理解JS深拷贝
前言:
JS的拷贝(copy),之所以分为深浅两种形式,是因为JS变量的类型存在premitive(字面量)与reference(引用)两种区别。当然,大多数编程语言都存在这种特性。
众所周知,内存包含的结构中,有堆与栈。在JS里,字面量类型变量存放在栈中,储存的是它的值,而引用类型变量虽然在栈中也占有空间,但储存的只是一个内存地址(通过该地址可以索引找到真实结构所在的内存区域),它的真实结构是存在于堆中的。如下图所示:
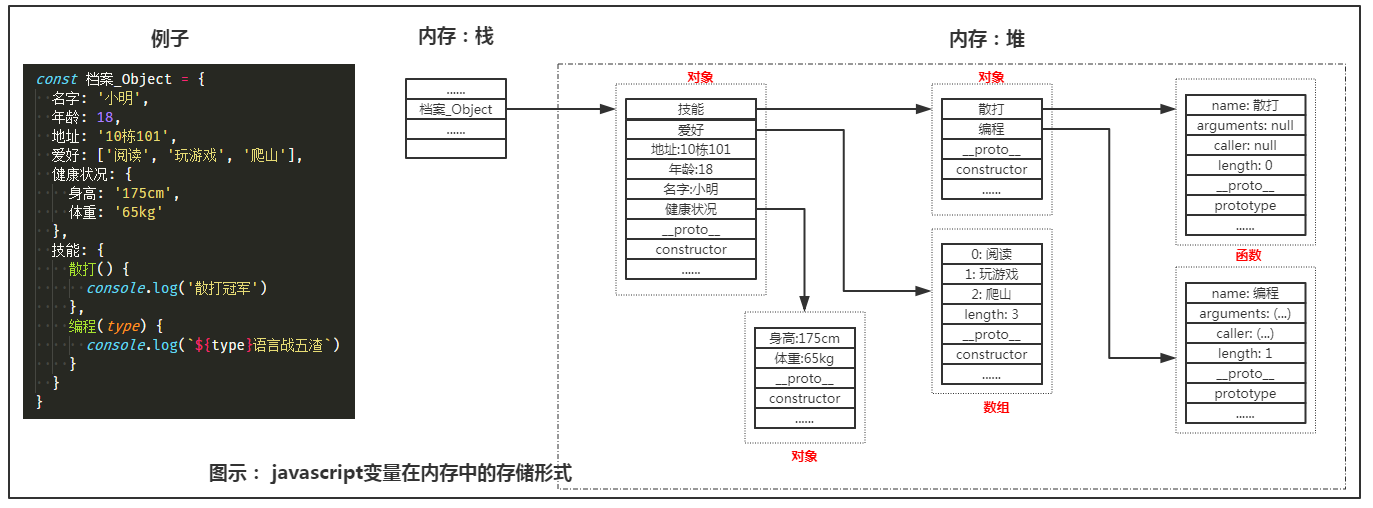
结合图示来看,一般来说,浅拷贝只是拷贝了内存栈中的数据,深拷贝,则是要沿着引用类型变量的真实内存地址,去进行一次次的深度遍历,直到拷贝完目标遍历在栈与堆中的所有真实值。
一、浅拷贝的实现
JS实现了一些拥有浅拷贝功能的接口,比如解构赋值的rest模式、Object.assgin。
但浅拷贝的缺陷在于,进行拷贝之后,如果改变了被拷贝目标的某个引用属性的值,则拷贝结果的对应属性的值也会发生改变,反过来亦是如此。
比如将example['爱好'][0]赋予新值 ('听歌'),如下图所示。

从本质上来说,就是因为两者都指向同一个内存区域。那片内存区域一旦发生了变动,自然两者取到的值都发生改变,而且完全一样。
二、深拷贝的实现
深拷贝的原理,前文已经叙述过,但过于抽象,还不够具体。
JS里,可以利用原生的JSON序列化与反序列化接口组合进行实现深拷贝。
如下图所示,深拷贝的结果与被拷贝的目标之间,已经互不影响。

