的信息(提供该动物园的全部信息)
PATCH /zoos/ID:更新某个指定动物园的信息(提供该动物园的部分信息)
DELETE /zoos/ID:删除某个动物园
GET /zoos/ID/animals:列出某个指定动物园的所有动物
DELETE /zoos/ID/animals/ID:删除某个指定动物园的指定动物
6、过滤信息(Filtering)
如果记录数量很多,服务器不可能都将它们返回给用户,API应该提供参数,过滤返回结果
?limit=10:指定返回记录的数量
?offset=10:指定返回记录的开始位置。
?page=2&per_page=100:指定第几页,以及每页的记录数。
?sortby=name&order=asc:指定返回结果按照哪个属性排序,以及排序顺序。
?animal_type_id=1:指定筛选条件
7、状态码(Status Code)
200 OK - [GET]:服务器成功返回用户请求的数据,该操作是幂等的(Idempotent)。
201 CREATED - [POST/PUT/PATCH]:用户新建或修改数据成功。
202 Accepted - [*]:表示一个请求已经进入后台排队(异步任务)
204 NO CONTENT - [DELETE]:用户删除数据成功。
400 INVALID REQUEST - [POST/PUT/PATCH]:用户发出的请求有错误,服务器没有进行新建或修改数据的操作,该操作是幂等的。
401 Unauthorized - [*]:表示用户没有权限(令牌、用户名、密码错误)。
403 Forbidden - [*] 表示用户得到授权(与401错误相对),但是访问是被禁止的。
404 NOT FOUND - [*]:用户发出的请求针对的是不存在的记录,服务器没有进行操作,该操作是幂等的。
406 Not Acceptable - [GET]:用户请求的格式不可得(比如用户请求JSON格式,但是只有XML格式)。
410 Gone -[GET]:用户请求的资源被永久删除,且不会再得到的。
422 Unprocesable entity - [POST/PUT/PATCH] 当创建一个对象时,发生一个验证错误。
500 INTERNAL SERVER ERROR - [*]:服务器发生错误,用户将无法判断发出的请求是否成功。
五、补充
1、列表
def func(arg,li=[]):
li.append(arg)
return li v1=func(1)
# print(v1) #[1]
v2=func(2,[])
# print(v2) #[2]
v3=func(3)
# print(v3) #[1, 3] # 代码从上到下解释的时候li=[]已经开辟了一块内存
# v1和v3用的是同一块内存
# v2重新开辟了一块内存
print(v1) #[1, 3]
print(v2) #[2]
print(v3) #[1, 3] n1 = [1,2,3,4,5]
n2 = n1
n3 = n1[:]
n1[0] = 66
n3[1] = 99 #n1,n2指向同一块内存,一起改变
#切片会重新开辟一块内存
print(n1) #[66, 2, 3, 4, 5]
print(n2) #[66, 2, 3, 4, 5]
print(n3) #[1, 99, 3, 4, 5]
2、JavaScript
- 代码在编译阶段,作用域就已经确定
#作用域,一个函数就是一个作用域
var v=123;
function func(){
var v=456;
function inner(){
console.log(v);
}
return inner;
}
ret = func()
console.log(ret())
#输出结果:456
3、js中的函数代指类,首字母一般大写的认为是类
this相当于Python中的self
每个函数中都有一个this
如果是创建对象obj=new Func(),this指的是obj,如果是执行函数Func(),指的就是window
js中无字典,只有对象,定义一个字典类型的数据相当于创建一个对象
#js中没有类,函数代指,函数名开头大写时,一般是类
Name='root';
Age=18;
function Foo(name,age){
this.Name=name;
this.Age=age;
this.Func=function(){
console.log(this.Name,this.Age);
(function(){
console.log(this.Name,this.Age);
})();
}
}
#创建对象
obj=new Foo('charlie',30);#以对象方式调用,this=obj,charlie
obj.Func()#以函数方式调用,this=window.Name,就是root
#输出结果: charlie 30 root 18
4、copy列表,修改原表和新表的值,互不影响;列表中嵌套的列表只是一个地址,无论修改原列表中还是复制列表中的嵌套列表,嵌套的列表中的
值都会被改变。如果想改变嵌套列表中的值时,两个列表互不影响,就要使用函数deepcopy()
#调出copy库
import copy
number=[10,22,56,[33,10,45],99,34]
number2=number.copy() #普通copy
number[1]=200
number2[1]=500
number[3][0]=''
number2[3][1]=''
print(number)
print(number2)
#深度copy,完全复制嵌套列表中的数值,两个列表互不影响
number3=copy.deepcopy(number)
number[3][0]='aaa'
number3[3][1]='jjjj'
