大数据学习之Hadoop快速入门
1、Hadoop生态概况
Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠、高效、可伸缩的特点。
大数据学习资料分享群119599574
Hadoop的核心是YARN,HDFS,Mapreduce,常用模块架构如下
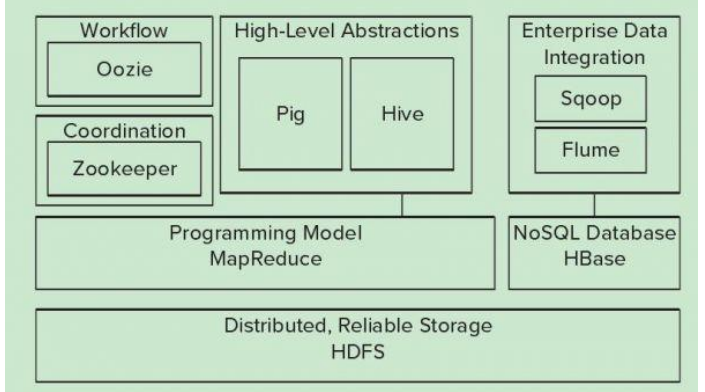
2、HDFS
源自谷歌的GFS论文,发表于2013年10月,HDFS是GFS的克隆版,HDFS是Hadoop体系中数据存储管理的基础,它是一个高度容错的系统,能检测和应对硬件故障
HDFS简化了文件一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序,它提供了一次写入多次读取的机制,数据以块的形式,同时分布在集群不同物理机器
3、Mapreduce
源自于谷歌的MapReduce论文,用以进行大数据量的计算,它屏蔽了分布式计算框架细节,将计算抽象成map和reduce两部分
4、HBASE(分布式列存数据库)
源自谷歌的Bigtable论文,是一个建立在HDFS之上,面向列的针对结构化的数据可伸缩,高可靠,高性能分布式和面向列的动态模式数据库
5、zookeeper
解决分布式环境下数据管理问题,统一命名,状态同步,集群管理,配置同步等
6、HIVE
由Facebook开源,定义了一种类似sql查询语言,将SQL转化为mapreduce任务在Hadoop上面执行
7、flume
日志收集工具
8、yarn分布式资源管理器
是下一代mapreduce,主要解决原始的Hadoop扩展性较差,不支持多种计算框架而提出的,架构如下
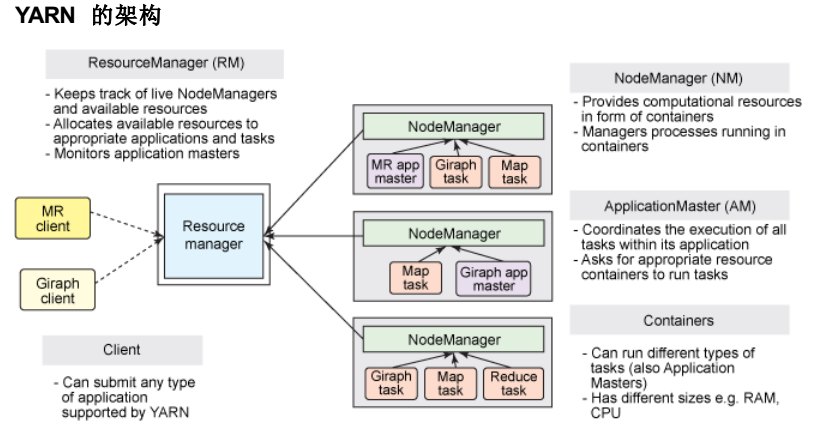 9、spark
9、spark
spark提供了一个更快更通用的数据处理平台,和Hadoop相比,spark可以让你的程序在内存中运行
大数据学习资料分享群119599574
10、kafka
分布式消息队列,主要用于处理活跃的流式数据
11、Hadoop伪分布式部署
目前而言,不收费的Hadoop版本主要有三个,都是国外厂商,分别是
1、Apache原始版本
2、CDH版本,对于国内用户而言,绝大多数选择该版本
3、HDP版本
这里我们选择CDH版本hadoop-2.6.0-cdh5.8.2.tar.gz,环境是centos7.1,jdk需要1.7.0_55以上
[root@hadoop1 ~]# useradd hadoop
我的系统默认自带的java环境如下
- [root@hadoop1 ~]# ll /usr/lib/jvm/
- total 12
- lrwxrwxrwx. 1 root root 26 Oct 27 22:48 java -> /etc/alternatives/java_sdk
- lrwxrwxrwx. 1 root root 32 Oct 27 22:48 java-1.6.0 -> /etc/alternatives/java_sdk_1.6.0
- drwxr-xr-x. 7 root root 4096 Oct 27 22:48 java-1.6.0-openjdk-1.6.0.34.x86_64
- lrwxrwxrwx. 1 root root 34 Oct 27 22:48 java-1.6.0-openjdk.x86_64 -> java-1.6.0-openjdk-1.6.0.34.x86_64
- lrwxrwxrwx. 1 root root 32 Oct 27 22:44 java-1.7.0 -> /etc/alternatives/java_sdk_1.7.0
- lrwxrwxrwx. 1 root root 40 Oct 27 22:44 java-1.7.0-openjdk -> /etc/alternatives/java_sdk_1.7.0_openjdk
