Python笔记(十四):操作excel openpyxl模块
(一) 常遇到的情况
就我自己来说,常遇到的情况可能就下面几种:
- 读取excel整个sheet页的数据。
- 读取指定行、列的数据
- 往一个空白的excel文档写数据
- 往一个已经有数据的excel文档追加数据
下面就以这几种情况为例进行说明。
(二) 涉及的模块及函数说明
就我知道的,有3个模块可以操作excel文档,3个模块通过pip都可以直接安装。
xlrd:读数据
xlwt:写数据
openpyxl:可以读数据,也可以写数据
这里就就只说明openpyxl了,因为这个模块能满足上面的需要了。
openpyxl函数
|
函数 |
说明 |
|
load_workbook(filename) |
打开excel,并返回所有sheet页 访问指定sheet页的方法: #打开excel文档 #关闭excel文档 wb.close() |
Workbook() |
创建excel文档 wb = openpyxl.Workbook() #保存excel文档 wb.save('文件名.xlsx') |
|
下面的函数是针对sheet页的 sheet = wb[‘sheet页的名称’] 访问指定单元格的方式sheet['A1']、sheet['B1']... |
|
|
min_row |
返回包含数据的最小行索引,索引从1开始 例如:sheet.min_row |
|
max_row |
返回包含数据的最大行索引,索引从1开始 |
|
min_column |
返回包含数据的最小列索引,索引从1开始 |
|
max_column |
返回包含数据的最大列索引,索引从1开始 |
|
values |
获取excel文档所有的数据,返回的是一个generator对象 |
|
iter_rows(min_row=None, max_row=None, min_col=None, max_col=None) |
min_row:最小行索引 max_row:最大行索引 min_col:最小列索引 max_col:最大列索引 获取指定行、列的单元格,没指定就是获取所有的 |
现在我有这么一个excel,下面以这个excel进行说明。
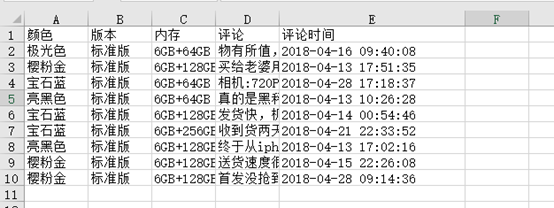
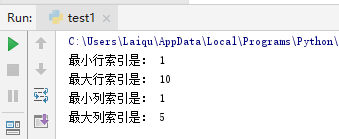
关于min_row、max_row这些,看下面的输出就很直观了
import openpyxl def get_data_openpyxl(file_name,sheet):
#打开excel文档
wb = openpyxl.load_workbook(file_name)
#访问sheet页
sheet = wb[sheet]
# 包含数据的最小行索引,从1开始
minRow = sheet.min_row
print("最小行索引是:", minRow)
#包含数据的最大行索引,从1开始
maxRow = sheet.max_row
print("最大行索引是:",maxRow)
#包含数据的最小列索引
minColumn = sheet.min_column
print("最小列索引是:",minColumn)
#包含数据的最大列索引
maxColumn = sheet.max_column
print("最大列索引是:", maxColumn)
wb.close()
get_data_openpyxl('测试.xlsx','Sheet')
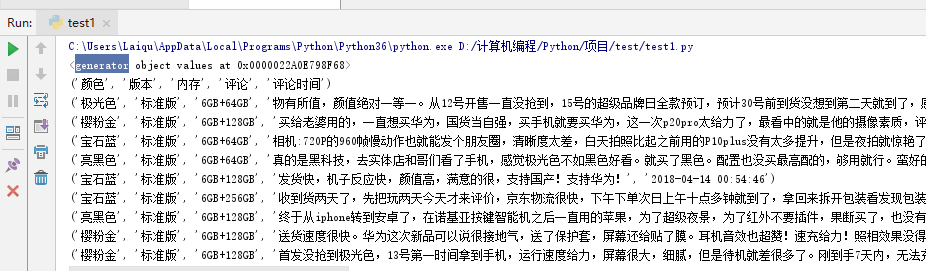
(三) 读取excel整个sheet页的数据
下面的代码都是没加异常处理的,要加的话自己看情况加上异常处理就行了。
import openpyxl def get_data_openpyxl(file_name,sheet):
#打开excel文档
wb = openpyxl.load_workbook(file_name)
#访问sheet页
sheet = wb[sheet]
# 获取excel文档所有的数据,返回的是一个generator对象
data = sheet.values
print(data)
#迭代输出所有数据
for i in data:
print(i)
wb.close()
get_data_openpyxl('测试.xlsx','Sheet')
