MySQL中文全文检索demoSQL
一、概述
MySQL全文检索是利用查询关键字和查询列内容之间的相关度进行检索,可以利用全文索引来提高匹配的速度。
二、语法
MATCH (col1,col2,...) AGAINST (expr [search_modifier])
search_modifier: { IN BOOLEAN MODE | WITH QUERY EXPANSION }
例如:SELECT * FROM tab_name WHERE MATCH ('列名1,列名2...列名n') AGAINST('词1 词2 词3 ... 词m');
即:MATCH 相当于要匹配的列,而 AGAINST 就是要找的内容。
这里的table需要是MyISAM类型的表,col1、col2 必须是char、varchar或text类型,在查询之前需要在 col1 和 col2 上分别建立全文索引(FULLTEXT索引)。
三、检索方式
1、自然语言检索: IN NATURAL LANGUAGE MODE
2、布尔检索: IN BOOLEAN MODE
剔除一半匹配行以上都有的词,譬如说,每个行都有this这个字的话,那用this去查时,会找不到任何结果,这在记录条数特别多时很有用,
原因是数据库认为把所有行都找出来是没有意义的,这时,this几乎被当作是stopword(中断词);但是若只有两行记录时,是啥鬼也查不出来的,
因为每个字都出现50%(或以上),要避免这种状况,请用IN BOOLEAN MODE。
● IN BOOLEAN MODE的特色:
·不剔除50%以上符合的row。
·不自动以相关性反向排序。
·可以对没有FULLTEXT index的字段进行搜寻,但会非常慢。
·限制最长与最短的字符串。
·套用Stopwords。
● 搜索语法规则:
+ 一定要有(不含有该关键词的数据条均被忽略)。
- 不可以有(排除指定关键词,含有该关键词的均被忽略)。
> 提高该条匹配数据的权重值。
< 降低该条匹配数据的权重值。
~ 将其相关性由正转负,表示拥有该字会降低相关性(但不像 - 将之排除),只是排在较后面权重值降低。
* 万用字,不像其他语法放在前面,这个要接在字符串后面。
" " 用双引号将一段句子包起来表示要完全相符,不可拆字。
SELECT * FROM articles WHERE MATCH (title,content) AGAINST ('+apple -banana' IN BOOLEAN MODE);
+ 表示AND,即必须包含。- 表示NOT,即必须不包含。即:返回记录必需包含 apple,且不能包含 banner。
SELECT * FROM articles WHERE MATCH (title,content) AGAINST ('apple banana' IN BOOLEAN MODE);
apple和banana之间是空格,空格表示OR。即:返回记录至少包含apple、banana中的一个。
SELECT * FROM articles WHERE MATCH (title,content) AGAINST ('+apple banana' IN BOOLEAN MODE);
返回记录必须包含apple,同时banana可包含也可不包含,若包含的话会获得更高的权重。
SELECT * FROM articles WHERE MATCH (title,content) AGAINST ('+apple ~banana' IN BOOLEAN MODE);
~ 是我们熟悉的异或运算符。返回记录必须包含apple,若也包含了banana会降低权重。
但是它没有 +apple -banana 严格,因为后者如果包含banana压根就不返回。
SELECT * FROM articles WHERE MATCH (title,content) AGAINST ('+apple +(>banana <orange)' IN BOOLEAN MODE);
返回必须同时包含“apple banana”或者必须同时包含“apple orange”的记录。
若同时包含“apple banana”和“apple orange”的记录,则“apple banana”的权重高于“apple orange”的权重。
3、查询扩展检索: WITH QUERY EXPANSION
四、MySQL全文检索的条件限制
1、在MySQL5.6以下,只有MyISAM表支持全文检索。在MySQL5.6以上Innodb引擎表也提供支持全文检索。
2、相应字段建立FULLTEXT索引
五、与全文检索相关的系统变量:
ft_min_word_len = 全文检索的最小许可字符(默认4,通过 SHOW VARIABLES LIKE 'ft_min_word_len' 可查看),
中文通常是两个字就是一个词,所以做中文的话需要修改这个值为2最好。
六、总结事项
1、预设搜寻是不分大小写,若要分大小写,columne 的 character set要从utf8改成utf8_bin。
2、预设 MATCH...AGAINST 是以相关性排序,由高到低。
3、MATCH(title, content)里的字段必须和FULLTEXT(title, content)里的字段一模一样。
如果只要单查title或content一个字段,那得另外再建一个 FULLTEXT(title) 或 FULLTEXT(content),也因为如此,MATCH()的字段一定不能跨table,但是另外两种搜寻方式好像可以。
4、MySQL不支持中文全文索引,原因很简单:与英文不同,中文的文字是连着一起写的,中间没有MySQL能找到分词的地方,截至目前MySQL5.6版本是如此,但是有变通的办法,就是将整句的中文分词,并按urlencode、区位码、base64、拼音等进行编码使之以“字母+数字”的方式存储于数据库中。
七、实验部分
◆ 步骤1 配置my.ini,在my.ini末尾添加如下:
# 修改全文检索的最小许可字符为2个字符或汉字
ft_min_word_len = 2
完成后“重启 MySQL 服务”,并用 SHOW VARIABLES LIKE 'ft_min_word_len' 查询下是否得到了正确的结果值为2,如下图:

