分布式缓存--系列1 -- Hash环/一致性Hash原理
当前,Memcached、Redis这类分布式kv缓存已经非常普遍。从本篇开始,本系列将分析分布式缓存相关的原理、使用策略和最佳实践。
我们知道Memcached的分布式其实是一种“伪分布式”,也就是它的服务器结点之间其实是相互无关联的,之间没有网络拓扑关系,由客户端来决定一个key是存放到哪台机器。
具体来讲,假设我有多台memcached服务器,编号分别为m0,m1,m2,…。对于一个key,由客户端来决定存放到哪台机器,那最简单的hash公式就是 key % N,其中N是机器的总数。
但这有个问题,一旦机器数变少,或者增加机器,N发生变化,那之前存放的数据就全部无效了。因为你按照新的N值取模计算出的机器编号,和当时按旧的N值取模算出的机器编号肯定是不等的,也就意味着绝大部分缓存会失效。
这个问题的解决办法就是用1种特别的Hash函数,尽可能使得,增加机器/减少机器时,缓存失效的数目降到最低,这就是Hash环,或者叫一致性Hash。
有兴趣朋友可以关注公众号“架构之道与术”, 获取最新文章。
或扫描如下二维码:

Hash环
上面说的Hash函数,只经过了1次hash,即把key hash到对应的机器编号。
而Hash环有2次Hash:
(1)把所有机器编号hash到这个环上
(2)把key也hash到这个环上。然后在这个环上进行匹配,看这个key和哪台机器匹配。
具体来讲,如下:
假定有这样一个Hash函数,其值空间为(0到2的32次方-1) ,也就是说,其hash值是个32位无整型数字 ,这些数字组成一个环。
然后,先对机器进行hash(比如根据机器的ip),算出每台机器在这个环上的位置; 再对key进行hash,算出该key在环上的位置,然后从这个位置往前走,遇到的第一台机器就是该key对应的机器,就把该(key, value) 存储到该机器上。
如下图所示:
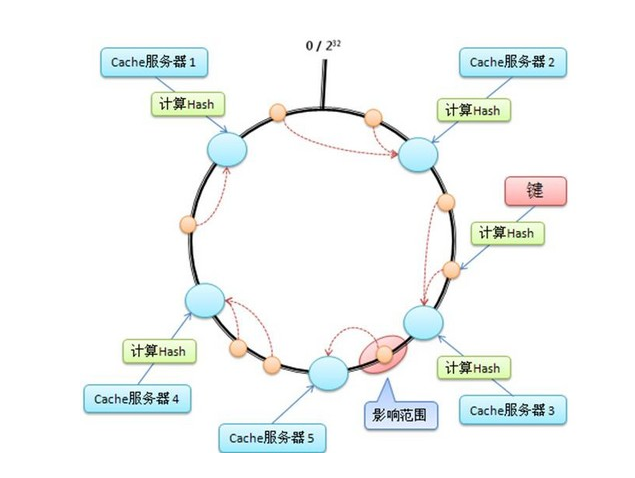
首先计算出每台Cache服务器在环上的位置(图中的大圆圈);然后每来一个(key, value),计算出在环上的位置(图中的小圆圈),然后顺时针走,遇到的第1个机器,就是其要存储的机器。
这里的关键点是:当你增加/减少机器时,其他机器在环上的位置并不会发生改变。这样只有增加的那台机器、或者减少的那台机器附近的数据会失效,其他机器上的数据都还是有效的。
数据倾斜问题
当你机器不多的时候,很可能出现几台机器在环上面贴的很近,不是在环上均匀分布。这将会导致大部分数据,都会集中在某1台机器上。
为了解决这个问题,可以引入“虚拟机器”的概念,也就是说:1台机器,我在环上面计算出多个位置。怎么弄呢? 假设用机器的ip来hash,我可以在ip后面加上几个编号, ip_1, ip_2, ip_3, .. 把1台物理机器生个多个虚拟机器的编号。
数据首先映射到“虚拟机器上”,再从“虚拟机器”映射到物理机器上。因为虚拟机器可以很多,在环上面均匀分布,从而保证数据均匀分布到物理机器上面。
ZK的引入
上面我们提到了服务器的机器增加、减少,问题是客户端怎么知道呢?
一种笨办法就是手动的,当服务器机器增加、减少时候,重新配置客户端,重启客户端。
另外一种,就是引入ZK,服务器的节点列表注册到ZK上面,客户端监听ZK。发现结点数发生变化,自动更新自己的配置。
当然,不用ZK,用一个其他的中心结点,只要能实现这种更改的通知,也是可以的。
分布式缓存--系列1 -- Hash环/一致性Hash原理的更多相关文章
- 分布式缓存 - hash环/一致性hash
一 引言 当前memcached,redis这类分布式kv缓存已经非常普遍.我们知道memcached的分布式其实是一种"伪分布式",也就是它的服务器节点之间其实是无关联的,之间没 ...
