Hbase简单配置与使用
一、 HBase的
二、基于Hadoop的HBase架构
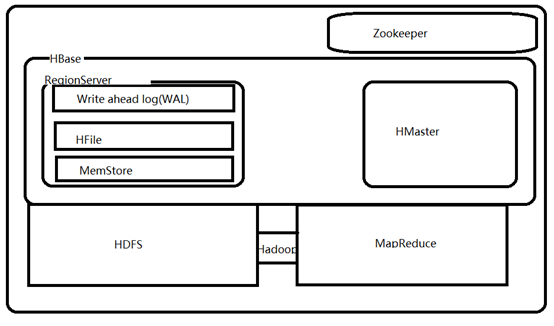
HBase内置有zookeeper,但一般我们会有其他的Zookeeper集群来监管master和regionserver,Zookeeper通过选举,保证任何时候,集群中只有一个活跃的HMaster,HMaster与HRegionServer 启动时会向ZooKeeper注册,存储所有HRegion的寻址入口,实时监控HRegionserver的上线和下线信息。并实时通知给HMaster,存储HBase的schema和table元数据,默认情况下,HBase 管理ZooKeeper 实例,Zookeeper的引入使得HMaster不再是单点故障。一般情况下会启动两个HMaster,非Active的HMaster会定期的和Active HMaster通信以获取其最新状态,从而保证它是实时更新的,因而如果启动了多个HMaster反而增加了Active HMaster的负担。
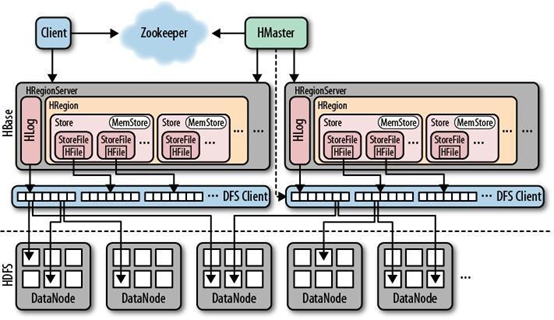
一个RegionServer可以包含多个HRegion,每个HRegion维护一个HLog,和多个HFiles以及其对应的MemStore。RegionServer运行于DataNode上,数量可以与DatNode数量一致,请参考如下架构图:
四、HBase特征简要
4.1、自动故障处理和负载均衡
HBase运行在HDFS上,所以HBase中的数据以多副本形式存放,数据也服从分布式存放,数据的恢复也可以得到保障。另外,HMaster和RegionServer也是多副本的。
4.2、自动分区
HBase表是由分布在多个RegionServer中的region组成的,这些RegionServer又分布在不同的DataNode上,如果一个region增长到了一个阈值,为了负载均衡和减少IO,HBase可以自动或手动干预的将region切分为更小的region,也称之为subregion。
4.3、集成Hadoop/HDFS
虽然HBase也可以运行在其他的分布式文件系统之上,但是与HDFS结合非常之方便,而且HDFS也非常之流行。
4.4、实时随机大数据访问
HBase采用log-structured merge-tree作为内部数据存储架构,这种架构会周期性地将小文件合并成大文件以减少磁盘访问同时减少NameNode压力。
4.5、MapReduce
HBase内建支持MapReduce框架,更加方便快速,并行的处理数据。
4.6、Java API
HBase提供原声的Java API支持,方便开发。
4.7、横向扩展
HBase支持横向扩展,这就意味着如果现有服务器硬件性能出现瓶颈,不需要停掉现有集群提升硬件配置,而只需要在现有的正在运行的集群中添加新的机器节点即可,而且新的RegionServer一旦建立完毕,集群会开始重新调整。
4.8、列存储
HBase是面向列存储的,每个列都单独存储,所以在HBase中列是连续存储的,而行不是。
4.9、HBase Shell
HBase提供了交互式命令行工具可以进行创建表、添加数据、扫描数据、删除数据等操作和其他一些管理命令。
五、HBase在集群中的定位
HBase一种是作为存储的分布式文件系统,另一种是作为数据处理模型的MR框架。因为日常开发人员比较熟练的是结构化的数据进行处理,但是在HDFS直接存储的文件往往不具有结构化,所以催生出了HBase在HDFS上的操作。如果需要查询数据,只需要通过键值便可以成功访问。
六、HBase内部存储架构
HBase是由row key,column family,column和cell组成,row key确定唯一的一行,column family由若干column组成,column是表的字段,cell存储了实际的值或数据。
七、HBase与Hadoop
7.1、HDFS
* 为分布式存储提供文件系统
* 针对存储大尺寸的文件进行优化,不需要对HDFS上的文件进行随机读写
* 直接使用文件
* 数据模型不灵活
* 使用文件系统和处理框架
* 优化一次写入,多次读取的方式
7.2、HBase
* 提供表状的面向列的数据存储