◆ 步骤2 创建数据库(视情况可跳过此步)
CREATE DATABASE search DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
◆ 步骤3 创建数据表
CREATE TABLE `zzx_articles` (
`id` int(10) unsigned NOT NULL auto_increment,
`title` char(254) default NULL COMMENT '标题',
`content` text COMMENT '内容',
`author` char(60) default NULL COMMENT '作者',
`title_fc` char(254) default NULL COMMENT '标题的分词',
`content_fc` text COMMENT '内容的分词',
PRIMARY KEY (`id`),
FULLTEXT KEY `zzx_title_fc` (`title_fc`),
FULLTEXT KEY `zzx_content_fc` (`content_fc`),
FULLTEXT KEY `zzx_title_con_fc` (`title_fc`,`content_fc`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8
# 如果后期需要添全文加索引可以用如下语句:
alter table `zzx_articles` add fulltext zzx_title_fc(`title_fc`);
alter table `zzx_articles` add fulltext zzx_con_fc(`content_fc`);
alter table `zzx_articles` add fulltext zzx_title_con_fc(`title_fc`,`content_fc`);
◆ 步骤4 插入测试数据
INSERT INTO `zzx_articles` (title_fc,content_fc) VALUES
('MySQL Tutorial Linux red','DBMS stands for DataBase ok'),
('How To Use MySQL Well','After you went through blue'),
('Optimizing MySQL ok','In this tutorial we will optimizing'),
('MySQL vs this YourSQL blue red','1. Never run mysqld as root red'),
('MySQL Tricks blue','In the following database'),
('MySQL Security','When configured properly, MySQL'),
('中华','中华人民共和国 '),
('中华情 和谐','上海 和谐'),
('污染之都','你好 我是 北京 人'),
('北京精神','创新 爱国 包容 厚颜')
插入结果如下图:

