python进阶之 进程编程
1.进程
顾名思义,进程即正在执行的一个过程。进程是对正在运行程序的一个抽象。 进程的概念起源于操作系统,是操作系统最核心的概念,也是操作系统提供的最古老也是最重要的抽象概念之一。操作系统的其他所有内容都是围绕进程的概念展开的。 即使可以利用的cpu只有一个(早期的计算机确实如此),也能保证支持(伪)并发的能力。将一个单独的cpu变成多个虚拟的cpu(多道技术:时间多路复用和空间多路复用+硬件上支持隔离),没有进程的抽象,现代计算机将不复存在。 进程的概念: 进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。 在早期面向进程设计的计算机结构中,进程是程序的基本执行实体;在当代面向线程设计的计算机结构中,进程是线程的容器。程序是指令、数据及其组织形式的描述,进程是程序的实体。
2.cpu处理调度机制
先来先服务(FCFS)调度算法是一种最简单的调度算法,该算法既可用于作业调度,也可用于进程调度。FCFS算法比较有利于长作业(进程),而不利于短作业(进程)。由此可知,本算法适合于CPU繁忙型作业,而不利于I/O繁忙型的作业(进程)。 FCFS调度算法的平均作业周转时间与作业提交的顺序和所需CPU时间有关 作业名 所需CPU时间 作业1 28 作业2 9 作业3 3 采用FCFS算法,三个作业的周转时间分别为:28、37和40,因此,平均作业周转时间T = (28+37+40)/3 = 35 若三个作业提交顺序改为作业2、1、3,平均作业周转时间约为29。 ((9+37+40)/3≈29) 若三个作业提交顺序改为作业3、2、1,平均作业周转时间约为18。 ((3+12+40)/3≈18)
短作业(进程)优先调度算法(SJ/PF)是指对短作业或短进程优先调度的算法,该算法既可用于作业调度,也可用于进程调度。但其对长作业不利;不能保证紧迫性作业(进程)被及时处理;作业的长短只是被估算出来的。
优点:
比FCFS改善平均周转时间和平均带权周转时间,缩短作业的等待时间;
提高系统的吞吐量;
缺点:
对长作业非常不利,可能长时间得不到执行;
未能依据作业的紧迫程度来划分执行的优先级;
难以准确估计作业(进程)的执行时间,从而影响调度性能。
时间片轮转(Round Robin,RR)算法的基本思路是让每个进程在就绪队列中的等待时间与享受服务的时间成比例。在时间片轮转法中,需要将CPU的处理时间分成固定大小的时间片,例如,几十毫秒至几百毫秒。如果一个进程在被调度选中之后用完了系统规定的时间片,但又未完成要求的任务,则它自行释放自己所占有的CPU而排到就绪队列的末尾,等待下一次调度。同时,进程调度程序又去调度当前就绪队列中的第一个进程。 显然,轮转法只能用来调度分配一些可以抢占的资源。这些可以抢占的资源可以随时被剥夺,而且可以将它们再分配给别的进程。CPU是可抢占资源的一种。但打印机等资源是不可抢占的。由于作业调度是对除了CPU之外的所有系统硬件资源的分配,其中包含有不可抢占资源,所以作业调度不使用轮转法。 在轮转法中,时间片长度的选取非常重要。首先,时间片长度的选择会直接影响到系统的开销和响应时间。如果时间片长度过短,则调度程序抢占处理机的次数增多。这将使进程上下文切换次数也大大增加,从而加重系统开销。反过来,如果时间片长度选择过长,例如,一个时间片能保证就绪队列中所需执行时间最长的进程能执行完毕,则轮转法变成了先来先服务法。时间片长度的选择是根据系统对响应时间的要求和就绪队列中所允许最大的进程数来确定的。 在轮转法中,加入到就绪队列的进程有3种情况: 一种是分给它的时间片用完,但进程还未完成,回到就绪队列的末尾等待下次调度去继续执行。 另一种情况是分给该进程的时间片并未用完,只是因为请求I/O或由于进程的互斥与同步关系而被阻塞。当阻塞解除之后再回到就绪队列。 第三种情况就是新创建进程进入就绪队列。 如果对这些进程区别对待,给予不同的优先级和时间片从直观上看,可以进一步改善系统服务质量和效率。例如,我们可把就绪队列按照进程到达就绪队列的类型和进程被阻塞时的阻塞原因分成不同的就绪队列, 每个队列按FCFS原则排列,各队列之间的进程享有不同的优先级,但同一队列内优先级相同。这样,当一个进程在执行完它的时间片之后,或从睡眠中被唤醒以及被创建之后,将进入不同的就绪队列。