* 针对表状数据的随机读写进行优化
* 使用key-value操作数据
* 提供灵活的数据模型
* 使用表状存储,支持MapReduce,依赖HDFS
* 优化了多次读,以及多次写
八、HBase的优缺点
8.1、优点
* 方便高效的压缩数据
* 支持快速数据检索
* 管理和配置简单,支持横向扩展,所以非常容易扩展
* 聚合查询性能非常高
* 可高效地进行分区,提供自动分区机制把大的region切分成小的subregion
8.2、缺点
* 对JOIN以及多表合并数据的查询性能不好
* 更新过程中有大量的写入和删除操作,需要频繁合并和分裂,降低存储效率
* 对关系模型支持不好,分区和索引模式设计比较困难。
九、HBase的环境角色
9.1、HMaster
9.1.1、功能描述
* 监控RegionServer
* 处理RegionServer故障转移
* 处理元数据的变更
* 处理region的分配或移除
* 在空闲时间进行数据的负载均衡
* 通过Zookeeper发布自己的位置给客户端
9.2、RegionServer
9.2.1、功能描述
* 负责存储HBase的实际数据
* 处理分配给它的Region
* 刷新缓存到HDFS
* 维护HLog
* 执行压缩
* 负责处理Region分片
9.2.2、内含组件
* Write-Ahead logs
HBase的修改记录,当对HBase读写数据的时候,数据不是直接写进磁盘,它会在内存中保留一段时间(时间以及数据量阈值可以设定)。如果机器突然原地爆炸,把数据保存在内存中会引起数据丢失,为了解决这个问题,数据会先写在一个叫做Write-Ahead logfile的文件中,然后再写入内存中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
* HFile
这是在磁盘上保存原始数据的实际的物理文件,是实际的存储文件。
* Store
HFile存储在Store中,一个Store对应HBase表中的一个列族
* MemStore
顾名思义,就是内存存储,位于内存中,用来保存当前的数据操作,所以当数据保存在WAL中之后,RegsionServer会在内存中存储键值对。
* Region
Hbase表的分片,HBase表会根据RowKey值被切分成不同的region存储在RegionServer中,在一个RegionServer中可以有多个不同的region
9.3、Zookeeper
HMaster与HRegionServer 启动时会向ZooKeeper注册,存储所有HRegion的寻址入口,实时监控HRegionserver的上线和下线信息。并实时通知给HMaster,存储HBase的schema和table元数据,默认情况下,HBase 管理ZooKeeper 实例,Zookeeper的引入使得HMaster不再是单点故障。一般情况下会启动两个HMaster,非Active的HMaster会定期的和Active HMaster通信以获取其最新状态,从而保证它是实时更新的,因而如果启动了多个HMaster反而增加了Active HMaster的负担。
十、使用场景的探讨
10.1、何时使用
* 如果数据有很多列,且包含很多空字段
* 数据包含了不定数量的列
* 需要维护数据的版本
* 需要很高的横向扩展性
* 需要大量的压缩数据
* 需要大量的I/O
一般而言数百万行的数据和频率不高的读写操作,是不需要HBase的,如果有几十亿列数据,同时在单位时间内有数以千、万记的读写操作,可以考虑HBase。
10.2、何时不使用
* 数据总量不大时(比如就几个G)
* 当需要JOIN以及关系型数据库的一些特性时
* 如果关系型数据库可以满足需求
十一、HBase的安装与部署
11.1、Zookeeper集群的正常部署并启动
$ /opt/modules/cdh/zookeeper-3.4.5-cdh5.3.6/bin/zkServer.sh start
11.2、Hadoop集群的正常部署并启动(我的为高可用HA)
$ /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/sbin/start-dfs.sh
