Python入门 来点栗子
查天气(1)
http://wthrcdn.etouch.cn/weather_mini?citykey=101280804
http://wthrcdn.etouch.cn/WeatherApi?citykey=101280804
http://bbs.crossincode.com/forum.php?mod=viewthread&tid=8&extra=page%3D4
http://bbs.crossincode.com/forum.php?mod=viewthread&tid=9&extra=page%3D4
查天气(2)
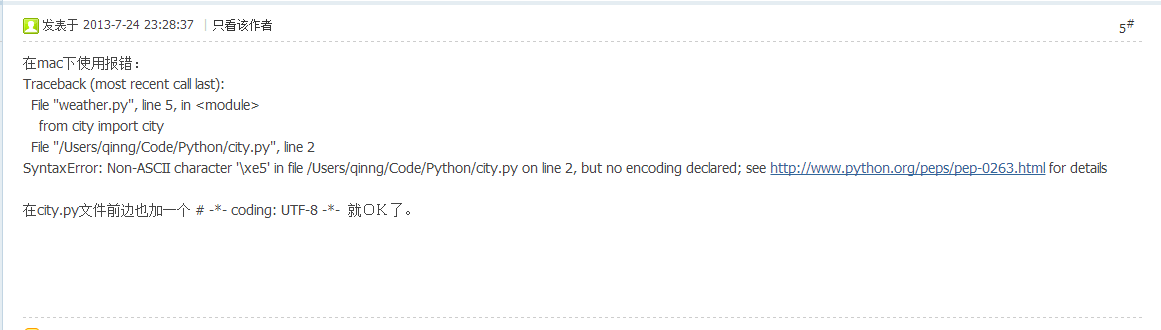
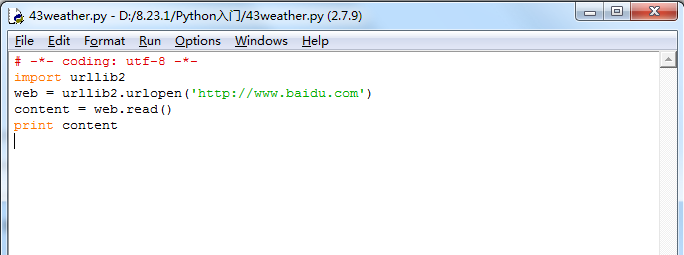
# -*- coding: utf-8 -*-
import urllib2
web = urllib2.urlopen('http://www.baidu.com')
content = web.read()
print content
# -*- coding: UTF-8 -*-
import urllib2
import json
from city import city
cityname = raw_input('你想查哪个城市的天气?\n')
citycode = city.get(cityname)
if citycode:
url = ('http://www.weather.com.cn/data/cityinfo/%s.html' % citycode)
content = urllib2.urlopen(url).read()
print content
http://www.weather.com.cn/data/cityinfo/101280800.html

# -*- coding: UTF-8 -*-
import urllib2
import json
