python爬虫笔记
1.抓取网页并保存到txt中.解决控制台乱码问题
#_*_coding:utf-8_*_
import urllib2
response = urllib2.urlopen('http://hws.m.taobao.com/cache/wdetail/5.0/?id=540698103032')
cont = response.read()
file1 = open("./1.txt","w")
file1.write(cont)
file1.close()
print cont.decode("utf-8").encode("gbk")
2.操作json
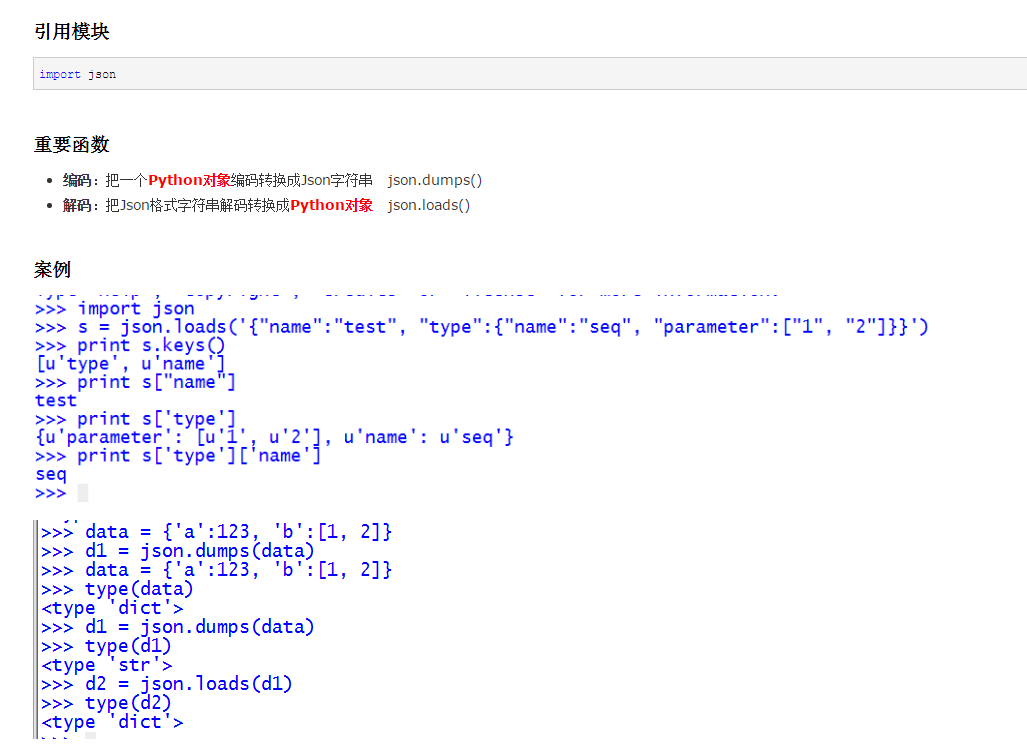
3.循环数组
https://www.cnblogs.com/Owen-ET/p/6932272.html
4.操作mssql
https://www.cnblogs.com/qianlifeng/archive/2012/02/06/2340367.html
https://www.cnblogs.com/lrzy/p/4346781.html
python爬虫笔记的更多相关文章
- [Python爬虫笔记][随意找个博客入门(一)]
[Python爬虫笔记][随意找个博客入门(一)] 标签(空格分隔): Python 爬虫 2016年暑假 来源博客:挣脱不足与蒙昧 1.简单的爬取特定url的html代码 import urllib ...
- Python爬虫笔记一(来自MOOC) Requests库入门
Python爬虫笔记一(来自MOOC) 提示:本文是我在中国大学MOOC里面自学以及敲的一部分代码,纯一个记录文,如果刚好有人也是看的这个课,方便搬运在自己电脑上运行. 课程为:北京理工大学-嵩天-P ...
- python爬虫笔记Day01
python爬虫笔记第一天 Requests库的安装 先在cmd中pip install requests 再打开Python IDM写入import requests 完成requests在.py文 ...
- Python爬虫笔记(一):爬虫基本入门
最近在做一个项目,这个项目需要使用网络爬虫从特定网站上爬取数据,于是乎,我打算写一个爬虫系列的文章,与大家分享如何编写一个爬虫.这是这个项目的第一篇文章,这次就简单介绍一下Python爬虫,后面根据项 ...