多级反馈队列1、设置 N 个就绪进程队列,即队列 0,队列 1,……,队列 N-1,用于存放就绪进程。每个队列 优先级不同,且从队列 0 到队列 N-1,优先级依次递减。 2、不同队列中的进程所赋予的时间片长度不同;优先级越低,时间片越长,比如,队列 0 中进程 的时间片为 5,队列 1 中进程的时间片为 10 等等。 3、在队列内部,进程之间采用先来先服务(FCFS)算法辅以时间片限时机制进行调度:位于队 列头部的进程(队首进程)先执行,如果在时间片限时内,它执行结束,则从本级队列移除;如 果它时间片内未能运行结束,则将它移入下一级队列末尾(若本级队列是最低优先级队列,则移 入本级队列末尾),然后按它当前所在新队列给它分配新的时间片。 4、当进程到达内存后,进入队列 0 末尾,并给它分配队列 0 规定的时间片。 5、优先执行高优先级队列中的队首进程,若高优先级队列中没有就绪进程,则执行下一级优先级 队列中的队首进程。 6、正在执行低优先级队列中的队首进程时,有新的进程到达高优先级队列,则立即中断低优先级 进程,并切换到高优先级进程执行。 https://blog.csdn.net/shenya1314/article/details/59077826
优点:
为提高系统吞吐量和缩短平均周转时间而照顾短进程。
为获得较好的I/O设备利用率和缩短响应时间而照顾I/O型进程。
不必估计进程的执行时间,动态调节
3.进程的并行与并发
并行:并行是指两者同时执行,比如赛跑,两个人都在不停的往前跑;(资源够用,比如三个线程,四核的CPU ) 并发:并发是指资源有限的情况下,两者交替轮流使用资源,比如一段路(单核CPU资源)同时只能过一个人,A走一段后,让给B,B用完继续给A ,交替使用,目的是提高效率。 区别: 并行是从微观上,也就是在一个精确的时间片刻,有不同的程序在执行,这就要求必须有多个处理器。 并发是从宏观上,在一个时间段上可以看出是同时执行的,比如一个服务器同时处理多个session。
并发和并行
并发 : 多个程序在一个cpu上交替运行
并行 : 在多个cpu上同时有多个程序在
阻塞和非阻塞
指CPU是否在工作
在工作 :非阻塞
不在工作 :阻塞
同步和异步
调一个任务,需要等待这个任务执行完并返回结果,现在的代码才能继续
调一个任务,不关心这个任务是否执行是否完毕,只负责调用,余下的内容和我当前的代码时各自执行的
多个进程之间的数据互相隔离
pid能够在操作系统中唯一标识一个进程
4.进程的5种状态
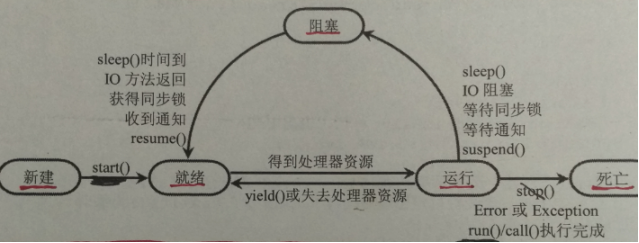
线程从创建、运行到结束总是处于下面五个状态之一:新建状态、就绪状态、运行状态、阻塞状态及死亡状态。
1.新建状态(New):
当用new操作符创建一个线程时, 例如new Thread(r),线程还没有开始运行,此时线程处在新建状态。 当一个线程处于新生状态时,程序还没有开始运行线程中的代码
2.就绪状态(Runnable)
一个新创建的线程并不自动开始运行,要执行线程,必须调用线程的start()方法。当线程对象调用start()方法即启动了线程,start()方法创建线程运行的系统资源,并调度线程运行run()方法。当start()方法返回后,线程就处于就绪状态。
处于就绪状态的线程并不一定立即运行run()方法,线程还必须同其他线程竞争CPU时间,只有获得CPU时间才可以运行线程。因为在单CPU的计算机系统中,不可能同时运行多个线程,一个时刻仅有一个线程处于运行状态。因此此时可能有多个线程处于就绪状态。对多个处于就绪状态的线程是由Java运行时系统的线程调度程序(thread scheduler)来调度的。
3.运行状态(Running)
当线程获得CPU时间后,它才进入运行状态,真正开始执行run()方法.
4. 阻塞状态(Blocked)
线程运行过程中,可能由于各种原因进入阻塞状态:
1>线程通过调用sleep方法进入睡眠状态;
2>线程调用一个在I/O上被阻塞的操作,即该操作在输入输出操作完成之前不会返回到它的调用者;
3>线程试图得到一个锁,而该锁正被其他线程持有;
4>线程在等待某个触发条件;
......