print(number)
print(number3)
5、三元运算,也叫三目运算,就是把简单的if--else--语句,合并成一句
#如果if后面的条件成立,就返回前面的值,不成立,返回后面的值
name = 'alex' if 1==1 else 'sb'
6、列表+lambda表达式+for循环,函数在执行之前,函数内部代码不执行,函数中的变量由for循环定义,变量一直被重新赋值,直到循环结束,变量等于最后一个循环的值,列表
内部元素是函数,函数加()表示执行函数,得到返回值
li = [lambda :x for x in range(10)]
ret1 = li[0]()
ret2 = li[9]()
print(ret1)#
print(ret2)# #每执行一次循环,函数的参数就被重新赋值,所以函数内部的变量是已经被定好的
li = [lambda x=i:x for i in range(10)]
ret1 = li[0]()
ret2 = li[1]()
ret9 = li[9]()
print(ret1)#
print(ret2)#
print(ret9)#
7、单例模式
class Foo:
#单例模式
instance = None
def __init__(self,name):
self.name = name
@classmethod
def get_instance(cls):
if cls.instance:
return cls.instance
else:
obj = cls('alex')
cls.instance = obj
return obj
obj1 = Foo.get_instance()
print(obj1)
obj2 = Foo.get_instance()
print(obj2)
#两个对象一模一样
# <__main__.Foo object at 0x000000B059AC92E8>
# <__main__.Foo object at 0x000000B059AC92E8>
class F1:
#普通模式
def __init__(self,name):
self.name = name
f1 = F1('alex')
print(f1)
f2 = F1('alex')
print(f2)
#普通模式,参数一样时两个对象也不一样
# <__main__.F1 object at 0x0000003E04762400>
# <__main__.F1 object at 0x0000003E04762550>
8、冒泡排序
需求:请按照从小到大对列表 [13, 22, 6, 99, 11] 进行排序
思路:相邻两个值进行比较,将较大的值放在右侧,依次比较!
li = [13, 22, 6, 99, 11]
for i in range(1,5):
for m in range(len(li)-i):
if li[m] > li[m+1]:
temp = li[m+1]
li[m+1] = li[m]
li[m] = temp print(li)# [6, 11, 13, 22, 99]
9、反射
'''
反射
利用字符串的形式去对象(模块)中(寻找/检查/删除/设置)成员
getattr()寻找、hasattr()检查、delattr()删除、setattr()设置
通过字符串导入模块:
obj = __import__("xxx")
obj = __import__("file.xxx", fromlist=True)
'''
def func():
inp = input("请输入你要访问的URL(模块名/函数名):")
#hasattr()检查对象中是否包含该成员,是返回True
m, h = inp.split("/")
#__import__通过字符串导入模块,obj.func()调用函数
obj = __import__(m)
#如果模块在文件夹中,后面加个参数fromlist,意思是按前面的指定路径导入
#obj = __import__("lib." + m, fromlist=True)
if hasattr(obj,h):
#getattr()获取对象中的成员
func = getattr(obj,h)
func()
else:
print("")
10、递归
# 递归实现斐波那契数列 0, 1, 1, 2, 3, 5, 8, 13, 21, 34,
def func(arg1,arg2):
if arg1 == 0:
print(arg1)
print(arg2)
arg3 = arg1 + arg2
print(arg3)
if arg3>5000:
return
return func(arg2, arg3)
func(0,1)
11、阶乘
n = 1
for i in range(1,5):
n *= i
print(n) #
12、阶加
n = sum(range(101))
print(n)#
Python面试笔记一的更多相关文章
- Python面试笔记二
一.算法 1.归并排序 2.快速排序 3.算法复杂度 4.哈希表数据结构 二.数据库 1.设计一个用户关注系统的数据库表 1.设计一个用户关注系统的数据库表,写三个相关的SQL语句两张表,一张user ...
- Python面试笔记三
1. 类继承 有如下的一段代码: python对象 如何调用类A的show方法了,方法如下: python对象 __class__方法指向了类对象,只用给他赋值类型A,然后调用方法show,但是用完了 ...
- Python面试笔记四
数据库 1.将name字段添加索引 create index index_emp_name on student(name); 2.查询女生中数学成绩最高的分数 select max(score) f ...
