python16_day37【爬虫2】
一、异步非阻塞
1.自定义异步非阻塞
import socket
import select class Request(object):
def __init__(self,sock,func,url):
self.sock = sock
self.func = func
self.url = url def fileno(self):
return self.sock.fileno() def async_request(url_list): input_list = []
conn_list = [] for url in url_list:
client = socket.socket()
client.setblocking(False)
# 创建连接,不阻塞
try:
client.connect((url[],,)) # 100个向百度发送的请求
except BlockingIOError as e:
pass obj = Request(client,url[],url[]) input_list.append(obj)
conn_list.append(obj) while True:
# 监听socket是否已经发生变化 [request_obj,request_obj....request_obj]
# 如果有请求连接成功:wlist = [request_obj,request_obj]
# 如果有响应的数据: rlist = [request_obj,request_obj....client100]
rlist,wlist,elist = select.select(input_list,conn_list,[],0.05)
for request_obj in wlist:
# print('连接成功')
# # # # 发送Http请求
# print('发送请求')
request_obj.sock.sendall("GET / HTTP/1.0\r\nhost:{0}\r\n\r\n".format(request_obj.url).encode('utf-8'))
conn_list.remove(request_obj) for request_obj in rlist:
data = request_obj.sock.recv()
request_obj.func(data)
request_obj.sock.close()
input_list.remove(request_obj) if not input_list:
break
2. 调用上面自定义模块
import s2 def callback1(data):
print('百度回来了',data) def callback2(data):
print('必应回来了',data) url_list = [
['www.baidu.com',callback1],
['www.bing.com',callback2]
]
s2.async_request(url_list) # ################################# twisted #################################
from twisted.web.client import getPage, defer
from twisted.internet import reactor def all_done(arg):
reactor.stop() def callback1(contents):
print(contents) def callback2(contents):
print(contents)
deferred_list = [] url_list = [
('http://www.bing.com',callback1),
('http://www.baidu.com',callback2)
]
for url in url_list:
deferred = getPage(bytes(url[0], encoding='utf8'))
deferred.addCallback(url[1])
deferred_list.append(deferred) dlist = defer.DeferredList(deferred_list)
dlist.addBoth(all_done)
二、scrapy
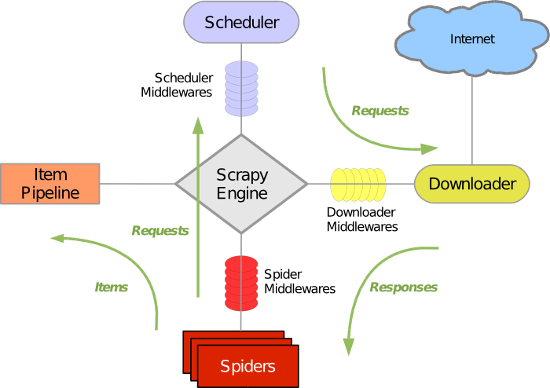
1. 安装
pip3 install scrapy
2. 基本命令
1. scrapy startproject p1
2. scrapy genspider chouti chouti.com
3. scrapy list
4. scrapy crawl chouti
3. 项目文件介绍
scrapy.cfg 项目的主配置信息。(真正爬虫相关的配置信息在settings.py文件中)
items.py 设置数据存储模板,用于结构化数据,如:Django的Model
pipelines 数据处理行为,如:一般结构化的数据持久化
settings.py 配置文件,如:递归的层数、并发数,延迟下载等
spiders 爬虫目录,如:创建文件,编写爬虫规则
4. 小试牛刀
import scrapy
from scrapy.selector import HtmlXPathSelector
from scrapy.http.request import Request class DigSpider(scrapy.Spider):
# 爬虫应用的名称,通过此名称启动爬虫命令
name = "dig" # 允许的域名
allowed_domains = ["chouti.com"] # 起始URL
start_urls = [
'http://dig.chouti.com/',
] has_request_set = {} def parse(self, response):
print(response.url) hxs = HtmlXPathSelector(response)
page_list = hxs.select('//div[@id="dig_lcpage"]//a[re:test(@href, "/all/hot/recent/\d+")]/@href').extract()
for page in page_list:
page_url = 'http://dig.chouti.com%s' % page
key = self.md5(page_url)
if key in self.has_request_set:
pass
else:
self.has_request_set[key] = page_url
obj = Request(url=page_url, method='GET', callback=self.parse)
yield obj @staticmethod
def md5(val):
import hashlib
ha = hashlib.md5()
ha.update(bytes(val, encoding='utf-8'))
key = ha.hexdigest()
return key
运行:scrapy crawl chouti.com --nolog
5. 选择器
from scrapy.selector import Selector, HtmlXPathSelector
from scrapy.http import HtmlResponse
html = """<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
</head>
<body>
<ul>
<li class="item-"><a id='i1' href="link.html">first item</a></li>
<li class="item-0"><a id='i2' href="llink.html">first item</a></li>
<li class="item-1"><a href="llink2.html">second item<span>vv</span></a></li>
</ul>
<div><a href="llink2.html">second item</a></div>
</body>
</html>
"""
response = HtmlResponse(url='http://example.com', body=html,encoding='utf-8')
