使用Spark进行搜狗日志分析实例——map join的使用
map join相对reduce join来说,可以减少在shuff阶段的网络传输,从而提高效率,所以大表与小表关联时,尽量将小表数据先用广播变量导入内存,后面各个executor都可以直接使用
package sogolog
import org.apache.hadoop.io.{LongWritable, Text}
import org.apache.hadoop.mapred.TextInputFormat
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
class RddFile {
def readFileToRdd(path: String): RDD[String] = {
val conf = new SparkConf().setMaster("local").setAppName("sougoDemo")
val sc = new SparkContext(conf);
//使用这种方法能够避免中文乱码
readFileToRdd(path,sc)
}
def readFileToRdd(path: String,sc :SparkContext): RDD[String] = {
//使用这种方法能够避免中文乱码
sc.hadoopFile(path,classOf[TextInputFormat], classOf[LongWritable], classOf[Text]).map{
pair => new String(pair._2.getBytes, 0, pair._2.getLength, "GBK")}
}
}
package sogolog
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
import scala.collection.mutable.ArrayBuffer
object MapSideJoin {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("sougoDemo")
val sc = new SparkContext(conf);
val userRdd = new RddFile().readFileToRdd("J:\\scala\\workspace\\first-spark-demo\\sougofile\\user",sc)
//解析用户信息
val userMapRDD:RDD[(String,String)] = userRdd.map(line=>(line.split("\t")(0),line.split("\t")(1)))
//将用户信息设置为广播变量,方便各个任务引用
val userMapBroadCast =sc.broadcast(userMapRDD.collectAsMap())
val searchLogRdd = new RddFile().readFileToRdd("J:\\scala\\workspace\\first-spark-demo\\sougofile\\SogouQ.reduced",sc)
val joinResult = searchLogRdd.mapPartitionsWithIndex((index,f)=>{
val userMap = userMapBroadCast.value
var result = ArrayBuffer[String]()
var count = 0
//搜索日志表join用户表
//原来日志列为:时间 用户ID 关键词 排名 URL
//新的日志列为:时间 用户ID 用户名 关键词 排名 URL
f.foreach( log=>{
count=count+1;
val lineArrs = log.split("\t")
val uid = lineArrs(1)
val newLine:StringBuilder = new StringBuilder()
if(userMap.contains(uid)){
newLine.append(lineArrs(0)).append("\t")
newLine.append(lineArrs(1)).append("\t")
newLine.append(userMap.get(uid).get).append("\t") //从广播变量中根据用户ID获取用户名
for (i<- 2 to lineArrs.length-1){
newLine.append(lineArrs(i)).append("\t")
}
result .+= (newLine.toString())
}
})
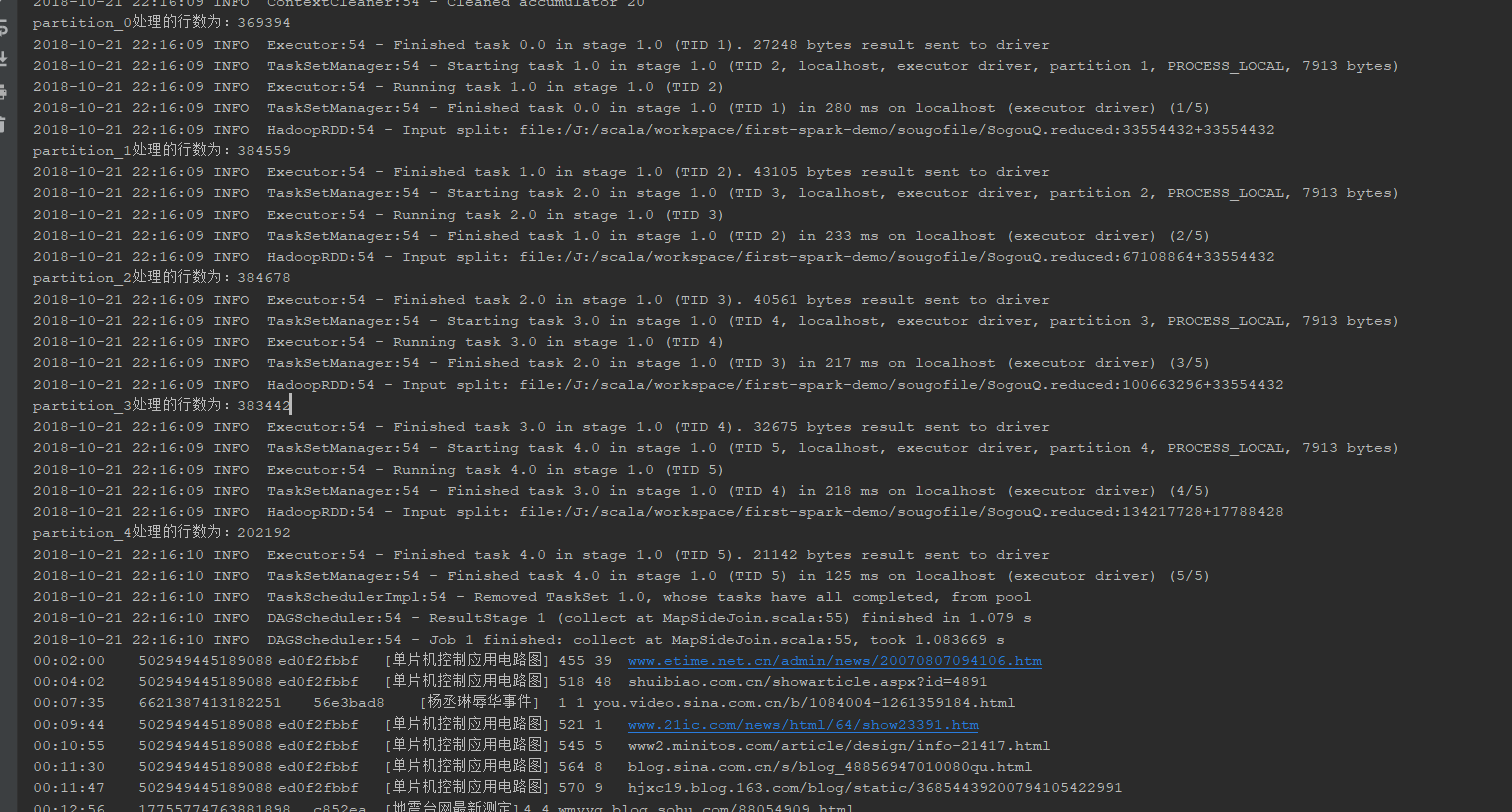
println("partition_"+index+"处理的行数为:"+count)
result.iterator
})
//打印结果
joinResult.collect().foreach(println)
}
}
结果展示:
使用Spark进行搜狗日志分析实例——map join的使用的更多相关文章
- 使用Spark进行搜狗日志分析实例——统计每个小时的搜索量
package sogolog import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /* ...
