MyCat-schema.xml详解
一、概念与图示
schema.xml配置的几个术语与其关系图示:
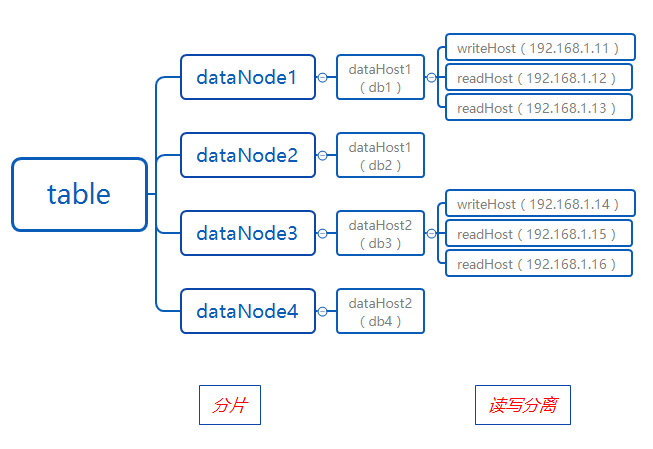
二、schema 标签
schema 标签用于定义 MyCat 实例中的逻辑库,如:
|
<schema name="USERDB" dataNode="dn1" checkSQLschema="false" sqlMaxLimit="100"> |
1. name属性
配置逻辑库的名字(即数据库实例名);
2. dataNode属性
用于配置该逻辑库默认的分片。没有通过table标签配置的表,就会走到默认的分片上。这里注意没有配置在table标签的表,用工具查看是无法显示的,但是可以正常使用。
如果没有配置dataNode属性,则没有配置在table标签的表,是无法使用的。注意,dual表在mycat中,也被视为一个表。
|
查询:select sysdate() from dual LIMIT 0, 1000 错误代码: 1064 can't find table define in schema DUAL schema:USERDB |
另外,通过mycat建表,而该表并没有提前配置table标签,则mycat会找到默认的dataNode,并把表建在默认的dataNode上。如果没有配置默认dataNode,则mycat会报错。
|
查询:create table test(id varchar(10)) 错误代码: 1064 op table not in schema----TEST |
而如果该表有配置table标签,则表会分别在table标签指定的dataNode上建表。
3. checkSQLschema属性
boolean类型。
当前端执行【select *from USERDB.tf_user;】时(表名前指定了mycat逻辑库名),两种取值:
true:mycat会把语句转换为【select * from tf_user;】
false:会报错
|
查询:SELECT * FROM USERDB.tf_user LIMIT 0, 1000 错误代码: 1064 find no Route:SELECT * FROM USERDB.tf_user LIMIT 0, 1000 |
4. sqlMaxLimit属性
相当于sql的结果集中,加上【limit N】。如果sql本身已经指定limit,则以sql指定的为准。
|
mysql> explain select * from tf_user; +-----------+---------------------------------+ | DATA_NODE | SQL | +-----------+---------------------------------+ | dn1 | SELECT * FROM tf_user LIMIT 100 | | dn2 | SELECT * FROM tf_user LIMIT 100 | +-----------+---------------------------------+ 2 rows in set (0.00 sec) mysql> explain select * from tf_user limit 50; +-----------+--------------------------------+ | DATA_NODE | SQL | +-----------+--------------------------------+ | dn1 | SELECT * FROM tf_user LIMIT 50 | | dn2 | SELECT * FROM tf_user LIMIT 50 | +-----------+--------------------------------+ 2 rows in set (0.00 sec) |
注意,如果table标签的表,needAddLimit属性配置为false,则该表的sql禁止自动加上limit
三、table 标签
table标签为schema标签的子标签。
table标签用于定义Mycat的逻辑表,以及逻辑表的分片规则。如:
|
<table name="tf_user" primaryKey="USER_ID" autoIncrement="true"dataNode="dn1,dn2" rule="hash-int" /> |
1. name属性
逻辑表的表名,同一个schema表名必须唯一。
2. dataNode属性
定义这个逻辑表所属的 dataNode,用英文逗号间隔,如:dataNode="dn1,dn2"
如果dataNode过多,可以使用如下的方法减少配置:
|