所谓阻塞状态是正在运行的线程没有运行结束,暂时让出CPU,这时其他处于就绪状态的线程就可以获得CPU时间,进入运行状态。
5. 死亡状态(Dead)
有两个原因会导致线程死亡:
1) run方法正常退出而自然死亡,
2) 一个未捕获的异常终止了run方法而使线程猝死。
为了确定线程在当前是否存活着(就是要么是可运行的,要么是被阻塞了),需要使用isAlive方法。如果是可运行或被阻塞,这个方法返回true; 如果线程仍旧是new状态且不是可运行的, 或者线程死亡了,则返回false.
进程三种状态间的转换
一个进程在运行期间,不断地从一种状态转换到另一种状态,它可以多次处于就绪状态和执行状态,也可以多次处于阻塞状态。
A. 就绪—>执行
处于就绪状态的进程,当进程调度程序为之分配好了处理机后,该进程便由就绪状态转换为执行状态;
B. 执行—>就绪
处于执行状态的进程在其执行过程中,因分配给它的一个时间片已经用完而不得不让出处理机,于是进程从执行状态转换为就绪状态;
C. 执行—>阻塞
正在执行的进程因等待某种事件发生而无法继续执行时,便从执行状态变成阻塞状态;
D. 阻塞—>就绪
处于阻塞状态的进程,若其等待的事件已经发生,于是进程便从阻塞状态转变为就绪状态。
进程五种状态详解
5. python中进程操作
运行中的程序就是一个进程。所有的进程都是通过它的父进程来创建的。因此,运行起来的python程序也是一个进程,那么我们也可以在程序中再创建进程。多个进程可以实现并发效果,也就是说,当我们的程序中存在多个进程的时候,在某些时候,就会让程序的执行速度变快。 multiprocess包: multiple:多功能的,包含了几乎所有和进程有关的子模 主要分为:创建进程部分,进程同步部分,进程持同步部分,进程之间数据共享
5.1 process模块介绍
Python中的multiprocess多进程包提供了Process类,实现进程相关的功能。但是它基于fork机制,因此不被windows平台支持。想要在windows中运行,必须使用if __name__ == '__main__:的方式,显然这只能用于调试和学习,不能用于实际环境。另外,在multiprocess中你既可以import大写的Process,也可以import小写的process,这两者是完全不同的东西。这种情况在Python中很多,请一定要小心和注意。
Process([group [, target [, name [, args [, kwargs]]]]]),由该类实例化得到的对象,表示一个子进程中的任务(尚未启动)
强调:
1. 需要使用关键字的方式来指定参数
2. args指定的为传给target函数的位置参数,是一个元组形式,必须有逗号
参数介绍:
1 group参数未使用,值始终为None
2 target表示调用对象,即子进程要执行的任务
3 args表示调用对象的位置参数元组,args=(1,2,'egon',)
4 kwargs表示调用对象的字典,kwargs={'name':'egon','age':18}
5 name为子进程的名称
1 p.daemon:默认值为False,如果设为True,代表p为后台运行的守护进程,当p的父进程终止时,p也随之终止,并且设定为True后,p不能创建自己的新进程,必须在p.start()之前设置 2 p.name:进程的名称 3 p.pid:进程的pid 4 p.exitcode:进程在运行时为None、如果为–N,表示被信号N结束(了解即可) 5 p.authkey:进程的身份验证键,默认是由os.urandom()随机生成的32字符的字符串。这个键的用途是为涉及网络连接的底层进程间通信提供安全性,这类连接只有在具有相同的身份验证键时才能成功(了解即可)
属性介绍
在Windows操作系统中由于没有fork(linux操作系统中创建进程的机制),在创建子进程的时候会自动 import 启动它的这个文件,而在 import 的时候又执行了整个文件。因此如果将process()直接写在文件中就会无限递归创建子进程报错。所以必须把创建子进程的部分使用if __name__ ==‘__main__’ 判断保护起来,import 的时候 ,就不会递归运行了。
在weindows中使用process模块的注意事项
p.start():启动进程,并调用该子进程中的p.run() #异步非阻塞 p.run():进程启动时运行的方法,正是它去调用target指定的函数,我们自定义类的类中一定要实现该方法 p.terminate():强制终止进程p,不会进行任何清理操作,如果p创建了子进程,该子进程就成了僵尸进程,使用该方法需要特别小心这种情况。如果p还保存了一个锁那么也将不会被释放,进而导致死锁 异步非阻塞 p.is_alive():如果p仍然运行,返回True p.join([timeout]):主线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态)。timeout是可选的超时时间,需要强调的是,p.join只能join住start开启的进程,而不能join住run开启的进程 同步阻塞 方法介绍
方法介绍
5.2创建子进程并实现并发效果
import time
import os
from multiprocessing import Process
def func ():
time.sleep(1)
print(1,os.getpid(),os.getppid())
if __name__ == '__main__':
