爬虫—分析Ajax爬取今日头条图片
以今日头条为例分析Ajax请求抓取网页数据。本次抓取今日头条的街拍关键字对应的图片,并保存到本地
一,分析
打开今日头条主页,在搜索框中输入街拍二字,打开开发者工具,发现浏览器显示的数据不在其源码里面。这样可以出初步判断这些内容是由
Ajax加载,然后使用JavaScript渲染出来的。
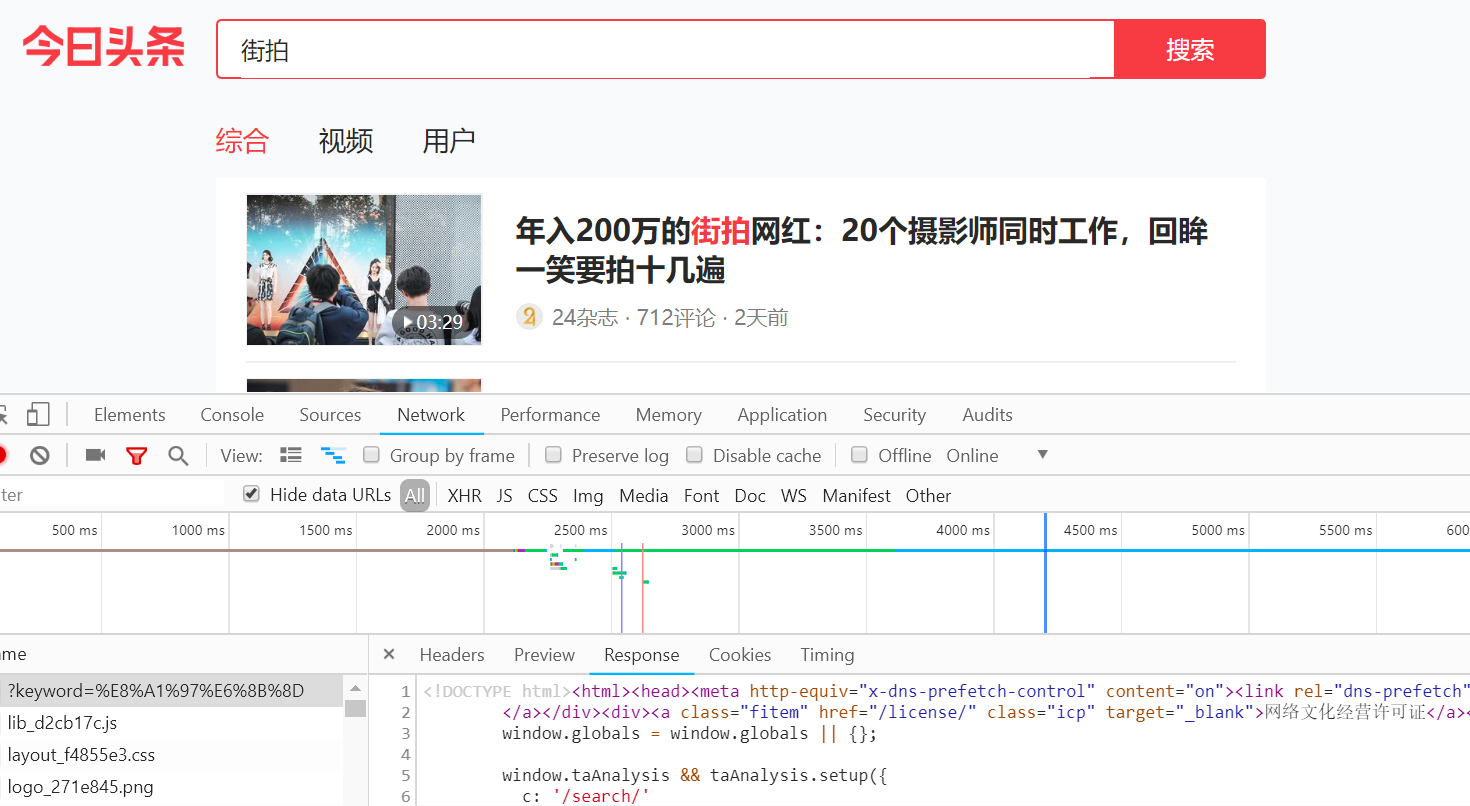
切换到XHR过滤选项卡,查看其Ajax请求。点击其中一条进去,进入data展开,发现其中一个title字段对应的值正好是页面中的某条数据的标题。再查看其他数据,正好也是一一对应的,这说明这些数据确实是由Ajax加载的。
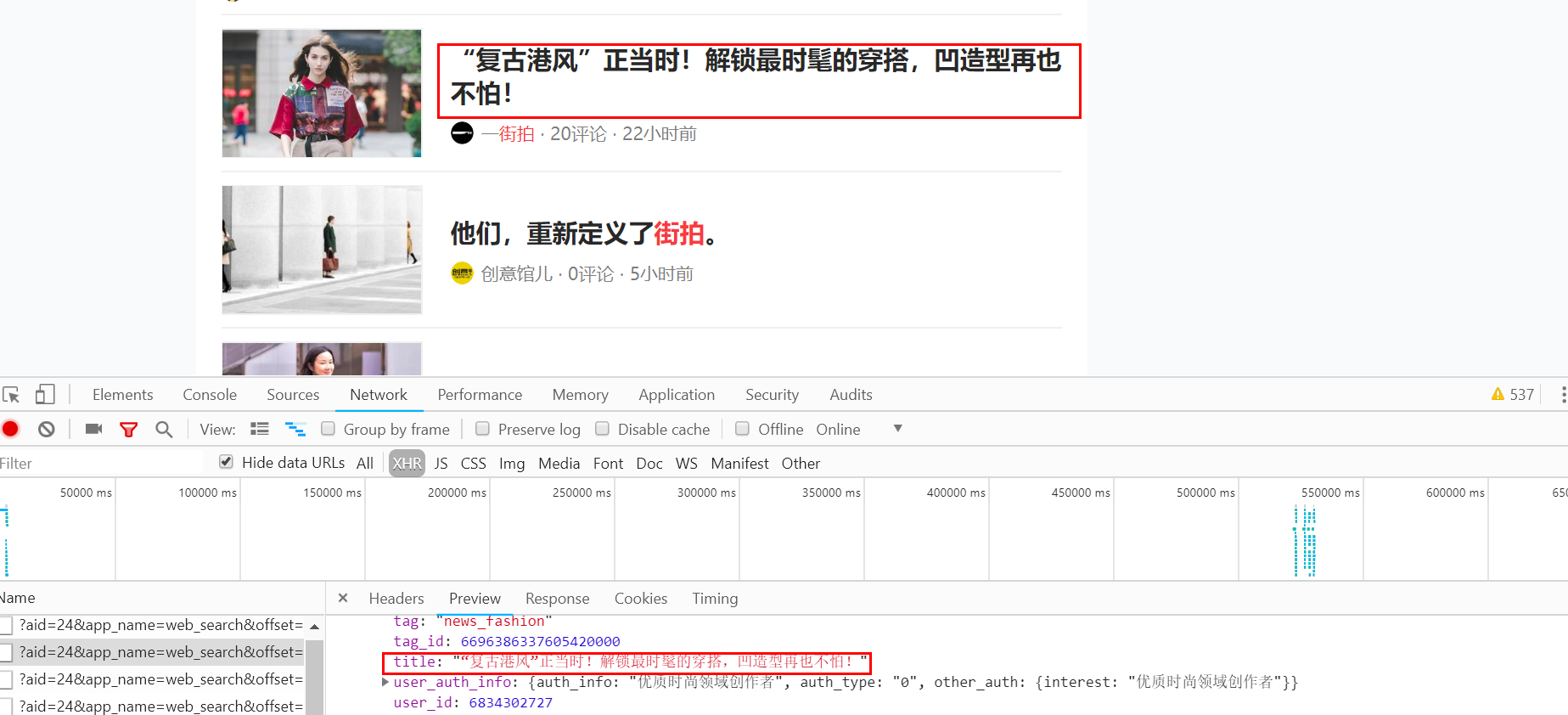
本次的目的是抓取其中的图片内容,data中每个元素就是一篇文章,元素中的image_list字段包含了该文章的图片内容。它是一个列表形式,包含了所有的图片列表。我们只需要将列表中的url字段下载下来就好了,每篇文章都创建一个文件夹,文件夹名称即文章标题。

在使用Python爬取之前还需要分析一下URL的规律。切换到Headers选项卡,查看Headers信息。可以看到,这是一个GET请求,请求的参数有aid,app_name,offset,format,keyword,autoload,count,en_qc,cur_tab,from,pd,timestamp。继续往下滑动,多加载一些数据,找出其中的规律。
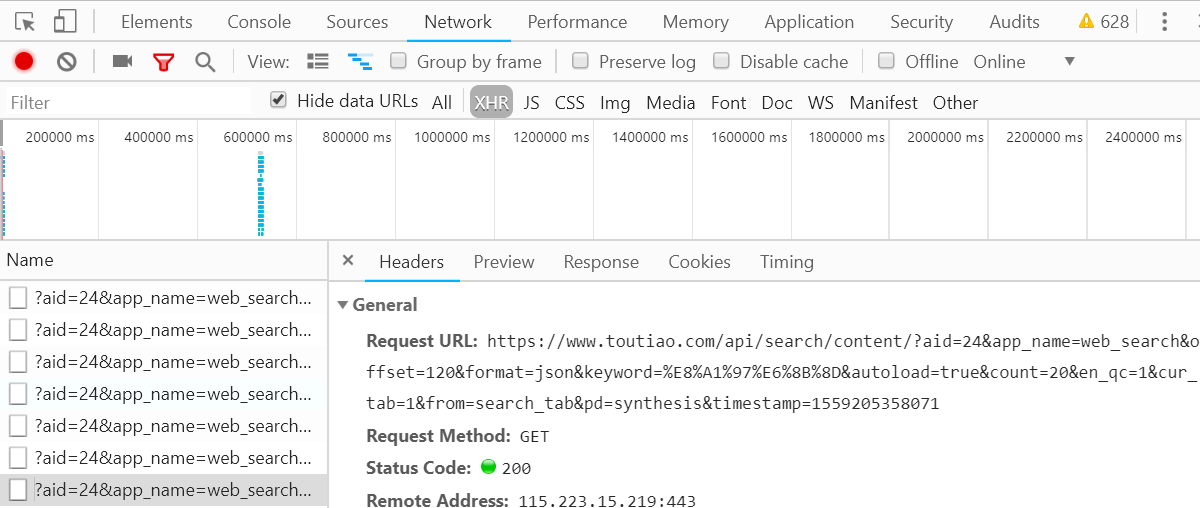
经过观察,可以发现变化的参数只有offset,timestamp。第一次请求的offset的值为0,第二次为20,第三次为40,key推断出这个offset就是偏移量,count为每次请求的数据量,而timestamp为时间戳。这样一来,我们就可以使用offset参数控制分页了,通过模拟Ajax请求获取数据,最后将数据解析后下载即可。
二,爬取