<table name="travelrecord" dataNode="multipleDn$0-99,multipleDn2$100-199" rule="auto-shardinglong" ></table> <dataNode name="multipleDn" dataHost="localhost1" database="db$0-99" ></dataNode> <dataNode name="multipleDn2" dataHost="localhost1" database=" db$0-99" ></dataNode> |
db$0-99为mysql的数据库,即从db0至db99的数据库(100个)。
3. rule属性
该属性用于指定逻辑表要使用的规则名字,规则名字在 rule.xml 中定义,必须与 tableRule 标签中 name 属性属性值一一对应。
4. ruleRequired属性
该属性用于指定表是否绑定分片规则,如果配置为 true,但没有配置具体 rule 的话 ,程序会报错
5. primaryKey属性
指定该逻辑表对应真实表的主键。MyCat会缓存主键(通过primaryKey属性配置)与具体 dataNode的信息。当分片规则使用非主键进行分片时,那么在使用主键进行查询时,MyCat就会通过缓存先确定记录在哪个dataNode上,然后再在该dataNode上执行查询。
如果缓存并没有命中的话,还是会发送语句给所有的dataNode。
|
mysql> explain select * from employee where id=101; +-----------+-------------------------------------+ | DATA_NODE | SQL | +-----------+-------------------------------------+ | dn1 | select * from employee where id=101 | | dn2 | select * from employee where id=101 | +-----------+-------------------------------------+ 2 rows in set (0.00 sec) mysql> select * from employee where id=101; +-----+------+-------------+ | id | name | sharding_id | +-----+------+-------------+ | 101 | A | 10000 | +-----+------+-------------+ 1 row in set (0.01 sec) mysql> explain select * from employee where id=101; +-----------+-------------------------------------+ | DATA_NODE | SQL | +-----------+-------------------------------------+ | dn1 | select * from employee where id=101 | +-----------+-------------------------------------+ 1 row in set (0.00 sec) |
关于Mycat的主键缓存,其机制是:当根据主键查询的SQL语句第一次执行时,Mycat会对其结果进行分析,确定该主键在哪个分片上,并进行该主键到分片ID的缓存。通过连接MyCAT的9066管理端口,执行show@@cache,可以显示当前缓存的使用情况。可在sql执行前后的2个时间点执行show @@cache,通过结果信息中的LAST_PUT和LAST_ACCESS列,判断相应表的缓存是否有被更新过。
6. type属性
该属性定义了逻辑表的类型,目前逻辑表只有“全局表”和”普通表”两种类型。对应的配置:
全局表:global。
普通表:不指定该值为 global 的所有表。
7. autoIncrement属性
8. subTables属性
分表配置,mycat1.6之后开始支持,但dataNode 在分表条件下只能配置一个。
9. needAddLimit属性
与schema标签的sqlMaxLimit配合使用,如果needAddLimit值为false,则语句不会加上limit
四、childTable 标签
childTable 标签用于定义 E-R 分片的子表。通过标签上的属性与父表进行关联。
1. name属性
定义子表的表名
2. joinKey属性
插入子表的时候会使用这个列的值查找父表存储的数据节点。
3. parentKey属性
该属性指定的值一般为与父表建立关联关系的列名。Mycat首先获取 joinkey 的值,再通过 parentKey 属性指定的列名产生查询语句,通过执行该语句得到父表存储在哪个分片上。从而确定子表存储的位置。
4. primaryKey属性
同table标签描述。
5. needAddLimit 属性
同table标签描述。
五、dataNode 标签
|
<dataNode name="dn1" dataHost="localhost1" database="mycatdb00" /> |
