神经网络的训练和测试 python
承接上一节,神经网络需要训练,那么训练集来自哪?测试的数据又来自哪?
《python神经网络编程》一书给出了训练集,识别图片中的数字。测试集的链接如下:
https://raw.githubusercontent.com/makeyourownneuralnetwork/makeyourownneuralnetwork/master/mnist_dataset/mnist_test_10.csv
为了方便,这只是一个小的测试集,才10个。
训练集链接:https://raw.githubusercontent.com/makeyourownneuralnetwork/makeyourownneuralnetwork/master/mnist_dataset/mnist_train_100.csv
这是包含100个数据的训练集。
训练集和测试集的每段的第一个字母是期望的数字,每段剩余的文本是表示这个数字的像素集合,为784个数据。为了计算,我们要把文本转化为数字进行存放。把第一个数据当作期望数据,剩余的784个数据当作输入。因此输入节点设为784个。输出节点设为10个,因为要识别的是10个数据0到9。隐藏层节点选为100个,并没有进行科学的计算。
import numpy
import scipy.special
import matplotlib.pyplot as plt
import pylab
# 神经网络类定义
class NeuralNetwork():
# 初始化神经网络
def __init__(self, inputnodes, hiddennodes, outputnodes, learningrate):
# 设置输入层节点,隐藏层节点和输出层节点的数量
self.inodes = inputnodes
self.hnodes = hiddennodes
self.onodes = outputnodes
# 学习率设置
self.lr = learningrate
# 权重矩阵设置 正态分布
self.wih = numpy.random.normal(0.0, pow(self.hnodes, -0.5), (self.hnodes, self.inodes))
self.who = numpy.random.normal(0.0, pow(self.onodes, -0.5), (self.onodes, self.hnodes))
# 激活函数设置,sigmod()函数
self.activation_function = lambda x: scipy.special.expit(x)
pass # 训练神经网络
def train(self,input_list,target_list):
# 转换输入输出列表到二维数组
inputs = numpy.array(input_list, ndmin=2).T
targets = numpy.array(target_list,ndmin= 2).T
# 计算到隐藏层的信号
hidden_inputs = numpy.dot(self.wih, inputs)
# 计算隐藏层输出的信号
hidden_outputs = self.activation_function(hidden_inputs)
# 计算到输出层的信号
final_inputs = numpy.dot(self.who, hidden_outputs)
final_outputs = self.activation_function(final_inputs) output_errors = targets - final_outputs
hidden_errors = numpy.dot(self.who.T,output_errors) #隐藏层和输出层权重更新
self.who += self.lr * numpy.dot((output_errors*final_outputs*(1.0-final_outputs)),
numpy.transpose(hidden_outputs))
#输入层和隐藏层权重更新
self.wih += self.lr * numpy.dot((hidden_errors * hidden_outputs * (1.0 - hidden_outputs)),
numpy.transpose(inputs))
pass
# 查询神经网络
def query(self, input_list):
# 转换输入列表到二维数组
inputs = numpy.array(input_list, ndmin=2).T
# 计算到隐藏层的信号
hidden_inputs = numpy.dot(self.wih, inputs)
# 计算隐藏层输出的信号
hidden_outputs = self.activation_function(hidden_inputs)
# 计算到输出层的信号
final_inputs = numpy.dot(self.who, hidden_outputs)
final_outputs = self.activation_function(final_inputs) return final_outputs # 设置每层节点个数
input_nodes = 784
hidden_nodes = 100
output_nodes = 10
# 设置学习率为0.3
learning_rate = 0.3
# 创建神经网络
n = NeuralNetwork(input_nodes, hidden_nodes, output_nodes, learning_rate) #读取训练数据集 转化为列表
training_data_file = open("D:/mnist_train_100.csv",'r')
training_data_list = training_data_file.readlines();
training_data_file.close() #训练神经网络
for record in training_data_list:
#根据逗号,将文本数据进行拆分
all_values = record.split(',')
#将文本字符串转化为实数,并创建这些数字的数组。
inputs = (numpy.asfarray(all_values[1:])/255.0 * 0.99) + 0.01
#创建用零填充的数组,数组的长度为output_nodes,加0.01解决了0输入造成的问题
targets = numpy.zeros(output_nodes) + 0.01
#使用目标标签,将正确元素设置为0.99
targets[int(all_values[0])] = 0.99
n.train(inputs,targets)
pass #读取测试文件
test_data_file = open("D:/mnist_test_10.csv",'r')
test_data_list = test_data_file.readlines()
test_data_file.close() all_values = test_data_list[0].split(',')
print(all_values[0]) #输出目标值 image_array = numpy.asfarray(all_values[1:]).reshape((28,28))
print(n.query((numpy.asfarray(all_values[1:])/255.0*0.99)+0.01))#输出标签值
plt.imshow(image_array,cmap='Greys',interpolation='None')#显示原图像
pylab.show()
输出情况:
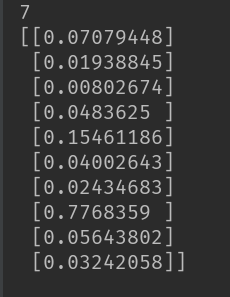
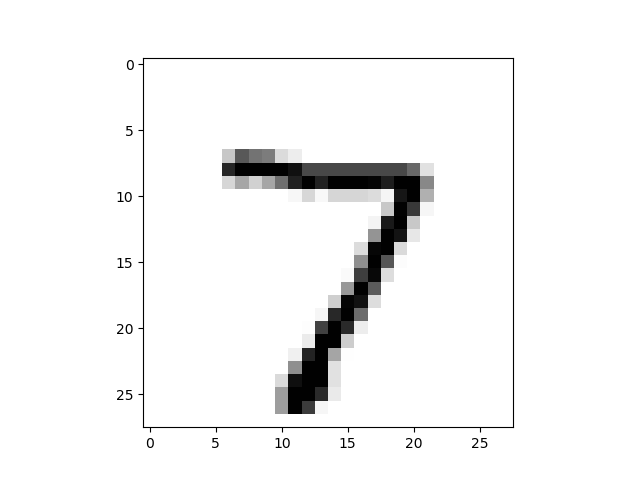
从结果可以看出,我们输入的目标值为7,结果中第7个标签所对应的值最大,表明了正确识别了目标值。和图片中的值一样。
神经网络的训练和测试 python的更多相关文章
- ensorflow学习笔记四:mnist实例--用简单的神经网络来训练和测试
http://www.cnblogs.com/denny402/p/5852983.html ensorflow学习笔记四:mnist实例--用简单的神经网络来训练和测试 刚开始学习tf时,我们从 ...