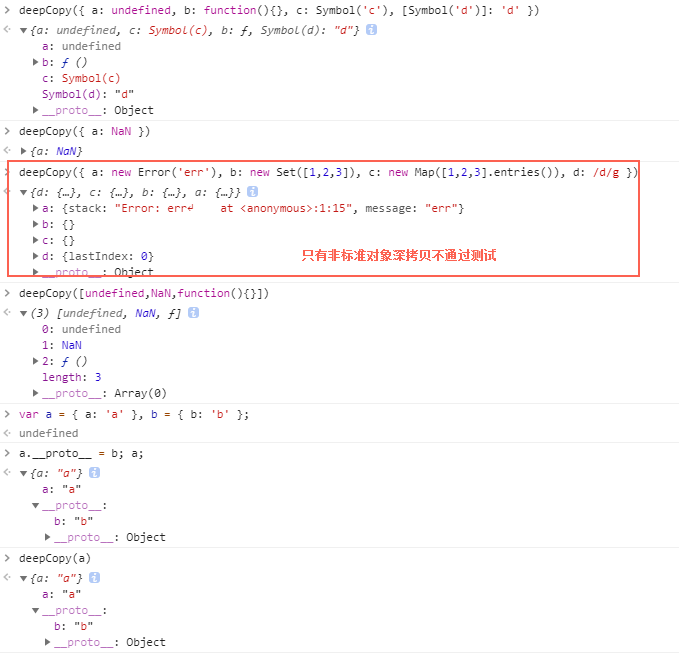
不过,JSON方式实现的深拷贝,有很多缺陷,首先,是拷贝失真:
1. 值为undefined、函数、Symbol的属性,或者键为Symbol字符串的属性,拷贝后,属性会丢失。

