论文阅读笔记五十五:DenseBox: Unifying Landmark Localization with End to End Object Detection(CVPR2015)

论文原址:https://arxiv.org/abs/1509.04874
github:https://github.com/CaptainEven/DenseBox
摘要
本文先提出了一个问题:如何将全卷积网络应用到目标检测中去?本文提出DenseBox,一个集成的FCN 框架可以直接在图像的位置上预测出目标物的边框及类别。本文两方面贡献:(1)FCN可以用于检测不同的目标(2)在多任务学习过程中结合landmark定位可以进一步提高对目标的检测的准确性。
介绍
本文只关注一个问题,即如何将FCN应用到目标检测当中去?本文提出DenseBox不需要生成proposal,在训练过程中也可以达到最优。与现存的基于滑动窗的FCN的检测框架相类似,DenseBox更偏重于小目标及较为模糊目标的检测。本文通过对DenseBox训练,使用hard negative mining技术来提升检测性能。为了进一步提高,后面多任务联合学习结合了landmark定位来进一步提升性能。
DenseBox for Detection
DenseBox的整体流程如下图所示,单一的卷积网路同时输出不同的预测框及类别分数。DenseBox中的所有目标检测模块都为全卷积网络结构,除了NMS处理部分,因此,proposal的生成是没有必要的。测试时,输入图片大小为(mxnx3),输出为(m/4 x n/4 *5),将目标边界框左上角及右下角的点的坐标域定义为 及
及 ,则第i个位置的像素的输出feature map用一个5维向量描述
,则第i个位置的像素的输出feature map用一个5维向量描述
 其中s^代表为目标的分数,剩余几个变量代表输出边界框于真是边框之间的距离。最后对带有边框及类别分数的框进行NMS处理。
其中s^代表为目标的分数,剩余几个变量代表输出边界框于真是边框之间的距离。最后对带有边框及类别分数的框进行NMS处理。

Ground Truth的生成
没有必要将整张图片送人网络中训练,这样会造成不必要的计算资源的消耗。一种有效的方式是裁剪较大块包含目标物及足够背景信息的patches进行训练。本文进行单一尺度训练,多尺度测试。
该网络的训练方式形似分割的类型,训练时,图片被裁剪并调整到240x240的大小,输出的ground truth 是一个经过4倍下采样后大小为60x60x5的map,在ground truth map的第一个通道中,positive labeld区域设置一个半径为rc的圆,该圆位于边界框的中心。半径rc与边界框的大小是成比例的。其缩放系数,针对输出坐标域中边框大小设置为0.3。如下图所示,剩余 的四个通道代表最相近(与ground truth比较)边框中左上角及右下角像素点的距离。如果patch中存在多个目标,将那些位于patch中心(0.8至1.25)区域的目标标记为正样本,像素的第一个通道,代表类别的分数,在ground truth中是目标像素值为1,否则为0.本文的方法中每个像素就可以产生一个边框,因此,可以将每个像素当作一个训练样本。
模型设计
网络结构如下图所示,基于VGG19进行的改进,整个网络包含16层卷积,前12层由VGG19初始化,输出conv4_4后接4个1x1的卷积,前两个卷积产生1-channel map用于类别分数,后两个产生4-channel map用于预测相对位置。最后一个1x1的卷积担当这全连接层的作用。

多层次特征融合
Part-Level特征关注于目标物的局部细节,进而借此可以区分外形的不同,然而object-level或者high-level特征通常通过一个较大的感受野来对目标进行识别。感受野的范围越大,其上下文信息越丰富,越有利于提高准确性能。本文将conv3_4与conv4_4进行了拼接处理。conv3_4感受野的大小为48x48,与本文的训练目标尺寸大小相似,而conv4_4的感受野更大,为118x118,可以有效的利用全局的文本及上下文信息用于检测。而conv4_4的feature map是conv3_4的一半,因此首先将其进行上采样至相同的分辨率。
多任务学习
本文使用基于ImageNet预训练的VGG19网络来初始化DenseBox,实际只初始化了前12层卷积,其余的卷积层使用新的卷积替换,并使用xavier进行初始化。
与Fast R-CNN相似,本文也存在两个子分支输出,第一个输出为目标的类别分数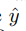 (输出map中的每一个像素),ground truth label为y* 属于{0,1},分类的损失定义如下,使用L2损失(Hinge 损失及交叉熵损失),L2损失效果已经很好。
(输出map中的每一个像素),ground truth label为y* 属于{0,1},分类的损失定义如下,使用L2损失(Hinge 损失及交叉熵损失),L2损失效果已经很好。