#异步执行func,在一秒钟的时间通过生成多个子进程来执行多个func
#1.先实例化
#2.实例化对象.start()
# 目标函数:target=
Process(target=func).start() #process类通知操作系统要为当前代码快在开辟一个进程,是异步过程
第一种方式
import time
from multiprocessing import Process
class Myprocess(Process): #继承Process类
def __init__(self,name): #重新父类的__init__方法
super().__init__()
self.name =name
def run(self): #必须是run函数名
print(os.getpid(),os.getppid(),'我爱你%s' % self.name)
time.sleep(3)
if __name__ == '__main__':
start_time = time.time()
p1 = Myprocess('kobe')
p2 = Myprocess('kobe')
p3 = Myprocess('kobe')
p1.start()
p2.start()
p3.start()
p1.join() #阻塞,直到p1对应的进程结束之后,才结束阻塞,是异步阻塞,阻塞等待一个子进程结束
p2.join()
p3.join()
print(time.time()-start_time)
##阻塞一个子进程:p.join()
#阻塞多个子进程,将子进程加入到列表,然后分别阻塞
'''
10600 9384 我爱你kobe
10448 9384 我爱你kobe
10032 9384 我爱你kobe
1.1659998893737793
从上面结果来看,我们知道join也是异步阻塞的,在同一秒钟分别执行了p1,p2,p3的time.sleep()
和我本来预想的要阻塞3s+是结果是不同的
'''
继承Process类创建多进程
join方法:
p.join()阻塞,直到p对应的进程结束之后,才结束阻塞,阻塞等待一个子进程结束,在同步阻塞子进程的时候,只关心子进程是否执行完毕,执行完毕之后,在执行join后面的代码join方法是Process模块提供管理子进程的方法
守护进程daemon在主进程代码全部执行完毕之后在退出,一定要是设置在start之前,设置子进程为守护进程p.start() #执行一个子进程 异步非阻塞p.terminate #关闭一个子进程 异步非阻塞
import time
import random
from multiprocessing import Process
def send_mail(name):
time.sleep(random.uniform(1,3))
print('已经给%s发送邮件完毕'%name)
if __name__ == '__main__':
lst = ['kobe','jordan','admin','t-mac']
#阻塞等待一个子进程结束
p = Process(target=send_mail, args=('alex',))
p.start()
p.join() # 阻塞,直到p对应的进程结束之后才结束阻塞
print('所有的信息都发送完毕了')
#阻塞多个子进程,将子进程加入到列表,然后分别阻塞
p_l = []
for name in lst:
p = Process(target=send_mail,args=(name,)) #args必须是元组类型
p.start()
# p.join() #这种就是同步阻塞
p_l.append(p)
for p in p_l : p.join() #异步阻塞
print('所有的信息都发送完毕了')
join实例
5.3 守护进程
进程负责拿资源,线程负责执行任务守护进程定义: 守护进程(daemon)是一类在后台运行的特殊进程,用于执行特定的系统任务。很多守护进程在系统引导的时候启动,并且一直运行直到系统关闭。另一些只在需要的时候才启动,完成任务后就自动结束守护进程是可以一直运行而不阻塞主程序退出。要标志一个守护进程,可以将Process实例的daemon属性设置为True。守护进程最大的特点是:子进程执行的过程中和主进程无关 守护进程daemon在主进程代码全部执行完毕之后在退出,一点要在start()方法之前设置守护进程
#守护进程 #主进程结束 守护进程也结束 然后子进程结束
import time
from multiprocessing import Process
def func():
while True:
# for i in range(20):
time.sleep(0.5)
print('in func')
def func2():
print('start: func2')
time.sleep(5)
print('end: func2')
if __name__ == '__main__':
p = Process(target=func)
p.daemon = True #表示设置p为一个守护进程
p.start() #结束主代码,结束 不管子进程
p2 = Process(target=func2)
p2.start()
print('in main')
time.sleep(3)
print('finished')
# p.join() # 这样可以 子进程 。阻塞在这 可以等到子进程也结束
#为什么主进程要等待子进程结束之后再结束那?