# hxs = HtmlXPathSelector(response)
# print(hxs)
# hxs = Selector(response=response).xpath('//a')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[2]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[@id]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[@id="i1"]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[@href="link.html"][@id="i1"]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[contains(@href, "link")]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[starts-with(@href, "link")]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[re:test(@id, "i\d+")]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[re:test(@id, "i\d+")]/text()').extract()
# print(hxs)
# hxs = Selector(response=response).xpath('//a[re:test(@id, "i\d+")]/@href').extract()
# print(hxs)
# hxs = Selector(response=response).xpath('/html/body/ul/li/a/@href').extract()
# print(hxs)
# hxs = Selector(response=response).xpath('//body/ul/li/a/@href').extract_first()
# print(hxs) # ul_list = Selector(response=response).xpath('//body/ul/li')
# for item in ul_list:
# v = item.xpath('./a/span')
# # 或
# # v = item.xpath('a/span')
# # 或
# # v = item.xpath('*/a/span')
# print(v)
import scrapy
from scrapy.selector import HtmlXPathSelector
from scrapy.http.request import Request
from scrapy.http.cookies import CookieJar
from scrapy import FormRequest class ChouTiSpider(scrapy.Spider):
# 爬虫应用的名称,通过此名称启动爬虫命令
name = "chouti"
# 允许的域名
allowed_domains = ["chouti.com"] cookie_dict = {}
has_request_set = {} def start_requests(self):
url = 'http://dig.chouti.com/'
# return [Request(url=url, callback=self.login)]
yield Request(url=url, callback=self.login) def login(self, response):
cookie_jar = CookieJar()
cookie_jar.extract_cookies(response, response.request)
for k, v in cookie_jar._cookies.items():
for i, j in v.items():
for m, n in j.items():
self.cookie_dict[m] = n.value req = Request(
url='http://dig.chouti.com/login',
method='POST',
headers={'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8'},
body='phone=8615131255089&password=pppppppp&oneMonth=1',
cookies=self.cookie_dict,
callback=self.check_login
)
yield req def check_login(self, response):
req = Request(
url='http://dig.chouti.com/',
method='GET',
callback=self.show,
cookies=self.cookie_dict,
dont_filter=True
)
yield req def show(self, response):
# print(response)
hxs = HtmlXPathSelector(response)
news_list = hxs.select('//div[@id="content-list"]/div[@class="item"]')
for new in news_list:
# temp = new.xpath('div/div[@class="part2"]/@share-linkid').extract()
link_id = new.xpath('*/div[@class="part2"]/@share-linkid').extract_first()
yield Request(
url='http://dig.chouti.com/link/vote?linksId=%s' %(link_id,),
method='POST',
cookies=self.cookie_dict,
callback=self.do_favor
) page_list = hxs.select('//div[@id="dig_lcpage"]//a[re:test(@href, "/all/hot/recent/\d+")]/@href').extract()
for page in page_list: page_url = 'http://dig.chouti.com%s' % page
import hashlib
hash = hashlib.md5()
hash.update(bytes(page_url,encoding='utf-8'))
key = hash.hexdigest()
if key in self.has_request_set:
pass
else:
self.has_request_set[key] = page_url
yield Request(
url=page_url,
method='GET',
callback=self.show
) def do_favor(self, response):
print(response.text)
自动登录抽屉点赞
6. 格式化处理
import scrapy class XiaoHuarItem(scrapy.Item):
name = scrapy.Field()
school = scrapy.Field()
url = scrapy.Field()
items
import json
import os
import requests class JsonPipeline(object):
def __init__(self):
self.file = open('xiaohua.txt', 'w') def process_item(self, item, spider):
v = json.dumps(dict(item), ensure_ascii=False)
self.file.write(v)
self.file.write('\n')
self.file.flush()
return item class FilePipeline(object):
def __init__(self):
if not os.path.exists('imgs'):
os.makedirs('imgs') def process_item(self, item, spider):