1. name 属性
指定分片的名字
2. dataHost 属性
定义该分片属于哪个数据库实例
3. database 属性
定义该分片属于哪个具体数据库实例上的具体库(即对应mysql中实际的DB)
六、dataHost标签
定义后端的数据库主机
|
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> |
1. name 属性
指定dataHost的名字
2. maxCon
指定每个读写实例连接池的最大连接。也就是说,标签内嵌套的writeHost、 readHost 标签都会使用这个属
性的值来实例化出连接池的最大连接数。
3. minCon 属性
指定每个读写实例连接池的最小连接,初始化连接池的大小。
4. balance 属性
负载均衡类型:
(1)balance="0", 不开启读写分离机制,所有读操作都发送到当前可用的writeHost 上。
(2)balance="1",全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且 M1 与 M2 互为主备),正常情况下,M2,S1,S2 都参与 select 语句的负载均衡。
(3)balance="2",所有读操作都随机的在 writeHost、 readhost 上分发。
(4)balance="3",所有读请求随机的分发到 wiriterHost 对应的 readhost 执行,writerHost 不负担读压力,注意 balance=3 只在 1.4 及其以后版本有,1.3 没有。
5. writeType 属性
(1)writeType="0", 所有写操作发送到配置的第一个 writeHost,第一个挂了切到还生存的第二个riteHost,重新启动后已切换后的为准,切换记录在配置文件中:dnindex.properties.
(2)writeType="1",所有写操作都随机的发送到配置的 writeHost,1.5 以后废弃不推荐。
6. dbType 属性
指定后端连接的数据库类型,目前支持二进制的 mysql 协议,还有其他使用 JDBC 连接的数据库。例如:mongodb、 oracle、 spark 等。
7. dbDriver 属性
指定连接后端数据库使用的 Driver,目前可选的值有 native 和 JDBC。使用native 的话,因为这个值执行的是二进制的 mysql 协议,所以可以使用 mysql 和 maridb。其他类型的数据库则需要使用 JDBC 驱动来支持。
8. switchType 属性
-1 表示不自动切换
1 默认值,自动切换
2 基于 MySQL 主从同步的状态决定是否切换
心跳语句为 show slave status
3 基于 MySQL galary cluster 的切换机制(适合集群)(1.4.1)
心跳语句为 show status like ‘wsrep%’.
9. tempReadHostAvailable 属性
如果配置了这个属性 writeHost 下面的 readHost 仍旧可用,默认 0 可配置(0、 1)。
七、writeHost 标签、 readHost 标签
1. host 属性
用于标识不同实例,一般 writeHost 我们使用*M1,readHost 我们用*S1。
2. url 属性
后端实例连接地址,如果是使用 native 的 dbDriver,则一般为 address:port 这种形式。用 JDBC 或其他的dbDriver,则需要特殊指定。当使用 JDBC 时则可以这么写:jdbc:mysql://localhost:3306/。
3. user 属性
后端存储实例需要的用户名字
4. password 属性
后端存储实例需要的密码
5. weight 属性
权重 配置在 readhost 中作为读节点的权重(1.4 以后)
6. usingDecrypt 属性
是否对密码加密默认 0 否 如需要开启配置 1,同时使用加密程序对密码加密
MyCat-schema.xml详解的更多相关文章
- Mycat分布式数据库架构解决方案--schema.xml详解
echo编辑整理,欢迎转载,转载请声明文章来源.欢迎添加echo微信(微信号:t2421499075)交流学习. 百战不败,依不自称常胜,百败不颓,依能奋力前行.--这才是真正的堪称强大!!! 该文件 ...
- Solr5之Schema.xml详解
schema.xml 是用来定义索引数据中的域的,包括域名称,域类型,域是否索引,是否分词,是否存储,是否标准化即 Norms ,是否存储项向量等等. schema.xml 配置文件的根元素就是 sc ...
- logback的使用和logback.xml详解,在Spring项目中使用log打印日志
logback的使用和logback.xml详解 一.logback的介绍 Logback是由log4j创始人设计的另一个开源日志组件,官方网站: http://logback.qos.ch.它当前分 ...