第二个分支输出边界框的回归损失,定义如下,用于最小化目标偏移及预测偏移之间的L2损失。
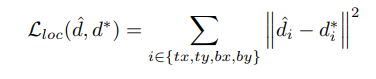
平衡采样
在学习过程中,负样本的采样挑选是至关重要的部分。如果简单的将mini-batch中的所有负样本都进行处理,将会使模型倾向于负样本。另外,检测器遇到正负样本之间的样本时会发生塌陷。本文使用一个二值mask输出像素,用于决定是否为训练样本。
忽略灰度区域
将正负区域之间的区域定义为忽略区域,该区域的样本既不是正样本也不是负样本,其损失权重也应设置为0。在输出坐标空间中,对于每一个非正标记的像素,只要其半径范围2内存在任意一个带正标记的像素,则ignore flag fign设置为1。
Hard Negative Mining
通过寻找预测较差的样本来提高学习效率。经过negative mining后,分错的负样本更容易被挑出来,对于这些样本基于随机梯度下降的学习可以产生噪音小而且更为鲁棒的预测。negative mining可以通过在线提升来提高性能。在前向传递过程中,按分类损失将像素按降序排列,top1%的为hard-negative。在实验中,将positive于negative的比例设置在1:1.在negative samples中,一半来自于hard-negative,剩余的从非hard-negative中随机采样。为了方便,将被挑选的像素设置标记fsel=1.
Loss with Mask
为每个样本 ,定义mask
,定义mask  ,函数如下
,函数如下