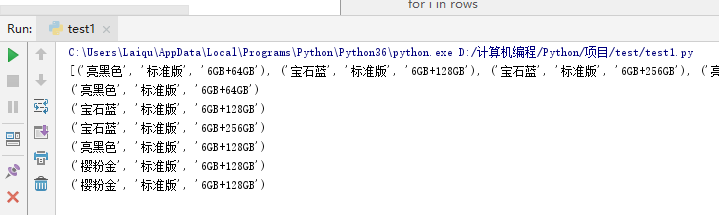
(四) 读取指定行、列的数据
这里有个问题就是,openpyxl模块貌似没有读取指定行、列数据的函数,不过没关系,自己封装一个函数去实现就行了,这个是通用的(前提是已经安装openpyxl),可以创建一个类(可以根据函数的作用创建多个不同的类,这个看自己了),放一些自己写的常用函数。
import openpyxl def get_data_iter(file_name,sheet, max_row=None,min_row=None,max_col=None,min_col=None):
''' :param file_name: excel文件名称
:param sheet: sheet页名称
:param max_row:最大行索引,未指定则获取所有行的数据
:param min_row: 最小行索引,未指定则从第一行开始
:param min_col:最小列索引,未指定则从第一列开始
:param max_col:最大列索引,未指定则获取所有列的数据
:return:返回指定行、列的数据
'''
# 打开excel文档
wb = openpyxl.load_workbook(file_name)
# 访问sheet页
sheet = wb[sheet]
# 获得指定行列的单元格
cell = sheet.iter_rows(max_row=max_row, min_row=min_row, max_col=max_col, min_col=min_col)
all_rows = []
# 获取单元格的值
for row in cell:
rows = []
for c in row:
rows.append(c.value)
all_rows.append(tuple(rows))
wb.close()
return all_rows rows = get_data_iter('测试.xlsx','Sheet',max_row=10,min_row=5,max_col=3,min_col=1)
print(rows)
for i in rows:
print(i)
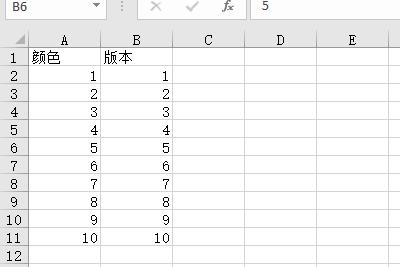
(五) 往空白的excel文档写数据
import openpyxl #创建excel文档
wb =openpyxl.Workbook()
sheet = wb['Sheet']
sheet['A1'] = '颜色'
sheet['B1'] = '版本'
x = 2
for i in range(10):
sheet['A'+str(x)] = i+1
sheet['B'+str(x)] = i+1
x += 1 wb.save('测试写数据.xlsx')
执行后,可以在当前工作目录下看到这个excel文档
(六) 往一个已经有数据的excel文档追加数据
要追加数据的话,获取已经有数据的最大索引就行了,从下一行开始添加数据,这里X的初始值忘记加1了,代码就不修改了,能看明白就行了
import openpyxl # 打开excel文档
wb = openpyxl.load_workbook('测试写数据.xlsx')
# 访问sheet页
sheet = wb['Sheet']
#获取最大行索引
maxRow = sheet.max_row
x = maxRow
for i in range(10):
sheet['A'+str(x)] = '追加数据'
sheet['B'+str(x)] = '追加数据'
x += 1 wb.save('测试写数据.xlsx')
执行完后:

Python笔记(十四):操作excel openpyxl模块的更多相关文章
- Python第十四天 序列化 pickle模块 cPickle模块 JSON模块 API的两种格式
Python第十四天 序列化 pickle模块 cPickle模块 JSON模块 API的两种格式 目录 Pycharm使用技巧(转载) Python第一天 安装 shell 文件 Py ...
- python3操作Excel openpyxl模块的使用
python 与excel 安装模块 本例子中使用的模块为: openpyxl 版本为2.4.8 安装方法请参看以前发表的文章(Python 的pip模块安装方法) Python处理Excel表格 使 ...