- drwxr-xr-x. 8 root root 4096 Oct 27 22:44 java-1.7.0-openjdk-1.7.0.75-2.5.4.2.el7_0.x86_64
- lrwxrwxrwx. 1 root root 32 Oct 27 22:44 java-1.8.0 -> /etc/alternatives/java_sdk_1.8.0
- lrwxrwxrwx. 1 root root 40 Oct 27 22:44 java-1.8.0-openjdk -> /etc/alternatives/java_sdk_1.8.0_openjdk
- drwxr-xr-x. 7 root root 4096 Oct 27 22:44 java-1.8.0-openjdk-1.8.0.31-2.b13.el7.x86_64
- lrwxrwxrwx. 1 root root 34 Oct 27 22:48 java-openjdk -> /etc/alternatives/java_sdk_openjdk
- lrwxrwxrwx. 1 root root 21 Oct 27 22:44 jre -> /etc/alternatives/jre
- lrwxrwxrwx. 1 root root 27 Oct 27 22:44 jre-1.6.0 -> /etc/alternatives/jre_1.6.0
- lrwxrwxrwx. 1 root root 38 Oct 27 22:44 jre-1.6.0-openjdk.x86_64 -> java-1.6.0-openjdk-1.6.0.34.x86_64/jre
- lrwxrwxrwx. 1 root root 27 Oct 27 22:44 jre-1.7.0 -> /etc/alternatives/jre_1.7.0
- lrwxrwxrwx. 1 root root 35 Oct 27 22:44 jre-1.7.0-openjdk -> /etc/alternatives/jre_1.7.0_openjdk
- lrwxrwxrwx. 1 root root 52 Oct 27 22:44 jre-1.7.0-openjdk-1.7.0.75-2.5.4.2.el7_0.x86_64 -> java-1.7.0-openjdk-1.7.0.75-2.5.4.2.el7_0.x86_64/jre
- lrwxrwxrwx. 1 root root 27 Oct 27 22:44 jre-1.8.0 -> /etc/alternatives/jre_1.8.0
- lrwxrwxrwx. 1 root root 35 Oct 27 22:44 jre-1.8.0-openjdk -> /etc/alternatives/jre_1.8.0_openjdk
- lrwxrwxrwx. 1 root root 48 Oct 27 22:44 jre-1.8.0-openjdk-1.8.0.31-2.b13.el7.x86_64 -> java-1.8.0-openjdk-1.8.0.31-2.b13.el7.x86_64/jre
- lrwxrwxrwx. 1 root root 29 Oct 27 22:44 jre-openjdk -> /etc/alternatives/jre_openjdk
[root@hadoop1 ~]# cat /home/hadoop/.bashrc 增加如下环境变量
- export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.75-2.5.4.2.el7_0.x86_64
- export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
