Linux 堆溢出原理分析
堆溢出与堆的内存布局有关,要搞明白堆溢出,首先要清楚的是malloc()分配的堆内存布局是什么样子,free()操作后又变成什么样子。
解决第一个问题:通过malloc()分配的堆内存,如何布局?


上图就是malloc()分配两块内存的情形。
其中mem指针指向的是malloc()返回的地址,pre_size与size都是4字节数据,size存放当前chunk(内存块,本文均不翻译)大小,pre_size存放上一个chunk大小。
因为malloc实现分配的内存空间是8字节对齐的,所以size的低3位其实没用,就取其中一位,用来标志前一个chunk是否被释放即PREV_INUSE位。当前一chunk释放,PREV_INUSE位置0,否则置1。
当malloc()分配的空间使用完毕后,将其mem指针传给free()进行释放。
解决第二个问题:free()对堆内存布局会产生什么影响?
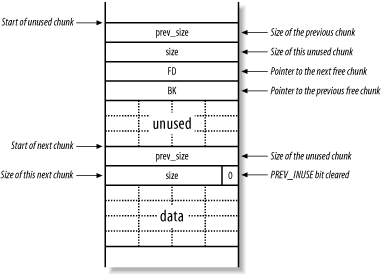

上图的情形是,当前chunk的上一chunk被free()释放,容易发现,当前chunk的PREV_ISUSE标志位置0,表示前一chunk已经被释放。
被释放的chunk中,原先data的位置的低地址处被填入两个指针,分别是fd和bk,它们是forward和backward单词的缩写,分别表示前一个free chunk和后一个free chunk的地址。这样所有通过free()释放的内存chunk会组成一个双向链表。也因此一个chunk最小长度为16字节:2个size和2个指针。
当一个chunk被释放时,还有一件事情要做,就是检查相邻chunk的是否处于释放状态,如果相邻chunk空闲的话,就会进行chunk合并操作。由于每个chunk中都存放了size信息,所以很容易就找到当前chunk前后chunk的状态。
free()里面会调用一个unlink宏来执行合并操作:
#define unlink(P, BK, FD) { \
FD = P->fd; \
BK = P->bk; \
FD->bk = BK; \
BK->fd = FD; \
}
好了,这个宏就是堆溢出利用的关键。仔细阅读这个宏其实就是在一个双向链表中删除一个结点的操作:
P->fd->bk = P->bk
P->bk->fd = P->fd
其中P代表当前被删除结点。
解决最后一个问题:堆溢出如何利用?
首先构造一段堆溢出漏洞代码:
int main(void)
{
char *buff1, *buff2;
buff1 = malloc(40);
buff2 = malloc(40);
gets(buff1);
free(buff1);
exit(0);
}
给出堆空间布局:
low address
+---------------------+ <--first chunk ptr
| prev_size |
+---------------------+
| size=48 |
+---------------------+ <--first
| |
| allocated |
| chunk |
+---------------------+ <--second chunk ptr
| prev_size |
+---------------------+
| size=48 |
+---------------------+ <--second
| Allocated |
| chunk |
+---------------------+
high address
现在使用gets函数进行堆溢出,将第2块chunk的prev_size覆盖为任意值,size覆盖为-4即0xfffffffc,fd位置覆盖为exit@got-12,bk位置覆盖为shellcode地址。
覆盖后的堆空间布局情况:
low address
+---------------------+ <--first chunk ptr
| prev_size |
+---------------------+
| size=48 |
+---------------------+ <--first
| |
| allocated |
| chunk |
+---------------------+ <--second chunk ptr
| XXXXXXXXX |
+---------------------+
| size=0xfffffffc |
+---------------------+ <--second
| exit@got-12 |
| shellcode地址 |
| Allocated |
| chunk |
+---------------------+
high address
下面看free(buff1)时发生的操作:
1.first空间即buff1被释放掉
2.检查上一chunk是否需要合并(这里否)
3.检查下一chunk是否需要合并,检查的方法是检查下下个chunk的PREV_ISUSE标志位。即当前chunk加上当前size得到下个chunk,下个chunk加上下个size得到下下个chunk,因为我们设置下个chunk大小为-4,则下个chunk的pre_size位置被认为是下下个chunk的开始,下个size位置是0xfffffffc标志未置位,被认为是free的需合并。
那么,这里合并用到unlink宏时出问题了,同样对照上面图来看:
second->fd->bk=second->bk
/* 1.second->bk是shellcode址
2.shellcode的地址被写进了second->fd+12的位置
3.second->fd是exit@got的地址-12
4.所以second->fd+12的位置就是exit@got-12 + 12 = exit@got即got中存的exit地址
因此exit()函数地址已经被shellcode地址替换
*/
second->bk->fd=second->fd
“shellcode的地址被写进了second->fd+12的位置” 这句话要好好理解,为什么second->fd->bk是second->fd+12呢? 其实second->fd指向前一chunk头部,加12是跳过pre_size,size和fd即到达bk位置。
最后程序在执行到exit(0)语句时,由于地址被替换,shellcode执行。
Linux 堆溢出原理分析的更多相关文章
- Linux堆溢出漏洞利用之unlink
Linux堆溢出漏洞利用之unlink 作者:走位@阿里聚安全 0 前言 之前我们深入了解了glibc malloc的运行机制(文章链接请看文末▼),下面就让我们开始真正的堆溢出漏洞利用学习吧.说实话 ...