$ /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/sbin/start-yarn.sh
11.3、上传(hbase-0.98.6-cdh5.3.6.tar.gz)并解压HBase
tar -zxvf hbase-0.98.6-cdh5.3.6.tar.gz -C /opt/module/
11.4进入配置文件目录( cd /opt/module/hbase-0.98.6-cdh5.3.6/conf/)
11.5删除cmd文件 ( rm -rf *.cmd )
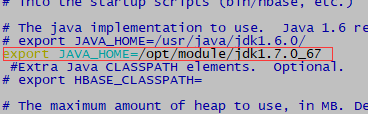
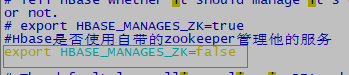
11.6修改hbase-env.sh (vim hbase-env.sh )
11.7修改hbase-site.xml ( vim hbase-site.xml ),在<configuration>中添加
<configuration>
<!--设置hbase节点位置 如果为高可用,则为高可用的名称例:hdfs://mycluster/hbase
如果是单节点,应该写成具体的哪台机器例:hdfs://hadoop201:80e
-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://mycluster/hbase</value>
</property>
<!-- 是否运行在分布式上面 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property> <!-- 指定master节点 ,两种方式
1.只写端口号,表示可能用于高可用 例:60000
2.配置绝对的路径例:hadoop201:60000
-->
<property>
<name>hbase.master</name>
<value>60000</value>
</property> <!-- -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop201:2181,hadoop202:2181,hadoop203:2181</value>
</property> <!-- 配置zookeeper的dataDir路径(会自动创建) -->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/module/zookeeper-3.4.5-cdh5.3.6/data/zkData</value>
</property> </configuration>
11.8regionservers ( vim regionservers )
hadoop201
hadoop202
hadoop203
11.9替换HBase根目录下的lib目录下的与自己使用的版本不同的jar包为自己使用的jar包,以解决兼容问题
cd /opt/module/hbase-0.98.6-cdh5.3.6/lib/
rm -rf hadoop-*
如果zookeeper与使用的不同也需要删除替换,这里我的一样就不替换了()
涉及的jar包大约有
hadoop-annotations-2.5.0.jar
hadoop-auth-2.5.0-cdh5.3.6.jar
hadoop-client-2.5.0-cdh5.3.6.jar
hadoop-common-2.5.0-cdh5.3.6.jar
hadoop-hdfs-2.5.0-cdh5.3.6.jar
hadoop-mapreduce-client-app-2.5.0-cdh5.3.6.jar
hadoop-mapreduce-client-common-2.5.0-cdh5.3.6.jar
hadoop-mapreduce-client-core-2.5.0-cdh5.3.6.jar
hadoop-mapreduce-client-hs-2.5.0-cdh5.3.6.jar
hadoop-mapreduce-client-hs-plugins-2.5.0-cdh5.3.6.jar
hadoop-mapreduce-client-jobclient-2.5.0-cdh5.3.6.jar
