使用webmagic搭建一个简单的爬虫
刚刚接触爬虫,听说webmagic很不错,于是就了解了一下。
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。
这句话说的真的一点都不假,像我这样什么都不懂的人直接下载部署,看了看可以调用的方法,马上就写出了第一个爬虫小程序。
以下是我学习的过程:
首先需要下载jar:http://webmagic.io/download.html
部署好后就建一个class继承PageProcessor接口,重写process()方法,即可完成一个爬虫。
是不是很简单?
先上代码,再讲解吧。
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor; public class MyProcessor implements PageProcessor {
// 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
private static int count =0; @Override
public Site getSite() {
return site;
} @Override
public void process(Page page) {
//判断链接是否符合http://www.cnblogs.com/任意个数字字母-/p/7个数字.html格式
if(!page.getUrl().regex("http://www.cnblogs.com/[a-z 0-9 -]+/p/[0-9]{7}.html").match()){
//加入满足条件的链接
page.addTargetRequests(
page.getHtml().xpath("//*[@id=\"post_list\"]/div/div[@class='post_item_body']/h3/a/@href").all());
}else{
//获取页面需要的内容
System.out.println("抓取的内容:"+
page.getHtml().xpath("//*[@id=\"Header1_HeaderTitle\"]/text()").get()
);
count ++;
}
} public static void main(String[] args) {
long startTime, endTime;
System.out.println("开始爬取...");
startTime = System.currentTimeMillis();
Spider.create(new MyProcessor()).addUrl("https://www.cnblogs.com/").thread(5).run();