response = requests.get(item['url'], stream=True)
file_name = '%s_%s.jpg' % (item['name'], item['school'])
with open(os.path.join('imgs', file_name), mode='wb') as f:
f.write(response.content)
return item
pipelines
ITEM_PIPELINES = {
'spider1.pipelines.JsonPipeline': 100,
'spider1.pipelines.FilePipeline': 300,
}
# 每行后面的整型值,确定了他们运行的顺序,item按数字从低到高的顺序,通过pipeline,通常将这些数字定义在0-1000范围内。
settings
7. 自定义pipelines
from scrapy.exceptions import DropItem class CustomPipeline(object):
def __init__(self,v):
self.value = v def process_item(self, item, spider):
# 操作并进行持久化 # return表示会被后续的pipeline继续处理
return item # 表示将item丢弃,不会被后续pipeline处理
# raise DropItem() @classmethod
def from_crawler(cls, crawler):
"""
初始化时候,用于创建pipeline对象
:param crawler:
:return:
"""
val = crawler.settings.getint('MMMM')
return cls(val) def open_spider(self,spider):
"""
爬虫开始执行时,调用
:param spider:
:return:
"""
print('') def close_spider(self,spider):
"""
爬虫关闭时,被调用
:param spider:
:return:
"""
print('') 自定义pipeline
8. 中间件
class SpiderMiddleware(object):
def process_spider_input(self,response, spider):
"""
下载完成,执行,然后交给parse处理
:param response:
:param spider:
:return:
"""
pass
def process_spider_output(self,response, result, spider):
"""
spider处理完成,返回时调用
:param response:
:param result:
:param spider:
:return: 必须返回包含 Request 或 Item 对象的可迭代对象(iterable)
"""
return result
def process_spider_exception(self,response, exception, spider):
"""
异常调用
:param response:
:param exception:
:param spider:
:return: None,继续交给后续中间件处理异常;含 Response 或 Item 的可迭代对象(iterable),交给调度器或pipeline
"""
return None
def process_start_requests(self,start_requests, spider):
"""
爬虫启动时调用
:param start_requests:
:param spider:
:return: 包含 Request 对象的可迭代对象
"""
return start_requests
爬虫中间件
爬虫中间件
class DownMiddleware1(object):
def process_request(self, request, spider):
"""
请求需要被下载时,经过所有下载器中间件的process_request调用
:param request:
:param spider:
:return:
None,继续后续中间件去下载;
Response对象,停止process_request的执行,开始执行process_response
Request对象,停止中间件的执行,将Request重新调度器
raise IgnoreRequest异常,停止process_request的执行,开始执行process_exception
"""
pass def process_response(self, request, response, spider):
"""
spider处理完成,返回时调用
:param response:
:param result:
:param spider:
:return:
Response 对象:转交给其他中间件process_response
Request 对象:停止中间件,request会被重新调度下载
raise IgnoreRequest 异常:调用Request.errback
"""
print('response1')
return response def process_exception(self, request, exception, spider):
"""
当下载处理器(download handler)或 process_request() (下载中间件)抛出异常
:param response:
:param exception:
:param spider:
:return:
None:继续交给后续中间件处理异常;
Response对象:停止后续process_exception方法
Request对象:停止中间件,request将会被重新调用下载
"""
return None 下载器中间件
下载中间件
9. 自定制命令
A.在spiders同级创建任意目录,在目录创建crawlall.py
from scrapy.commands import ScrapyCommand
from scrapy.utils.project import get_project_settings class Command(ScrapyCommand): requires_project = True def syntax(self):
return '[options]' def short_desc(self):
return 'Runs all of the spiders' def run(self, args, opts):
spider_list = self.crawler_process.spiders.list()
for name in spider_list:
self.crawler_process.crawl(name, **opts.__dict__)
self.crawler_process.start()
crawlall.py
B.在settings.py 中添加配置 COMMANDS_MODULE = '项目名称.目录名称
C.scrapy crawlall
10. 避免重复访问
scrapy默认使用 scrapy.dupefilter.RFPDupeFilter 进行去重,相关配置有:
DUPEFILTER_CLASS = 'scrapy.dupefilter.RFPDupeFilter'
DUPEFILTER_DEBUG = False
JOBDIR = "保存范文记录的日志路径,如:/root/" # 最终路径为 /root/requests.seen
11. settings其它配置
# -*- coding: utf-8 -*- # Scrapy settings for step8_king project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
# http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html # 1. 爬虫名称
BOT_NAME = 'step8_king' # 2. 爬虫应用路径
SPIDER_MODULES = ['step8_king.spiders']
NEWSPIDER_MODULE = 'step8_king.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent
# 3. 客户端 user-agent请求头
# USER_AGENT = 'step8_king (+http://www.yourdomain.com)' # Obey robots.txt rules
# 4. 禁止爬虫配置
# ROBOTSTXT_OBEY = False # Configure maximum concurrent requests performed by Scrapy (default: 16)
# 5. 并发请求数
# CONCURRENT_REQUESTS = 4 # Configure a delay for requests for the same website (default: 0)
# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
# 6. 延迟下载秒数
# DOWNLOAD_DELAY = 2 # The download delay setting will honor only one of:
# 7. 单域名访问并发数,并且延迟下次秒数也应用在每个域名
# CONCURRENT_REQUESTS_PER_DOMAIN = 2
# 单IP访问并发数,如果有值则忽略:CONCURRENT_REQUESTS_PER_DOMAIN,并且延迟下次秒数也应用在每个IP
# CONCURRENT_REQUESTS_PER_IP = 3 # Disable cookies (enabled by default)
# 8. 是否支持cookie,cookiejar进行操作cookie
# COOKIES_ENABLED = True
# COOKIES_DEBUG = True # Disable Telnet Console (enabled by default)
# 9. Telnet用于查看当前爬虫的信息,操作爬虫等...
# 使用telnet ip port ,然后通过命令操作
# TELNETCONSOLE_ENABLED = True
# TELNETCONSOLE_HOST = '127.0.0.1'
# TELNETCONSOLE_PORT = [6023,] # 10. 默认请求头
# Override the default request headers:
# DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
# } # Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
# 11. 定义pipeline处理请求
# ITEM_PIPELINES = {
# 'step8_king.pipelines.JsonPipeline': 700,
# 'step8_king.pipelines.FilePipeline': 500,
# } # 12. 自定义扩展,基于信号进行调用
# Enable or disable extensions
# See http://scrapy.readthedocs.org/en/latest/topics/extensions.html
# EXTENSIONS = {
# # 'step8_king.extensions.MyExtension': 500,
# } # 13. 爬虫允许的最大深度,可以通过meta查看当前深度;0表示无深度
# DEPTH_LIMIT = 3 # 14. 爬取时,0表示深度优先Lifo(默认);1表示广度优先FiFo # 后进先出,深度优先
# DEPTH_PRIORITY = 0
# SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleLifoDiskQueue'
# SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.LifoMemoryQueue'
# 先进先出,广度优先 # DEPTH_PRIORITY = 1
# SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleFifoDiskQueue'
# SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.FifoMemoryQueue' # 15. 调度器队列
# SCHEDULER = 'scrapy.core.scheduler.Scheduler'
# from scrapy.core.scheduler import Scheduler # 16. 访问URL去重
# DUPEFILTER_CLASS = 'step8_king.duplication.RepeatUrl' # Enable and configure the AutoThrottle extension (disabled by default)
# See http://doc.scrapy.org/en/latest/topics/autothrottle.html """
17. 自动限速算法
from scrapy.contrib.throttle import AutoThrottle
自动限速设置
1. 获取最小延迟 DOWNLOAD_DELAY
2. 获取最大延迟 AUTOTHROTTLE_MAX_DELAY
3. 设置初始下载延迟 AUTOTHROTTLE_START_DELAY
4. 当请求下载完成后,获取其"连接"时间 latency,即:请求连接到接受到响应头之间的时间
5. 用于计算的... AUTOTHROTTLE_TARGET_CONCURRENCY
target_delay = latency / self.target_concurrency
new_delay = (slot.delay + target_delay) / 2.0 # 表示上一次的延迟时间
new_delay = max(target_delay, new_delay)
new_delay = min(max(self.mindelay, new_delay), self.maxdelay)