- Hash环/一致性Hash原理
当前,Memcached.Redis这类分布式kv缓存已经非常普遍.从本篇开始,本系列将分析分布式缓存相关的原理.使用策略和最佳实践. 我们知道Memcached的分布式其实是一种“伪分布式”,也就是 ...
- 分布式缓存技术memcached学习系列(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到"分布式一致性hash算法"这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前, ...
- 分布式理论系列(二)一致性算法:2PC 到 3PC 到 Paxos 到 Raft 到 Zab
分布式理论系列(二)一致性算法:2PC 到 3PC 到 Paxos 到 Raft 到 Zab 本文介绍一致性算法: 2PC 到 3PC 到 Paxos 到 Raft 到 Zab 两类一致性算法(操作原 ...
- hash·余数hash和一致性hash
网站的伸缩性架构中,分布式的设计是现在的基本应用. 在memcached的分布式架构中,key-value缓存的命中通常采用分布式的算法 一.余数Hash 简单的路由算法可以使用余数Hash: ...
- 【分布式缓存系列】Redis实现分布式锁的正确姿势
一.前言 在我们日常工作中,除了Spring和Mybatis外,用到最多无外乎分布式缓存框架——Redis.但是很多工作很多年的朋友对Redis还处于一个最基础的使用和认识.所以我就像把自己对分布式缓 ...
- CYQ.Data V5 分布式缓存Redis应用开发及实现算法原理介绍
前言: 自从CYQ.Data框架出了数据库读写分离.分布式缓存MemCache.自动缓存等大功能之后,就进入了频繁的细节打磨优化阶段. 从以下的更新列表就可以看出来了,3个月更新了100条次功能: 3 ...
- 【分布式缓存系列】集群环境下Redis分布式锁的正确姿势
一.前言 在上一篇文章中,已经介绍了基于Redis实现分布式锁的正确姿势,但是上篇文章存在一定的缺陷——它加锁只作用在一个Redis节点上,如果通过sentinel保证高可用,如果master节点由于 ...
- 一致性Hash(Consistent Hashing)原理剖析
引入 在业务开发中,我们常把数据持久化到数据库中.如果需要读取这些数据,除了直接从数据库中读取外,为了减轻数据库的访问压力以及提高访问速度,我们更多地引入缓存来对数据进行存取.读取数据的过程一般为: ...
随机推荐
- poj3734 Blocks[矩阵优化dp or 组合数学]
Blocks Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 6578 Accepted: 3171 Descriptio ...
- Autofac在项目中应用的体会,一个接口多个实现的情况
在本人接触的项目中Autofac应用的比较多一些,我理解的他的工作原理就是 注册类并映射到接口,通过注入后返回相应实例化的类! 下面说说我在项目中的实际应用 先来简单介绍下Autofac的使用 1. ...
- vector容器建图
#pragma comment(linker, "/STACK:1024000000,1024000000") #include"stdio.h" #inclu ...
- 网站微图标,页标签,favicon.ico
随便打开一个网页:比如 http://www.baidu.com/ 可以看到在浏览器的标签头上面显示了一个图标,也就是我们常说的favicon.ico, 由于这篇文章主要讨论favicon.ico,以 ...
- Centos7更改yum源与更新系统
[1] 首先备份 /etc/yum.repos.d/CentOS-Base.repo mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/Cen ...
- Oracle表的维护(字段,重命名表名)
案例:银行里建的开卡信息 字段 字段类型 Id Number name Varchar2(64) sex Char2() birth Date money Number(10,2) 创建银行卡表 cr ...
- oracle的认证方式
使用as sysdba是使用操作系统验证方式,不需要输入密码
- Delphi中那些容易混淆的基础(@、^、Addr、Pointer,Move、CopyMemory,GetMem和FreeMem、GetMemory和FreeMemory、New和Dispose、StrAlloc和StrDispose、AllocMem)
@.^.Addr.Pointer Delphi(Pascal)中有几个特殊的符号,如@.^等,弄清楚这些符号的运行,首先要明白Delphi指针的一些基础知识:指针,是一个无符号整数(unsigned ...
- Python开发【模块】:CSV文件 数据可视化
CSV模块 1.CSV文件格式 要在文本文件中存储数据,最简单的方式是讲数据作为一系列逗号分隔的值(CSV)写入文件,这样的文件成为CSV文件,如下: AKDT,Max TemperatureF,Me ...
- linux IO多路复用POLL机制深入分析
POLL机制的作用这里就不进行介绍,根据linux man手册,解释为在一个文件描述符上等待某个事件.按照抽象一点的理解,当某个事件被触发(条件被满足),文件描述符变为有状态,那么用户空间可以根据此进 ...