hadoop-mapreduce-client-jobclient-2.5.0-cdh5.3.6-tests.jar
hadoop-mapreduce-client-shuffle-2.5.0-cdh5.3.6.jar
hadoop-yarn-api-2.5.0-cdh5.3.6.jar
hadoop-yarn-applications-distributedshell-2.5.0-cdh5.3.6.jar
hadoop-yarn-applications-unmanaged-am-launcher-2.5.0-cdh5.3.6.jar
hadoop-yarn-client-2.5.0-cdh5.3.6.jar
hadoop-yarn-common-2.5.0-cdh5.3.6.jar
hadoop-yarn-server-applicationhistoryservice-2.5.0-cdh5.3.6.jar
hadoop-yarn-server-common-2.5.0-cdh5.3.6.jar
hadoop-yarn-server-nodemanager-2.5.0-cdh5.3.6.jar
hadoop-yarn-server-resourcemanager-2.5.0-cdh5.3.6.jar
hadoop-yarn-server-tests-2.5.0-cdh5.3.6.jar
hadoop-yarn-server-web-proxy-2.5.0-cdh5.3.6.jar
zookeeper-3.4.5-cdh5.3.6.jar
可以通过find命令快速进行定位,例如
cd /opt/module/hadoop-2.5.0-cdh5.3.6/
find -name hadoop-hdfs-2.5.0-cdh5.3.6.jar

然后将找到的jar包复制到hbase的lib目录下
注:这里有我整理好的此版本的jar包放在(CDH_HadoopJar.tar.gz) (cp -a /opt/software/HadoopJar/* /opt/module/hbase-0.98.6-cdh5.3.6/lib/)
11.10将整理好的HBase安装目录scp到其他机器节点
cd /opt/module/
scp -r hbase-0.98.6-cdh5.3.6/ hadoop202:/opt/module/
scp -r hbase-0.98.6-cdh5.3.6/ hadoop203:/opt/module/
11.11将Hadoop配置文件软连接到HBase的conf目录下
* core-site.xml
$ ln -s /opt/module/hadoop-2.5.0-cdh5.3.6/etc/hadoop/core-site.xml /opt/module/hbase-0.98.6-cdh5.3.6/conf/core-site.xml
* hdfs-site.xml
$ ln -s /opt/module/hadoop-2.5.0-cdh5.3.6/etc/hadoop/hdfs-site.xml /opt/module/hbase-0.98.6-cdh5.3.6/conf/hdfs-site.xml
(尖叫提示:不要忘记其他几台机器也要做此操作)
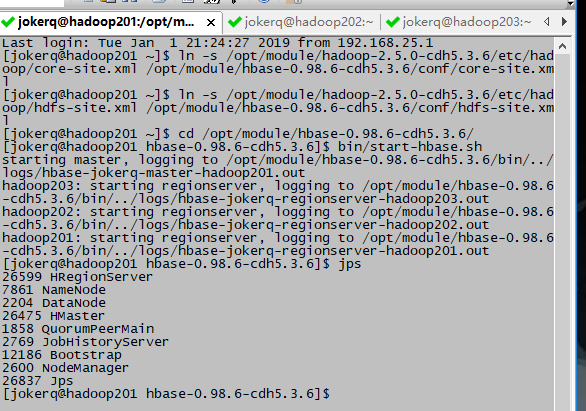
11.12启动服务
$ bin/hbase-daemon.sh start master
$ bin/hbase-daemon.sh start regionserver
或者:
$ bin/start-hbase.sh
对应的停止命令:
$ bin/stop-hbase.sh
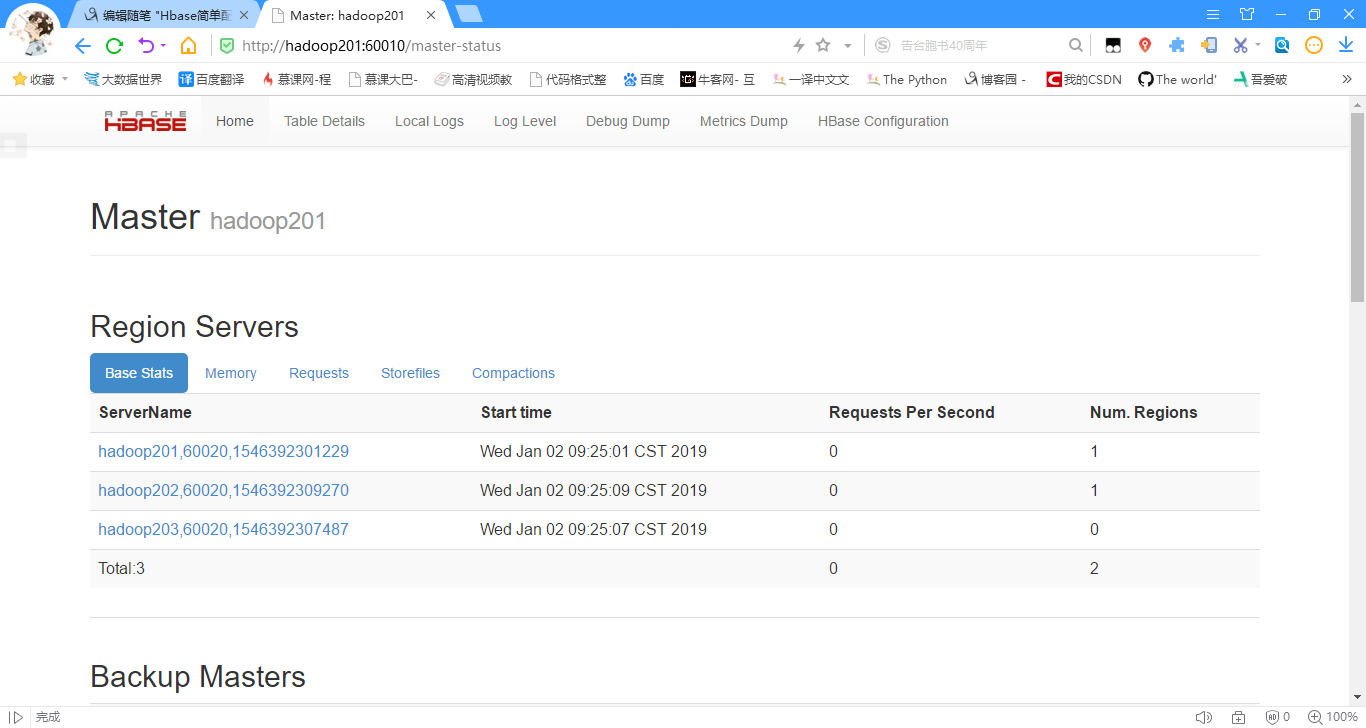
11.13查看页面
启动成功后,可以通过主机名:60010地址来访问HBase的管理页面
例如,http://hadoop201:60010
十二、HBase常用操作
12.1、进入HBase客户端命令操作界面
$ bin/hbase shell
12.2、查看帮助命令
hbase(main):001:0> help
12.3、查看当前数据库中有哪些表
hbase(main):002:0> list
