抓包分析、多线程爬虫及xpath学习
1、抓包分析
1.1 Fiddler安装及基本操作
由于很多网站采用的是HTTPS协议,而fiddler默认不支持HTTPS,先通过设置使fiddler能抓取HTTPS网站,过程可参考(https://www.cnblogs.com/liulinghua90/p/9109282.html)。使用clear可以将当前fiddler清屏。
1.2 通过抓包爬取腾讯视频评论
unicode转码:在Python中转码可以直接输入u'需要转码的内容'
由于每个视频后面的评论需要自动加载,在源代码中未发现有关评论的相关链接,此时就需要使用fiddler进行抓包分析,打开视频网站后,可以先使用clear清屏,找到JS包,可以复制它的url,打开后发现评论都是使用的Unicode编码,此时就需要解码。由于需要自动加载后面的评论,此时需要分析网页的构成。再使用一次clear,在网页上点击加载更多评论,在fiddler中找到JS包,复制url,将之与之前的url进行对比,重复几次该操作,构造评论url。
下面给出爬取腾讯视频中权力的游戏第八季评论:

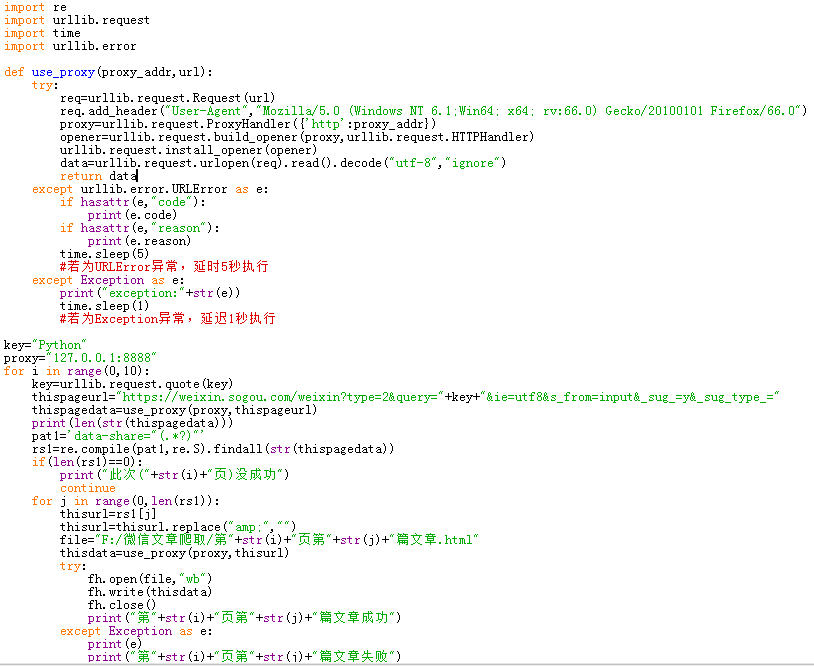
1.3 微信文章爬取
进入weixin.sougou.com,搜索关键词为“Python”,也采取抓包分析,不过增加了代理,其余操作步骤与1.2类似。
2、多线程爬虫
多线程,即程序中的某些程序段并行执行,合理地设置多线程,可以让爬虫的效率更高。

运行之后的结果为:

可以看出两个线程是同时开始工作的,那么如果用多线程爬取多个网页的话,就可以更加高效。下面将用多线程爬取糗事百科的文字内容:

首先需要分析网页的构造,通过翻页将规律找出来,实现在程序中实现自动翻页加载文本,其次需要将内容解码输出,最后需要加上异常处理。
3、scrapy xpath
/标签名:从顶端开始,如/html从顶端开始寻找html这个标签,找到的是这个标签内的内容
//标签名:寻找所有该标签
text():提取文本信息
@属性:提取属性信息
命令行输入:scrapy startproject 爬虫名,表示新建一个爬虫;如果新建一个自动爬虫,则先输入:scrapy startproject 爬虫名,再输入:scrapy genspider -t crawl 爬虫名 网址
items.py主要用来设置爬取的目标
pipelines.py设置后续的处理
settings.py主要用于配置信息
抓包分析、多线程爬虫及xpath学习的更多相关文章
- Python 爬虫知识点 - 淘宝商品检索结果抓包分析(续一)
通过前一节得出地址可能的构建规律,如下: https://s.taobao.com/search?data-key=s&data-value=44&ajax=true&_ksT ...
- 爬虫系列(二) Chrome抓包分析
在这篇文章中,我们将尝试使用直观的网页分析工具(Chrome 开发者工具)对网页进行抓包分析,更加深入的了解网络爬虫的本质与内涵 1.测试环境 浏览器:Chrome 浏览器 浏览器版本:67.0.33 ...
- python爬虫(3)——用户和IP代理池、抓包分析、异步请求数据、腾讯视频评论爬虫
用户代理池 用户代理池就是将不同的用户代理组建成为一个池子,随后随机调用. 作用:每次访问代表使用的浏览器不一样 import urllib.request import re import rand ...
- FTP协议的粗浅学习--利用wireshark抓包分析相关tcp连接
一.为什么写这个 昨天遇到个ftp相关的问题,关于ftp匿名访问的.花费了大量的脑细胞后,终于搞定了服务端的配置,现在客户端可以像下图一样,直接在浏览器输入url,即可直接访问. 期间不会弹出输入用户 ...
- Python 爬虫知识点 - 淘宝商品检索结果抓包分析(续二)
一.URL分析 通过对“Python机器学习”结果抓包分析,有两个无规律的参数:_ksTS和callback.通过构建如下URL可以获得目标关键词的检索结果,如下所示: https://s.taoba ...
- Python 爬虫知识点 - 淘宝商品检索结果抓包分析
一.抓包基础 在淘宝上搜索“Python机器学习”之后,试图抓取书名.作者.图片.价格.地址.出版社.书店等信息,查看源码发现html-body中没有这些信息,分析脚本发现,数据存储在了g_page_ ...
- Java网络编程学习A轮_02_抓包分析TCP三次握手过程
参考资料: https://huoding.com/2013/11/21/299 https://hpbn.co/building-blocks-of-tcp/#three-way-handshake ...
- 抓包分析SSL/TLS连接建立过程【总结】
1.前言 最近在倒腾SSL方面的项目,之前只是虽然对SSL了解过,但是不够深入,正好有机会,认真学习一下.开始了解SSL的是从https开始的,自从百度支持https以后,如今全站https的趋势越来 ...
- wireshark 抓包分析 TCPIP协议的握手
wireshark 抓包分析 TCPIP协议的握手 原网址:http://www.cnblogs.com/TankXiao/archive/2012/10/10/2711777.html 之前写过一篇 ...
随机推荐
- laravel 跨库执行原生 sql 语句
执行原生 sql 返回结果集
- android stuido搭配git常用命令
查看本地分支:git branch 查看远程分支:git branch -a 推送本地分支到远程:git push origin local_branch:remote_branch 推送远程访问 g ...
- [转] 常用Loss函数
好文mark 转自机器之心 :https://www.jiqizhixin.com/articles/2018-06-21-3 “损失函数”是机器学习优化中至关重要的一部分.L1.L2损失函数相信大多 ...
- codeforces 787D - Legacy 线段树优化建图,最短路
题意: 有n个点,q个询问, 每次询问有一种操作. 操作1:u→[l,r](即u到l,l+1,l+2,...,r距离均为w)的距离为w: 操作2:[l,r]→u的距离为w 操作3:u到v的距离为w 最 ...
- Mockito框架入门教程(一)
官网: http://mockito.org API文档:http://docs.mockito.googlecode.com/hg/org/mockito/Mockito.html 项目源码:htt ...
- nginx+iis使用
一.nginx的介绍 nginx是由俄罗斯人开发的一款高性能的http和反向代理服务器,也可以用来作为邮件代理.相比较于其他的服务器,具有占用内存少,稳定性高等优势 Nginx相关地址 源码:http ...
- C语言判断水仙花数
水仙花数 水仙花数(Narcissistic number)也被称为超完全数字不变数(pluperfect digital invariant, PPDI).自恋数.自幂数.阿姆斯壮数或阿姆斯特朗数( ...
- beta冲刺1/7
目录 摘要 团队部分 个人部分 摘要 队名:小白吃 组长博客:hjj 作业博客:beta冲刺(1/7) 团队部分 后敬甲(组长) 过去两天完成了哪些任务 团队完成测试答辩 整理博客 复习接口 接下来的 ...
- 如何使用JMeter开源性能测试工具来构建Web性能测试体系
一.性能测试一些概念 性能测试:就是通过自动化的测试工具模拟多种正常峰值及异常负载条件来对系统的各项性能指标进行测试.负载测试和压力测试都属于性能测试,两者可以结合进行. 负载测试:确定在各种工作负载 ...
- 记 Win10 + Ubuntu18.04 安装
目录 一.准备(一)环境(二)镜像(三)优盘 (四)启动项管理软件EasyBCD(五)启动优盘制作软件(六)分区二.安装 (一)优盘启动(二)安装windows10(三)安装ubuntu18.04(四 ...