- tensorflow学习笔记四:mnist实例--用简单的神经网络来训练和测试
刚开始学习tf时,我们从简单的地方开始.卷积神经网络(CNN)是由简单的神经网络(NN)发展而来的,因此,我们的第一个例子,就从神经网络开始. 神经网络没有卷积功能,只有简单的三层:输入层,隐藏层和输 ...
- Python实现一个简单三层神经网络的搭建并测试
python实现一个简单三层神经网络的搭建(有代码) 废话不多说了,直接步入正题,一个完整的神经网络一般由三层构成:输入层,隐藏层(可以有多层)和输出层.本文所构建的神经网络隐藏层只有一层.一个神经网 ...
- 机器学习基础:(Python)训练集测试集分割与交叉验证
在上一篇关于Python中的线性回归的文章之后,我想再写一篇关于训练测试分割和交叉验证的文章.在数据科学和数据分析领域中,这两个概念经常被用作防止或最小化过度拟合的工具.我会解释当使用统计模型时,通常 ...
- 《TensorFlow实战》中AlexNet卷积神经网络的训练中
TensorFlow实战中AlexNet卷积神经网络的训练 01 出错 TypeError: as_default() missing 1 required positional argument: ...
- Caffe系列4——基于Caffe的MNIST数据集训练与测试(手把手教你使用Lenet识别手写字体)
基于Caffe的MNIST数据集训练与测试 原创:转载请注明https://www.cnblogs.com/xiaoboge/p/10688926.html 摘要 在前面的博文中,我详细介绍了Caf ...
- Caffe初试(二)windows下的cafee训练和测试mnist数据集
一.mnist数据集 mnist是一个手写数字数据库,由Google实验室的Corinna Cortes和纽约大学柯朗研究院的Yann LeCun等人建立,它有60000个训练样本集和10000个测试 ...
- Caffe上用SSD训练和测试自己的数据
学习caffe第一天,用SSD上上手. 我的根目录$caffe_root为/home/gpu/ljy/caffe 一.运行SSD示例代码 1.到https://github.com ...
- 物体检测算法 SSD 的训练和测试
物体检测算法 SSD 的训练和测试 GitHub:https://github.com/stoneyang/caffe_ssd Paper: https://arxiv.org/abs/1512.02 ...
随机推荐
- PHP保存Base64图片base64_decode的问题
PHP对Base64的支持非常好,有内置的base64_encode与base64_decode负责图片的Base64编码与解码. 编码上,只要将图片流读取到,而后使用base64_encode进行进 ...
- Debug get/set property
1. Select "Debug -> Windows -> Breakpoints" from VS menu. 2. Click "New -> B ...
- Android Studio 导入 AOSP 源码
有了 AOSP 源码,接下来就是如何看了,可以直接文本看,可以用 Source Insight,我当然选择 Android Studio,Android Studio 是我熟悉且十分强大的工具.问题来 ...
- SQL获得连续的记录的统计
SELECT TYEAR, MIN(TDATE) AS STARTDATE, MAX(TDATE), COUNT(TYEAR) AS ENDNUM --TYEAR年,STARTDATE连续记录的开始时 ...
- 如何找到Android app启动activity和页面元素信息
在实施app自动化的时候,我们需要知道app 的启动activity和页面元素信息,以此启动app和定位页面元素,那么如何在没有源码的情况下找打他们呢?当然是有好的工具啦,有Android sdk自带 ...
- selenium select 标签选中
public static int SetSelectedIndex(this IWebDriver webdriver, string selector, int selectedIndex) { ...
- python绘图 matplotlib教程
mark一个很好的python绘图教程 https://liam0205.me/2014/09/11/matplotlib-tutorial-zh-cn/
- 一种轻量级的C4C业务数据同步到S4HANA的方式:Odata通知
SAP Cloud for Customer和SAP其他传统产品的同步,除了使用SAP Netweaver Process Integration和SAP HANA Cloud Integration ...
- Uva 11582 巨大的斐波那契数 模运算
题目链接:https://vjudge.net/contest/156903#problem/A 题意:计算 f(a^b)%n 分析: 1.斐波那契数列是 f(i+2) = f(i+1) + f(i) ...
- spring教程(一):简单实现(转)
转:https://www.cnblogs.com/Lemon-i/p/8398263.html 一.概念介绍 1. 一站式框架:管理项目中的对象.spring框架性质是容器(对象容器) 2. 核心 ...