- Linux Kbuild工作原理分析(以DVSDK生成PowerVR显卡内核模块为例)
一.引文 前篇博文<Makefile之Linux内核模块的Makefile写法分析>,介绍了Linux编译生成内核驱动模块的Makefile的写法,但最近在DVSDK下使用Linux2.6 ...
- CVE-2012-1876:Internet Exporter MSHTML.DLL CaculateMinMax 堆溢出简单分析
0x01 2012 Pwn2Own 黑客大赛 Pwn2Own 是世界上最著名的黑客大赛,意在激励白帽黑客们进行顶尖的安全研究.在 2012 年 Pwn2Own 大赛上,来自法国著名的安全团队 Vupe ...
- 【linux】helloword原理分析及实战
目录 前言 linux中hello word原理 hello word 实战 学习参考 前言 hello word 著名演示程序,哈哈 下面在 arm linux 下展示一下hello world,便 ...
- linux下编译原理分析
linux下编译hello.c 程序,使用gcc hello.c,然后./a.out就能够执行:在这个简单的命令后面隐藏了很多复杂的过程,这个过程包含了以下的步骤: ================= ...
- Linux ubi子系统原理分析
本文思维导图总纲: 综述 关于ubi子系统,早已有比较正式的介绍,也提供非常形象的介绍ubi子系统ppt 国内的前辈 alloysystem 不辞辛劳为我们提供了部分正式介绍的中文译文,以及找不到原文 ...
- 利用DWORD SHOOT实现堆溢出的利用(先知收录)
原文链接:https://xz.aliyun.com/t/4009 1.0 DWORD SHOOT是什么捏? DWORD SHOOT指能够向内存任意位置写入任意数据,1个WORD=4个bytes,即可 ...
- CVE_2012_1876堆溢出分析
首先用windbg附加进程ie页面内容进程,!gflag +hpa添加堆尾检查,.childdbg 1允许子进程调试,然后加载POC. POC: <html> <body> & ...
- linux下堆溢出unlink的一个简单例子及利用
最近认真学习了下linux下堆的管理及堆溢出利用,做下笔记:作者作为初学者,如果有什么写的不对的地方而您又碰巧看到,欢迎指正. 本文用到的例子下载链接https://github.com/ctfs/w ...
随机推荐
- Linux NFS挂载
Linux NFS挂载 一.NFS挂载 192.25.10.101/home/sharedata/azkaban/ODS_HS08 挂载到 192.25.10.102/home/data_azkaba ...
- aliplayer 视频播放报错
问题总结: 1.引用 阿里库时href和src 文件路径不加http <link rel="stylesheet" href="//g.alicdn.com/de/ ...
- [c/c++] programming之路(21)、字符串(二)
一.for /l %i in (1,1,5) do calc 等命令行参数 #define _CRT_SECURE_NO_WARNINGS #include<stdio.h> #inclu ...
- 【Visual Studio 扩展工具】使用 ComponentOne迷你图控件,进行可视化数据趋势分析
概述 迷你图 —— Sparklines是迷你的轻量级图表,有助于快速可视化数据. 它们是由数据可视化传奇人物Edward Tufte发明的,他将其描述为“数据密集,设计简单,字节大小的图形.”虽然迷 ...
- 6th-Python基础——集合、函数
1.集合 主要作用: (1)去重 (2)关系测试,交集.差集difference().并集union().反向差集symmetric_difference().子集issubset().父集issup ...
- [福建集训2011][LOJ10111]相框
这题主要还是分类讨论欧拉回路 首先对于导线一端没有东西的新建一个节点 由于原图不一定连通所以需要用到并查集判断有多少个连通块 将一条导线连接的两个焊点连接 然后先对于只有一个连通块考虑 1.如果一个焊 ...
- IOS面试题2018/11/17
1.设计模式是什么?你知道哪些设计模式? 设计模式是一种编码经验,就是一种成熟的逻辑去处理某一种类型的事情. 1.MVC模式:model view controller,把模型,视图,控制器 层进行解 ...
- TestMap
public class TestMap { public static void main(String[] args) { Map map=new HashMap(); //在此映射中关联指定值与 ...
- 误操作yum导致error: rpmdb
error: cannot open Packages index using db5 - (-30973) error: cannot open Packages database in /var ...
- 使用Wscript/cscript调用VB脚本
●强制用Wscript.exe执行 SET Wshell=CreateObject("Wscript.Shell") if lcase(right(Wscript.fullName ...