本文的整体损失为,回归损失只对正样本起作用,本文将目标d*除以标准目标的高(ground truth map中为50/4)进行正则化,设置

细节增强
将特定尺寸中心处包含目标中心的输入patch称为"positive patch",这些patches在正样本的周围只包含负样本。本文将输入图片中随机进行裁剪,并resize到相同的大小送入网络中,这类patch称为"random patches","positive patch"与"random patch"的比例为1:1,另外,为了提升网络的鲁棒性,对每个patch进行了jitter操作,left-right flip,translation shift(25个像素),尺寸变形([0.8,1.25])
基于mini-batch的SGD训练,batchsize=10,loss及梯度通过贡献的像素个数进行正则化。global learning rate开始为0.001,每100K迭代,学习率衰减10倍。momentum设置为0.9,权重衰减为0.0005
Refine with Landmark Localization
在DenseBox中由于是全卷积网络,因此,基于landmark定位可以通过简单添加一些层来进行实现。通过融合landmark heatmaps及目标score maps来对检测结果进行增强。如下图所示,增加了一个分支用于landmark定位,假设存在N个landmarks,landmark 定位分支将会输出N个响应maps,其中,每个像素值代表该位置为landmark的置信分数。该任务的ground truth maps与检测的十分相似,对于一个landmark 实例 ,landmark k的第i个实例,其对应的ground truth 是位于输出坐标空间中第k个响应 map上的positive 标记的区域。半径rl应当较小从而避免准确率的损失。与分类任务相似,landmark 定位损失也是定义为预测值与真实值的L2损失。同样使用negative mining及ignore region。
,landmark k的第i个实例,其对应的ground truth 是位于输出坐标空间中第k个响应 map上的positive 标记的区域。半径rl应当较小从而避免准确率的损失。与分类任务相似,landmark 定位损失也是定义为预测值与真实值的L2损失。同样使用negative mining及ignore region。
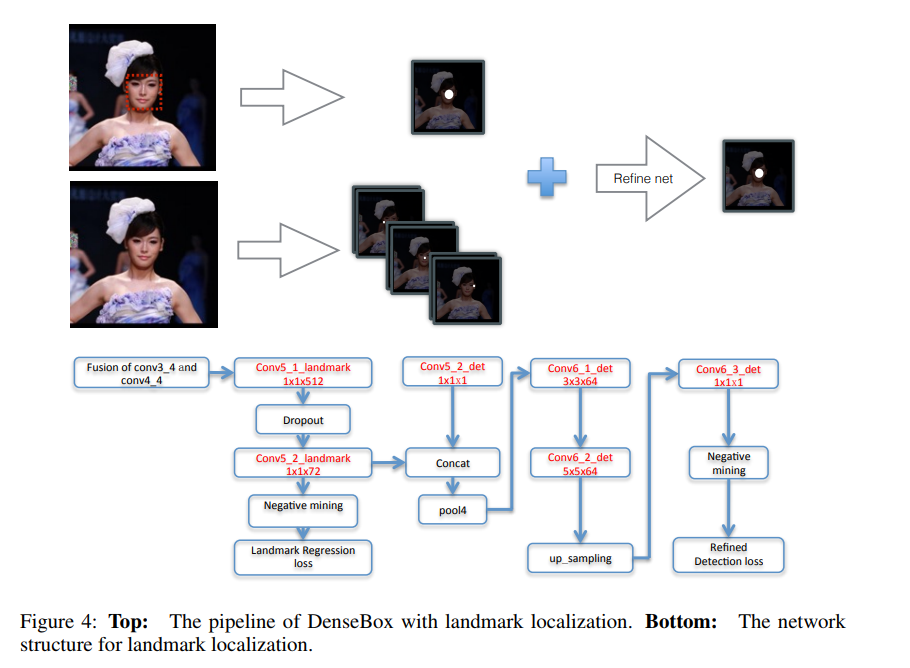
将分类score map及landmark localization maps作为输入的增强分支的最终输出用于增强检测结果。通过一些高层次空间模型来了解landmark confidence及边界框分数的方法来进一步提高检测性能。本文使用带ReLU的卷积来近似空间模型,增加了增强分支后的整体损失函数如下所示。

