hadoop ——HDFS存储
一、HDFS概念
HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开发的,可以运行于廉价的商用服务器上。它所具有的高容错、高可靠性、高可扩展性、高获得性、高吞吐率等特征为海量数据提供了不怕故障的存储,为超大数据集(Large Data Set)的应用处理带来了很多便利。
hadoop前提和设计目标:
- 硬件错误是常态
- 数据的批处理而不是数据与用户的交互,从而提升数据的高吞吐量
- 大规模数据集,存储大文件和非常多个单个文件
- 满足一次写入多次使用
- 移动计算比移动数据更划算
- 异构软硬件的可可移植性
二、HDFS优缺点
1、高容错性
- 数据自动保存多个副本。它通过增加副本的形式,提高容错性。
- 某一个副本丢失以后,它可以自动恢复,这是由 HDFS内部机制实现的,我们不必关心。
2、适合批处理
- 它是通过移动计算而不是移动数据。
- 它会把数据位置暴露给计算框架。
3、适合大数据处理
- 处理数据达到 GB、TB、甚至PB级别的数据。
- 能够处理百万规模以上的文件数量,数量相当之大。
- 能够处理10K节点的规模。
4、流式文件访问
- 一次写入,多次读取。文件一旦写入不能修改,只能追加。
- 它能保证数据的一致性。
5、可构建在廉价机器上
- 它通过多副本机制,提高可靠性。
- 它提供了容错和恢复机制。比如某一个副本丢失,可以通过其它副本来恢复。
当然 HDFS 也有它的劣势,并不适合所有的场合:
1、低延时数据访问
- 比如毫秒级的来存储数据,这是不行的,它做不到。
- 它适合高吞吐率的场景,就是在某一时间内写入大量的数据。但是它在低延时的情况下是不行的,比如毫秒级以内读取数据,这样它是很难做到的。
2、小文件存储
- 存储大量小文件(这里的小文件是指小于HDFS系统的Block大小的文件(默认64M))的话,它会占用 NameNode大量的内存来存储文件、目录和块信息。这样是不可取的,因为NameNode的内存总是有限的。
- 小文件存储的寻道时间会超过读取时间,它违反了HDFS的设计目标。
3、并发写入、文件随机修改 - 一个文件只能有一个写,不允许多个线程同时写。
- 仅支持数据 append(追加),不支持文件的随机修改。
四、HDFS如何存储
HDFS的架构图:
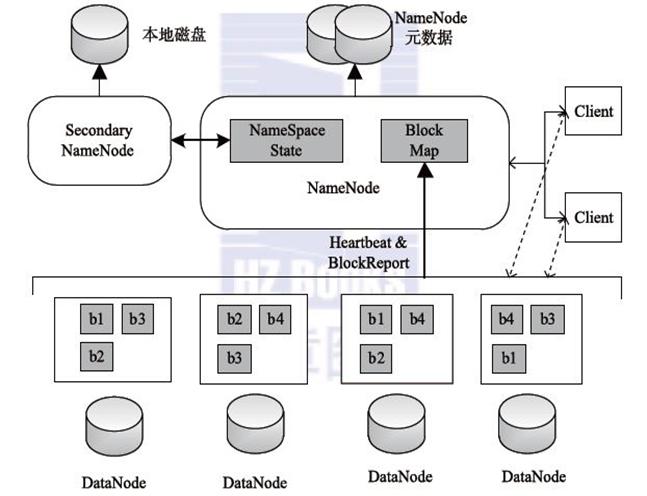
HDFS 采用Master/Slave的架构来存储数据,这种架构主要由四个部分组成,分别为HDFS Client、NameNode、DataNode和Secondary NameNode。下面我们分别介绍这四个组成部分:
1、Client:就是客户端。
- 文件切分。文件上传 HDFS 的时候,Client 将文件切分成 一个一个的Block,然后进行存储。
- 与 NameNode 交互,获取文件的位置信息。
- 与 DataNode 交互,读取或者写入数据。
- Client 提供一些命令来管理 HDFS,比如启动或者关闭HDFS。
- Client 可以通过一些命令来访问 HDFS。
2、NameNode:就是 master,它是一个主管、管理者。
- 管理 HDFS 的名称空间
- 管理数据块(Block)映射信息
- 配置副本策略
- 处理客户端读写请求。
3、DataNode:就是Slave。NameNode 下达命令,DataNode 执行实际的操作。
- 存储实际的数据块。
- 执行数据块的读/写操作。
4、Secondary NameNode:并非 NameNode 的热备。当NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。
- 辅助 NameNode,分担其工作量。
- 定期合并 fsimage和fsedits,并推送给NameNode。
- 在紧急情况下,可辅助恢复 NameNode。
HDFS 如何读取文件
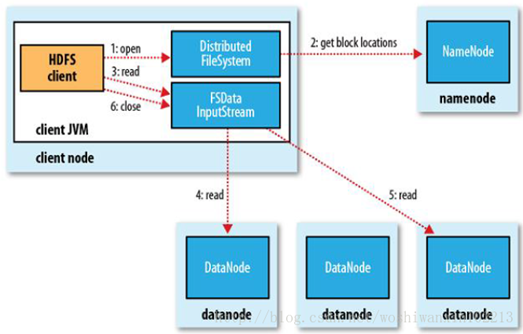
HDFS的文件读取原理,主要包括以下几个步骤:
- 首先调用FileSystem对象的open方法,其实获取的是一个DistributedFileSystem的实例。
- DistributedFileSystem通过RPC(远程过程调用)获得文件的第一批block的locations,同一block按照重复数会返回多个locations,这些locations按照hadoop拓扑结构排序,距离客户端近的排在前面。