12.4、创建一张表( create '表名','列祖名' )
hbase(main):003:0> create 'student','info'
12.5、向表中存储一些数据( put '表名','ROWKEY','列族名:列名','值' )
hbase(main):004:0> put 'student','1001','info:name','Thomas'
hbase(main):005:0> put 'student','1001','info:sex','male'
hbase(main):006:0> put 'student','1001','info:age','18'
12.6、扫描查看存储的数据
hbase(main):007:0> scan 'student'
 (表名+RowKey+列族+列+(时间戳)+值)
(表名+RowKey+列族+列+(时间戳)+值)
或:查看某个rowkey范围内的数据
hbase(main):014:0> scan 'student',{STARTROW => '1001',STOPROW => '1007'}
12.7查看表结构
hbase(main):009:0> describe 'student'

12.8更新指定字段的数据
hbase(main):009:0> put 'student','1001','info:name','Nick'
hbase(main):010:0> put 'student','1001','info:age','100'
12.9查看指定行的数据
hbase(main):012:0> get 'student','1001'
或:查看指定行指定列或列族的数据
hbase(main):013:0> get 'student','1001','info:name'
12.10删除数据
12.10.1删除某一个rowKey全部的数据
hbase(main):015:0> deleteall 'student','1001'
12.10.2删除掉某个rowKey中某一列的数据
hbase(main):016:0> delete 'student','1001','info:sex'
12.11清空表数据
hbase(main):017:0> truncate 'student'
12.12删除表
首先需要先让该表为disable状态,使用命令:
hbase(main):018:0> disable 'student'
然后才能drop这个表,使用命令:
hbase(main):019:0> drop 'student'
(尖叫提示:如果直接drop表,会报错:Drop the named table. Table must first be disabled)
12.13统计一张表有多少行数据
hbase(main):020:0> count 'student'
十三、HMaster的高可用
13.1、确保HBase集群已正常停止
$ bin/stop-hbase.sh
13.2、在conf目录下创建backup-masters文件
$ touch conf/backup-masters
13.3、在backup-masters文件中配置高可用HMaster节点
$ echo hadoop202 > conf/backup-masters
13.4、将整个conf目录scp到其他节点
$ scp -r conf/ hadoop202:/opt/module/hbase-0.98.6-cdh5.3.6/
$ scp -r conf/ hadoop203:/opt/module/hbase-0.98.6-cdh5.3.6/
13.5、打开页面测试
最后,可以尝试关闭第一台机器的HMaster:
$ bin/hbase-daemon.sh stop master
然后查看第二台的HMaster是否会直接启用
Hbase简单配置与使用的更多相关文章
- HBase + Kerberos 配置示例(二)
接上篇<HBase + Kerberos配置示例(一)>,我们继续剩下的配置工作. 环境准备 Hadoop配置 Zookeeper配置 HBase配置 Java测试程序 环境准备 安装ha ...