#守护进程首先是子进程,守护的是主进程
#因为主进程要负责给子进程回收一些系统资源
#p.daemon= True
#p.start()
#守护进程的结束条件是主进程的代码全部结束之后再结束子进程,而不是等待主进程结束全部,因为主进程也要给守护进程回收资源
#将所有的进程都join住,守护进程就能在所有的子进程执行完毕之后再退出
守护进程实例
5.4 锁
同一时刻同一段代码只能有一个进程来执行这段代码,当子进程执行异步操作同一个文件/数据库的时候,会产生不安全的现象,我们应该使用锁来避免多个进程同时修改一个文件我们应该避免在多进程时修改文件,多进程中只有去操作一些共享数据资源的时候,才需要加锁 互斥锁:在同一个进程内,也有锁的竞争,连续的acquire多次会产生死锁
import json
import time
from multiprocessing import Process,Lock
def search_ticket(name):
with open('ticket',encoding='utf-8') as f:
dic = json.load(f)
print('%s查询余票为%s'%(name,dic['count']))
def buy_ticket(name):
with open('ticket',encoding='utf-8') as f:
dic = json.load(f)
time.sleep(2)
if dic['count'] >= 1:
print('%s买到票了'%name)
dic['count'] -= 1
time.sleep(2)
with open('ticket', mode='w',encoding='utf-8') as f:
json.dump(dic,f)
else:
print('余票为0,%s没买到票' % name)
def use(name,lock):
search_ticket(name)
print('%s在等待'%name)
# lock.acquire() #得到锁
# print('%s开始执行了'%name)
# buy_ticket(name)
# lock.release() #将锁归还
with lock: #lock的with上下文管理,,lock是互斥锁,其中Lock()方法里面包含acquire()方法和release()方法,使用装饰器也能完成此功能!
print('%s开始执行了'%name)
buy_ticket(name)
if __name__ == '__main__':
lock = Lock()
l = ['admin','kebi','and0ne','jordan']
for name in l:
Process(target=use,args=(name,lock)).start()
锁示例
5.5 队列
多个进程之间通信是否可以进行通信?
多个进程之间通信ipc inter process communication (多个进程之间的数据是隔离的) python中进程间通信可以通过一下方法: 通过python模块: 基于socket, 基于进程队列Queue 基于管道 注意:队列和管道只适用于多个进程都是源于同一个父进程 通过文件 通过第三方工具:基于网络 mamcache redis rabbitMQ kafka等消息队列(消息中间件)
from multiprocessing import Queue, Process #导入队列模块和多进程模块
def son(q):
print(q.get()) #用户接受一个数据
if __name__ == '__main__':
q = Queue() #实例化一个队列对象
print(q)
Process(target=son, args=(q,)).start()
q.put('wahaha') #队列存入一个数据
简单的队列
通过简单的队列示例,能从中提现到生产者和消费者的模型
生产者生产数据,交给消费者取处理数据
在使用生产者和消费者模型的时候要注意:
1.解耦合
2.调节生产者和消费者的个数来让程序的效率达到最平衡和最大化(生产和消费在同一时间内基本相等)
3.不要出现供大于求或者求小于供的情况
在并发编程中使用生产者和消费者模式能够解决绝大多数并发问题。该模式通过平衡生产线程和消费线程的工作能力来提高程序的整体处理数据的速度。
为什么要使用生产者和消费者模式
在线程世界里,生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发当中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样 的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这个问题于是引入了生产者和消费者模式。
什么是生产者消费者模式
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列, 消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
import time
import random
from multiprocessing import Process,Queue
def producer(q): #生产者
for i in range(10):
time.sleep(random.random()) #用来模拟爬虫子在爬取资料的时间
food = '泔水%s'%i
print('%s生产了%s'%('taibai',food))
q.put(food) #将资料加入队列里面,以后会加入到redis或者rbMQ里面做分布式
def consumer(q,name): #消费者
while True:
food = q.get() # food = 食物/None
if not food : break #判断时候为空,为空说明队列已经没数据了,就退出
time.sleep(random.uniform(1,2)) #模拟客户端出来数据的时间
print('%s 吃了 %s'%(name,food)) #模拟出来好的数据展示,以后可能存入数据库
if __name__ == '__main__':
q = Queue() #创建一个队列
p1 = Process(target=producer,args=(q,)) #创建一个生产者对象
p1.start()
c1 = Process(target=consumer,args=(q,'kobe')) #创建消费者对象p1
c1.start()
c2 = Process(target=consumer,args=(q,'admin')) #创建消费者对象p2
c2.start()
c3 = Process(target=consumer,args=(q,'james')) #创建消费者对象p3
c3.start()
p1.join()
#将p1 join住,如果p1对象执行完毕,说明生产者数据已经生产完毕,在等待消费者消费,并且生产者应该发送一个结束信号none
# 如果不加p1.join()和不发送None信号,此时的问题是主进程永远不会结束,原因是:生产者p在生产完后就结束了,但是消费者c在取空了q之后,
# 则一直处于死循环中且卡在q.get()这一步。
# 解决方式无非是让生产者在生产完毕后,往队列中再发一个结束信号,这样消费者在接收到结束信号后就可以break出死循环。
#比较笨的方法是有几个消费者对象就要发几个None
q.put(None)
q.put(None)
q.put(None)
生产者和消费者模型
生产者和消费者模型
生产者和消费者模型主要做了什么?
