6-----Scrapy框架中Item Pipeline用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理
每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或者被丢弃而不再进行处理
item pipeline的主要作用:
1、清理html数据
2、验证爬取的数据
3、去重并丢弃
4、讲爬取的结果保存到数据库中或文件中
编写自己的item pipeline
process_item(self,item,spider)
每个item piple组件是一个独立的pyhton类,必须实现以process_item(self,item,spider)方法
每个item pipeline组件都需要调用该方法,这个方法必须返回一个具有数据的dict,或者item对象,或者抛出DropItem异常,被丢弃的item将不会被之后的pipeline组件所处理
下面的方法也可以选择实现
open_spider(self,spider)
表示当spider被开启的时候调用这个方法
close_spider(self,spider)
当spider挂去年比时候这个方法被调用
from_crawler(cls,crawler)
这个和我们在前面说spider的时候的用法是一样的,可以用于获取settings配置文件中的信息,需要注意的这个是一个类方法,用法例子如下:
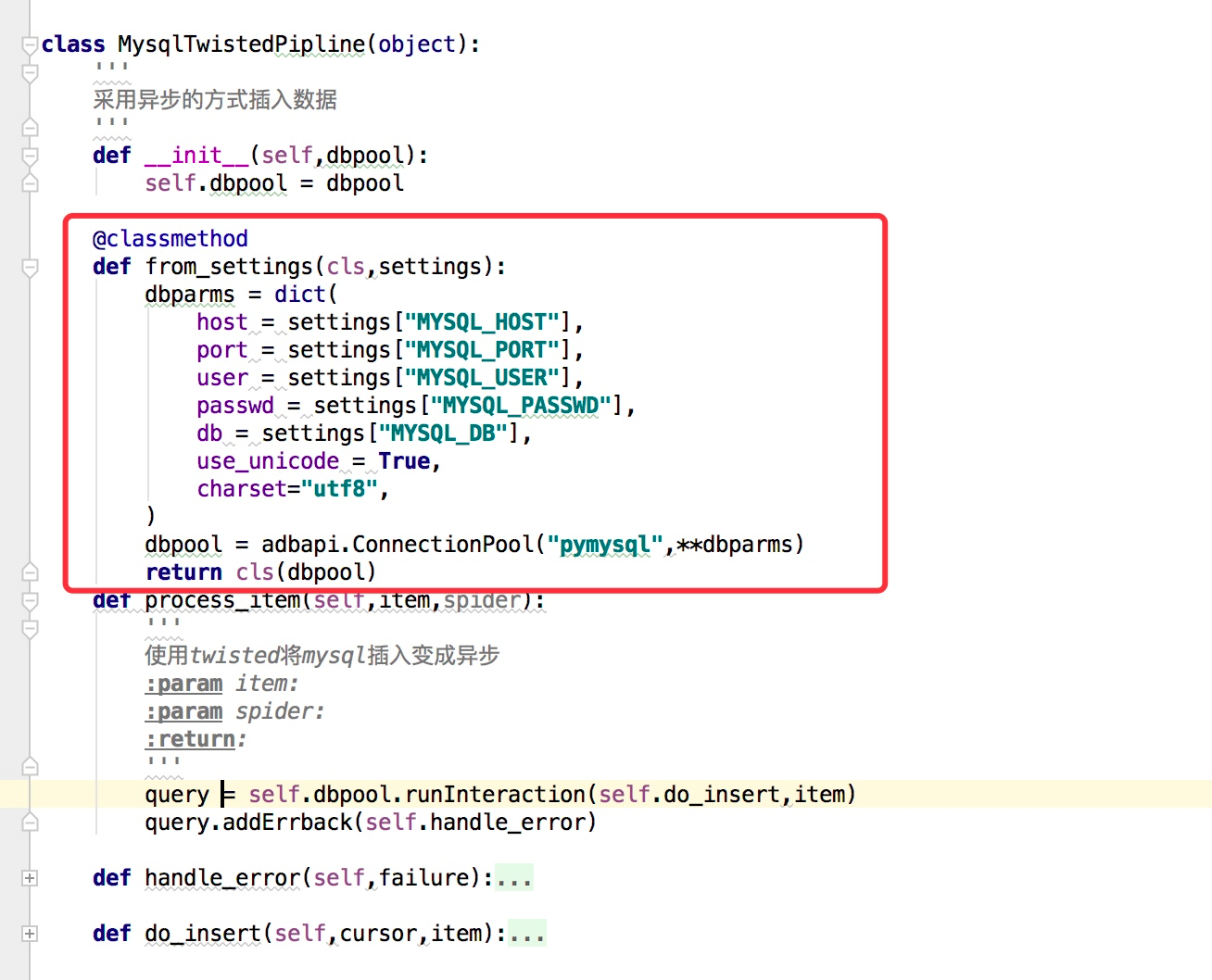
一些item pipeline的使用例子(官网说明)
例子1
这个例子实现的是判断 item中是否包含 price以及price_excludes_vat,如果存在则调整了price属性,都让 item['price'] = item['price'] * self.vat_factor,如果不存在则返回 DropItem
from scrapy.exceptions import DropItem
class PricePipeline(object):
vat_factor = 1.15
def process_item(self, item, spider):
if item['price']:
if item['price_excludes_vat']:
item['price'] = item['price'] * self.vat_factor
return item
else:
raise DropItem("Missing price in %s" % item)
例子2
这个例子是将item写入到json文件中
import json
class JsonWriterPipeline(object):
def __init__(self):
self.file = open('items.jl', 'wb')
def process_item(self, item, spider):
line = json.dumps(dict(item)) + "\n"
self.file.write(line)
return item
例子3
将 item写入到 MongoDB,同时这里演示了 from_crawler的用法
import pymongo
class MongoPipeline(object):
collection_name = 'scrapy_items'
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
self.db[self.collection_name].insert(dict(item))
return item
例子4:去重
一个用于去重的过滤器,丢弃那些已经被处理过的 item,假设item有一个唯一的id,但是我们spider返回的多个 item中包含了相同的 id,去重方法如下:这里初始化了一个集合,每次判断id是否在集合中已经存在,从而做到去重的功能
from scrapy.exceptions import DropItem
class DuplicatesPipeline(object):
def __init__(self):
self.ids_seen = set()
def process_item(self, item, spider):
if item['id'] in self.ids_seen:
raise DropItem("Duplicate item found: %s" % item)
else:
self.ids_seen.add(item['id'])
return item
启用一个item Pipeline组件
在settings配置文件中y9ou一个ITEM_PIPELINES的配置参数,例子如下:
ITEM_PIPELINES = {
'myproject.pipelines.PricePipeline': 300,
'myproject.pipelines.JsonWriterPipeline': 800,
}
每个pipeline后面有一个数值,这个数组的范围是0-1000,这个数值确定了他们的运行顺序,数字越小越优先。
6-----Scrapy框架中Item Pipeline用法的更多相关文章
- scrapy框架中Item Pipeline用法
scrapy框架中item pipeline用法 当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的pyt ...