- 前两步会返回一个FSDataInputStream对象,该对象会被封装成 DFSInputStream对象,DFSInputStream可以方便的管理datanode和namenode数据流。客户端调用read方法,DFSInputStream就会找出离客户端最近的datanode并连接datanode。
- 数据从datanode源源不断的流向客户端。
- 如果第一个block块的数据读完了,就会关闭指向第一个block块的datanode连接,接着读取下一个block块。这些操作对客户端来说是透明的,从客户端的角度来看只是读一个持续不断的流。
- 如果第一批block都读完了,DFSInputStream就会去namenode拿下一批blocks的location,然后继续读,如果所有的block块都读完,这时就会关闭掉所有的流。
HDFS 如何写入文件
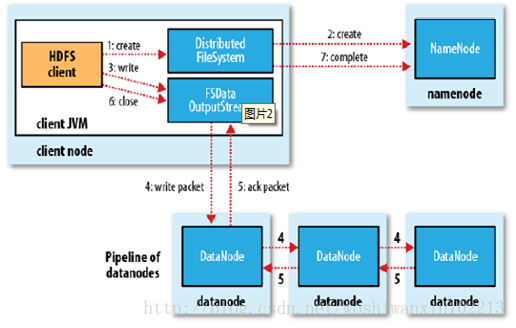
HDFS的文件写入原理,主要包括以下几个步骤:
- 客户端通过调用 DistributedFileSystem 的create方法,创建一个新的文件。
- DistributedFileSystem 通过 RPC(远程过程调用)调用 NameNode,去创建一个没有blocks关联的新文件。创建前,NameNode 会做各种校验,比如文件是否存在,客户端有无权限去创建等。如果校验通过,NameNode 就会记录下新文件,否则就会抛出IO异常。
- 前两步结束后会返回 FSDataOutputStream 的对象,和读文件的时候相似,FSDataOutputStream 被封装成 DFSOutputStream,DFSOutputStream 可以协调 NameNode和 DataNode。客户端开始写数据到DFSOutputStream,DFSOutputStream会把数据切成一个个小packet,然后排成队列 data queue。
- DataStreamer 会去处理接受 data queue,它先问询 NameNode 这个新的 block 最适合存储的在哪几个DataNode里,比如重复数是3,那么就找到3个最适合的 DataNode,把它们排成一个 pipeline。DataStreamer 把 packet 按队列输出到管道的第一个 DataNode 中,第一个 DataNode又把 packet 输出到第二个 DataNode 中,以此类推。
- DFSOutputStream 还有一个队列叫 ack queue,也是由 packet 组成,等待DataNode的收到响应,当pipeline中的所有DataNode都表示已经收到的时候,这时akc queue才会把对应的packet包移除掉。
- 客户端完成写数据后,调用close方法关闭写入流。
- DataStreamer 把剩余的包都刷到 pipeline 里,然后等待 ack 信息,收到最后一个 ack 后,通知 DataNode 把文件标示为已完成。
数据的复制
数据复制,hadoop默认为复制三份,一个DataNode存储两份,另一个DataNode存储一个。Namenode管理这些复制的位置,并且监听每个DataNode,如果dataNode宕机了,namenode就能够监听到,并后续的存储不会存储到该DataNode,并且计算每个副本的数量,如果副本的数量低于一个阈值时,这启动复制程序。
数据的复制,是Namenode先讲文件存储到临时文件中,直到该临时文件达到预先设置的大小块,则将该文件复制到一个DataNode,复制完成后继续下一个节点复制。
数据删除
文件的恢复与删除,文件删除后,不是直接删除,而是将数据放置到如window时垃圾站内,hadoop将删除的数据放置于/trash目录下,有一个过期时间,到时间了,就会将数据从/trash目录中删除,之后文件永久在hadoop消失,不可恢复。存储在/trash文件也可以恢复。
hadoop ——HDFS存储的更多相关文章
- 使用python来访问Hadoop HDFS存储实现文件的操作
原文:http://rfyiamcool.blog.51cto.com/1030776/1258292 在调试环境下,咱们用hadoop提供的shell接口测试增加删除查看,但是不利于复杂的逻辑编程 ...
