【Spark篇】---Spark中内存管理和Shuffle参数调优
一、前述
Spark内存管理
Spark执行应用程序时,Spark集群会启动Driver和Executor两种JVM进程,Driver负责创建SparkContext上下文,提交任务,task的分发等。Executor负责task的计算任务,并将结果返回给Driver。同时需要为需要持久化的RDD提供储存。Driver端的内存管理比较简单,这里所说的Spark内存管理针对Executor端的内存管理。
Spark内存管理分为静态内存管理和统一内存管理,Spark1.6之前使用的是静态内存管理,Spark1.6之后引入了统一内存管理。
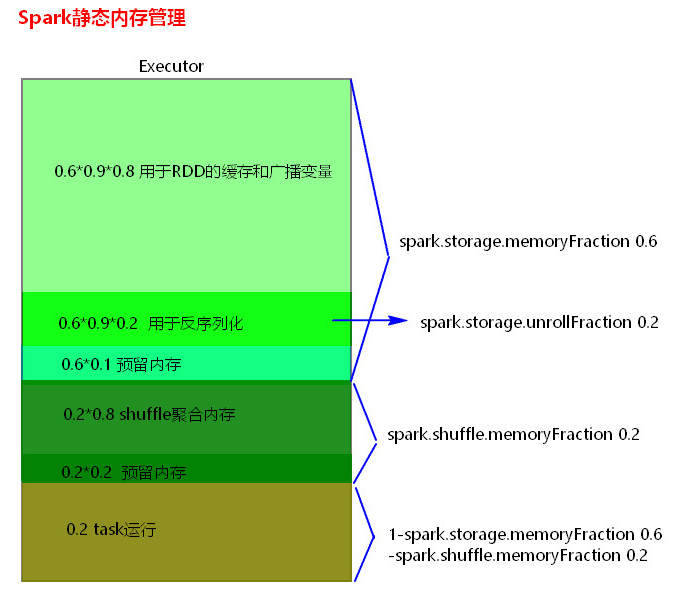
静态内存管理中存储内存、执行内存和其他内存的大小在 Spark 应用程序运行期间均为固定的,但用户可以应用程序启动前进行配置。
统一内存管理与静态内存管理的区别在于储存内存和执行内存共享同一块空间,可以互相借用对方的空间。
Spark1.6以上版本默认使用的是统一内存管理,可以通过参数spark.memory.useLegacyMode 设置为true(默认为false)使用静态内存管理。
二、具体细节
1、静态内存管理分布图
2、统一内存管理分布图

3、reduce 中OOM如何处理?
拉取数据的时候一次都放不下,放下的话可以溢写磁盘
1) 减少每次拉取的数据量
2) 提高shuffle聚合的内存比例
3) 提高Excutor的总内存
4、Shuffle调优
spark.shuffle.file.buffer
默认值:32k
参数说明:该参数用于设置shuffle write task的BufferedOutputStream的buffer缓冲大小。将数据写到磁盘文件之前,会先写入buffer缓冲中,待缓冲写满之后,才会溢写到磁盘。
调优建议:如果作业可用的内存资源较为充足的话,可以适当增加这个参数的大小(比如64k,一定是成倍的增加),从而减少shuffle write过程中溢写磁盘文件的次数,也就可以减少磁盘IO次数,进而提升性能。在实践中发现,合理调节该参数,性能会有1%~5%的提升。
spark.reducer.maxSizeInFlight
默认值:48m
参数说明:该参数用于设置shuffle read task的buffer缓冲大小,而这个buffer缓冲决定了每次能够拉取多少数据。
调优建议:如果作业可用的内存资源较为充足的话,可以适当增加这个参数的大小(比如96m),从而减少拉取数据的次数,也就可以减少网络传输的次数,进而提升性能。在实践中发现,合理调节该参数,性能会有1%~5%的提升。
spark.shuffle.io.maxRetries
默认值:3
参数说明:shuffle read task从shuffle write task所在节点拉取属于自己的数据时,如果因为网络异常导致拉取失败,是会自动进行重试的。该参数就代表了可以重试的最大次数。如果在指定次数之内拉取还是没有成功,就可能会导致作业执行失败。
调优建议:对于那些包含了特别耗时的shuffle操作的作业,建议增加重试最大次数(比如60次),以避免由于JVM的full gc或者网络不稳定等因素导致的数据拉取失败。在实践中发现,对于针对超大数据量(数十亿~上百亿)的shuffle过程,调节该参数可以大幅度提升稳定性。
shuffle file not find taskScheduler不负责重试task,由DAGScheduler负责重试stage
spark.shuffle.io.retryWait
默认值:5s
参数说明:具体解释同上,该参数代表了每次重试拉取数据的等待间隔,默认是5s。
调优建议:建议加大间隔时长(比如60s),以增加shuffle操作的稳定性。
spark.shuffle.memoryFraction
默认值:0.2
参数说明:该参数代表了Executor内存中,分配给shuffle read task进行聚合操作的内存比例,默认是20%。
调优建议:在资源参数调优中讲解过这个参数。如果内存充足,而且很少使用持久化操作,建议调高这个比例,给shuffle read的聚合操作更多内存,以避免由于内存不足导致聚合过程中频繁读写磁盘。在实践中发现,合理调节该参数可以将性能提升10%左右。