slot.delay = new_delay
""" # 开始自动限速
# AUTOTHROTTLE_ENABLED = True
# The initial download delay
# 初始下载延迟
# AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
# 最大下载延迟
# AUTOTHROTTLE_MAX_DELAY = 10
# The average number of requests Scrapy should be sending in parallel to each remote server
# 平均每秒并发数
# AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received:
# 是否显示
# AUTOTHROTTLE_DEBUG = True # Enable and configure HTTP caching (disabled by default)
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings """
18. 启用缓存
目的用于将已经发送的请求或相应缓存下来,以便以后使用 from scrapy.downloadermiddlewares.httpcache import HttpCacheMiddleware
from scrapy.extensions.httpcache import DummyPolicy
from scrapy.extensions.httpcache import FilesystemCacheStorage
"""
# 是否启用缓存策略
# HTTPCACHE_ENABLED = True # 缓存策略:所有请求均缓存,下次在请求直接访问原来的缓存即可
# HTTPCACHE_POLICY = "scrapy.extensions.httpcache.DummyPolicy"
# 缓存策略:根据Http响应头:Cache-Control、Last-Modified 等进行缓存的策略
# HTTPCACHE_POLICY = "scrapy.extensions.httpcache.RFC2616Policy" # 缓存超时时间
# HTTPCACHE_EXPIRATION_SECS = 0 # 缓存保存路径
# HTTPCACHE_DIR = 'httpcache' # 缓存忽略的Http状态码
# HTTPCACHE_IGNORE_HTTP_CODES = [] # 缓存存储的插件
# HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage' """
19. 代理,需要在环境变量中设置
from scrapy.contrib.downloadermiddleware.httpproxy import HttpProxyMiddleware 方式一:使用默认
os.environ
{
http_proxy:http://root:woshiniba@192.168.11.11:9999/
https_proxy:http://192.168.11.11:9999/
}
方式二:使用自定义下载中间件 def to_bytes(text, encoding=None, errors='strict'):
if isinstance(text, bytes):
return text
if not isinstance(text, six.string_types):
raise TypeError('to_bytes must receive a unicode, str or bytes '
'object, got %s' % type(text).__name__)
if encoding is None:
encoding = 'utf-8'
return text.encode(encoding, errors) class ProxyMiddleware(object):
def process_request(self, request, spider):
PROXIES = [
{'ip_port': '111.11.228.75:80', 'user_pass': ''},
{'ip_port': '120.198.243.22:80', 'user_pass': ''},
{'ip_port': '111.8.60.9:8123', 'user_pass': ''},
{'ip_port': '101.71.27.120:80', 'user_pass': ''},
{'ip_port': '122.96.59.104:80', 'user_pass': ''},
{'ip_port': '122.224.249.122:8088', 'user_pass': ''},
]
proxy = random.choice(PROXIES)
if proxy['user_pass'] is not None:
request.meta['proxy'] = to_bytes("http://%s" % proxy['ip_port'])
encoded_user_pass = base64.encodestring(to_bytes(proxy['user_pass']))
request.headers['Proxy-Authorization'] = to_bytes('Basic ' + encoded_user_pass)
print "**************ProxyMiddleware have pass************" + proxy['ip_port']
else:
print "**************ProxyMiddleware no pass************" + proxy['ip_port']
request.meta['proxy'] = to_bytes("http://%s" % proxy['ip_port']) DOWNLOADER_MIDDLEWARES = {
