spark 2.0.2 集群搭建
由于之前已经搭建过hadoop相关环境,现在搭建spark的预备工作只有scala环境了
一,配置scala环境
1.解压tar包后,编辑/etc/profile

2.source /etc/profile
3.scala -version

4.分发到其他两台机器上
二.搭建spark集群
1.配置spark环境变量

2.进入spark的conf目录下
cp -a spark-env.sh.template spark-env.sh
cp -a slaves.template slaves
3.修改spark-env.sh,这里依然指定master为hadoop002
export JAVA_HOME=/opt/module/jdk1.8.0_181
export SCALA_HOME=/opt/module/scala-2.10.1
export SPARK_MASTER_IP=192.168.101.102
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/opt/module/hadoop-2.7.7
4.修改slaves
hadoop003
hadoop004
5.分发到其他两台机器
6.启动集群
先启动zk,然后启动hdfs,yarn,最后来到spark目录下
执行sbin/start-all.sh启动spark
7.查看,虽然我们没有配置hadoop002为slaves,但显然此时它也是一个worker(下次重新启动时就只有Masrter节点就不会有worker进程了)
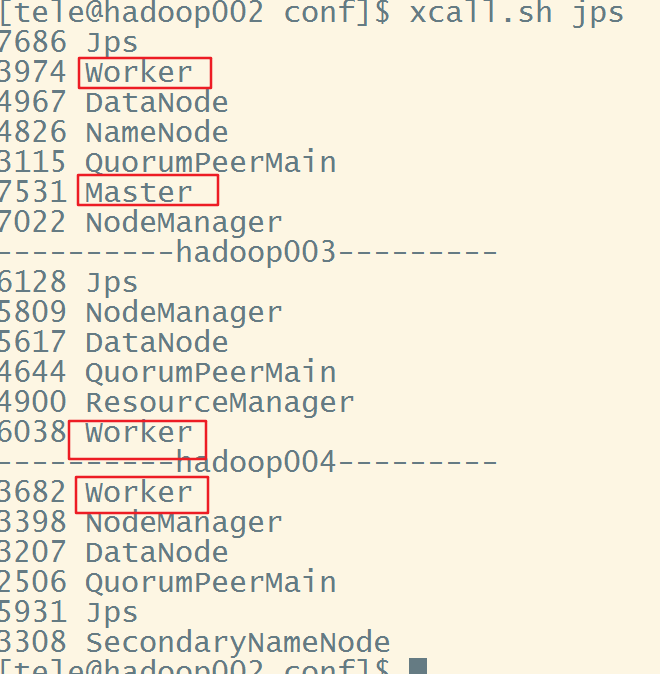
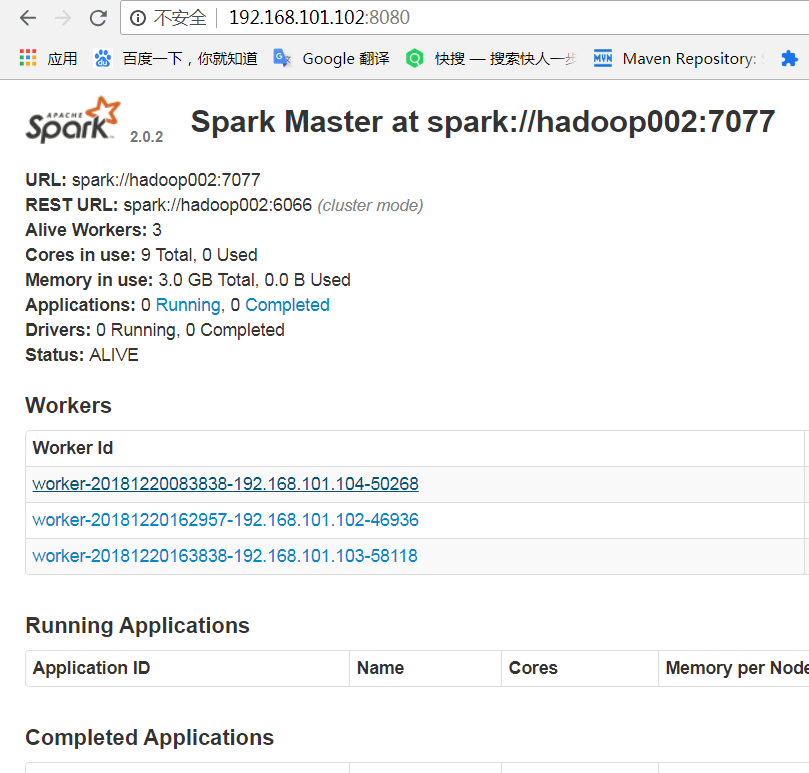
也可以打开8080端口,查看UI
8.停止时先在spark目录下sbin/stop-all.sh 然后停止yarn,再停止hdfs.最后zk
spark 2.0.2 集群搭建的更多相关文章
- 【原创 Hadoop&Spark 动手实践 5】Spark 基础入门,集群搭建以及Spark Shell
Spark 基础入门,集群搭建以及Spark Shell 主要借助Spark基础的PPT,再加上实际的动手操作来加强概念的理解和实践. Spark 安装部署 理论已经了解的差不多了,接下来是实际动手实 ...
- Redis 5.0.5集群搭建
Redis 5.0.5集群搭建 一.概述 Redis3.0版本之后支持Cluster. 1.1.redis cluster的现状 目前redis支持的cluster特性: 1):节点自动发现 2):s ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- CDH 6.0.1 集群搭建 「After install」
集群搭建完成之后其实还有很多配置工作要做,这里我列举一些我去做的一些. 首先是去把 zk 的角色重新分配一下,不知道是不是我在配置的时候遗漏了什么在启动之后就有报警说目前只能检查到一个节点.去将 zk ...
- CDH 6.0.1 集群搭建 「Before install」
从这一篇文章开始会有三篇文章依次介绍集群搭建 「Before install」 「Process」 「After install」 继上一篇使用 docker 部署单机 CDH 的文章,当我们使用 d ...
- HADOOP+SPARK+ZOOKEEPER+HBASE+HIVE集群搭建(转)
原文地址:https://www.cnblogs.com/hanzhi/articles/8794984.html 目录 引言 目录 一环境选择 1集群机器安装图 2配置说明 3下载地址 二集群的相关 ...
- java_redis3.0.3集群搭建