spark.shuffle.manager
默认值:sort|hash
参数说明:该参数用于设置ShuffleManager的类型。Spark 1.5以后,有三个可选项:hash、sort和tungsten-sort。HashShuffleManager是Spark 1.2以前的默认选项,但是Spark 1.2以及之后的版本默认都是SortShuffleManager了。tungsten-sort与sort类似,但是使用了tungsten计划中的堆外内存管理机制,内存使用效率更高。
调优建议:由于SortShuffleManager默认会对数据进行排序,因此如果你的业务逻辑中需要该排序机制的话,则使用默认的SortShuffleManager就可以;而如果你的业务逻辑不需要对数据进行排序,那么建议参考后面的几个参数调优,通过bypass机制或优化的HashShuffleManager来避免排序操作,同时提供较好的磁盘读写性能。这里要注意的是,tungsten-sort要慎用,因为之前发现了一些相应的bug。
spark.shuffle.sort.bypassMergeThreshold
默认值:200
参数说明:当ShuffleManager为SortShuffleManager时,如果shuffle read task的数量小于这个阈值(默认是200),则shuffle write过程中不会进行排序操作,而是直接按照未经优化的HashShuffleManager的方式去写数据,但是最后会将每个task产生的所有临时磁盘文件都合并成一个文件,并会创建单独的索引文件。
调优建议:当你使用SortShuffleManager时,如果的确不需要排序操作,那么建议将这个参数调大一些,大于shuffle read task的数量。那么此时就会自动启用bypass机制,map-side就不会进行排序了,减少了排序的性能开销。但是这种方式下,依然会产生大量的磁盘文件,因此shuffle write性能有待提高。
spark.shuffle.consolidateFiles
默认值:false
参数说明:如果使用HashShuffleManager,该参数有效。如果设置为true,那么就会开启consolidate机制,会大幅度合并shuffle write的输出文件,对于shuffle read task数量特别多的情况下,这种方法可以极大地减少磁盘IO开销,提升性能。
调优建议:如果的确不需要SortShuffleManager的排序机制,那么除了使用bypass机制,还可以尝试将spark.shffle.manager参数手动指定为hash,使用HashShuffleManager,同时开启consolidate机制。在实践中尝试过,发现其性能比开启了bypass机制的SortShuffleManager要高出10%~30%。
5、Shuffle调优设置
SparkShuffle调优配置项如何使用?
1) 在代码中,不推荐使用,硬编码。
new SparkConf().set(“spark.shuffle.file.buffer”,”64”)
2) 在提交spark任务的时候,推荐使用。
spark-submit --conf spark.shuffle.file.buffer=64 –conf ….
3) 在conf下的spark-default.conf配置文件中,不推荐,因为是写死后所有应用程序都要用。
【Spark篇】---Spark中内存管理和Shuffle参数调优的更多相关文章
- Spark Shuffle原理、Shuffle操作问题解决和参数调优
摘要: 1 shuffle原理 1.1 mapreduce的shuffle原理 1.1.1 map task端操作 1.1.2 reduce task端操作 1.2 spark现在的SortShuff ...
- spark 资源参数调优
资源参数调优 了解完了Spark作业运行的基本原理之后,对资源相关的参数就容易理解了.所谓的Spark资源参数调优,其实主要就是对Spark运行过程中各个使用资源的地方,通过调节各种参数,来优化资源使 ...