- 从 RAID 到 Hadoop Hdfs 『大数据存储的进化史』
我们都知道现在大数据存储用的基本都是 Hadoop Hdfs ,但在 Hadoop 诞生之前,我们都是如何存储大量数据的呢?这次我们不聊技术架构什么的,而是从技术演化的角度来看看 Hadoop Hdf ...
- Hadoop hdfs副本存储和纠删码(Erasure Coding)存储优缺点
body { margin: 0 auto; font: 13px / 1 Helvetica, Arial, sans-serif; color: rgba(68, 68, 68, 1); padd ...
- Hadoop HDFS 用户指南
This document is a starting point for users working with Hadoop Distributed File System (HDFS) eithe ...
- Hadoop HDFS负载均衡
Hadoop HDFS负载均衡 转载请注明出处:http://www.cnblogs.com/BYRans/ Hadoop HDFS Hadoop 分布式文件系统(Hadoop Distributed ...
- 用hdfs存储海量的视频数据的设计思路
用hdfs存储海量的视频数据 存储海量的视频数据,主要考虑两个因素:如何接收视频数据和如何存储视频数据. 我们要根据数据block在集群上的位置分配计算量,要充分利用带宽的优势. 1.接收视频数据 将 ...
- Hadoop HDFS分布式文件系统设计要点与架构
Hadoop HDFS分布式文件系统设计要点与架构 Hadoop简介:一个分布式系统基础架构,由Apache基金会开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群 ...
- hadoop hdfs ha 模式
这是我自己在公司一个搭建公司大数据框架是自己的选项,在配置yarn ha 出现了nodemanager起不来的问题于是我把yarn搭建为普通yarn 如果有人解决 高yarn的nodemanager问 ...
- 大数据 - hadoop - HDFS+Zookeeper实现高可用
高可用(Hign Availability,HA) 一.概念 作用:用于解决负载均衡和故障转移(Failover)问题. 问题描述:一个NameNode挂掉,如何启动另一个NameNode.怎样让两个 ...
随机推荐
- Reverting back to the R12.1.1 and R12.1.3 Homepage Layout
Reverting back to the 12.1.1 Homepage Layout Set the following profiles: FND: Applications Navigator ...
- [翻译] FastReport Class Hierarchy (FastReport 组件类层次结构)
"TfrxComponent" is the base class for all FastReport components. Objects of this type have ...
- Python学习-13.Python的输入输出(二)
在Python中,读取文件使用open函数 file=open(r'E:\temp\test.txt','r') var = file.read() print(var) file.close() 第 ...
- EAS 最大单据号获取
BaseService using System; using System.Collections.Generic; using System.Linq; using System.Text; us ...
- C#用 catch 捕获异类的常用类型
C#用 catch 捕获异类的常用类型 最近在书上刚刚学到了try和catch用法,然后网上找了下常用的,自己存在这里方便自己查找 Exception 类 描述 SystemException 其他 ...
- Kafka与.net core(三)kafka操作
1.Kafka相关知识 Broker:即Kafka的服务器,用户存储消息,Kafa集群中的一台或多台服务器统称为broker. Message消息:是通信的基本单位,每个 producer 可以向一个 ...
- Winfrom PictureBox 设置图片自适应
初始状态 Bitmap bm = new Bitmap(Image.FromStream(System.Net.WebRequest.Create(new Uri(result.Result)).Ge ...
- [UWP]xaml中自定义附加属性使用方法的注意项
---恢复内容开始--- 随笔小记,欢迎指正 在UWP平台上做WVVM的时候,想针对ListBox的SelectionChanged事件定义一个自定义的命令,于是使用自定义附加属性的方式.可是最后自定 ...
- java学习笔记—Tomcat(9)
1 目录结构 bin 二进制目录,主要存储的是一些启动和停止服务器的命令startup.bat conf 配置目录,server.xml web.xml lib 服务器软件使用的第三方的j ...
- 深入了解java虚拟机(JVM) 第七章 内存分配策略
理解了jvm内存分配策略不仅是程序性能调优的重要知识,还能够给养成自己一种良好的代码思路,一个程序的代码差异往往都是在这里体现出来的. 一.对象优先分配到Eden区域 一般来说,新创建的对象都会直 ...