endTime = System.currentTimeMillis();
System.out.println("爬取结束,耗时约" + ((endTime - startTime) / 1000) + "秒,抓取了"+count+"条记录");
} }
由于刚开始学,技术有限,所以简单地爬一下这些文章的作者。
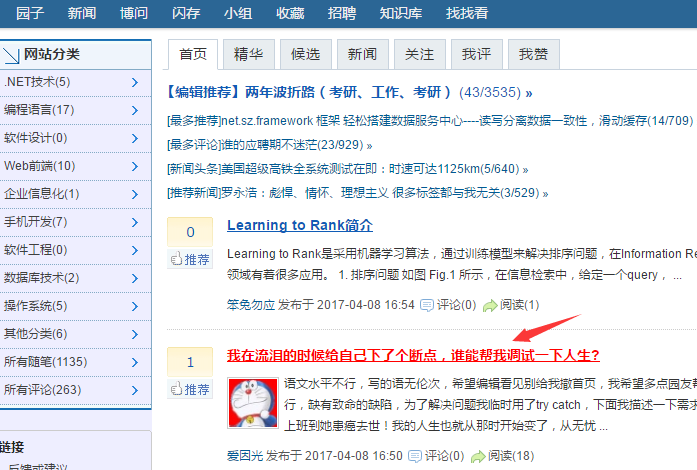
要爬取,首先得知道内容在哪个位置上。在chrome下审查一下元素发现,文章都在这里
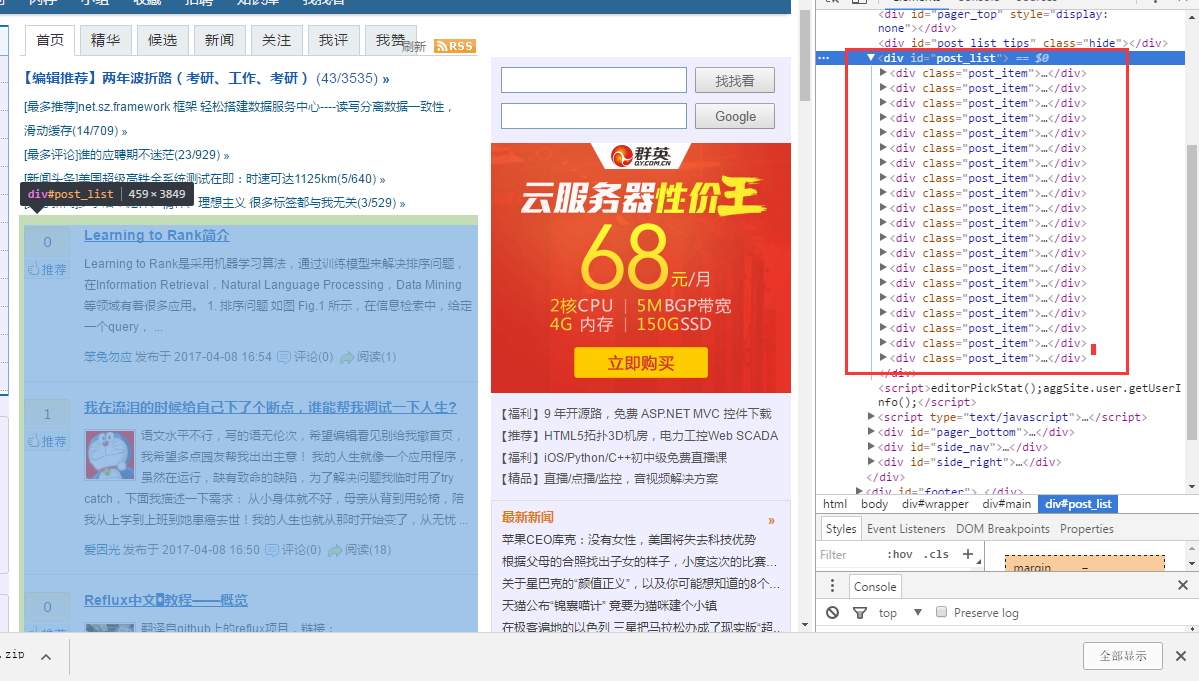
点进文章后审查元素发现作者的名字在这里
知道要爬的内容在哪个位置之后。我们还需要知道怎样才能拿到这些数据。
这里说一下webmagic的内容
启动爬虫就这句:Spider.create(new MyProcessor()).addUrl("https://www.cnblogs.com/").thread(5).run();//addUrl就是种子url
Page对象就是当前获取的页面,
getUrl()可以获得当前url,
addTargetRequests()就是把链接放入等待爬取
getHtml()获得页面的html元素
上面这些很容易就能知道它的意思,不懂得是xpath();
刚开始学,我也不懂,但是chrome懂,所以可以让它帮我们写好xpath。
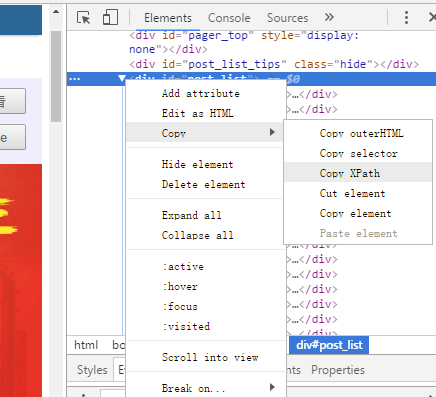
审查元素下,选择要需要的部分右键Copy,选择Copy XPath,然后在console下粘贴
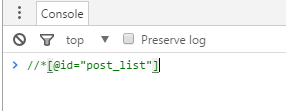
关于xpath的教程可以查看https://www.one-tab.com/page/JFPOsHyvQUOQlzZwahc6-Q
关于webmagic的可以查看http://webmagic.io/docs/zh/posts/ch1-overview/
使用webmagic搭建一个简单的爬虫的更多相关文章
- 【转】使用webmagic搭建一个简单的爬虫
[转]使用webmagic搭建一个简单的爬虫 刚刚接触爬虫,听说webmagic很不错,于是就了解了一下. webmagic的是一个无须配置.便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代 ...
- 用nodejs搭建一个简单的服务器
使用nodejs搭建一个简单的服务器 nodejs优点:性能高(读写文件) 数据操作能力强 官网:www.nodejs.org 验证是否安装成功:cmd命令行中输入node -v 如果显示版本号表示安 ...