生产者和消费者模型:基于队列把生产数据和消费数据的过程分开了
队列:是进程安全的恶,队列里面有自带锁,
队列是基于什么实现的?
是基于文件家族的socket服务实现+锁
基于文件家族的socket服务实现的ipc机制不止队列一个:还有管道pipe,但是没有锁
队列 = 管道 +锁
管道 = 是基于文件家族的socket服务实现的
注意:
from queue import Queue #不能完成进程间通信的队列 from multiprocessing import Queue #可以完成进程之间通信的特殊队列
5.6 JoinableQueue([maxsize])
创建可连接的共享进程队列。这就像是一个Queue对象,但队列允许项目的使用者通知生产者项目已经被成功处理(None)。通知进程是使用共享的信号和条件变量来实现的。
#也是多进程并发的实现
import time
import random
from multiprocessing import JoinableQueue,Process
def consumer(jq,name):
while True:
food = jq.get()
time.sleep(random.uniform(1,2))
print('%s 吃完了 %s'%(name,food))
jq.task_done() #通知producer里面的jq.join(),要将队列里面的计数器-1,因为有一个数据被取走了,当所有的任务处理完之后,队列的计数器为0
#当生产者的队列为空时,while True会hold住,等待队列中进入数据,再次读取!
#怎么来退出此子进程那?,通过守护进程
def producer(jq):
for item in range(10):
time.sleep(random.random())
food = '香肠%s'%item
print('%s生产了 %s'%('jordan',food))
jq.put(food)
jq.join() # 队列的join结束,说明队列里面的数据已经被消费者消费完了,producer函数运行完毕,不在继续生产了,
# 当jq.join()结束之后,说明下面阻塞的p1.join()也结束了,因为p1.join()在等待子进程执行完毕
if __name__ == '__main__':
jq = JoinableQueue() #实例化对象
c1 = Process(target=consumer,args=(jq,'kobe'))
c2 = Process(target=consumer,args=(jq,'admin'))
p1 = Process(target=producer,args=(jq,))
c1.daemon = True #将c1设置成守护进程,在主进程的全部代码都执行完之后,才关闭
c2.daemon = True #将c2设置成守护进程,在主进程的全部代码都执行完之后,才关闭
c1.start()
c2.start()
p1.start()
p1.join() #p1的进程阻塞结束之后,c1的守护进程就结束了,
# 因为执行到主程序代码的最后了,所以守护进程c1,c2都在主进程代码执行结束之后就退出了
#所以当守护进程退出时候,while True退出!
#c1.daemon= True #将consumer设置成守护进程,在主进程的全部代码都执行完之后,才关闭
#jq.task_donw()通知producer,要将队列里面的计数器-1,当所有的任务处理完之后,队列的计数器为0
#jq.join() 队列的join结束,producer函数运行完毕
#p1.join() p1的进程阻塞结束之后,c1的守护进程就结束了
基于JoinableQueue的生产者消费者模型
JoinableQueue的实例p除了与Queue对象相同的方法之外,还具有以下方法: q.task_done() 使用者使用此方法发出信号,表示q.get()返回的项目已经被处理。如果调用此方法的次数大于从队列中删除的项目数量,将引发ValueError异常。 q.join() 生产者将使用此方法进行阻塞,直到队列中所有项目均被处理。阻塞将持续到为队列中的每个项目均调用q.task_done()方法为止。 下面的例子说明如何建立永远运行的进程,使用和处理队列上的项目。生产者将项目放入队列,并等待它们被处理
方法介绍
5.7 进程间的通信
队列 管道 Manager Lock() Process#以上在底层都会有进程间通信的机制,与其他不同的是,队列是能发任意的消息
5.8 进程池
使用进程池 :控制进程的数量,节省资源开销,不用每次创建 用有限的进程执行无限的任务,多个被开启的进程重复利用,节省的是开启\销毁\多个进程切换的时间
import os
import time
from concurrent.futures import ProcessPoolExecutor
def make(i):
time.sleep(1)
print('%s 制作螺丝%s'%(os.getpid(),i))
return i**2
if __name__ == '__main__':
p = ProcessPoolExecutor(4) # 创建一个进程池
for i in range(100):
p.submit(make,i) # 向进程池中提交任务,submit返回值是一个Future对象!使用result从中取值!