刚才已经分析完了整个Ajax请求,接下来就是使用代码来实现这个过程。
# _*_ coding=utf-8 _*_ import requests
import time
import os
from hashlib import md5
from urllib.parse import urlencode
from multiprocessing.pool import Pool def get_data(offset):
"""
构造URL,发送请求
:param offset:
:return:
"""
timestamp = int(time.time())
params = {
'aid': '',
'app_name': 'web_search',
'offset': offset,
'format': 'json',
'autoload': 'true',
'count': '',
'en_qc': '',
'cur_tab': '',
'from': 'search_tab',
'pd': 'synthesis',
'timestamp': timestamp
} base_url = 'https://www.toutiao.com/api/search/content/?keyword=%E8%A1%97%E6%8B%8D'
url = base_url + urlencode(params)
try:
res = requests.get(url)
if res.status_code == 200:
return res.json()
except requests.ConnectionError:
return '555...' def get_img(data):
"""
提取每一张图片连接,与标题一并返回,构造生成器
:param data:
:return:
"""
if data.get('data'):
page_data = data.get('data')
for item in page_data:
# cell_type字段不存在的这类文章不爬取,它没有title,和image_list字段,会出错
if item.get('cell_type') is not None:
continue
title = item.get('title').replace(' |', ' ') # 去掉某些可能导致文件名错误而不能创建文件的特殊符号,根据具体情况而定
imgs = item.get('image_list')
for img in imgs:
yield {
'title': title,
'img': img.get('url')
} def save(item):
"""
根据title创建文件夹,将图片以二进制形式写入,
图片名称使用其内容的md5值,可以去除重复的图片
:param item:
:return:
"""
img_path = 'img' + '/' + item.get('title')
if not os.path.exists(img_path):
os.makedirs(img_path)
try:
res = requests.get(item.get('img'))
if res.status_code == 200:
file_path = img_path + '/' + '{name}.{suffix}'.format(
name=md5(res.content).hexdigest(),
suffix='jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(res.content)
print('Successful')
else:
print('Already Download')
except requests.ConnectionError:
print('Failed to save images') def main(offset):
data = get_data(offset)