redis3.0版本之后支持Cluster,具体介绍redis集群我就不多说,了解请看redis中文简介. 首先,直接访问redis.io官网,下载redis.tar.gz,现在版本3.0.3,我下面 ...
- Redis 3.0.2集群搭建以及相关问题汇总
Redis3 正式支持了 cluster,是为了解决构建redis集群时的诸多不便 (1)像操作单个redis一样操作key,不用操心key在哪个节点上(2)在线动态添加.删除redis节点,不用停止 ...
- Hadoop2.0 HA集群搭建步骤
上一次搭建的Hadoop是一个伪分布式的,这次我们做一个用于个人的Hadoop集群(希望对大家搭建集群有所帮助): 集群节点分配: Park01 Zookeeper NameNode (active) ...
随机推荐
- 基于zookeeper实现的分布式锁
基于zookeeper实现的分布式锁 2011-01-27 • 技术 • 7 条评论 • jiacheo •14,941 阅读 A distributed lock base on zookeeper ...
- 为easyUI的dataGrid加入自己的查询框
dataGrid作为easyUI的一个核心组件,其功能上是非常强大的. 可是外观上似乎就有点差强人意了,首先说一下我对dataGrid外观的2点感受 1.图标不好看,且尺寸非常小(16x16)-- 关 ...
- 前端开发概述+JS基础细节知识点
一 前端开发概述 html页面:html css javascript 拿到UI设计图纸:切图-->html+css静态布局-->用JS写一写动态效果-->ajax和后台进行交互,把 ...
- (转)ORA-01940: cannot drop a user that is currently connected 问题解析
删除数据库用户的时候经常会遇到这样的错误: ORA: cannot drop a user that is currently connected 原因是有程序在连接我们需要删除的用户,我们删除用户之 ...
- 基于StringUtils工具类的常用方法介绍(必看篇)
前言:工作中看到项目组里的大牛写代码大量的用到了StringUtils工具类来做字符串的操作,便学习整理了一下,方便查阅. isEmpty(String str) 是否为空,空格字符为false is ...
- Android界面相关的类
Android界面相关的类 Window Activity的显示界面对象,并作为顶层View被加入到WindowManager中.Window提供了标准的UI显示策略:界面背景.标题区域.默认的事件处 ...
- JAVA一些基础概念
Java (计算机编程语言) Java是一门面向对象编程语言,不仅吸收了C++语言的各种长处,还摒弃了C++里难以理解的多继承.指针等概念.因此Java语言具有功能强大和简单易用两个特征. Java语 ...
- fdopen:让文件描述符像文件一样使用
FILE * fdopen(int fildes,const char * mode); fdopen与fopen类似,返回一个FILE *类型的值,不同的是此函数以文件描述符而非文件作为参数. 如果 ...
- 【AtCoder ABC 075 C】Bridge
[链接] 我是链接,点我呀:) [题意] 让你求出桥的个数 [题解] 删掉这条边,然后看看1能不能到达其他所有的点就可以了 [代码] #include <bits/stdc++.h> us ...
- Spring-Boot整合freemarker引入静态资源css、js等(转)
一.概述 springboot 默认静态资源访问的路径为:/static 或 /public 或 /resources 或 /META-INF/resources 这样的地址都必须定义在src/mai ...