- 使用Spark进行搜狗日志分析实例——列出搜索不同关键词超过10个的用户及其搜索的关键词
package sogolog import org.apache.hadoop.io.{LongWritable, Text} import org.apache.hadoop.mapred.Tex ...
- ELK 日志分析实例
ELK 日志分析实例一.ELK-web日志分析二.ELK-MySQL 慢查询日志分析三.ELK-SSH登陆日志分析四.ELK-vsftpd 日志分析 一.ELK-web日志分析 通过logstash ...
- Spark之搜狗日志查询实战
1.下载搜狗日志文件: 地址:http://www.sogou.com/labs/resource/chkreg.php 2.利用WinSCP等工具将文件上传至集群. 3.创建文件夹,存放数据: mk ...
- 基于Spark的网站日志分析
本文只展示核心代码,完整代码见文末链接. Web Log Analysis 提取需要的log信息,包括time, traffic, ip, web address 进一步解析第一步获得的log信息,如 ...
- spark提交异常日志分析
java.lang.NoSuchMethodError: org.apache.spark.sql.SQLContext.sql(Ljava/lang/String;)Lorg/apache/spar ...
- Spark RDD/Core 编程 API入门系列之动手实战和调试Spark文件操作、动手实战操作搜狗日志文件、搜狗日志文件深入实战(二)
1.动手实战和调试Spark文件操作 这里,我以指定executor-memory参数的方式,启动spark-shell. 启动hadoop集群 spark@SparkSingleNode:/usr/ ...
- 024 关于spark中日志分析案例
1.四个需求 需求一:求contentsize的平均值.最小值.最大值 需求二:请各个不同返回值的出现的数据 ===> wordCount程序 需求三:获取访问次数超过N次的IP地址 需求四:获 ...
- Spark SQL慕课网日志分析(1)--系列软件(单机)安装配置使用
来源: 慕课网 Spark SQL慕课网日志分析_大数据实战 目标: spark系列软件的伪分布式的安装.配置.编译 spark的使用 系统: mac 10.13.3 /ubuntu 16.06,两个 ...
随机推荐
- Nodejs运行错误小结
(迁移自旧博客2017 04 15) 在使用过程中会遇到一些问题,学习过程中不定期更新. 问题一 错误如下 **events.js:72 throw er; // Unhandled 'error' ...
- 剑指offer 06:旋转数组的最小数字
题目描述把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转. 输入一个非减排序的数组的一个旋转,输出旋转数组的最小元素. 例如数组{3,4,5,1,2}为{1,2,3,4,5}的一个旋转 ...
- LEETCODE 07 09
最近忙着面试耽误了几天,今天刷了07,09都是字符串处理,一个是大数反转,一个是回文数判断,我都是转成字符串处理的,过了是过了,但是挺慢的,先记着,等有机会优化下 题目 给定一个 32 位有符号整数, ...
- 本地连接属性:Internet协议版本4(TCP/IPv4)打开闪退解决办法
1.命令窗口配置网络连接指定IP netsh interface ip set address "本地连接" static IP地址 子网掩码 默认网关 例:netsh inter ...
- C语言多种方法求解字符串编辑距离问题的代码
把做工程过程经常用的内容记录起来,如下内容段是关于C语言多种方法求解字符串编辑距离问题的内容. { if(xbeg > xend) { if(ybeg > yend) return 0; ...
- Cocos Creator学习五:触摸和重力传感响应事件
1.移动设备上主要涉及触摸响应事件以及重力传感响应事件的处理. 事件主要分两类: 针对节点事件处理的节点响应事件cc.Node.EventType(主要是触摸响应事件和鼠标响应事件): 针对全局系统事 ...
- 移动vue项目,启动错误:Module build failed: Error: No PostCSS Config found in:
解决办法:在根目录新建postcss.config.js module.exports = { plugins: { 'autoprefixer': {browsers: 'last 5 versio ...
- MariaDB主从复制,redis发布订阅,持久化,以及主从同步
一. MariaDB主从复制 mysql基本操作 1 连接数据库 mysql -u root -p -h 127.0.0.1 mysql -u root -p -h 192.168.12.60 2 ...
- Genymotion下载及安装
引用https://blog.csdn.net/yht2004123/article/details/80146989 一.注册\登录 打开Genymotion官网,https://www.genym ...
- python 数据分析基础
安装Python基础的几个数据分析库: pip install pandas pip install numpy pip install scipy pip install scikit-surpri ...