- 转载 logback的使用和logback.xml详解 http://www.cnblogs.com/warking/p/5710303.html
logback的使用和logback.xml详解 一.logback的介绍 Logback是由log4j创始人设计的另一个开源日志组件,官方网站: http://logback.qos.ch.它当前 ...
- Web.xml详解(转)
这篇文章主要是综合网上关于web.xml的一些介绍,希望对大家有所帮助,也欢迎大家一起讨论. ---题记 一. Web.xml详解: (一) web.xml加载过程(步骤) 首 ...
- Maven-pom.xml详解
(看的比较累,可以直接看最后面有针对整个pom.xml的注解) pom的作用 pom作为项目对象模型.通过xml表示maven项目,使用pom.xml来实现.主要描述了项目:包括配置文件:开发者需要遵 ...
- 【maven】 pom.xml详解
pom.xml详解 <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www ...
- build.xml详解
build.xml详解1.<project>标签每个构建文件对应一个项目.<project>标签时构建文件的根标签.它可以有多个内在属性,就如代码中所示,其各个属性的含义分别如 ...
- 【转】maven核心,pom.xml详解
感谢如下博主: http://www.cnblogs.com/qq78292959/p/3711501.html maven核心,pom.xml详解 什么是pom? pom作为项目对象模型.通过 ...
- C#中的Linq to Xml详解
这篇文章主要介绍了C#中的Linq to Xml详解,本文给出转换步骤以及大量实例,讲解了生成xml.查询并修改xml.监听xml事件.处理xml流等内容,需要的朋友可以参考下 一.生成Xml 为了能 ...
随机推荐
- 初识中间件Kafka
初识中间件Kafka Author:SimplelWu 什么是消息中间件? 非底层操作系统软件,非业务应用软件,不是直接给最终用户使用的,不能直接给客户带来价值的软件统称为中间件 关注于数据的发送和接 ...
- 仓位管理 V4.3
之前设计的仓位管理算法一直比较有效,往往能在市场的不断的上涨下跌中获利.不过感觉短期变动的仓位占整体的仓位较低,使得盈利较低.所以这个月对仓位管理算法进行了升级,尝试了几个版本.这里做一个记录. V4 ...
- java.util.ConcurrentModificationException 记一次坑
集合在单线程,一个循环内,有添加又删除会出现此异常. 多线程时,在不同的循环操作同一个集合,会出现此异常. 因为,集合长度发生改变时,在迭代器未结束前,迭代器的大小不会发生变化. 1.保证在同一个进程 ...
- 【webpack系列】从零搭建 webpack4+react 脚手架(二)
html文件如何也同步到dist目录?bundle.js文件修改了,万一被浏览器缓存了怎么办?如何为导出的文件加md5?如何把js引用自动添加到html?非业务代码和业务代码如何分开打包?如何搭建开发 ...
- js常见的面试题
css 选择符有哪些 通配选择符 *类选择符 classid选择符 id属性选择符 input[name=button]包含选择符 类似 div span子对象选择符 类似 div > span ...
- RN和IOS原生端交互
1.RCTBridgeModule #import <Foundation/Foundation.h> #import "RCTBridgeModule.h" #imp ...
- RESTful-3架构详解
1. 什么是REST REST全称是Representational State Transfer,中文意思是表述(编者注:通常译为表征)性状态转移. 它首次出现在2000年Roy Fielding的 ...
- sql查询一个字段多列值合并为一列
SELECT GROUP_CONCAT(A.字段) AS 字段别名 FROM 表名 A WHERE A.字段=,,) SELECT GROUP_CONCAT(A.字段) AS 字段FROM 表名 A
- php的运行机制
php的解析过程是 apache -> httpd -> php5_module -> sapi -> php cgi (外部应用程序)只是用来解析php代码的 sapi中的其 ...
- toString
在java中使用toString: 如果在Java在输出定义一个Person类 然后实例化person per 直接用system.out.println(per);无法得到我们想要的实例化内容 p ...