- Python爬虫从入门到放弃(十六)之 Scrapy框架中Item Pipeline用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为, ...
- Python之爬虫(十八) Scrapy框架中Item Pipeline用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为, ...
- Scrapy框架中选择器的用法【转】
Python爬虫从入门到放弃(十四)之 Scrapy框架中选择器的用法 请给作者点赞 --> 原文链接 Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpa ...
- scrapy框架中Download Middleware用法
scrapy框架中Download Middleware用法 Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给sp ...
- scrapy框架中选择器的用法
scrapy框架中选择器的用法 Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中 ...
- Scrapy框架中的Pipeline组件
简介 在下图中可以看到items.py与pipeline.py,其中items是用来定义抓取内容的实体:pipeline则是用来处理抓取的item的管道 Item管道的主要责任是负责处理有蜘蛛从网页中 ...
- Python爬虫从入门到放弃(十四)之 Scrapy框架中选择器的用法
Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中选择节点的语言,也可以用在HTM ...
- Python之爬虫(十六) Scrapy框架中选择器的用法
Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中选择节点的语言,也可以用在HTM ...
随机推荐
- CoreData的增删改查
首先使用CoreData创建Demo,勾上CoreData选项 然后创建Entity对象,点击Add Entity(+)按钮 生成Entity对象 重命名双击Entity选项,然后输入Person 设 ...
- Matlab 摄像机标定+畸变校正
博客转载自:http://blog.csdn.net/Loser__Wang/article/details/51811347 本文目的在于记录如何使用MATLAB做摄像机标定,并通过opencv进行 ...
- p2657 windy数
传送门 分析 首先这是一个询问一段区间内的个数的问题,所以我们可以用差分的思想用sum(R)-sum(L-1).然后我们考虑如何求出sum(n),我们用dp[i][j][k][t]表示考虑到第i位,最 ...
- p2234&bzoj1588 营业额统计
传送门 题目 营业额统计 Tiger最近被公司升任为营业部经理,他上任后接受公司交给的第一项任务便是统计并分析公司成立以来的营业情况. Tiger拿出了公司的账本,账本上记录了公司成立以来每天的营业额 ...
- 树莓派研究笔记(10)-- Retropie 模拟器
前面介绍过lakka模拟器,小巧,轻便,支持中文.其实最著名的游戏系统还是要属于Retropie啊.虽然笨重了一点,但是很多树莓派系统的原汁原味还是保留的很好.这样就不需要我们自己还要对lakka的源 ...
- Ubuntu16.04版安装VMwareTools的步骤和没法挂载目录问题的解决
vmtool安装流程 1.点击vmware 里面的虚拟机——>安装vmware tool 2.然后(等待一会)弹出一个界面把里面的 VMwareTools-9.6.1-1378637.tar.g ...
- 多线程学习-基础(四)常用函数说明:sleep-join-yield
一.常用函数的使用 (1)Thread.sleep(long millis):在指定的毫秒内让当前正在执行的线程休眠(暂停执行),休眠时不会释放当前所持有的对象的锁.(2)join():主线程等待子线 ...
- [转]MySQL时间与字符串相互转换
转至:https://www.cnblogs.com/wangyongwen/p/6265126.html 时间.字符串.时间戳之间的互相转换很常用,但是几乎每次使用时候都喜欢去搜索一下用法:本文整理 ...
- SVM浅析
系列博客机器学习总结,主要参考书目<统计学习方法>--李航,涉及数学公式较多,以图片的形式表现.SVM是经典的线性分类方法,通过线性映射投射到希尔伯特空间(完备的赋范内积空间)得到了无穷维 ...
- ASP.NET常用数据绑定控件优劣总结
本文的初衷在于对Asp.net常用数据绑定控件进行一个概览性的总结,主要分析各种数据绑定控件各自的优缺点,以便在实际的开发中选用合适的控件进行数据绑定,以提高开发效率. 因为这些数据绑定控件大部分都已 ...