'step8_king.middlewares.ProxyMiddleware': 500,
} """ """
20. Https访问
Https访问时有两种情况:
1. 要爬取网站使用的可信任证书(默认支持)
DOWNLOADER_HTTPCLIENTFACTORY = "scrapy.core.downloader.webclient.ScrapyHTTPClientFactory"
DOWNLOADER_CLIENTCONTEXTFACTORY = "scrapy.core.downloader.contextfactory.ScrapyClientContextFactory" 2. 要爬取网站使用的自定义证书
DOWNLOADER_HTTPCLIENTFACTORY = "scrapy.core.downloader.webclient.ScrapyHTTPClientFactory"
DOWNLOADER_CLIENTCONTEXTFACTORY = "step8_king.https.MySSLFactory" # https.py
from scrapy.core.downloader.contextfactory import ScrapyClientContextFactory
from twisted.internet.ssl import (optionsForClientTLS, CertificateOptions, PrivateCertificate) class MySSLFactory(ScrapyClientContextFactory):
def getCertificateOptions(self):
from OpenSSL import crypto
v1 = crypto.load_privatekey(crypto.FILETYPE_PEM, open('/Users/wupeiqi/client.key.unsecure', mode='r').read())
v2 = crypto.load_certificate(crypto.FILETYPE_PEM, open('/Users/wupeiqi/client.pem', mode='r').read())
return CertificateOptions(
privateKey=v1, # pKey对象
certificate=v2, # X509对象
verify=False,
method=getattr(self, 'method', getattr(self, '_ssl_method', None))
)
其他:
相关类
scrapy.core.downloader.handlers.http.HttpDownloadHandler
scrapy.core.downloader.webclient.ScrapyHTTPClientFactory
scrapy.core.downloader.contextfactory.ScrapyClientContextFactory
相关配置
DOWNLOADER_HTTPCLIENTFACTORY
DOWNLOADER_CLIENTCONTEXTFACTORY """ """
21. 爬虫中间件
class SpiderMiddleware(object): def process_spider_input(self,response, spider):
'''
下载完成,执行,然后交给parse处理
:param response:
:param spider:
:return:
'''
pass def process_spider_output(self,response, result, spider):
'''
spider处理完成,返回时调用
:param response:
:param result:
:param spider:
:return: 必须返回包含 Request 或 Item 对象的可迭代对象(iterable)
'''
return result def process_spider_exception(self,response, exception, spider):
'''
异常调用
:param response:
:param exception:
:param spider:
:return: None,继续交给后续中间件处理异常;含 Response 或 Item 的可迭代对象(iterable),交给调度器或pipeline
'''
return None def process_start_requests(self,start_requests, spider):
'''
爬虫启动时调用
:param start_requests:
:param spider:
:return: 包含 Request 对象的可迭代对象
'''
return start_requests 内置爬虫中间件:
'scrapy.contrib.spidermiddleware.httperror.HttpErrorMiddleware': 50,
'scrapy.contrib.spidermiddleware.offsite.OffsiteMiddleware': 500,
'scrapy.contrib.spidermiddleware.referer.RefererMiddleware': 700,
'scrapy.contrib.spidermiddleware.urllength.UrlLengthMiddleware': 800,
'scrapy.contrib.spidermiddleware.depth.DepthMiddleware': 900, """
# from scrapy.contrib.spidermiddleware.referer import RefererMiddleware
# Enable or disable spider middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
SPIDER_MIDDLEWARES = {