◆ 步骤5 搜索语法规则、排序 实验
说明:匹配语句 MATCH (col1,col2,...) AGAINST (expr [search_modifier]) 匹配完成后,会返回此条数据的权重值(权重值1 ≈ 各个词的匹配结果权重值之和),我们利用此权重值“由高到低”排序可优化查询结果。
------------------------------------------------------------------------------------------------------------------------------
▶ 实验1:只对 title_fc 索引字段做全文检索,并显示每条数据的权重值
SELECT *,MATCH (title_fc) AGAINST ('optimizing ok red blue') as title_score
FROM zzx_articles
WHERE MATCH (title_fc) AGAINST ('optimizing ok red blue' IN BOOLEAN MODE) order by title_score DESC
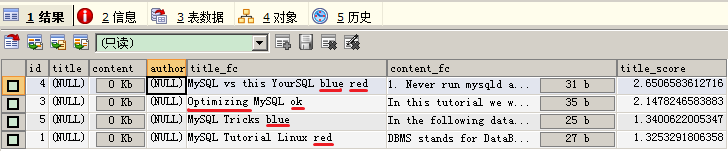
总结:1.当没有加 + - 这样的过滤符号时,这些关键词是“或(or)”的关系,即:要么匹配optimizing,要么匹配ok,要么匹配red,要么匹配blue。
2.通过上面实验,发现当某条数据有多个关键词匹配时(如:red blue),此条数据的权重值会略高:
此条数据权重值 ≈ optimizing权重值 + ok权重值 + red权重值 + blue权重值
理论上来说,当一条数据能匹配上的关键词越多,则此条数据的权重值越高,排名越靠前。
------------------------------------------------------------------------------------------------------------------------------
▶ 实验2:过滤条件:必须包含"red"关键词
SELECT *,MATCH (title_fc) AGAINST ('optimizing ok red') as title_score
FROM zzx_articles
WHERE MATCH (title_fc) AGAINST ('optimizing ok +red' IN BOOLEAN MODE) order by title_score DESC

总结:使用了过滤符号 + ,表示查询结果中,任一条数据都必须包含"red"这个词,不包含"red"这个词的行均被忽略。
------------------------------------------------------------------------------------------------------------------------------
▶ 实验3:过滤条件:必须包含"red"关键词,如果匹配到的行中还含有"blue"关键词,则会对此条数据增加权重:
SELECT *,MATCH (title_fc) AGAINST ('optimizing ok red blue') as title_score
FROM zzx_articles
WHERE MATCH (title_fc) AGAINST ('optimizing ok +red blue' IN BOOLEAN MODE) order by title_score DESC
或下面写法:
SELECT *,MATCH (title_fc) AGAINST ('optimizing ok red >blue') as title_score
FROM zzx_articles
WHERE MATCH (title_fc) AGAINST ('optimizing ok +red >blue' IN BOOLEAN MODE) order by title_score DESC

总结:与实验2比较,当包含了red的行中,若也包含blue关键词,权重确实增加了(如:id=4这条)。
------------------------------------------------------------------------------------------------------------------------------
▶ 实验4:过滤条件:必须包含"red"关键词,并且不能包含"blue"关键词
SELECT *,MATCH (title_fc) AGAINST ('optimizing ok red blue') as title_score
FROM zzx_articles
WHERE MATCH (title_fc) AGAINST ('optimizing ok +red -blue' IN BOOLEAN MODE) order by title_score DESC

总结:可见 + - 这两个符号是表示“并且(and)”的意思,即:必须包含red关键词 and 不能包含blue关键词。
------------------------------------------------------------------------------------------------------------------------------
▶ 实验5:过滤条件:必须包含"red"关键词,如果匹配到的行中还包含"blue"关键词则降低此条数据权重
SELECT *,MATCH (title_fc) AGAINST ('optimizing ok +red ~blue') as title_score
FROM zzx_articles
WHERE MATCH (title_fc) AGAINST ('optimizing ok +red ~blue' IN BOOLEAN MODE) order by title_score DESC

总结:这个实验没有看到明显效果,但 ~ 过滤符确实是降低此权重符
------------------------------------------------------------------------------------------------------------------------------
▶ 实验6:过滤条件:匹配包含单词“red”和“Linux” 的行,或包含“red” 和“blue”的行(无先后顺序)
然而包含 “apple Linux”的行较包含“apple blue”的行有更高的权重值。
SELECT *,MATCH (title_fc) AGAINST ('+red +(>Linux <blue)') as title_score
FROM zzx_articles
WHERE MATCH (title_fc) AGAINST ('+red +(>Linux <blue)' IN BOOLEAN MODE) order by title_score DESC