- export PATH=$PATH:$JAVA_HOME/bin
- export HADOOP_PREFIX=/opt/hadoop/current
- export HADOOP_MAPRED_HOME=${HADOOP_PREFIX}
- export HADOOP_COMMON_HOME=${HADOOP_PREFIX}
- export HADOOP_HDFS_HOME=${HADOOP_PREFIX}
- export HADOOP_YARN_HOME=${HADOOP_PREFIX}
- export HTTPS_CATALINA_HOME=${HADOOP_PREFIX}/share/hadoop/httpfs/tomcat
- export HADOOP_CONF_DIR=/etc/hadoop/conf
- export YARN_CONF_DIR=/etc/hadoop/conf
- export HTTPS_CONFIG=/etc/hadoop/conf
- export PATH=$PATH:$HADOOP_PREFIX/bin:$HADOOP_PREFIX/sbin
我们将Hadoop安装在/opt/hadoop目录下面,建立如下软连接,配置文件放在/etc/hadoop/conf目录下面
[root@hadoop1 hadoop]# ll current
lrwxrwxrwx 1 root root 21 Oct 29 11:02 current -> hadoop-2.6.0-cdh5.8.2
做好如下授权
[root@hadoop1 hadoop]# chown -R hadoop.hadoop hadoop-2.6.0-cdh5.8.2
[root@hadoop1 hadoop]# chown -R hadoop.hadoop /etc/hadoop/conf
CDH5新版本的Hadoop启动服务脚步位于$HADOOP_HOME/sbin目录下面,启动服务有如下
namenode
secondarynamenode
datanode
resourcemanger
nodemanager
这里以Hadoop用户来进行管理和启动Hadoop的各种服务
[root@hadoop1 etc]# cd /etc/hadoop/conf/
[root@hadoop1 conf]# vim core-site.xml
- <configuration>
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://hadoop1</value>
- </property>
- </configuration>
- 格式化namenode
- [root@hadoop1 conf]# cd /opt/hadoop/current/bin
- [root@hadoop1 bin]# hdfs namenode -format
- 启动namenode服务
- [root@hadoop1 bin]# cd /opt/hadoop/current/sbin/
- [root@hadoop1 sbin]# ./hadoop-daemon.sh start namenode
- [hadoop@hadoop1 sbin]$ ./hadoop-daemon.sh start datanode
查看服务启动情况
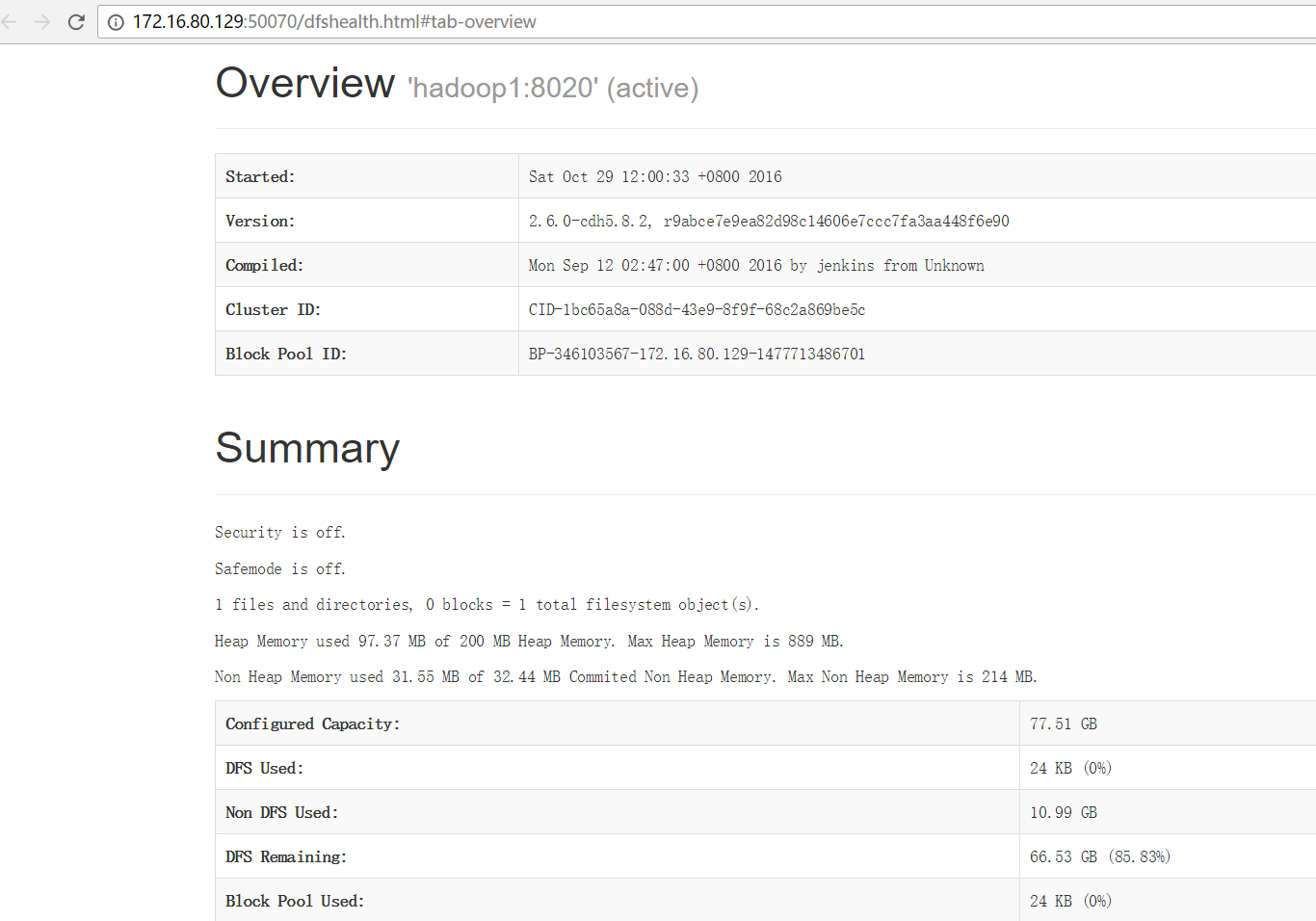
namenode启动完成后,就可以通过web界面查看状态了,默认端口是50070,我们访问测试下
大数据学习之Hadoop快速入门的更多相关文章
- 大数据学习笔记——Hadoop编程实战之HDFS
HDFS基本API的应用(包含IDEA的基本设置) 在上一篇博客中,本人详细地整理了如何从0搭建一个HA模式下的分布式Hadoop平台,那么,在上一篇的基础上,我们终于可以进行编程实操了,同样,在编程 ...