from city import city cityname = raw_input('你想查哪个城市的天气?\n'.decode('utf-8').encode('gbk'))
citycode = city.get(cityname.decode('gbk').encode('utf-8'))
if citycode:
url = ('http://www.weather.com.cn/data/cityinfo/%s.html'%citycode)
print url
content = urllib2.urlopen(url).read().decode('utf-8').encode('gbk')
print content
查天气(3)
看一下我们已经拿到的json格式的天气数据:
{"weatherinfo":{"city":"佛山","cityid":"101280800","temp1":"14℃","temp2":"24℃","weather":"晴","img1":"n0.gif","img2":"d0.gif","ptime":"18:00"}}
{
"weatherinfo":{
"city":"佛山",
"cityid":"101280800",
"temp1":"14℃",
"temp2":"24℃",
"weather":"晴",
"img1":"n0.gif",
"img2":"d0.gif",
"ptime":"18:00"}
}
直接在命令行中看到的应该是没有换行和空格的一长串字符,这里我把格式整理了一下。可以看出,它像是一个字典的结构,但是有两层。最外层只有一个key--“weatherinfo”,它的value是另一个字典,里面包含了好几项天气信息,现在我们最关心的就是其中的temp1,temp2和weather。
虽然看上去像字典,但它对于程序来说,仍然是一个字符串,只不过是一个满足json格式的字符串。我们用python中提供的另一个模块json提供的loads方法,把它转成一个真正的字典。