------------------------------------------------------------------------------------------------------------------------------
▶ 实验7:过滤条件:匹配关键词以 re 开头,或以 bl 开头的数据行
SELECT *,MATCH (title_fc) AGAINST ('re* bl*') as title_score
FROM zzx_articles
WHERE MATCH (title_fc) AGAINST ('re* bl*' IN BOOLEAN MODE) order by title_score DESC

总结:注意 * 是写在后面哦,此时相当于 like 模糊匹配,没有权重值了
------------------------------------------------------------------------------------------------------------------------------
▶ 实验8:过滤条件:匹配查找字符串“To Use MySQL”关键词
SELECT *,MATCH (title_fc) AGAINST ('"To Use MySQL"') as title_score
FROM zzx_articles
WHERE MATCH (title_fc) AGAINST ('"To Use MySQL"' IN BOOLEAN MODE) order by title_score DESC

总结:此时是把双引号内的的字符串看成一个关键词,若不用双引号则是将 To Use MySQL 三个关键词去分别匹配,两者有区别;
------------------------------------------------------------------------------------------------------------------------------
▶ 实验9:在实验1基础上,将blue的权重值忽视不要(注意与实验1比较)
SELECT *,MATCH (title_fc) AGAINST ('optimizing ok red') as title_score
FROM zzx_articles
WHERE MATCH (title_fc) AGAINST ('optimizing ok red blue' IN BOOLEAN MODE) order by title_score DESC

总结:在实验1的基础上,此时去除select字段条件里的blue关键词,但在where里去仍保留blue关键词。
我的本意是想正常匹配“optimizing ok red blue”这几个关键词,但不想得到blue的权重值(忽视blue的权重值)。
查询的结果是含有blue关键词的数据的权重值会略降低了。
通过“降重”——忽略某些关键词权重值的方式可使部分数据权重值减小,进而影响排序。
------------------------------------------------------------------------------------------------------------------------------
▶ 实验10:在实验9的基础上,在select字段条件里增加几个red关键词,where里的关键词保持不变(注意与实验1 实验9比较)。
SELECT *,MATCH (title_fc) AGAINST ('optimizing ok red red red') as title_score
FROM zzx_articles
WHERE MATCH (title_fc) AGAINST ('optimizing ok red blue' IN BOOLEAN MODE) order by title_score DESC

总结:发现只要含有 red 关键词的数据的权重值都增加了,排序也发生了变化。
说明通过“提重”——重复多次某些关键词权重值的方式可使部分数据权重值增加,进而影响排序。
------------------------------------------------------------------------------------------------------------------------------
▶ 实验11:同时对 title_fc 和 content_fc 两字段做全文检索
SELECT *,MATCH (title_fc) AGAINST ('optimizing ok red blue') as title_score,MATCH (content_fc) AGAINST ('optimizing ok red blue') as content_score
FROM zzx_articles
WHERE MATCH (title_fc,content_fc) AGAINST ('optimizing ok red blue' IN BOOLEAN MODE) order by title_score DESC,content_score DESC