p.shutdown() # 阻塞 直到池中的任务都完成为止
print('所有的螺丝都制作完了')
p.map(make,range(100)) # submit的简便用法
创建进程池
import os
import time
from concurrent.futures import ProcessPoolExecutor
def make(i):
time.sleep(1)
print('%s 制作螺丝%s'%(os.getpid(),i))
return i**2
if __name__ == '__main__':
p = ProcessPoolExecutor(4) # 创建一个进程池
ret = p.map(make, range(100)) #是for循环的简便写法,一般只用于传递一个参数
#ret=返回的是返回的是生成器,再循环就可以了
for i in ret:
print(i)
#为什么ret返回的是一个对象?
# 如果返回一个结果,就要在返回结果的时候阻塞了
创建进程池二版本
other
if __name__=='__main__':详解
if __name__ == '__main__':主要作用就是查看文件的运行方式
在python中,每个文件a.py(模块)都包含内置的变量__name__
1.作为脚本直接执行
a.py的__name__默认等于__main__,也就是此时文件的名字a.py,此时if __name__ == '__main__'下的所有代码都会执行
2.当被inport其他文件中时
a.py的__name__等于这个这个文件的名字a,不包含.py后缀,此时if __name__ == '__main__'下的代码不会执行
windows创建多线程
需要注意的是windows创建多线程和linux上是不同的。
windows上子进程启动的时候会自动的import启动其文件。如果不加上if __name__ == '__main__':的话,子进程会无限循环的import
所以必须使用if __name__ == '__main__'将子进程启动保护起来,当import的时候,第一次的__name__=='__mian__'中的name是等于
__main__也就是等于import的文件的名字(包含)后缀,当inport之后,__name__就等于文件的名字(不包含后缀),所以只是执行一次
Linux创建进程
https://blog.csdn.net/wujiafei_njgcxy/article/details/77116175
def func():
pass
from multiprocessing import Process
if __name__ == '__main__': #主要用来区分脚本的运行方式
c = Process(target=func).start()
a = 1
print(__name__)
print(a)
通过运行上述代码,会得到 name a not defined ,并且会打印1
因为在执行的时候子进程会import 这个文件到其自己的内存空间,当执行到if __name__ == '__main__':的时候会得出
__name__ 等于的是import的名字,并不等于__main__
所以不会执行 if语句,但是后面有一个peint(a),a没有被定义在子进程的内存空间里面,所以会爆a未定义
那个1又是谁打印的那?肯定是父进程打印的,当父进程创建子进程并运行子进程之后,会继续向下执行,a = 1,所以会打印1
不同进程间进行通讯(数据共享)
import time
from multiprocessing import Process,Manager
def func(dic):
dic ['count'] -=1
if __name__ == '__main__':
m = Manager()
dic = m.dict({'count':100})
p_list =[]
for i in range(100):
p = Process(target=func,args=(dic,))
p.start()
p_list.append(p)
for p in p_list:
p.join()
print(dic)
普通版本
from multiprocessing import Process,Manager,Lock
def func(dic,lock):
with lock:
dic ['count'] -=1
if __name__ == '__main__':
m = Manager()
lock = Lock()
dic = m.dict({'count':100})
# dic =
p_list =[]
for i in range(100):
p = Process(target=func,args=(dic,lock))
p.start()
p_list.append(p)
for p in p_list:
p.join()
print(dic)
加锁版本
区别于队列和管道:
Manager能进行不同进程间的不基于同一父进程之间通讯
队列和管道:只适用于多进程都是基于同一父进程
在普通版本里面可能会出现{'count':3}或者{'count':2}的情况,就是出现了多个进程同一时间对同一个数值的数据进行修改。Manager类当中对 字典 列表 += -= *= /= 会产生不安全问题,解决的话,就是加锁来解决.
如果多个进程不是源于同一个父进程,只能用共享内存,信号量等方式,但是这些方式对于复杂的数据结构,例如Queue,dict,list等,使用起来比较麻烦,不够灵活。Manager是一种较为高级的多进程通信方式,它能支持Python支持的的任何数据结构。 那么进程间通讯都可能用到什么: # 队列 queue # 管道 # manager # lock # Process
python进阶之 进程编程的更多相关文章
- Python进阶:函数式编程实例(附代码)
Python进阶:函数式编程实例(附代码) 上篇文章"几个小例子告诉你, 一行Python代码能干哪些事 -- 知乎专栏"中用到了一些列表解析.生成器.map.filter.lam ...