- 初学Node(六)搭建一个简单的服务器
搭建一个简单的服务器 通过下面的代码可以搭建一个简单的服务器: var http = require("http"); http.createServer(function(req ...
- python (1)一个简单的爬虫: python 在windows下 创建文件夹并写入文件
1.一个简单的爬虫:爬取豆瓣的热门电影的信息 写在前面:如何创建本来存在的文件夹并写入 t_path = "d:/py/inn" #本来不存在inn,先定义路径,然后如果不存在,则 ...
- 【netty】(2)---搭建一个简单服务器
netty(2)---搭建一个简单服务器 说明:本篇博客是基于学习慕课网有关视频教学.效果:当用户访问:localhost:8088 后 服务器返回 "hello netty"; ...
- 使用gitblit搭建一个简单的局域网服务器
使用gitblit搭建一个简单的局域网服务器 1.使用背景 现在很多使用github管理代码,但是github需要互联网的支持,而且私有的git库需要收费.有一些项目的代码不能外泄,所以,搭建一个局域 ...
- Golang学习-第二篇 搭建一个简单的Go Web服务器
序言 由于本人一直从事Web服务器端的程序开发,所以在学习Golang也想从Web这里开始学起,如果对Golang还不太清楚怎么搭建环境的朋友们可以参考我的上一篇文章 Golang的简单介绍及Wind ...
- Python并发编程-一个简单的爬虫
一个简单的爬虫 #网页状态码 #200 正常 #404 网页找不到 #502 504 import requests from multiprocessing import Pool def get( ...
- python爬虫系列(1)——一个简单的爬虫实例
本文主要实现一个简单的爬虫,目的是从一个百度贴吧页面下载图片. 1. 概述 本文主要实现一个简单的爬虫,目的是从一个百度贴吧页面下载图片.下载图片的步骤如下: 获取网页html文本内容:分析html中 ...
随机推荐
- 从零开始,制定PHP学习计划
7月份学习计划1-15 搭建开发环境.做个小demo 增删改查.Mysql数据库16-30号 架构设计.服务器管理.版本控制 8月份正式入手项目jquery脚本学习Thinksns开源学习.核心业务学 ...
- e685. 显示页面格式窗口
The page format dialog allows the user to change the default page format values such as the orientat ...
- dm8127前段采集和抓拍
高清监控(944275216) 2014-1-17 9:36:24自主研发高清网络摄像机,720P.960P.1080P系列产品,经济型.低照型.宽动态型等各种机型可选,支持onvif.P2 ...
- android 自定义照相机Camera黑屏 (转至 http://blog.csdn.net/chuchu521/article/details/8089058)
对于一些手机,像HTC,当自定义Camera时,调用Camera.Parameters的 parameters.setPreviewSize(width, height)方法时,如果width和hei ...
- TF42064: The build number already exists for build definition error in TFS2010
In TFS2008, deleting a build removes it from the database itself. If you delete a build called Build ...
- 做asp.net的在别人眼中都是渣渣吗?
做asp.net的在别人眼中都是渣渣吗?
- 关于Bundle
1. 黄色的文件夹,打包的时候,不会建立目录,主要保存程序文件 - 素材不允许重名 2. 蓝色的文件夹,打包的时候,会建立目录,可以分目录的存储素材文件 - 素材可以重名 - 游戏的场景,backgr ...
- Unity的加载路径
1.Resources 路径 只读 不能动态的修改 存放内容 预制体(prefabs) - 不容易变化的预制体 prefabs打包的时候 会自动过滤不需要的资源 有利于减小资源大小 主线程加载 Res ...
- module、applet
Each Module is developed as a standalone Windows DLL.Each module can contain one or more applets, an ...
- Zookeeper(一)-- 简介以及单机部署和集群部署
一.分布式系统 由多个计算机组成解决同一个问题的系统,提高业务的并发,解决高并发问题. 二.分布式环境下常见问题 1.节点失效 2.配置信息的创建及更新 3.分布式锁 三.Zookeeper 1.定义 ...