import json
data = json.loads(content)
这时候的data已经是一个字典,尽管在控制台中输出它,看上去和content没什么区别,只是编码上有些不同:
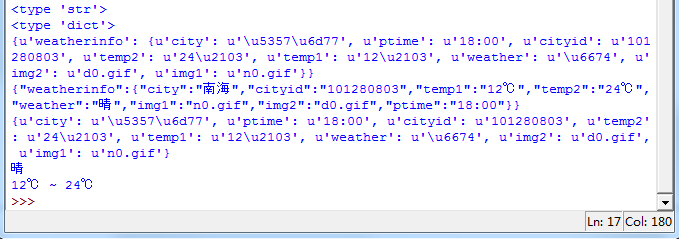
{u'weatherinfo': {u'city': u'\u4f5b\u5c71', u'ptime': u'18:00', u'cityid': u'101280800', u'temp2': u'24\u2103', u'temp1': u'14\u2103', u'weather': u'\u6674', u'img2': u'd0.gif', u'img1': u'n0.gif'}}
但如果你用type方法看一下它们的类型:
print type(content)
print type(data)
就知道区别在哪里了。
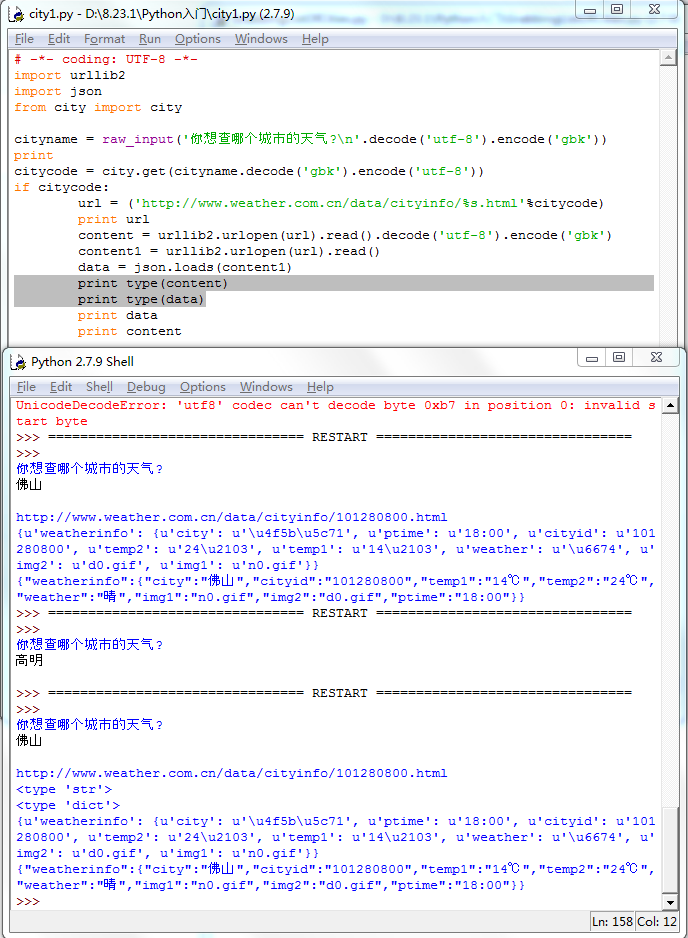
# -*- coding: UTF-8 -*-
import urllib2
import json
from city import city cityname = raw_input('你想查哪个城市的天气?\n'.decode('utf-8').encode('gbk'))
citycode = city.get(cityname.decode('gbk').encode('utf-8'))
if citycode:
url = ('http://www.weather.com.cn/data/cityinfo/%s.html'%citycode)
print url
content = urllib2.urlopen(url).read().decode('utf-8').encode('gbk')
content1 = urllib2.urlopen(url).read()