总结:通过实验发现,又成功的取到了 content_fc 字段匹配的权重值,排序方式是首要按title字段权重降序排序,次要按 content_fc 权重降序排序。
另外我发现 ok 这个关键词在对“title_fc char(254)”字段匹配时得到匹配值为2.1xxxxxxx,但对“content_fc text”字段匹配时权重值去为0,
这是MySQL对各英文单词权重值的给予有自己的算法,我们无权干涉。所以当我们发现有些单词的权重值为零甚至为负时,不用过于纠结,
因为MySQL有自己的算法。
关于排序,首要按 title_score 字段权重降序排序,次要按 content_score 权重降序排序,这样的排序规则看起来更科学了,但我想优秀的搜索引擎绝不至于简单如此吧,继续下面的实验:
------------------------------------------------------------------------------------------------------------------------------
▶ 实验12:进一步优化 排序规则
看一个SQL语句原型,查询“字段1,字段2”两字段,同时将每条数据的“字段1”与“字段2”的求和作为“字段3”字段:
select 字段1,字段2,字段1 + 字段2 as 字段3
from 表名
where .....
下面将 title_fc 和 content_fc 两权重值求和,放入新字段 score1 中,并按 score1 首要排序,title_score 次之,content_score再次之:
SELECT *,MATCH (title_fc) AGAINST ('optimizing ok red blue') as title_score,MATCH (content_fc) AGAINST ('optimizing ok red blue') as content_score,MATCH (title_fc) AGAINST ('optimizing ok red blue') + MATCH (content_fc) AGAINST ('optimizing ok red blue') as score1
FROM zzx_articles
WHERE MATCH (title_fc,content_fc) AGAINST ('optimizing ok red blue' IN BOOLEAN MODE) order by score1 DESC,title_score DESC,content_score DESC

总结:相对而言,如果 title_fc 和 content_fc 都匹配上了,应给予靠前的排名吧。所以首要按其 title_fc 和 content_fc 两权重值之和排名,
次要再考虑 title_fc、content_fc 排序。
------------------------------------------------------------------------------------------------------------------------------
▶ 实验13:另一个角度看排序
看一个SQL语句原型,如果性别字段值为“1”显示“男”否则显示“女”
select *,IF(sex=1,"男","女") as ssva from 表名 where id = 1
我的新排序思路:如果 title_fc 和 content_fc 同时匹配上的行做首要排序,然后对只匹配上 title_fc 的做次要排序,只匹配上 content_fc 的再次要排序。 (对于实验5的排序不科学之处在于:如果有一个对content_fc关键词的匹配权重很高,导致了求和后 score1 的值也高,但对title_fc的匹配权重去为0,由于score1值高却排到了前面这不一定科学吧?)
SELECT *,MATCH (title_fc) AGAINST ('optimizing ok red blue') as title_score,MATCH (content_fc) AGAINST ('optimizing ok red blue') as content_score,IF(MATCH (title_fc) AGAINST ('optimizing ok red blue') > 0 AND MATCH (content_fc) AGAINST ('optimizing ok red blue') > 0,1,0) as score1
FROM zzx_articles
WHERE MATCH (title_fc,content_fc) AGAINST ('optimizing ok red blue' IN BOOLEAN MODE) order by score1 DESC,title_score DESC,content_score DESC

总结:如果 title_fc 和 content_fc 都匹配上了,做为优先排序理所当然,但也应考虑局部权重值过高的问题哦。
------------------------------------------------------------------------------------------------------------------------------
▶ 实验14:优化实验13,可支持更复杂的条件排序
看一个SQL语句原型,CASE WHEN THEN END 结构:
CASE <单值表达式>
WHEN <表达式值> THEN <SQL语句或者返回值>
WHEN <表达式值> THEN <SQL语句或者返回值>
...
WHEN <表达式值> THEN <SQL语句或者返回值>
ELSE <SQL语句或者返回值>
END
有一表查询:大于或等于80表示显示为“优秀”,大于或等于60显示为“及格”,小于60分显示为“不及格”。
select (CASE WHEN 语文>=80 THEN '优秀' WHEN 语文>=60 THEN '及格' ELSE '不及格' END) as 语文,
(CASE WHEN 数学>=80 THEN '优秀' WHEN 数学>=60 THEN '及格' ELSE '不及格' END) as 数学,
(CASE WHEN 英语>=80 THEN '优秀' WHEN 英语>=60 THEN '及格' ELSE '不及格' END) as 英语
from table_name
# 实例测试一下
select *,(CASE WHEN id<8 THEN '5' WHEN id=8 THEN '4' ELSE '0' END) as newfield
from zzx_articles
where id>5
我的新排序思路:如果 title_fc 和 content_fc 的权重值“同时大于0且相等”为首要排序,“同时大于0且不相等”的为次要排序,
“title_fc 大于0的再次要排序”,如果用 IF() 貌似不好实现,看下面语句:
SELECT *,MATCH (title_fc) AGAINST ('optimizing ok red blue') as title_score,MATCH (content_fc) AGAINST ('optimizing ok red blue') as content_score,
(CASE WHEN MATCH (title_fc) AGAINST ('optimizing ok red blue') > 0 AND MATCH (title_fc) AGAINST ('optimizing ok red blue') = MATCH (content_fc) AGAINST ('optimizing ok red blue') THEN '3' WHEN MATCH (title_fc) AGAINST ('optimizing ok red blue') > 0 AND MATCH (title_fc) AGAINST ('optimizing ok red blue') <> MATCH (content_fc) AGAINST ('optimizing ok red blue') THEN '2' WHEN MATCH (title_fc) AGAINST ('optimizing ok red blue') > 0 THEN '1' ELSE '0' END) AS score1
FROM zzx_articles
WHERE MATCH (title_fc,content_fc) AGAINST ('optimizing ok red blue' IN BOOLEAN MODE) order by score1 DESC,title_score DESC,content_score DESC