# 'step8_king.middlewares.SpiderMiddleware': 543,
} """
22. 下载中间件
class DownMiddleware1(object):
def process_request(self, request, spider):
'''
请求需要被下载时,经过所有下载器中间件的process_request调用
:param request:
:param spider:
:return:
None,继续后续中间件去下载;
Response对象,停止process_request的执行,开始执行process_response
Request对象,停止中间件的执行,将Request重新调度器
raise IgnoreRequest异常,停止process_request的执行,开始执行process_exception
'''
pass def process_response(self, request, response, spider):
'''
spider处理完成,返回时调用
:param response:
:param result:
:param spider:
:return:
Response 对象:转交给其他中间件process_response
Request 对象:停止中间件,request会被重新调度下载
raise IgnoreRequest 异常:调用Request.errback
'''
print('response1')
return response def process_exception(self, request, exception, spider):
'''
当下载处理器(download handler)或 process_request() (下载中间件)抛出异常
:param response:
:param exception:
:param spider:
:return:
None:继续交给后续中间件处理异常;
Response对象:停止后续process_exception方法
Request对象:停止中间件,request将会被重新调用下载
'''
return None 默认下载中间件
{
'scrapy.contrib.downloadermiddleware.robotstxt.RobotsTxtMiddleware': 100,
'scrapy.contrib.downloadermiddleware.httpauth.HttpAuthMiddleware': 300,
'scrapy.contrib.downloadermiddleware.downloadtimeout.DownloadTimeoutMiddleware': 350,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': 400,
'scrapy.contrib.downloadermiddleware.retry.RetryMiddleware': 500,
'scrapy.contrib.downloadermiddleware.defaultheaders.DefaultHeadersMiddleware': 550,
'scrapy.contrib.downloadermiddleware.redirect.MetaRefreshMiddleware': 580,
'scrapy.contrib.downloadermiddleware.httpcompression.HttpCompressionMiddleware': 590,
'scrapy.contrib.downloadermiddleware.redirect.RedirectMiddleware': 600,
'scrapy.contrib.downloadermiddleware.cookies.CookiesMiddleware': 700,
'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware': 750,
'scrapy.contrib.downloadermiddleware.chunked.ChunkedTransferMiddleware': 830,
'scrapy.contrib.downloadermiddleware.stats.DownloaderStats': 850,
'scrapy.contrib.downloadermiddleware.httpcache.HttpCacheMiddleware': 900,
} """
# from scrapy.contrib.downloadermiddleware.httpauth import HttpAuthMiddleware
# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# DOWNLOADER_MIDDLEWARES = {
# 'step8_king.middlewares.DownMiddleware1': 100,
# 'step8_king.middlewares.DownMiddleware2': 500,
# } settings
python16_day37【爬虫2】的更多相关文章
- 设计爬虫Hawk背后的故事
本文写于圣诞节北京下午慵懒的午后.本文偏技术向,不过应该大部分人能看懂. 五年之痒 2016年,能记入个人年终总结的事情没几件,其中一个便是开源了Hawk.我花不少时间优化和推广它,得到的评价还算比较 ...
- Scrapy框架爬虫初探——中关村在线手机参数数据爬取
关于Scrapy如何安装部署的文章已经相当多了,但是网上实战的例子还不是很多,近来正好在学习该爬虫框架,就简单写了个Spider Demo来实践.作为硬件数码控,我选择了经常光顾的中关村在线的手机页面 ...
- Python 爬虫模拟登陆知乎
在之前写过一篇使用python爬虫爬取电影天堂资源的博客,重点是如何解析页面和提高爬虫的效率.由于电影天堂上的资源获取权限是所有人都一样的,所以不需要进行登录验证操作,写完那篇文章后又花了些时间研究了 ...