data = json.loads(content1)
print type(content)
print type(data)
print data
print content
之后的事情就比较容易了。
result = data['weatherinfo']
str_temp = ('%s\n%s ~ %s') % (
result['weather'],
result['temp1'],
result['temp2'] )
print str_temp
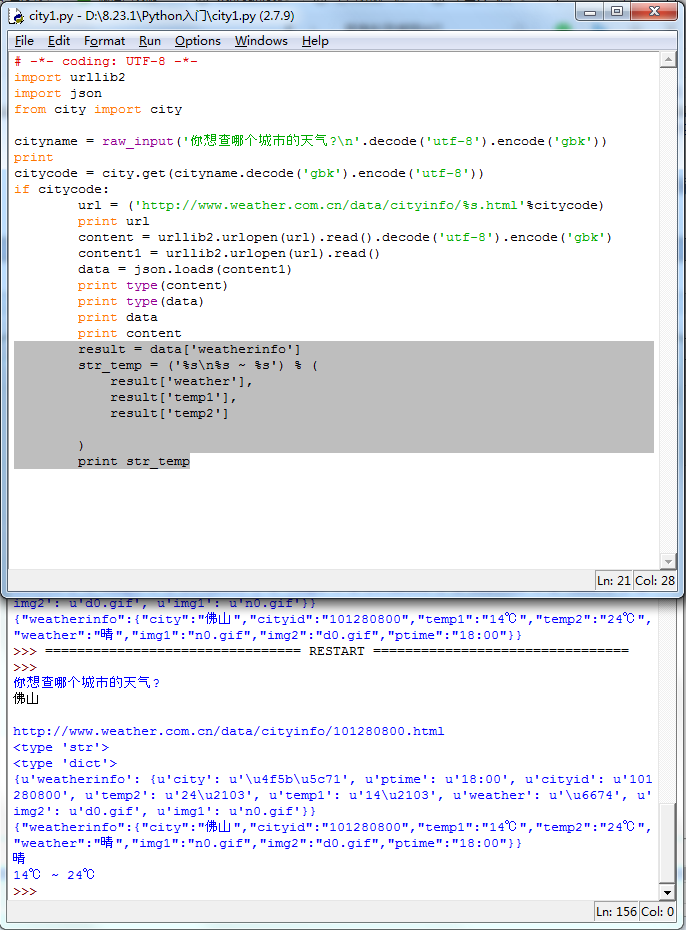
# -*- coding: UTF-8 -*-
import urllib2
import json
from city import city cityname = raw_input('你想查哪个城市的天气?\n'.decode('utf-8').encode('gbk'))
citycode = city.get(cityname.decode('gbk').encode('utf-8'))
if citycode:
url = ('http://www.weather.com.cn/data/cityinfo/%s.html'%citycode)
print url
content = urllib2.urlopen(url).read().decode('utf-8').encode('gbk')
content1 = urllib2.urlopen(url).read()
data = json.loads(content1)
print type(content)
print type(data)
print data
print content
result = data['weatherinfo']
str_temp = ('%s\n%s ~ %s') % (
result['weather'],
result['temp1'],