- spark参数调优
摘要 1.num-executors 2.executor-memory 3.executor-cores 4.driver-memory 5.spark.default.parallelism 6. ...
- spark submit参数调优
在开发完Spark作业之后,就该为作业配置合适的资源了.Spark的资源参数,基本都可以在spark-submit命令中作为参数设置.很多Spark初学者,通常不知道该设置哪些必要的参数,以及如何设置 ...
- 【Spark调优】Shuffle原理理解与参数调优
[生产实践经验] 生产实践中的切身体会是:影响Spark性能的大BOSS就是shuffle,抓住并解决shuffle这个主要原因,事半功倍. [Shuffle原理学习笔记] 1.未经优化的HashSh ...
- 【Spark调优】内存模型与参数调优
[Spark内存模型] Spark在一个executor中的内存分为3块:storage内存.execution内存.other内存. 1. storage内存:存储broadcast,cache,p ...
- Spark学习之路 (十)SparkCore的调优之Shuffle调优
摘抄自https://tech.meituan.com/spark-tuning-pro.html 一.概述 大多数Spark作业的性能主要就是消耗在了shuffle环节,因为该环节包含了大量的磁盘I ...
- Spark学习之路 (十)SparkCore的调优之Shuffle调优[转]
概述 大多数Spark作业的性能主要就是消耗在了shuffle环节,因为该环节包含了大量的磁盘IO.序列化.网络数据传输等操作.因此,如果要让作业的性能更上一层楼,就有必要对shuffle过程进行调优 ...
- Spark面试题(八)——Spark的Shuffle配置调优
Spark系列面试题 Spark面试题(一) Spark面试题(二) Spark面试题(三) Spark面试题(四) Spark面试题(五)--数据倾斜调优 Spark面试题(六)--Spark资源调 ...
随机推荐
- Log4j使用笔记:每天生成一个日志文件、按日志大小生成文件
其中TestLog4j.java如下: package cn.zhoucy.test; import org.apache.log4j.Logger; public class TestLog4j { ...
- Mapreduce求气温值项目
Mapreduce前提工作 简单的来说map是大数据,reduce是计算<运行时如果数据量不大,但是却要分工做这就比较花时间了> 首先想要使用mapreduce,需要在linux中进行一些 ...
- CF719E. Sasha and Array [线段树维护矩阵]
CF719E. Sasha and Array 题意: 对长度为 n 的数列进行 m 次操作, 操作为: a[l..r] 每一项都加一个常数 C, 其中 0 ≤ C ≤ 10^9 求 F[a[l]]+ ...
- AppImage格式安装包使用
AppImage(以及前身klik和portablelinuxapps)不会安装传统意义上的软件(即它不会将文件放在系统中的所有位置). 它每个应用程序使用一个文件.每个都是自包含的:它包括应用程序所 ...
- AES加密算法详解
AES 是一个对称密码分组算法,分组长度为128bit,密钥长度为128.192 和 256 bit. 整个加密过程如下图所示. 1.密钥生成算法 密钥扩展过程: 1) 将种子密钥按下图所示的格式排 ...
- 创建一个git仓库
1.git init 使用git init命令初始化一个git仓库,git仓库会生成一个.git目录 git init 1.使用指定的目录作为我们的git仓库 git init newrepo 2.初 ...
- WinForm的.Designer.cs代码内抛反射异常
今天在项目内一个Winform增加控件后,无法打开,抛如下异常. System.Reflection.TargetInvocationException: Exception has been thr ...
- CDI Features
概述 如果说EJB,JPA是之前JEE(JEE5及JEE5之前)中里程碑式的规范,那么在JEE6,JEE7中CDI可以与之媲美,CDI(Contexts and Dependency Injectio ...
- python中的单向链表实现
引子 数据结构指的是是数据的组织的方式.从单个数据到一维结构(线性表),二维结构(树),三维结构(图),都是组织数据的不同方式. 为什么需要链表? 顺序表的构建需要预先知道数据大小来申请连续的存储空间 ...
- zstd --压缩工具
Zstandard (也被称为zstd )是一款免费的开源,快速实时数据压缩程序,具有更好的压缩比 (约为 10:1). 安装 yum group install "Development ...