for item in get_img(data):
print(item)
save(item) START = 0
END = 10
if __name__ == "__main__":
pool = Pool()
offsets = ([n * 20 for n in range(START, END + 1)])
pool.map(main, offsets)
pool.close()
pool.join()
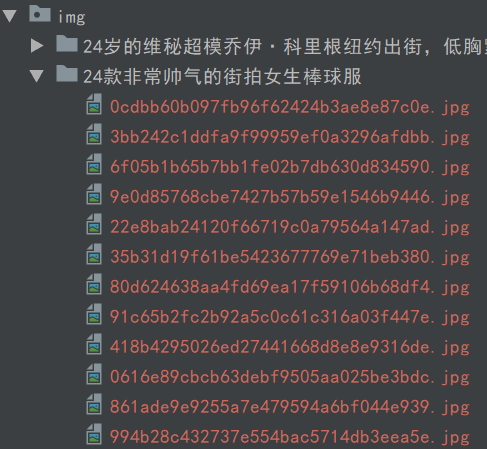
这里定义了起始页START和结束页END,可以自定义设置。然后利用多进程的进程池,调用map()方法实现多进程下载。运行之后发现图片都报存下来了。
爬虫—分析Ajax爬取今日头条图片的更多相关文章
- 【Python3网络爬虫开发实战】 分析Ajax爬取今日头条街拍美图
前言本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理.作者:haoxuan10 本节中,我们以今日头条为例来尝试通过分析Ajax请求 ...
- 分析Ajax爬取今日头条街拍美图-崔庆才思路
站点分析 源码及遇到的问题 代码结构 方法定义 需要的常量 关于在代码中遇到的问题 01. 数据库连接 02.今日头条的反爬虫机制 03. json解码遇到的问题 04. 关于response.tex ...
- 用Ajax爬取今日头条图片集
Ajax原理 在用requests抓取页面时,得到的结果可能和浏览器中看到的不一样:在浏览器中可以正常显示的页面数据,但用requests得到的结果并没有.这是因为requests获取的都是原始 ...
- 【Python3网络爬虫开发实战】6.4-分析Ajax爬取今日头条街拍美图【华为云技术分享】
[摘要] 本节中,我们以今日头条为例来尝试通过分析Ajax请求来抓取网页数据的方法.这次要抓取的目标是今日头条的街拍美图,抓取完成之后,将每组图片分文件夹下载到本地并保存下来. 1. 准备工作 在本节 ...