- Python机器学习笔记:不得不了解的机器学习面试知识点(1)
机器学习岗位的面试中通常会对一些常见的机器学习算法和思想进行提问,在平时的学习过程中可能对算法的理论,注意点,区别会有一定的认识,但是这些知识可能不系统,在回答的时候未必能在短时间内答出自己的认识,因 ...
- python学习笔记目录
人生苦短,我学python学习笔记目录: week1 python入门week2 python基础week3 python进阶week4 python模块week5 python高阶week6 数据结 ...
- 服务器文档下载zip格式 SQL Server SQL分页查询 C#过滤html标签 EF 延时加载与死锁 在JS方法中返回多个值的三种方法(转载) IEnumerable,ICollection,IList接口问题 不吹不擂,你想要的Python面试都在这里了【315+道题】 基于mvc三层架构和ajax技术实现最简单的文件上传 事件管理
服务器文档下载zip格式 刚好这次项目中遇到了这个东西,就来弄一下,挺简单的,但是前台调用的时候弄错了,浪费了大半天的时间,本人也是菜鸟一枚.开始吧.(MVC的) @using Rattan.Co ...
- 我的python面试简历
分享前一段我的python面试简历,自我介绍这些根据你自己的来写就行,这里着重分享下我的项目经验.公司职责情况(时间倒序),不一定对每个人适用,但是有适合你的点可以借鉴 我的真实经验:(14年毕业,化 ...
- Web Scraping with Python读书笔记及思考
Web Scraping with Python读书笔记 标签(空格分隔): web scraping ,python 做数据抓取一定一定要明确:抓取\解析数据不是目的,目的是对数据的利用 一般的数据 ...
- python学习笔记整理——字典
python学习笔记整理 数据结构--字典 无序的 {键:值} 对集合 用于查询的方法 len(d) Return the number of items in the dictionary d. 返 ...
随机推荐
- 使用xUnit为.net core程序进行单元测试 -- Assert
第一部分: http://www.cnblogs.com/cgzl/p/8283610.html Assert Assert做什么?Assert基于代码的返回值.对象的最终状态.事件是否发生等情况来评 ...
- python3安装sklearn机器学习库
安装sklearn需要的库请全部在万能仓库下载: http://www.lfd.uci.edu/~gohlke/pythonlibs/#scipy http://www.lfd.uci.edu/~go ...
- 【从零开始自制CPU之学习篇00】开篇
从今天开始决定用面包板制作一个8位的CPU,实现几个简单的指令.我给自己分两大部分计划,第一部分是学习制作CPU的理论知识,第二部分是实践.并打算实施计划的同时用博客的方式记录下来.理论知识的部分重点 ...
- 根据地址查询经纬度Js
<html xmlns="http://www.w3.org/1999/xhtml"> <head> <title>根据地址查询经纬度</ ...
- C#版 - Leetcode 633. 平方数之和 - 题解
版权声明: 本文为博主Bravo Yeung(知乎UserName同名)的原创文章,欲转载请先私信获博主允许,转载时请附上网址 http://blog.csdn.net/lzuacm. C#版 - L ...
- 带着新人学springboot的应用12(springboot+Dubbo+Zookeeper 下)
上半节已经下载好了Zookeeper,以及新建了两个应用provider和consumer,这一节我们就结合dubbo来测试一下分布式可不可以用. 现在就来简单用一下,注意:这里只是涉及最简单的部分, ...
- ELK-log4j2异步输出+logstash
1.pom.xml配置文件 <dependency> <groupId>log4j</groupId> <artifactId>log4j</ar ...
- C++STL模板库序列容器之deque
目录 一丶队列容器deque简介 二丶使用代码演示 一丶队列容器deque简介 deque底层跟vector一样,都是数组维护.不同的是可以操作头部. 二丶使用代码演示 #define _CRT_SE ...
- Spring Boot 2.x(十四):整合Redis,看这一篇就够了
目录 Redis简介 Redis的部署 在Spring Boot中的使用 Redis缓存实战 寻找组织 程序员经典必备枕头书免费送 Redis简介 Redis 是一个开源的使用 ANSI C 语言编写 ...
- 《C#并发编程经典实例》学习笔记—2.4 等待一组任务完成
问题 执行几个任务,等待它们全部完成. 使用场景 几个独立任务需要同时进行 UI界面加载多个模块,并发请求 解决方案 Task.WhenAll 传入若干任务,当所有任务完成时,返回一个完成的任务. 重 ...