Stacking方法详解
集成学习方法主要分成三种:bagging,boosting 和 Stacking。这里主要介绍Stacking。
stacking严格来说并不是一种算法,而是精美而又复杂的,对模型集成的一种策略。
首先来看一张图。
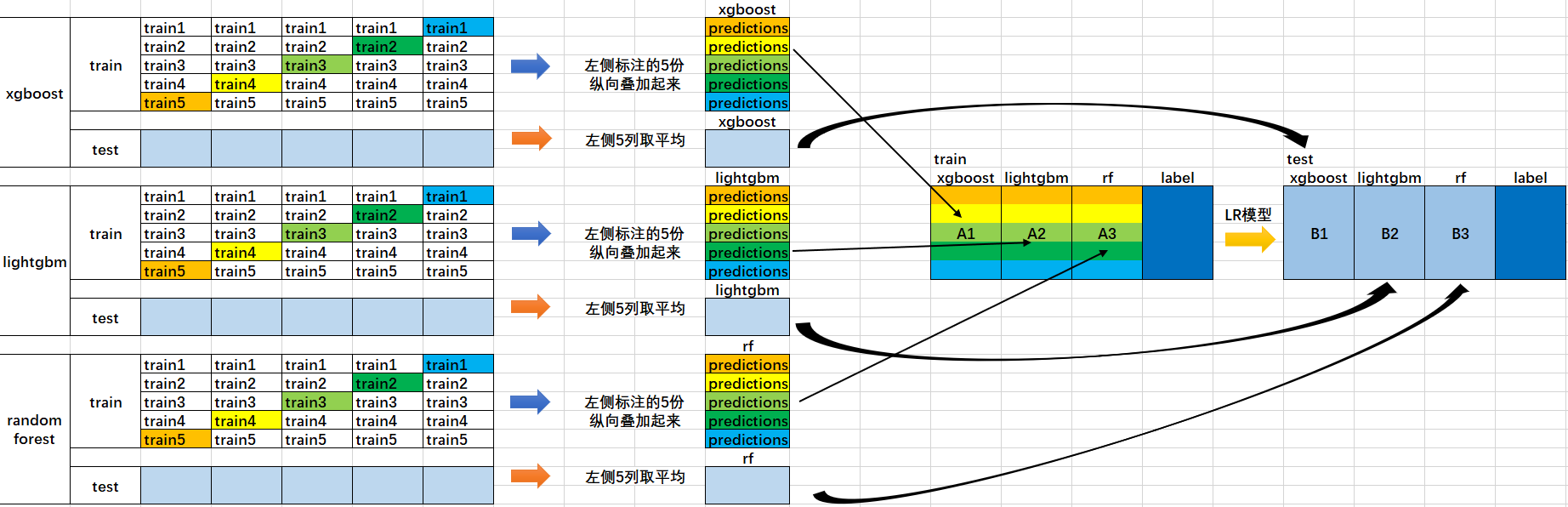
1、首先我们会得到两组数据:训练集和测试集。将训练集分成5份:train1,train2,train3,train4,train5。
2、选定基模型。这里假定我们选择了xgboost, lightgbm 和 randomforest 这三种作为基模型。比如xgboost模型部分:依次用train1,train2,train3,train4,train5作为验证集,其余4份作为训练集,进行5折交叉验证进行模型训练;再在测试集上进行预测。这样会得到在训练集上由xgboost模型训练出来的5份predictions,和在测试集上的1份预测值B1。将这五份纵向重叠合并起来得到A1。lightgbm和randomforest模型部分同理。
3、三个基模型训练完毕后,将三个模型在训练集上的预测值作为分别作为3个"特征"A1,A2,A3,使用LR模型进行训练,建立LR模型。
4、使用训练好的LR模型,在三个基模型之前在测试集上的预测值所构建的三个"特征"的值(B1,B2,B3)上,进行预测,得出最终的预测类别或概率。
做stacking,首先需要安装mlxtend库。安装方法:进入Anaconda Prompt,输入命令 pip install mlxtend 即可。
stacking主要有几种使用方法:
1、最基本的使用方法,即使用基分类器所产生的预测类别作为meta-classifier“特征”的输入数据
from sklearn import datasets iris = datasets.load_iris()
X, y = iris.data[:, 1:3], iris.target from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from xgboost.sklearn import XGBClassifier
import lightgbm as lgb
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import StackingClassifier
import numpy as np basemodel1 = XGBClassifier()
basemodel2 = lgb.LGBMClassifier()
basemodel3 = RandomForestClassifier(random_state=1) lr = LogisticRegression()
sclf = StackingClassifier(classifiers=[basemodel1, basemodel2, basemodel3],
meta_classifier=lr) print('5-fold cross validation:\n') for basemodel, label in zip([basemodel1, basemodel2, basemodel3, sclf],
['xgboost',
'lightgbm',
'Random Forest',
'StackingClassifier']): scores = model_selection.cross_val_score(basemodel,X, y,
cv=5, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]"
% (scores.mean(), scores.std(), label))
2、这一种是使用第一层所有基分类器所产生的类别概率值作为meta-classfier的输入。需要在StackingClassifier 中增加一个参数设置:use_probas = True。
另外,还有一个参数设置average_probas = True,那么这些基分类器所产出的概率值将按照列被平均,否则会拼接。
例如:
基分类器1:predictions=[0.2,0.2,0.7]
基分类器2:predictions=[0.4,0.3,0.8]
基分类器3:predictions=[0.1,0.4,0.6]
1)若use_probas = True,average_probas = True,
则产生的meta-feature 为:[0.233, 0.3, 0.7]
2)若use_probas = True,average_probas = False,
则产生的meta-feature 为:[0.2,0.2,0.7,0.4,0.3,0.8,0.1,0.4,0.6]
from sklearn import datasets iris = datasets.load_iris()