- hbase安装配置(整合到hadoop)
hbase安装配置(整合到hadoop) 如果想详细了解hbase的安装:http://abloz.com/hbase/book.html 和官网http://hbase.apache.org/ 1. ...
- Phoenix(sql on hbase)简单介绍
Phoenix(sql on hbase)简单介绍 介绍: Phoenix is a SQL skin over HBase delivered as a client-embedded JDBC d ...
- 企业级hbase HA配置
1 HBase介绍HBase是一个分布式的.面向列的开源数据库,就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类 ...
- 小丁带你走进git世界一-git简单配置
小丁带你走进git世界一-git简单配置 1.github的简单配置 配置提交代码的信息,例如是谁提交的代码之类的. git config –global user.name BattleHeaer ...
- 以实际的WebGIS例子探讨Nginx的简单配置
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/ 1.背景 以实际项目中的一个例子来详细讲解Nginx中的一般配置,其中涉 ...
- CentOS 7.0 使用 yum 安装 MariaDB 与 MariaDB 的简单配置
1.安装MariaDB 安装命令 yum -y install mariadb mariadb-server 安装完成MariaDB,首先启动MariaDB,两条命令都可以 systemctl sta ...
- ssm简单配置
MyBatis 是一个可以自定义SQL.存储过程和高级映射的持久层框架. MyBatis 摒除了大部分的JDBC代码.手工设置参数和结果集重获. MyBatis 只使用简单的XML 和注解来配置和映射 ...
- 安装MariaDB和简单配置
1.安装MariaDB 安装命令 yum -y install mariadb mariadb-server 安装完成MariaDB,首先启动MariaDB systemctl start maria ...
随机推荐
- JS应用实例2:轮播图
在学习轮播图之前,要先会切换图片: 找三张图片,命名1.jpg,2.jpg,3.jpg 示例: <!DOCTYPE html> <html> <head> < ...
- python实现线性排序-基数排序
基数排序算法是一种是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较. 由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排序也不是只能使用于 ...
- Tools - 源代码阅读分析工具Source Insight
简介 https://www.sourceinsight.com/ Source Insight是一个面向项目开发的程序编辑器和代码浏览器,可以分析C/C++.C#.Java.Python等语言源代码 ...
- 678 "流浪地球"为什么是个好地方?(系统越复杂拥有好运气的机会也就越大)
运气,其实就是一个复杂系统孕育出的,超出已知经验的解决方案.它不是没有产生机制.只不过,这个机制太复杂,涉及的因素太多.我们没法复制.所以,我们只能笼统的,把这套机制称为运气,或者命数. 举个例子,假 ...
- spring boot 集成 Listener 的两种方式
1)@ServletComponentScan注解+@WebListener注解 2)@Bean注解+ServletListenerRegistrationBean类
- python之getpass模块使用
我们登入linux时,输入密码是什么都不显示的,在python中也可以这样做,那就是getpass模块(在pycharm中无法使用) getpass模块中包含几个比较实用的功能: 1.getpass ...
- firefox设置每次访问时检查缓存
1.在firefox的地址栏上输入about:config回车2.找到browser.cache.check_doc_frequency选项,双击将3改成1保存即可. 选项每个值都是什么含义的.请看下 ...
- 《ASP.NET Core跨平台开发从入门到实战》Web API自定义格式化protobuf
<ASP.NET Core跨平台开发从入门到实战>样章节 Web API自定义格式化protobuf. 样章 Protocol Buffers 是一种轻便高效的结构化数据存储格式,可以用于 ...
- ABP默认生成数据库结构
数据库设计文档 -- MyFirstABP 数据库设计文档 数据库名:MyFirstABP 序号 表名 说明 1 AbpFeatures 2 AbpEditions 3 AbpLanguage ...
- 【Shell实战】定期清理日志文件的shell脚本
功能描述:清理/var/log/路径下的messages历史日志文件(messages-date),但不清理messages文件本身 依赖要求:服务器上安装了bc模块 # clean_logs.sh ...