- Python笔记(十四)_永久存储pickle
pickle模块:将所有的Python对象转换成二进制文件存放 应用场景:编程时最好将大对象(列表.字典.集合等)用pickle写成永久数据包供程序调用,而不是直接写入程序 写入过程:将list转换为 ...
- python笔记十四(高阶函数——map/reduce、filter、sorted)
一.map/reduce 1.map() map(f,iterable),将一个iterable对象一次作用于函数f,并返回一个迭代器. >>> def f(x): #定义一个函数 ...
- python制作简单excel统计报表2之操作excel的模块openpyxl简单用法
python制作简单excel统计报表2之操作excel的模块openpyxl简单用法 # coding=utf-8 from openpyxl import Workbook, load_workb ...
- VSTO学习笔记(十四)Excel数据透视表与PowerPivot
原文:VSTO学习笔记(十四)Excel数据透视表与PowerPivot 近期公司内部在做一种通用查询报表,方便人力资源分析.统计数据.由于之前公司系统中有一个类似的查询使用Excel数据透视表完成的 ...
- Python第二十四天 binascii模块
Python第二十四天 binascii模块 binascii用来进行进制和字符串之间的转换 import binascii s = 'abcde' h = binascii.b2a_hex(s) # ...
- Python 3标准库 第十四章 应用构建模块
Python 3标准库 The Python3 Standard Library by Example -----------------------------------------第十四章 ...
- 孤荷凌寒自学python第二十四天python类中隐藏的私有方法探秘
孤荷凌寒自学python第二十四天python类中隐藏的私有方法探秘 (完整学习过程屏幕记录视频地址在文末,手写笔记在文末) 今天发现了python的类中隐藏着一些特殊的私有方法. 这些私有方法不管我 ...
随机推荐
- 25-socket
socket通信流程 #server端 #family参数代表地址家族,可为AF_INET或AF_UNIX.AF_INET家族包括#Internet地址,AF_UNIX家族用于同一台机器上的进程间通信 ...
- Python模块——logging模块
logging模块简介 logging模块定义的函数和类为应用程序和库的开发实现了一个灵活的事件日志系统.logging模块是Python的一个标准库模块, 由标准库模块提供日志记录API的关键好处是 ...
- laravel5实现第三方登录(微信)
背景 最近手头一个项目需要实现用户在网站的第三方登录(微信和微博),后端框架laravel5.4. 实现过程以微信网页版第三方登录,其他于此类似,在此不做重复. 准备工作 网站应用微信登录是基于OAu ...
- Oracle.ManagedDataAccess 提示ORA-01017 错误【解决方案】
Oracle.ManagedDataAccess 提示ORA-01017 错误[解决方案] Oracle.ManagedDataAccess 提示ORA-01017 错误[解决方案] [HKEY_LO ...
- mysql 开发进阶篇系列 40 mysql日志之二进制日志下以及查询日志
一.binlog 二进制其它选项 在二进制日志记录了数据的变化过程,对于数据的完整性和安全性起着非常重要作用.在mysql中还提供了一些其它参数选项,来进行更小粒度的管理. 1.1 binlog-do ...
- Java 动态生成 PDF 文件
每片文章前来首小诗: 今日夕阳伴薄雾,印着雪墙笑开颜.我心仿佛出窗前,浮在半腰望西天. --泥沙砖瓦浆木匠 需求: 项目里面有需要java动态生成 PDF 文件,提供下载.今天我找了下有关了,系 ...
- Shell脚本 | 截取包名
之前写 shell 脚本的几篇文章都是先大致介绍脚本的功能和写法,然后一股脑的给出完整的代码.并没有细致入微的解释脚本中的每一行是如何思考如何编写的. 今天反其道而行之,只介绍一行代码.争取能讲的清楚 ...
- Spring的Java配置方式—@Configuration和@Bean实现Java配置
Java配置是Spring4.x推荐的配置方式,可以完全替代xml配置. 1.@Configuration 和 @BeanSpring的Java配置方式是通过 @Configuration 和 @Be ...
- SpringBoot自动配置注解原理解析
1. SpringBoot启动主程序类: @SpringBootApplication public class DemoApplication { public static void main(S ...
- 深入浅出 JVM GC(4)常用 GC 参数介绍
# 前言 从前面的3篇文章中,我们分析了5个垃圾收集器,还有一些 GC 的算法,那么,在 GC 调优中,我们肯定会先判断哪里出现的问题,然后再根据出现的问题进行调优,而调优的手段就是 JVM 提供给我 ...