X, y = iris.data[:, 1:3], iris.target from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from xgboost.sklearn import XGBClassifier
import lightgbm as lgb
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import StackingClassifier
import numpy as np basemodel1 = XGBClassifier()
basemodel2 = lgb.LGBMClassifier()
basemodel3 = RandomForestClassifier(random_state=1)
lr = LogisticRegression()
sclf = StackingClassifier(classifiers=[basemodel1, basemodel2, basemodel3],
use_probas=True,
average_probas=False,
meta_classifier=lr) print('5-fold cross validation:\n') for basemodel, label in zip([basemodel1, basemodel2, basemodel3, sclf],
['xgboost',
'lightgbm',
'Random Forest',
'StackingClassifier']): scores = model_selection.cross_val_score(basemodel,X, y,
cv=5, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]"
% (scores.mean(), scores.std(), label))
3、这一种方法是对基分类器训练的特征维度进行操作的,并不是给每一个基分类器全部的特征,而是赋予不同的基分类器不同的特征。比如:基分类器1训练前半部分的特征,基分类器2训练后半部分的特征。这部分的操作是通过sklearn中的pipelines实现。最终通过StackingClassifier组合起来。
from sklearn.datasets import load_iris
from mlxtend.classifier import StackingClassifier
from mlxtend.feature_selection import ColumnSelector
from sklearn.pipeline import make_pipeline
from sklearn.linear_model import LogisticRegression
from xgboost.sklearn import XGBClassifier
from sklearn.ensemble import RandomForestClassifier iris = load_iris()
X = iris.data
y = iris.target
#基分类器1:xgboost
pipe1 = make_pipeline(ColumnSelector(cols=(0, 2)),
XGBClassifier())
#基分类器2:RandomForest
pipe2 = make_pipeline(ColumnSelector(cols=(1, 2, 3)),
RandomForestClassifier()) sclf = StackingClassifier(classifiers=[pipe1, pipe2],
meta_classifier=LogisticRegression()) sclf.fit(X, y)
StackingClassifier使用API和参数说明:
StackingClassifier(classifiers, meta_classifier, use_probas=False, average_probas=False, verbose=0, use_features_in_secondary=False)
verbose : int, optional (default=0)。用来控制使用过程中的日志输出,当 verbose = 0时,什么也不输出, verbose = 1,输出回归器的序号和名字。verbose = 2,输出详细的参数信息。verbose > 2, 自动将verbose设置为小于2的,verbose -2.
use_features_in_secondary : bool (default: False). 如果设置为True,那么最终的目标分类器就被基分类器产生的数据和最初的数据集同时训练。如果设置为False,最终的分类器只会使用基分类器产生的数据训练。

Stacking方法详解的更多相关文章
- 集成学习总结 & Stacking方法详解
http://blog.csdn.net/willduan1/article/details/73618677 集成学习主要分为 bagging, boosting 和 stacking方法.本文主要 ...