result['temp2'] )
print str_temp
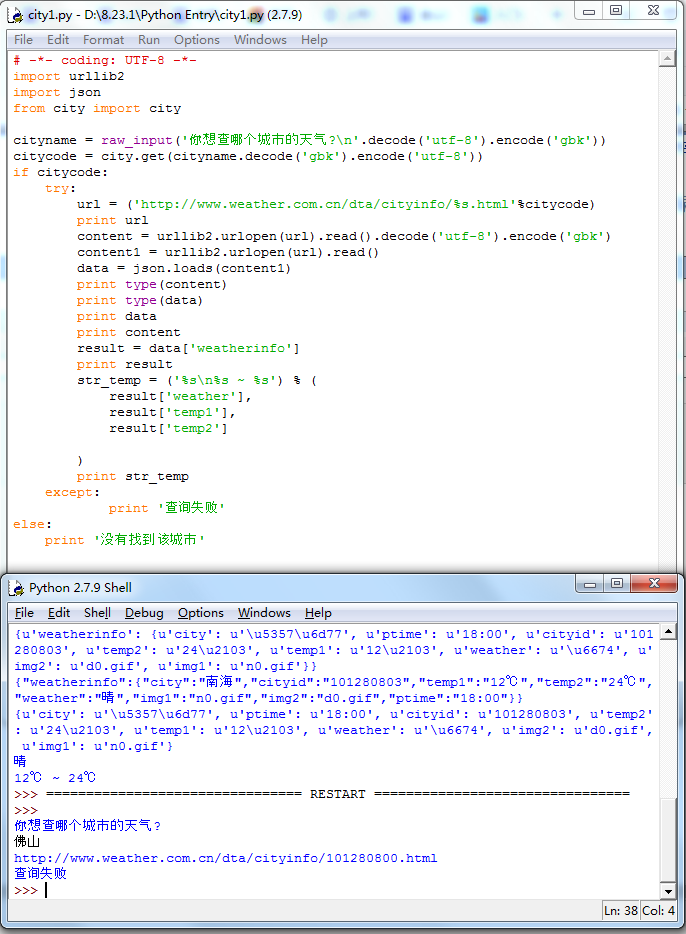
为了防止在请求过程中出错,我加上了一个异常处理。
try:
###
###
except:
print '查询失败'
以及没有找到城市时的处理:
if citycode:
###
###
else:
print '没有找到该城市'
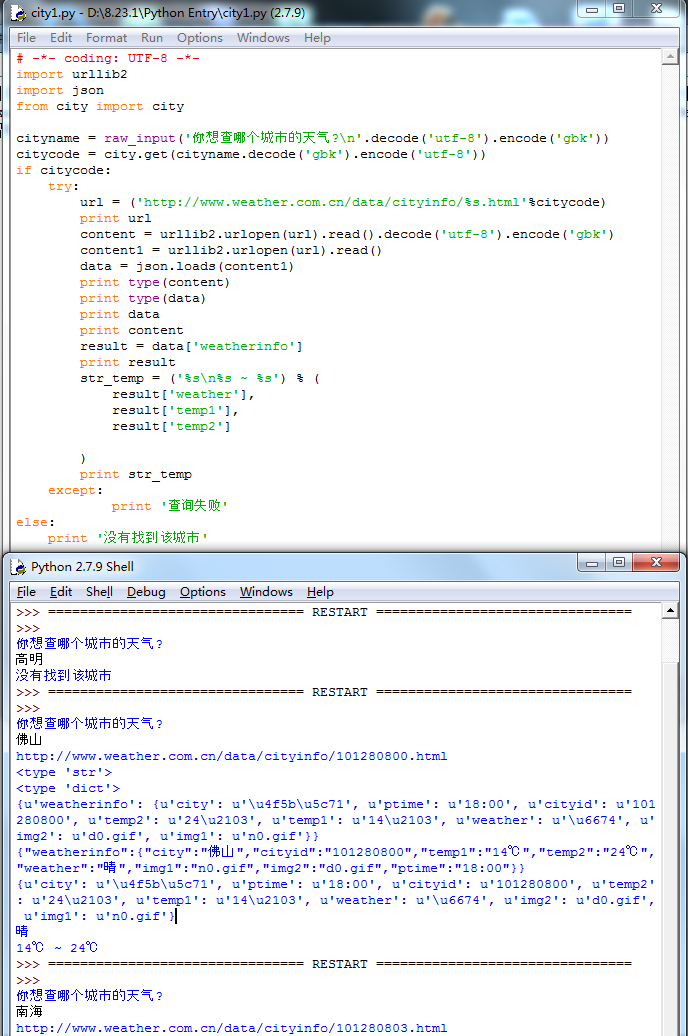
# -*- coding: UTF-8 -*-
import urllib2
import json
from city import city cityname = raw_input('你想查哪个城市的天气?\n'.decode('utf-8').encode('gbk'))
citycode = city.get(cityname.decode('gbk').encode('utf-8'))
if citycode:
try:
url = ('http://www.weather.com.cn/data/cityinfo/%s.html'%citycode)
print url
content = urllib2.urlopen(url).read().decode('utf-8').encode('gbk')
content1 = urllib2.urlopen(url).read()
data = json.loads(content1)
print type(content)
print type(data)
print data
print content
result = data['weatherinfo']
print result
str_temp = ('%s\n%s ~ %s') % (
result['weather'],
result['temp1'],
result['temp2'] )
print str_temp
except:
print '查询失败'
else:
print '没有找到该城市'
查天气(4)
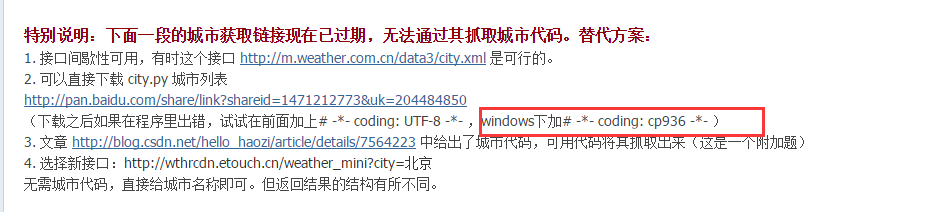
这一课算是“查天气”程序的附加内容。没有这一课,你也查到天气了。但了解一下城市代码的抓取过程,会对网页抓取有更深的理解。
天气网的城市代码信息结构比较复杂,所有代码按层级放在了很多xml为后缀的文件中。而这些所谓的“xml”文件又不符合xml的格式规范,导致在浏览器中无法显示,给我们的抓取又多加了一点难度。
首先,抓取省份的列表:
# -*- coding: UTF-8 -*-
import urllib2 url1 = 'http://m.weather.com.cn/data3/city.xml' content1 = urllib2.urlopen(url1).read() provinces = content1.split(',') print content1
输出content1可以查看全部省份代码:
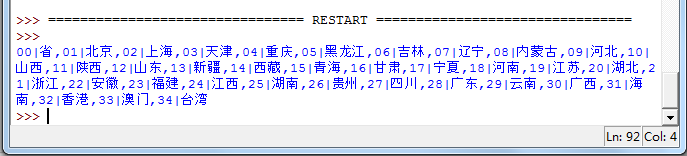
对于每个省,抓取城市列表:
url = 'http://m.weather.com.cn/data3/city%s.xml'
for p in provinces:
p_code = p.split('|')[0]
url2 = url % p_code
content2 = urllib2.urlopen(url2).read()
cities = content2.split(',')
print content2.decode('utf-8')
输出content2可以查看此省份下所有城市代码:
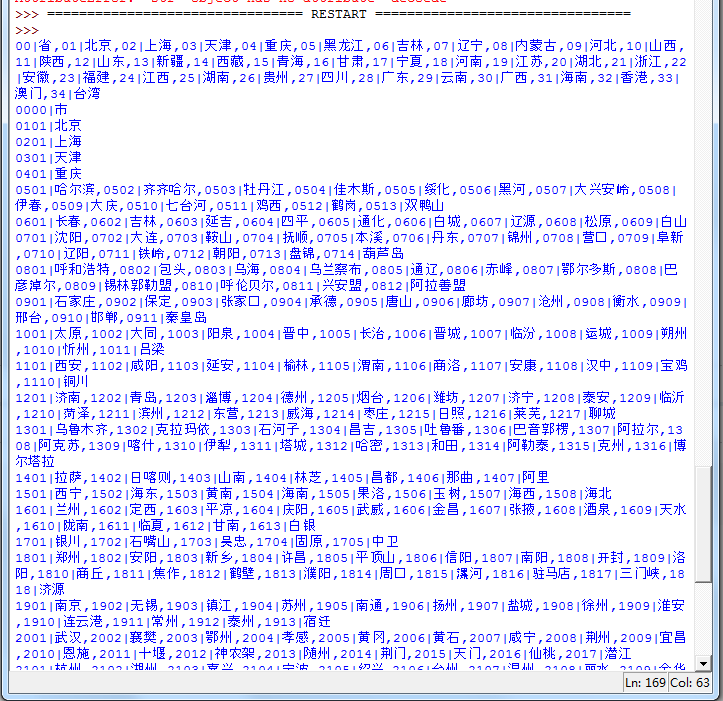
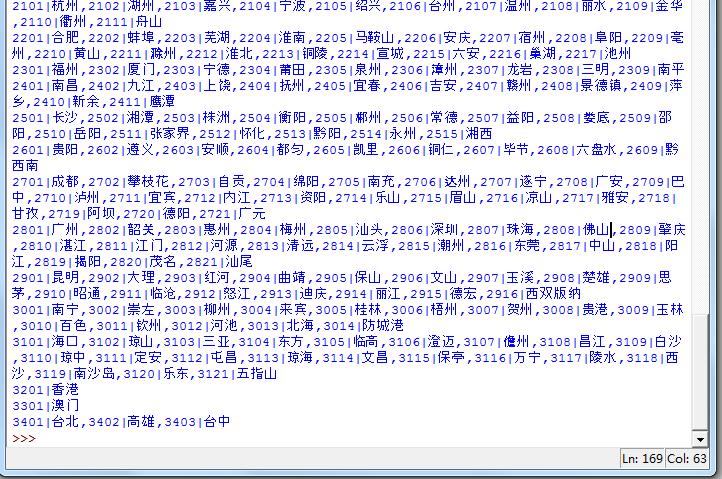
再对于每个城市,抓取地区列表:
for c in cities[:3]:
c_code = c.split('|')[0]
url3 = url % c_code
content3 = urllib2.urlopen(url3).read()
districts = content3.split(',')
print content3.decode('utf-8')
content3是此城市下所有地区代码:
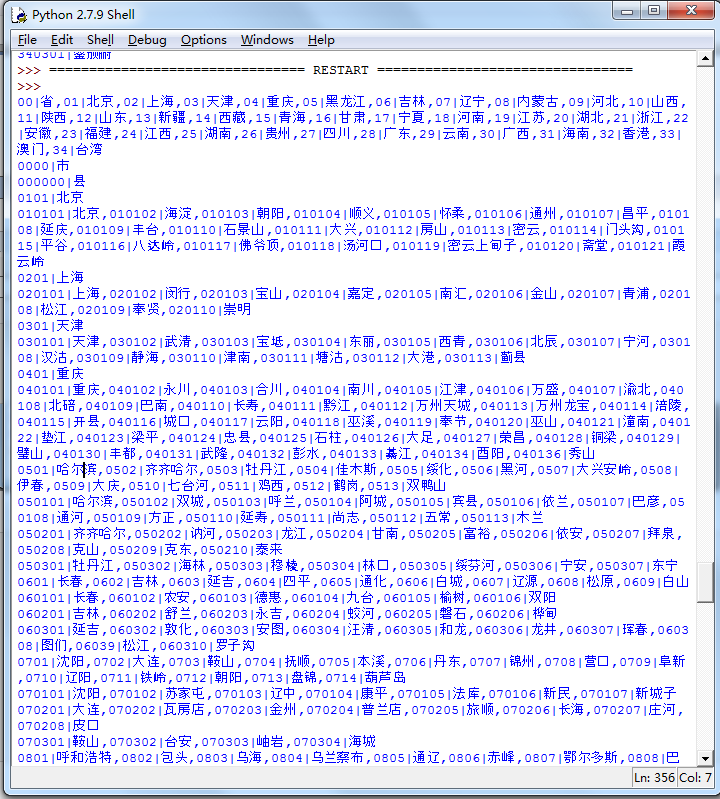
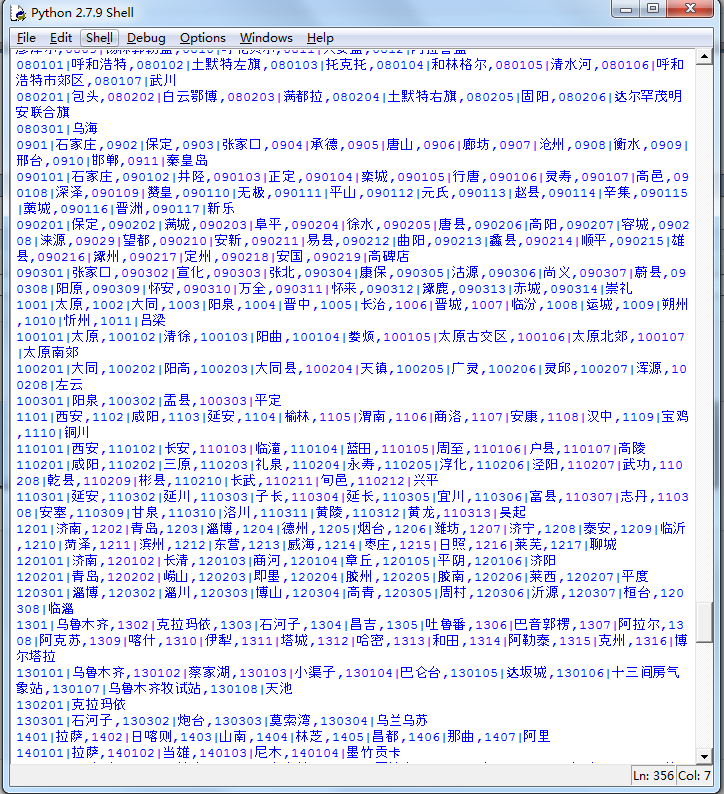
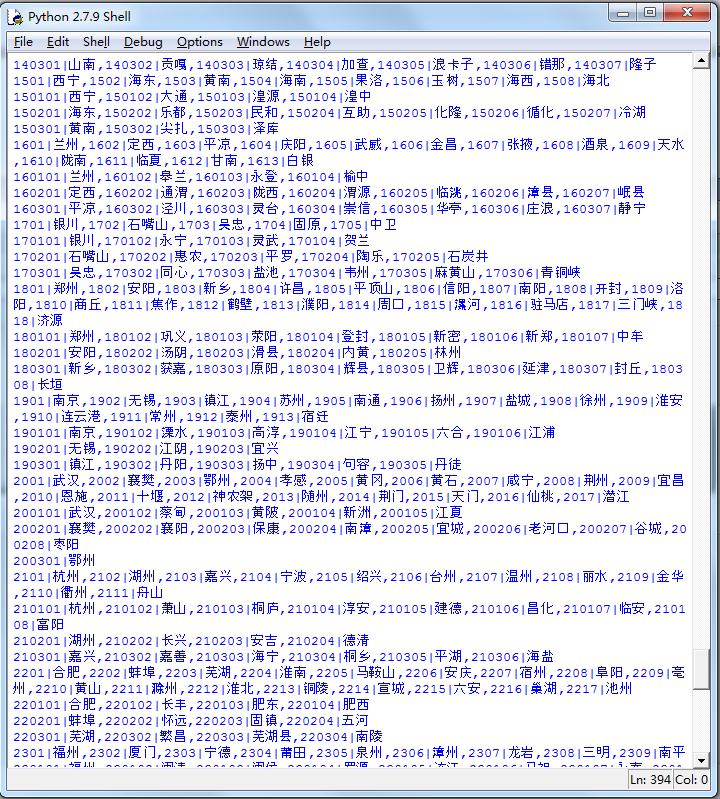

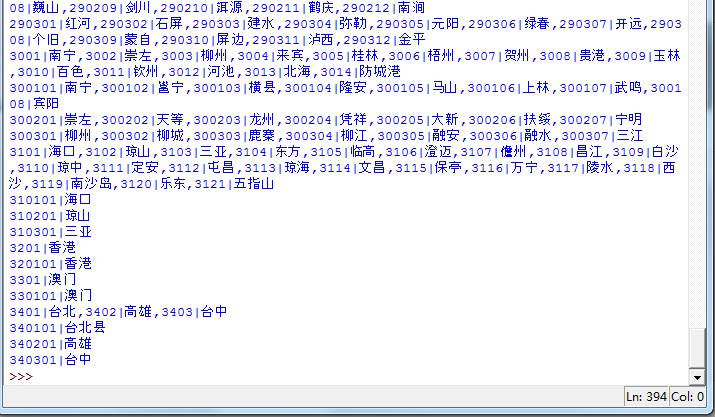
最后,对于每个地区,我们把它的名字记录下来,然后再发送一次请求,得到它的最终代码:
Python入门 来点栗子的更多相关文章
- python入门之小栗子
1 点球小游戏: from random import choice score=[0,0]direction=['left','center','right'] def kick(): print ...
- PYTHON 学习笔记1 PYTHON 入门 搭建环境与基本类型
简介 Python,当然大家听到这个名词不再是有关于像JAVA 一样的关于后台,我们学习Python 的目的在于对于以后数据分析和机器学习AI 奠定基础,Python 在数据分析这一块,可谓是有较好的 ...
- python入门简介
Python前世今生 python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为ABC ...
- python入门学习课程推荐
最近在学习自动化,学习过程中,越来越发现coding能力的重要性,不会coding,基本不能开展自动化测试(自动化工具只是辅助). 故:痛定思痛,先花2个星期将python基础知识学习后,再进入自动化 ...