总结:本实验的排序未必合乎科学,但引出一个更复杂规则的排序方式、角度,多种排序结合使用才能做出更合理的排序,才能使你的搜索引擎更加智能。抛砖引玉,或许你有更好的排序,请也分享给我。
------------------------------------------------------------------------------------------------------------------------------
▶ 实验15:中文全文检索
MySQL不支持中文全文检索,因为中文一句话是连着写的,不像英文单词间有空格分隔。解决办法就是中文分词(关于中文分词请参阅其它文章),
如果你的MySQL是安装在Windows平台上的,可以不用转码直接存储中文就可以使用全文索引,如本例。但是如果你的MySQL是安装在Linux上的则需要进行转编码(urlencode / base64_encode / json_encode / 区位 / 拼音)等方案,具体方案参看其它博文。
SELECT *,MATCH (title_fc) AGAINST ('中华 北京 和谐 security') as title_score,MATCH (content_fc) AGAINST ('中华 北京 和谐 security') as content_score,(case when MATCH (title_fc) AGAINST ('中华 北京 和谐 security') > 0 and MATCH (content_fc) AGAINST ('中华 北京 和谐 security') > 0 then '5' when MATCH (title_fc) AGAINST ('中华 北京 和谐 security') > 0 and MATCH (content_fc) AGAINST ('中华 北京 和谐 security') = 0 then '4' else '0' end) as score1
FROM zzx_articles
WHERE MATCH (title_fc,content_fc) AGAINST ('中华 北京 和谐 security' IN BOOLEAN MODE) order by score1 DESC,title_score DESC,content_score DESC