2. 值为NaN的属性,拷贝后,值转为了null。

3. 值为非标准对象Object,比如Set、Map、Error、RegExp等等的属性或数组元素,拷贝后,值转为了空的标准对象,丢失了原来的原型继承关系。

3. 值为undefined、NaN、函数的数组元素,拷贝后,值转为了null。

其次,是拷贝功能的缺陷:
1. 原型链丢失

2. 无法拷贝有循环引用的对象

综上所述,要实现比较完整功能的深拷贝,就必须得兼顾JSON方式的功能和缺点。
三、手动实现深拷贝
追寻深拷贝的实现方式,可以理解为:深拷贝 = 浅拷贝+深度遍历+特殊情况容错。
以下,我们来实现一个深拷贝函数,deepCopy。假定函数接受的输入为o。
// 深拷贝函数
function deepCopy(o) { }
深拷贝的基本实现思路,从JS数据类型的角度出发,可以先区分字面量与引用两种类型的变量。
然后,只要判断是字面量,我们就直接浅拷贝返回,否则就进入深度遍历,重复前面的浅拷贝,直到遍历结束。
// 深拷贝函数
function deepCopy(o) {
// 如果是字面量,直接返回
if(isPrimitive(o)) return o;
// 否则,进行深度遍历 /**
* 深度遍历代码
*/
}
我们先实现一个判断输入是否为字面量的函数
function isPrimitive(o) {
if (typeof o !== 'function' && typeof o !== 'object') return true;
if (o === null) return true;
return false;
}
然后,进行深度遍历。深度遍历一般有两种选择,一个是递归,一个是while循环。
递归很好理解,但有个缺陷,大量函数栈帧的入栈,很容易导致内存空间不足而爆栈,特别是对于有循环引用关系的输入,可能秒秒钟爆炸。这里,我们采用while循环。
采用while循环的话,我们可以模拟一个栈结构,栈如果为空,则结束循环,若不为空,则进行循环,循环第一步,先出栈,然后处理数据,处理完之后,进入下一次循环判断。
在JS里,模拟栈结构可以用数组,push与pop组合,完美实现后入先出。在数据结构与算法里,这叫深度优先。
// 深拷贝函数
function deepCopy(o) {
// 如果是字面量,直接返回; 否则,进行深度遍历
if(isPrimitive(o)) return o; // 首先,先定义一个观察者,用来记录遍历的结果。等到遍历结束,这个观察者就是深拷贝的结果。
const observer = {}; // 然后,用数组模拟一个栈结构
const nodeList = []; // 其次,为了每次遍历时能地做一些处理,入栈的数据用对象来表示比较合适。
nodeList.push({
key: null, // 这里,增加一个key属性,用来关联每次遍历所要处理的数据。
}); // 循环遍历
while(nodeList.length > 0) {
const node = nodeList.pop(); // 出栈,深度优先 // 处理节点node }
}
接下来,就是处理节点node了。这里要处理的任务,主要有:
1.特殊情况处理,比如Symbol类型的属性虽然无法被Object.keys迭代出来,但可以用Reflect.ownKeys来解决。又比如,针对循环引用,可以在循环外面建立哈希表,每次循环都判断要处理的输入是否已存在哈希表,如果存在,直接引用,否则,存入哈希表。
// 用WeakMap模拟的哈希表,它的弱引用特性可以避免内存泄露
const hashmap = new WeakMap(); // 遍历包括Symbol类型在内的所有属性
const keys = Reflect.ownKeys(node.value);
2.初始化,将输入o挂载到节点里,并存入哈希表。
// 初始化
if (node.key === null) {
node.value = o;
node.observer = observer
// 存入哈希表
hashmap.set(node.value, node.observer)
}
3.对节点的属性进行遍历,属性值为引用类型,将它压入栈,否则,观察者利用关联的key记录属性值,然后进入下一次循环。
for (let i = 0; i < keys.length; i++) {
key = keys[i];
value = node.value[key];
// 是字面量,直接记录
if (isPrimitive(value)) {
node.observer[key] = value;
continue;
}
// 否则,入栈
nodeList.push({
key,
value,
observer: node.observer
})
}
4.每次对节点属性进行遍历前,先根据哈希表进行判断
// 查询哈希表,如果不存在对象key,就存入哈希表
if (!hashmap.has(node.value)) {
hashmap.set(node.value, node.observer[node.key] = isArray(node.value) ? [] : {});
// 将对象压入栈
nodeList.push({
key: node.key,
value: node.value,
observer: node.observer[node.key]
})
continue;
}
// 存在哈希表里,则从哈希表里取出,赋值
else if (node.observer !== hashmap.get(node.value)) {
node.observer[node.key] = hashmap.get(node.value)
continue;
}
这里,补上isArray函数,用来判断是否为数组
function isArray(o) {
return Object.prototype.toString.call(o) === '[object Array]';
}
到此,深拷贝函数已经成型了。但,还不够完善,因为还没有对输入是函数的情况做处理。
所以,添加两个函数,一个判断是否是函数,一个用例拷贝函数。
// 判断函数
function isFunction(o) {
return Object.prototype.toString.call(o) === '[object Function]';
} // 拷贝函数
function copyFunction(fnc) {
const f = eval(`(${fnc.toString()})`)
Object.setPrototypeOf(f, Object.getPrototypeOf(fnc))
Object.keys(fnc).map(key => f[key] = deepCopy(fnc[key]))
return f;
}
循环遍历之前,加一层对函数的判断
// 是函数,则拷贝函数
if (isFunction(o)) return copyFunction(o);
遍历的时候,也要加一层对函数的判断
// 函数直接赋值
else if (isFunction(node.value)) {
node.observer[node.key] = copyFunction(node.value)
continue;
}
循环结束后,我们还要对原型链进行处理,深拷贝,不能把继承关系给弄丢,这也是输入无论是数组还是对象都能获得正确拷贝结果的一个技巧
// 继承原型
Object.setPrototypeOf(observer, Object.getPrototypeOf(o))
最后,返回观察者对象,即深拷贝结果。
// 返回深拷贝结果
return observer;
四、测试结果与结论