- scrapy爬虫docker部署
spider_docker 接我上篇博客,为爬虫引用创建container,包括的模块:scrapy, mongo, celery, rabbitmq,连接https://github.com/Liu ...
- scrapy 知乎用户信息爬虫
zhihu_spider 此项目的功能是爬取知乎用户信息以及人际拓扑关系,爬虫框架使用scrapy,数据存储使用mongo,下载这些数据感觉也没什么用,就当为大家学习scrapy提供一个例子吧.代码地 ...
- 120项改进:开源超级爬虫Hawk 2.0 重磅发布!
沙漠君在历时半年,修改无数bug,更新一票新功能后,在今天隆重推出最新改进的超级爬虫Hawk 2.0! 啥?你不知道Hawk干吗用的? 这是采集数据的挖掘机,网络猎杀的重狙!半年多以前,沙漠君写了一篇 ...
- Python爬虫小白入门(四)PhatomJS+Selenium第一篇
一.前言 在上一篇博文中,我们的爬虫面临着一个问题,在爬取Unsplash网站的时候,由于网站是下拉刷新,并没有分页.所以不能够通过页码获取页面的url来分别发送网络请求.我也尝试了其他方式,比如下拉 ...
- Python多线程爬虫爬取电影天堂资源
最近花些时间学习了一下Python,并写了一个多线程的爬虫程序来获取电影天堂上资源的迅雷下载地址,代码已经上传到GitHub上了,需要的同学可以自行下载.刚开始学习python希望可以获得宝贵的意见. ...
- QQ空间动态爬虫
作者:虚静 链接:https://zhuanlan.zhihu.com/p/24656161 来源:知乎 著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处. 先说明几件事: 题目的意 ...
随机推荐
- oracle最精简客户端(3个文件+1个path变量就搞定oracle客户端)
oracle最精简客户端: network\admin\tnsnames.ora (自己新建)oci.dlloraocieill.dll 将oci.dll的路径加到path变量中就可以了 tnsnam ...
- Visual Studio使用技巧,创建自己的代码片段
1.代码片段的使用示例 在编写代码中常会使用代码片段来提高我们的编写代码的效率,如:在Visual Studio中编写一个 for(int i = 0; i < length;i++) { } ...
- 改善C#程序的建议4:C#中标准Dispose模式的实现
http://www.cnblogs.com/luminji/archive/2011/03/29/1997812.html 需要明确一下C#程序(或者说.NET)中的资源.简单的说来,C#中的每一个 ...
- Android程序增加代码混淆器
增加代码混淆器.主要是增加proguard-project.txt文件的规则进行混淆,之前新建Android程序是proguard.cfg文件 能够看一下我採用的通用规则(proguard-proje ...
- C++异常 将对象用作异常类型
通常,引发异常的函数将传递一个对象.这样做的重要有点之一是,可以使用不同的异常类型来区分不同的函数在不同情况下引发的异常.另外,对象可以携带信息,程序员可以根据这些信息来确定引发异常的原因.同时,ca ...
- (二)微信小程序的三种传值方式
1.全局变量 app.js里 App({ //全局变量 globalData: { userInfo: null, host: 'http://localhost:8080/data.json' } ...
- 小程序 - API 踩坑记录(更新中...)
API 小程序API结构导览图: 声明: 请尊重博客园原创精神,转载或使用图片请注明: 博主:xing.org1^ 出处:http://www.cnblogs.com/padding1015/
- Java初学者笔记五:泛型处理
一.泛型类: 泛型是指适用于某一种数据类型而不是一个数据机构中能存不同类型 import java.io.*; import java.nio.file.Files; import java.nio. ...
- Egret Wing4.1.0 断点调试
一 双击代码行号左侧打断点 二 选择调试视图工具栏. 三 点击开始调试 1 wing内置播放器调试 选择此项进行调试会打开Egret内置播放器,我这里这个版本该选项无法进行断点... 2 使用本机 ...
- {sharepoint} Setting List Item Permissions Programatically in sharepoint
namespace Avinash { class Program { static void Main(string[] args) { SetListItemPermission(); } sta ...