- Python运算符,python入门到精通[五]
运算符用于执行程序代码运算,会针对一个以上操作数项目来进行运算.例如:2+3,其操作数是2和3,而运算符则是“+”.在计算器语言中运算符大致可以分为5种类型:算术运算符.连接运算符.关系运算符.赋值运 ...
- Python基本语法[二],python入门到精通[四]
在上一篇博客Python基本语法,python入门到精通[二]已经为大家简单介绍了一下python的基本语法,上一篇博客的基本语法只是一个预览版的,目的是让大家对python的基本语法有个大概的了解. ...
- Python基本语法,python入门到精通[二]
在上一篇博客Windows搭建python开发环境,python入门到精通[一]我们已经在自己的windows电脑上搭建好了python的开发环境,这篇博客呢我就开始学习一下Python的基本语法.现 ...
- visual studio 2015 搭建python开发环境,python入门到精通[三]
在上一篇博客Windows搭建python开发环境,python入门到精通[一]很多园友提到希望使用visual studio 2013/visual studio 2015 python做demo, ...
- python入门教程链接
python安装 选择 2.7及以上版本 linux: 一般都自带 windows: https://www.python.org/downloads/windows/ mac os: https:/ ...
随机推荐
- Cesium学习笔记(四)Camera ----http://blog.csdn.net/hobhunter/article/details/74909641
Cesium 相机控制场景中的视野.操作相机的方法有很多,如旋转,缩放,平移和飞到目的地.Cesium具有默认的鼠标和触摸事件处理程序与相机进行交互,还有一个API以编程方式操纵相机. 我们可以使用该 ...
- A water problem (hdu-5832)
不多说就是一个数对两个数的乘积求模运算 不得不说vj上这个题的翻译版本真是太暴力了 难点 主要还是时间的控制,这题太容易TLE了.用到的算法就是大数求余数的ans=(ans*10-a[i]-'0')% ...
- Linux之网络ping(unknown host)故障及yum no more mirrors to try
1.ping外网出现ping:unknown host 字样故障 鉴于网上大多都是提供临时生效的解决办法,这里不再赘述,并提供下永久生效的方案: 永久生效: 1)添加DNS地址和下一跳网关地址至网 ...
- axios请求中跨域及post请求问题解决方案
闲话不多说,用到vue的童鞋们应该大部分都会遇到请求中的各种奇葩问题,昨天研究一天,终于搞出来个所以然了,写篇文章拯救一下广大的童鞋们,某度娘当然也可以搜到,但一般解决了一个问题后就会出现另外一个问题 ...
- socket 网络编程笔记 一
初始socket模块 Serve端代码 import socket sk = socket.socket() #默认为TCP连接 """socket 里面两个方法 fam ...
- 《零压力学Python》 之 第二章知识点归纳
第二章(数字)知识点归纳 要生成非常大的数字,最简单的办法是使用幂运算符,它由两个星号( ** )组成. 如: 在Python中,整数是绝对精确的,这意味着不管它多大,加上1后都将得到一个新的值.你将 ...
- BUAA_OO_博客作业二
1.作业设计策略 1.1第一次作业 第一次作业指导书要求是一个单部多线程傻瓜调度(FAFS)电梯的模拟,由于为了可扩展性和模块化设计,第一次作业我采用了三线程,即输入处理线程,调度器线程,电梯线程 ...
- 【Codeforces Global Round 1 E】Magic Stones
[链接] 我是链接,点我呀:) [题意] 你可以把c[i]改成c[i+1]+c[i-1]-c[i] (2<=i<=n-1) 问你能不能把每一个c[i]都换成对应的t[i]; [题解] d[ ...
- [luoguP2342] 叠积木(并查集)
传送门 up[i] 表示一个木块上面有多少个 all[i] 表示整个连通块内有多少个 那么 一个木块下面的木块个数为 all[root[i]] - up[i] - 1 注意:up[i] 可以在 fin ...
- 爬虫——response中获取的不带主域名的url的拼接
scrapy中response提取的没有主域名的url拼接 # 1.导入urllib的parse # 2.调用parse.urljoin()进行拼接,例子中response.url会自动提取出当前页面 ...