MySQL中文全文检索demoSQL的更多相关文章
- MySQL中文全文检索
一.概述 MySQL全文检索是利用查询关键字和查询列内容之间的相关度进行检索,可以利用全文索引来提高匹配的速度. 二.语法 MATCH (col1,col2,...) AGAINS ...
- MySQL 5.7 中文全文检索
MySQL 5.7 中文全文检索 在 MySQL 5.7.6 之前,全文索引只支持英文全文索引,不支持中文全文索引,需要利用分词器把中文段落预处理拆分成单词,然后存入数据库.从 MySQL 5.7.6 ...
- MySQL中文全文索引插件 mysqlcft 1.0.0 安装使用文档[原创]
[文章+程序 作者:张宴 本文版本:v1.0 最后修改:2008.07.01 转载请注明原文链接:http://blog.zyan.cc/post/356/] MySQL在高并发连接.数据库记录数较多 ...
- mysql中文进行全文索引支持问题
先来看看对一个字段做全文索引,作为一个数据库系统需要做哪些工作? 假设一个文章表里面包含几个字段:文章id.文章作者.文章标题.文章内容 比如,我们对文章内容这个字段artilce_content建立 ...
- Sphinx在windows下安装使用[支持中文全文检索]
原文地址:http://www.fuchaoqun.com/2008/11/sphinx-on-windows-xp/ 前 一阵子尝试使用了一下Sphinx,一个能够被各种语言(PHP/Python/ ...
- 解决springmvc+mybatis+mysql中文乱码问题【转】
这篇文章主要介绍了解决java中springmvc+mybatis+mysql中文乱码问题的相关资料,需要的朋友可以参考下 近日使用ajax请求springmvc后台查询mysql数据库,页面显示中文 ...
- 总结--解决 mysql 中文乱码
首先分析一下导致mysql 中文乱码的原因: 1.建表时使用了latin 编码 2.连接数据库的编码没有指定 3.写入时就已经乱码(这种情况需要自己检查源数据了) 解决方法总结: 1.创建库时指定编码 ...
- Servlet、MySQL中文乱码
1.Servlet中文乱码: 在doPost或doGet方法里,加上以下两行即可: response.setContentType("text/html;charset=UTF-8" ...
- php mysql 中文乱码解决方法
本文章向码农们介绍php mysql 中文乱码解决方法,对码农们非常实用,需要的码农可以参考一下. 从MySQL 4.1开始引入多语言的支持,但是用PHP插入的中文会出现乱码.无论用什么编码也不行 解 ...
随机推荐
- [备忘]Windows Server 2008 R2部署FTP FileZilla Server防火墙设置
有一台服务器,之前文件迁移少,现准备用FileZilla Server当FTP服务器,服务器系统是Windows Server 2008 R2,同样适用FileZilla Client连接服务器FTP ...
- HIVE简介及安装
一.简介 百度百科HIVE定义: hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运 ...
- Docker 快速入门教程
本文目的是给几乎从未接触过docker,或者仅仅是听说或者通过新闻了解过Docker的同学 通过一个已有的Docker仓库构建和提交自己的Docker 镜像 这里会涉及到一些概念,但是不单独介绍 这里 ...
- Spring Task中的定时任务无法注入service的解决办法
1.问题 因一个项目(使用的是Spring+SpringMVC+hibernate框架)需要在spring task定时任务中调用数据库操作,在使用 @Autowired注入service时后台报错, ...
- 学习使用Git 版本控制 代码管理
title: 学习使用Git 版本控制 代码管理 notebook: 经验累积 tags:Git --- Git 版本控制 学习教程 Git版本控制器,可以作为程序员.计算机科学和软件工程的研究人员在 ...
- 算法笔记(c++)--c++中碰到的一些用法
算法笔记(c++)--c++中碰到的一些用法 toupper(xxx)可以变成大写; tolower(xx)小写 isalpha(xxx)判断是不是字母 isalnum(xx)判断是不是数字 abs( ...
- eBay:美国各州最受欢迎的产品品类
雨果网从美国媒体<商业内幕>8月26日的报道中获悉,电商巨头eBay近日发布了美国各州最受欢迎的产品品类.包括:加州人青睐女性高端配件,而新泽西 州的男人喜欢古龙香水.相比这些华丽配饰而言 ...
- HTML5+Bootstrap 学习笔记 2
navbar升级 从Bootstrap 2到Bootstrap 3 1. .navbar-inner已从Bootstrap 3中去除. 2. <ul class="nav"& ...
- 利用box-shadow制作loading图
我们见过很多利用css3做的loading图,像下面这种应该是很常见的.通常制作这种loading,我们会一个标签对应一个圆,八个圆就要八个标签.但是这种做法很浪费资源.我们可以只用一个标签,然后利用 ...
- JS 操作 checkbox(cc角色管理等)
1.获取选中的权限的个数 var size=$("input[name='privileges']:checked").size();