Experiment



References
[1] Y. Bengio, A. Courville, and P. Vincent. Representation learning: A review and new perspectives. Pattern Analysis and Machine Intelligence, IEEE Transactions on, 35(8):1798–1828, 2013.
[2] G. Bertasius, J. Shi, and L. Torresani. Deepedge: A multi-scale bifurcated deep network for top-down contour detection. arXiv preprint arXiv:1412.1123, 2014.
[3] X. Chen, K. Kundu, Y. Zhu, A. Berneshawi, H. Ma, S. Fidler, and R. Urtasun. 3d object proposals for accurate object class detection. In NIPS, 2015.
[4] R. G. Cinbis, J. Verbeek, and C. Schmid. Segmentation driven object detection with fisher vectors. In Computer Vision (ICCV), 2013 IEEE International Conference on, pages 2968– 2975. IEEE, 2013.
论文阅读笔记五十五:DenseBox: Unifying Landmark Localization with End to End Object Detection(CVPR2015)的更多相关文章
- 论文阅读笔记四十八:Bounding Box Regression with Uncertainty for Accurate Object Detection(CVPR2019)
论文原址:https://arxiv.org/pdf/1809.08545.pdf github:https://github.com/yihui-he/KL-Loss 摘要 大规模的目标检测数据集在 ...
- 论文阅读笔记二十八:You Only Look Once: Unified,Real-Time Object Detection(YOLO v1 CVPR2015)
论文源址:https://arxiv.org/abs/1506.02640 tensorflow代码:https://github.com/nilboy/tensorflow-yolo 摘要 该文提出 ...
- 论文阅读笔记四十五:Region Proposal by Guided Anchoring(CVPR2019)
论文原址:https://arxiv.org/abs/1901.03278 github:code will be available 摘要 区域anchor是现阶段目标检测方法的重要基石.大多数好的 ...
- 论文阅读笔记三十五:R-FCN:Object Detection via Region-based Fully Convolutional Networks(CVPR2016)
论文源址:https://arxiv.org/abs/1605.06409 开源代码:https://github.com/PureDiors/pytorch_RFCN 摘要 提出了基于区域的全卷积网 ...
- 论文阅读笔记二十五:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition(SPPNet CVPR2014)
论文源址:https://arxiv.org/abs/1406.4729 tensorflow相关代码:https://github.com/peace195/sppnet 摘要 深度卷积网络需要输入 ...
- 论文阅读笔记六十五:Enhanced Deep Residual Networks for Single Image Super-Resolution(CVPR2017)
论文原址:https://arxiv.org/abs/1707.02921 代码: https://github.com/LimBee/NTIRE2017 摘要 以DNN进行超分辨的研究比较流行,其中 ...
- 论文阅读笔记(十五)【CVPR2016】:Top-push Video-based Person Re-identification
Approach 特征由两部分组成:space-time特征和外貌特征.space-time特征由HOG3D[传送门]提取,其包含了空间梯度和时间动态信息:外貌特征采用颜色直方图[传送门]和LBP[传 ...
- 论文阅读笔记(十八)【ITIP2019】:Dynamic Graph Co-Matching for Unsupervised Video-Based Person Re-Identification
论文阅读笔记(十七)ICCV2017的扩刊(会议论文[传送门]) 改进部分: (1)惩罚函数:原本由两部分组成的惩罚函数,改为只包含 Sequence Cost 函数: (2)对重新权重改进: ① P ...
- 论文阅读笔记(十二)【CVPR2018】:Exploit the Unknown Gradually: One-Shot Video-Based Person Re-Identification by Stepwise Learning
Introduction (1)Motivation: 大量标记数据成本过高,采用半监督的方式只标注一部分的行人,且采用单样本学习,每个行人只标注一个数据. (2)Method: 对没有标记的数据生成 ...
随机推荐
- loadrunner断言多结果返回
有这么一个场景,接口返回的多个状态都是正常的,那么在压测的时候,断言就需要多 init里面执行登录,根据返回获取到tokenId action中,执行登录后的操作,获取响应返回的状态,把正确的状态个数 ...
- Mysql高性能笔记(一):Schema与数据类型优化
1.数据类型 1.1.几个参考优化原则 a. 更小的通常更好 i.更小的数据类型,占用更少磁盘.内存和CPU缓存,需要的CPU周期更少 ii.如果无法确定哪个数据类型是最好的,就选择不会超过范围的最 ...
- Vue-route实现原理
1.原理图如下所示 2.说明 1.安装插件的时候监听hashchange事件,监视_route 2.处理router-link 获取到path关联组件 3.等待hashchange触发,匹配route ...
- layui模板引擎
<在模板中调用js方法> 1.js代码 layui.define(['laytpl', 'jquery'], function (exports) { var $ = layui.jque ...
- python3.x执行post请求时报错“POST data should be bytes or an iterable of bytes...”的解决方法
使用python3.5.1执行post请求时,一直报错"POST data should be bytes or an iterable of bytes. It cannot be of ...
- Vue学习笔记五:事件修饰符
目录 什么是事件修饰符 没有事件修饰符的问题 HTML 运行 使用事件修饰符 .stop阻止冒泡 .prevent 阻止默认事件 .capture 添加事件侦听器时使用事件捕获模式 .self 只当事 ...
- 快速掌握Nginx(三) —— Nginx+Systemd托管netcore应用
以前dotnet web应用程序开发完成后,我们都是使用IIS部署在Windows Server上,如今netcore技术发展迅速,因为其跨平台的特性,将dotnet web应用程序部署在更方便部署和 ...
- Oracle启动操作
转自:https://www.cnblogs.com/mellowsmile/p/4610942.html 1.启动oracle数据库: 从root切换到oracle用户进入:su - oracle ...
- IntelliJ IDEA 2018最新版注册码激活方法
一.首先点击intellij idea 2018 二.选择激活码 三.输入以下激活码intellij idea 2018 最新版本 注册激活码 **************************** ...
- import模块/包--软件开发规范
一. 模块 模块:就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀. import加载的模块分为四个通用类别: 1 使用python编写的代码(.py文件) 2 已被编译 ...