- 大数据学习笔记——Hadoop编程实战之Mapreduce
Hadoop编程实战——Mapreduce基本功能实现 此篇博客承接上一篇总结的HDFS编程实战,将会详细地对mapreduce的各种数据分析功能进行一个整理,由于实际工作中并不会过多地涉及原理,因此 ...
- 大数据学习之hadoop伪分布式集群安装(一)公众号undefined110
hadoop的基本概念: Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力进行高速运算和存储. Hadoo ...
- 大数据学习笔记——Hadoop编程之SequenceFile
SequenceFile(Hadoop序列文件)基础知识与应用 上篇编程实战系列中本人介绍了基本的使用HDFS进行文件读写的方法,这一篇将承接上篇重点整理一下SequenceFile的相关知识及应用 ...
- 大数据学习之Hadoop运行模式
一.Hadoop运行模式 (1)本地模式(默认模式): 不需要启用单独进程,直接可以运行,测试和开发时使用. (2)伪分布式模式: 等同于完全分布式,只有一个节点. (3)完全分布式模式: 多个节点一 ...
- 大数据学习之Hadoop环境搭建
一.Hadoop的优势 1)高可靠性:因为Hadoop假设计算元素和存储会出现故障,因为它维护多个工作数据副本,在出现故障时可以对失败的节点重新分布处理. 2)高扩展性:在集群间分配任务数据,可方便的 ...
- 大数据学习笔记——Hadoop高可用完全分布式模式完整部署教程(包含zookeeper)
高可用模式下的Hadoop集群搭建 本篇博客将会在之前写过的Linux的完整部署的基础上进行,暂时不会涉及到伪分布式或者完全分布式模式搭建,由于HA模式涉及到的配置文件较多,维护起来也较为复杂,相信学 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
随机推荐
- 如何在 Azure 虚拟机里配置条带化
什么是条带化(striping) 条带 (strip) 是把连续的数据分割成相同大小的数据块,把每段数据分别写入到阵列中的不同磁盘上的方法.简单的说,条带是一种将多个磁盘驱动器合并为一个卷的方法. 许 ...
- Delphi XE7功能之TMultiView
TMultView,做为一个TPanel来显示控件,可通过属性Mode来控制TMultView的显示效果,如下拉或者以抽屉方式.从屏一侧象抽屉一样显示TMultView,但不会转换主屏,也就是说在主窗 ...
- 如何查看SharePoint Server的版本信息
可以通过查看注册表来得你当前运行的是SharePoint 2010的哪个版本,具体步骤如下: 1. 登录到安装了SharePoint Central Administration 的服务器. 2. 点 ...
- 【解决方案】[XCUITest] WDA is not listening at 'http://localhost:8100/'
1. 使用Xcode 编译 WebDriver 发现端口为:serverurlhere->http://手机ip:0 <-serverurlhere 2. 解决方案: xcodebuild ...
- codeforces 808G Anthem of Berland
codeforces 808G Anthem of Berland 题面 给定\(s\)串和\(t\)串,字符集是小写字母.\(s\)串中有些位置的值不确定,要求你确定这些位置上的值,使得\(t\)在 ...
- java接口实例
1.开发系统时,主体架构使用接口,接口构成系统的骨架2.这样就可以通过更换接口的实现类来更换系统的实现 public class printerDemo{ public static void mai ...
- mvvm模型
- tcp的三次握手:通信的本质:通信通知与信息交换
tcp的三次握手:通信的本质:通信通知与信息交换
- Guava包学习---Bimap
Bimap也是Guava中提供的新集合类,别名叫做双向map,就是key->value,value->key,也就是你可以通过key定位value,也可以用value定位key. 这个场景 ...
- gluoncv 训练自己的数据集,进行目标检测
跑了一晚上的模型,实在占GPU资源,这两天已经有很多小朋友说我了.我选择了其中一个参数. https://github.com/dmlc/gluon-cv/blob/master/scripts/de ...