- Python爬虫笔记安装篇
目录 爬虫三步 请求库 Requests:阻塞式请求库 Requests是什么 Requests安装 selenium:浏览器自动化测试 selenium安装 PhantomJS:隐藏浏览器窗口 Ph ...
- Python爬虫笔记技术篇
目录 前言 requests出现中文乱码 使用代理 BeautifulSoup的使用 Selenium的使用 基础使用 Selenium获取网页动态数据赋值给BeautifulSoup Seleniu ...
- Python爬虫笔记【一】模拟用户访问之设置请求头 (1)
学习的课本为<python网络数据采集>,大部分代码来此此书. 网络爬虫爬取数据首先就是要有爬取的权限,没有爬取的权限再好的代码也不能运行.所以首先要伪装自己的爬虫,让爬虫不像爬虫而是像人 ...
- Python爬虫笔记(一)
个人笔记,仅适合个人使用(大部分摘抄自python修行路) 1.爬虫Response的内容 便是所要获取的页面内容,类型可能是HTML,Json(json数据处理链接)字符串,二进制数据(图片或者视频 ...
- Python 爬虫笔记(二)
个人笔记,仅适合个人使用(大部分摘抄自python修行路) 1.使用selenium(传送) selenium 是一套完整的web应用程序测试系统,包含了测试的录制(selenium IDE),编写及 ...
- Python 爬虫笔记、多线程、xml解析、基础笔记(不定时更新)
1 Python学习网址:http://www.runoob.com/python/python-multithreading.html
随机推荐
- [蓝桥杯]ALGO-188.算法训练_P0504
Anagrams指的是具有如下特性的两个单词:在这两个单词当中,每一个英文字母(不区分大小写)所出现的次数都是相同的.例如,Unclear和Nuclear.Rimon和MinOR都是Anagrams. ...
- 廖雪峰Java7处理日期和时间-3java.time的API-2ZonedDateTime
ZonedDatetime = LocalDateTime + ZoneId ZonedDateTime:带时区的日期和时间 ZoneId:新的API定义的时区对象(取代几句的java.util.Ti ...
- word embeddding和keras中的embedding
训练好的词向量模型被保存下来,该模型的本质就是一个m*n的矩阵,m代表训练语料中词的个数,n代表训练时我们设定的词向量维度.当我们训练好模型后再次调用时,就可以从该模型中直接获取到对应词的词向量. 通 ...
- python数据处理 pandas用法大全
一.生成数据表 1.首先导入pandas库,一般都会用到numpy库,所以我们先导入备用: import numpy as np import pandas as pd 1 2 2.导入CSV ...
- syslog-ng日志收集分析服务搭建及配置
syslog-ng日志收集分析服务搭建及配置:1.网上下载eventlog_0.2.12.tar.gz.libol-0.3.18.tar.gz.syslog-ng_3.3.5.tar.gz三个软件: ...
- Redis-Sentinel 数据源配置
1.redis配置文件 : redis.properties # Redis settings #sentinel_node_1 redis.sentinel1.host=192.168.0.1 re ...
- Music Recommendation System with User-based and Item-based Collaborative Filtering Technique(使用基于用户及基于物品的协同过滤技术的音乐推荐系统)【更新】
摘要: 大数据催生了互联网,电子商务,也导致了信息过载.信息过载的问题可以由推荐系统来解决.推荐系统可以提供选择新产品(电影,音乐等)的建议.这篇论文介绍了一个音乐推荐系统,它会根据用户的历史行为和口 ...
- 01 Python 逻辑运算
#基本运算符 #and or not #优先级 ()>not>and>or #and or not print(2>1 and 1<4 or 2<3 and 9&g ...
- python大法好—模块 续
1.sys模块 sys模块的常见函数列表 sys.argv: 实现从程序外部向程序传递参数. sys.exit([arg]): 程序中间的退出,arg=0为正常退出. sys.getdefaulten ...
- SSH登录启用Google二次身份验证
一般来说,使用ssh远程登录服务器,只需要输入账号和密码,显然这种方式不是很安全.为了安全着想,可以使用GoogleAuthenticator(谷歌身份验证器),以便在账号和密码之间再增加一个验证码, ...