- 转:【Python3网络爬虫开发实战】6.4-分析Ajax爬取今日头条街拍美图
[摘要] 本节中,我们以今日头条为例来尝试通过分析Ajax请求来抓取网页数据的方法.这次要抓取的目标是今日头条的街拍美图,抓取完成之后,将每组图片分文件夹下载到本地并保存下来. 1. 准备工作 在本节 ...
- 分析AJAX抓取今日头条的街拍美图并把信息存入mongodb中
今天学习分析ajax 请求,现把学得记录, 把我们在今日头条搜索街拍美图的时候,今日头条会发起ajax请求去请求图片,所以我们在网页源码中不能找到图片的url,但是今日头条网页中有一个json 文件, ...
- 关于爬虫的日常复习(9)—— 实战:分析Ajax抓取今日头条接拍美图
- 分析Ajax抓取今日头条街拍美图
spider.py # -*- coding:utf-8 -*- from urllib import urlencode import requests from requests.exceptio ...
- python爬取今日头条图片
import requests from urllib.parse import urlencode from requests import codes import os # qianxiao99 ...
随机推荐
- 【Oracle】redo与undo
一 .redo(重做信息) 是Oracle在线(或归档)重做日志文件中记录的信息,万一出现失败时可以利用这些数据来“重放”(或重做)事务.Oracle中记录这些信息的文件叫做redo log file ...
- Deutsch lernen (08)
1. empfehlen - empfahl - hat empfohlen 推荐:劝说,劝告 Können Sie mir einen guten Artz empfehlen? jemand e ...
- 题解 P3258 【[JLOI2014]松鼠的新家】(From luoguBlog)
唯一能得分的题也被自己搞炸了,好的. 考场上读完题基本认定和lca脱不了干系,想了一会确认是树剖. 那么问题来了,考前一节课刚发现自己之前打的树剖是错的. 而且就算是错的我也没信心考场调出来. 于是打 ...
- CorelDRAW中内置的视频教程在哪里?
CorelDRAW中内置了很多教学内容和视频教程,可以帮助用户快速学习和掌握CorelDRAW的使用方法,创作出个性化的作品.很多小伙伴表示找不到软件自带学习视频,现在小编就来告诉你. 用户可以通过两 ...
- 安卓 九宫格 GridView 的表格布局
首先,请大家理解一下“迭代显示”这个概念,这个好比布局嵌套,我们在一个大布局里面重复的放入一些布局相同的小布局,那些重复的部分是由图片和文字组成的小控件,图片在上方,文字在下方,之后我们只需要把这些小 ...
- [转载]windows下github 出现Permission denied (publickey).解决方法
今天在学习github的时候遇到了一些问题,然后爬了一会,找到了解决方法记录下来,以防忘记,当然能帮助别人最好啦! github教科书传送门:http://www.liaoxuefeng.com/ ...
- spring-boot启动自动执行sql文件失效 解决办法
在springboot1.5及以前的版本,要执行sql文件只需在applicaion文件里指定sql文件的位置即可.但是到了springboot2.x版本, 如果只是这样做的话springboot不会 ...
- [bzoj3029] 守卫者的挑战 (概率期望dp)
传送门 Description 打开了黑魔法师Vani的大门,队员们在迷宫般的路上漫无目的地搜寻着关押applepi的监狱的所在地.突然,眼前一道亮光闪过."我,Nizem,是黑魔法圣殿的守 ...
- Spring MVC学习总结(2)——Spring MVC常用注解说明
使用Spring MVC的注解及其用法和其它相关知识来实现控制器功能. 02 之前在使用Struts2实现MVC的注解时,是借助struts2-convention这个插件,如今我们使 ...
- jvm学习-垃圾回收器(四)
说明 各种垃圾回收算法都有各自的优缺点.jvm也并没有只采用一种垃圾算法.并提供几种组合供我根据场景进行选择. jvm内存结构 Person p=new Person(); 1.程序里面创建一个对象会 ...