- session的使用方法详解
session的使用方法详解 Session是什么呢?简单来说就是服务器给客户端的一个编号.当一台WWW服务器运行时,可能有若干个用户浏览正在运正在这台服务器上的网站.当每个用户首次与这台WWW服务器 ...
- Kooboo CMS - Html.FrontHtml[Helper.cs] 各个方法详解
下面罗列了方法详解,每一个方法一篇文章. Kooboo CMS - @Html.FrontHtml().HtmlTitle() 详解 Kooboo CMS - Html.FrontHtml.Posit ...
- HTTP请求方法详解
HTTP请求方法详解 请求方法:指定了客户端想对指定的资源/服务器作何种操作 下面我们介绍HTTP/1.1中可用的请求方法: [GET:获取资源] GET方法用来请求已被URI识别的资源.指定 ...
- ecshop后台增加|添加商店设置选项和使用方法详解
有时候我们想在Ecshop后台做个设置.radio.checkbox 等等来控制页面的显示,看看Ecshop的设计,用到了shop_config这个商店设置功能 Ecshop后台增加|添加商店设置选项 ...
- (转)Spring JdbcTemplate 方法详解
Spring JdbcTemplate方法详解 文章来源:http://blog.csdn.net/dyllove98/article/details/7772463 JdbcTemplate主要提供 ...
- C++调用JAVA方法详解
C++调用JAVA方法详解 博客分类: 本文主要参考http://tech.ccidnet.com/art/1081/20050413/237901_1.html 上的文章. C++ ...
- windows.open()、close()方法详解
windows.open()方法详解: window.open(URL,name,features,replace)用于载入指定的URL到新的或已存在的窗口中,并返回代表新窗口的Win ...
- CURL使用方法详解
php采集神器CURL使用方法详解 作者:佚名 更新时间:2016-10-21 对于做过数据采集的人来说,cURL一定不会陌生.虽然在PHP中有file_get_contents函数可以获取远程 ...
随机推荐
- Eclipse去掉对jQuery的错误提示
1.I have found that I can leave the JavaScript Validator enable and ignore specific files by adding ...
- Oracle-11g-r2 实例囚笼(Instance Caging)配置
实例囚笼(Instance Caging)应用场合: 在单台多 CPU 的服务器上,经常出现同时运行多个数据库实例的情况,此方式有利于提高硬件的使用率. 但是多个数据库实例运行,将会互相争用服务器资源 ...
- jquery text() html() val()
test text() 返回 test html() 返回 test val() 没值, val() 适用于有value属性的元素, 例如: input
- Java Thread系列(一)线程创建
Java Thread系列(一)线程创建 Java 中创建线程主要有三种方式:继承 Thread.实现 Runnable 接口.使用 ExecutorService.Callable.Future 实 ...
- 数据备份——PHP
在大多数情况下,开发实在win下进行,因此,然系统每天自动备份数据这也是有必要的饿. Windows平台数据备份 创建批处理文件 在批处理文件中填写如下代码: D:\wamp64\bin\php\ph ...
- Flash的不同位宽与CPU地址线的接线问题?
一般Flash都有8.16.32等这些不同的位宽,当然说白了就是Flash的数据线位数. 在Flash与CPU的地址线的连接问题时:不同位宽的有不同的连接方法: 一般是:位宽为8时CPU的ADDR0与 ...
- jmeter 性能分析 (一点点加)
1.聚合报告 我们可以看到,通过这份报告我们就可以得到通常意义上性能测试所最关心的几个结果了. Samples -- 本次场景中一共完成了多少个Transaction Average -- 平均响应时 ...
- (简单的物理题)Bungee Jumping
链接: http://acm.hdu.edu.cn/showproblem.php?pid=1155 Time Limit: 2000/1000 MS (Java/Others) Memory ...
- VS中的Debug 和 Release 编译方式的本质区别
VS中的Debug 和 Release 编译方式的本质区别 Debug 通常称为调试版本,它包含调试信息,并且不作任何优化,便于程序员调试程序.Release 称为发布版本,它往往是进行了各种优化,使 ...
- [转]解决Mysql InnoDB: Failing assertion: ret || !assert_on_error问题
国庆回来后,发现mysql停止服务了,没办法继续启动了.查看日志,看到: 131008 09:56:03 mysqld_safe Starting mysqld daemon with databas ...