五、手动实现的深拷贝完整代码
理解JS深拷贝的更多相关文章
- 一篇文章理解JS数据类型、深拷贝和浅拷贝
前言 笔者最近整理了一些前端技术文章,如果有兴趣可以参考这里:muwoo blogs.接下来我们进入正片: js 数据类型 六种 基本数据类型: Boolean. 布尔值,true 和 false. ...
- 老生常谈之js深拷贝与浅拷贝
前言 经常会在一些网站或博客看到"深克隆","浅克隆"这两个名词,其实这个很好理解,今天我们就在这里分析一下js深拷贝和浅拷贝. 浅拷贝 我们先以一个例子来说明 ...
- 这一次,彻底理解JavaScript深拷贝
导语 这一次,通过本文彻底理解JavaScript深拷贝! 阅读本文前可以先思考三个问题: JS世界里,数据是如何存储的? 深拷贝和浅拷贝的区别是什么? 如何写出一个真正合格的深拷贝? 本文会一步步解 ...
- 怎么理解js中的事件委托
怎么理解js中的事件委托 时间 2015-01-15 00:59:59 SegmentFault 原文 http://segmentfault.com/blog/sunchengli/119000 ...
- 简单理解js的this
js的this是什么?关于这个东西,博客园里面有太多的解释了,不过,本人看了一下,感觉对this解释的有点复杂了,因此,本人在此给this一个简单易于理解的定义. this其实是js的一个对象,至于是 ...
- 从一个简单例子来理解js引用类型指针的工作方式
<script> var a = {n:1}; var b = a; a.x = a = {n:2}; console.log(a.x);// --> undefined conso ...
- 深入理解js——prototype原型
之前(深入理解js--一切皆是对象)中说道,函数也是一种对象.它也是属性的集合,你也可以对函数进行自定义属性.而JavaScript默认的给了函数一个属性--prototype(原型).每个函数都有一 ...
- 如何理解js
1.js/dom功能 2.performance 3.code organization 4.tools and flow 如何理解js代码,代码即业务. 如何快速理解代码业务.
- 理解JS闭包
从事web开发工作,尤其主要是做服务器端开发的,难免会对客户端语言JavaScript一些概念有些似懂非懂的,甚至仅停留在实现功能的层面上,接下来的文章,是记录我对JavaScript的一些概念的理解 ...
随机推荐
- python运算符——算数运算符
加减乘除比较简单这里不多赘述了,print(2 +-*/ 3),唯一需要注意的就是整除运算,符号是“//”,整除运算取的是整数部分,而不是四舍五入哦! print(5 / 2) 这个运行的结果是 ...
- 利用NSE脚本检测域传送和证书透明度滥用
nslookup -type=NS <domain> <server> nmap -p 53 --script dns-zone-transfer --script-args ...
- CSS---通向臃肿的道路(关于 “separation of concerns” (SoC)的原则)
When it comes to CSS, I believe that the sacred principle of “separation of concerns” (SoC) has lead ...
- LINUX更改桌面的分辨率
命令行 输入xrandr 输入xrandr命令后可以看到系统的一些分辨率的列表, 和当前系统屏幕的分辨率信息,可以通过命令的 相应参数对系统分辨率的一些设置操作. xrandr -s 0 全屏 xra ...
- NOIP-铺地毯
题目描述 为了准备一个独特的颁奖典礼,组织者在会场的一片矩形区域(可看做是平面直角坐标系的第一象限)铺上一些矩形地毯.一共有n张地毯,编号从1到n.现在将这些地毯按照编号从小到大的顺序平行于坐标轴先后 ...
- centos+git+gitolite 安装和部署
一.部署环境 系统:CentOS 6.4x64 最小化安装 IP:192.168.52.131 git默认使用SSH协议,在服务器上基本上不用怎么配置就能直接使用.但是如果面向团队服务,需要控制权限的 ...
- C_输入一个整数N,输出从0~N(算法思考)
1.for循环实现 #include <stdio.h> #include <time.h> clock_t start, stop; double duration; voi ...
- DocX Xceed.Words.NET操作Word,插入特殊符号
x 传送门,我们走... DocX的Github传送门 介绍一 介绍二 写入特殊符号 开始... 自己做一个工具,要导出Word的,当时刚开始想使用Xceed.Words.NET.dll第三方插件进行 ...
- BZOJ 1053 - 反素数ant - [数论+DFS][HAOI2007]
题目链接:https://www.lydsy.com/JudgeOnline/problem.php?id=1053 题解: 可以证明,$1 \sim N$ 中最大的反质数,就是 $1 \sim N$ ...
- linux mysql 定时备份
1.查看磁盘空间情况: 既然是定时备份,就要选择一个空间充足的磁盘空间,避免出现因空间不足导致备份失败,数据丢失的恶果! 存储到当前磁盘这是最简单,却是最不推荐的:服务器有多块硬盘,最好是把备份存放到 ...