- Python进阶之面向对象编程
面向对象编程——Object Oriented Programming,简称OOP,是一种程序设计思想.OOP把对象作为程序的基本单元,一个对象包含了数据和操作数据的函数. 面向过程的程序设计把计算机 ...
- Python进阶之函数式编程
函数式编程 函数是Python内建支持的一种封装,我们通过把大段代码拆成函数,通过一层一层的函数调用,就可以把复杂任务分解成简单的任务,这种分解可以称之为面向过程的程序设计.函数就是面向过程的程序设计 ...
- Python进阶之函数式编程(把函数作为参数)
什么是函数式编程? 什么是函数式编程? 函数:function 函数式:functional,一种编程范式 函数式编程是一种抽象计算的编程模式 函数≠函数式,比如:计算≠计算机 在计算机当中,计算机硬 ...
- python进阶之 网络编程
1.tcp和udp协议的区别 TCP协议 面向连接\可靠\慢\对传递的数据的长短没有要求 两台机器之间要想传递信息必须先建立连接 之后在有了连接的基础上,进行信息的传递 可靠 : 数据不会丢失 不会重 ...
- python进阶之 线程编程
1.进程回顾 之前已经了解了操作系统中进程的概念,程序并不能单独运行,只有将程序装载到内存中,系统为它分配资源才能运行,而这种执行的程序就称之为进程.程序和进程的区别就在于:程序是指令的集合,它是进程 ...
- Python进阶之面向对象编程(二)
Python面向对象编程(二) .note-content {font-family: "Helvetica Neue",Arial,"Hiragino Sans GB& ...
- Python进阶之面向对象编程概述
Python面向对象编程(一) .note-content {font-family: "Helvetica Neue",Arial,"Hiragino Sans GB& ...
- python进阶之 进程&线程区别
1.进程创建方式 import time import os from multiprocessing import Process def func (): time.sleep(1) print( ...
随机推荐
- Python之turtle画同心圆和棋盘
画饼图 import turtle t = turtle.Pen() for i in range(5): t.penup() t.goto(0, -i*30) t.pendown() t.circl ...
- 【温暖】文龙回AICODER给老马送锦旗了
又是一个愉快的周末,AICODER第一批老学员文龙小伙伴.已经工作两个月,而且就业薪资12000+,文龙从之前月薪不足4000,一下子翻了三倍多的工资. 几个月的实习,让文龙掌握了大前端全栈的技术,在 ...
- Postman 接口测试神器
Postman 接口测试神器 Postman 是一个接口测试和 http 请求的神器,非常好用. 官方 github 地址: https://github.com/postmanlabs Postma ...
- Word Embedding/RNN/LSTM
Word Embedding Word Embedding是一种词的向量表示,比如,对于这样的"A B A C B F G"的一个序列,也许我们最后能得到:A对应的向量为[0.1 ...
- 大数据:Hive - ORC 文件存储格式
一.ORC File文件结构 ORC的全称是(Optimized Row Columnar),ORC文件格式是一种Hadoop生态圈中的列式存储格式,它的产生早在2013年初,最初产生自Apache ...
- Modelsim使用常见问题集锦(实时更新)
1.Modelsim使用时出现闪退情况,解决办法:(1)请再次查看modelsim是否破解完全:(2)电脑上安装的文件与Modelsim有冲突,多半是爱奇艺这个软件,删掉爱奇艺软件. 2.再利用mod ...
- Netty:option和childOption参数设置说明
Channel配置参数 (1).通用参数 CONNECT_TIMEOUT_MILLIS : Netty参数,连接超时毫秒数,默认值30000毫秒即30秒. MAX_MESSAGES_PER_REA ...
- vue+node+mongodb前后端分离博客系统
感悟 历时两个多月,终于利用工作之余完成了这个项目的1.0版本,为什么要写这个项目?其实基于vuejs+nodejs构建的开源博客系统有很多,但是大多数不支持服务端渲染,也不支持动态标题,只是做到了前 ...
- dir 命令手册
dir 命令手册 参数 /A D 目录 R 只读文件 H 隐藏文件 A 准备存档的文件 S 系统文件 - 表示"否"的前缀 /B 使用空格式(没有标题信息或摘要) /C 在文件大小 ...
- css3 - 纯css实现一个轮播图
这是我上一次的面试题.一晃两个月过去了. 从前都是拿原理骗人,把怎么实现的思路说出来. 我今天又被人问到了,才想起来真正码出来.码出来效果说明一切: 以上gif,只用到了5张图片,一个html+css ...