redis 有用 Sorted-Set 应用场景
1.1.1Set数据类型的 使用场景
1、可以使用Redis的Set数据类型跟踪一些唯一性数据,比如访问某一博客的唯一IP地址信息。对于此场景,我们仅需在每次访问该博客时将访问者的IP存入Redis中,Set数据类型会自动保证IP地址的唯一性。
2、充分利用Set类型的服务端聚合操作方便、高效的特性,可以用于维护数据对象之间的关联关系。比如所有购买某一电子设备的客户ID被存储在一个指定的Set中,而购买另外一种电子产品的客户ID被存储在另外一个Set中,如果此时我们想获取有哪些客户同时购买了这两种商品时,Set的intersections交集命令就可以充分发挥它的方便和效率的优势了。
1.1 存储sortedset
1.1.1 概述
Sorted-Set和Set类型极为相似,它们都是字符串的集合,都不允许重复的成员出现在一个Set中。它们之间的主要差别是Sorted-Set中的每一个成员都会有一个分数(score)与之关联,Redis正是通过分数来为集合中的成员进行从小到大的排序。然而需要额外指出的是,尽管Sorted-Set中的成员必须是唯一的,但是分数(score)却是可以重复的。
在Sorted-Set中添加、删除或更新一个成员都是非常快速的操作,其时间复杂度为集合中成员数量的对数。由于Sorted-Set中的成员在集合中的位置是有序的,因此,即便是访问位于集合中部的成员也仍然是非常高效的。事实上,Redis所具有的这一特征在很多其它类型的数据库中是很难实现的,换句话说,在该点上要想达到和Redis同样的高效,在其它数据库中进行建模是非常困难的。
例如:游戏排名、微博热点话题等使用场景。
1.1.1 扩展命令(了解)
l zrangebyscore key min max [withscores] [limit offset count]:返回分数在[min,max]的成员并按照分数从低到高排序。[withscores]:显示分数;[limit offset count]:offset,表明从脚标为offset的元素开始并返回count个成员。 分页排名
l zincrby key increment member:设置指定成员的增加的分数。返回值是更改后的分数。
l zcount key min max:获取分数在[min,max]之间的成员
l zrank key member:返回成员在集合中的排名。(从小到大)
l zrevrank key member:返回成员在集合中的排名。(从大到小)
1.1.1 使用场景
1、可以用于一个大型在线游戏的积分排行榜。每当玩家的分数发生变化时,可以执行ZADD命令更新玩家的分数,此后再通过ZRANGE命令获取积分TOPTEN的用户信息。当然我们也可以利用ZRANK命令通过username来获取玩家的排行信息。最后我们将组合使用ZRANGE和ZRANK命令快速的获取和某个玩家积分相近的其他用户的信息。
2、Sorted-Set类型还可用于构建索引数据。
1.1 消息订阅与发布
l subscribe channel:订阅频道,例:subscribe mychat,订阅mychat这个频道
l psubscribe channel*:批量订阅频道,例:psubscribe s*,订阅以”s”开头的频道
l publish channel content:在指定的频道中发布消息,如 publish mychat ‘today is a newday’
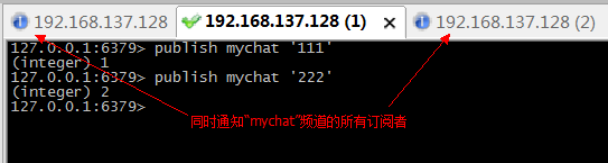
l 步骤1:在第一个连接中,订阅mychat频道。此时如果没有人“发布”消息,当前窗口处于等待状态。
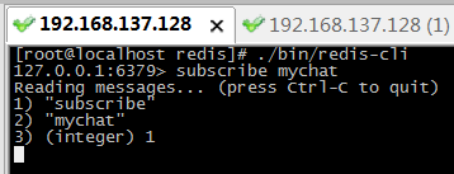
l 步骤2:在另一个窗口中,在mychat频道中,发布消息。
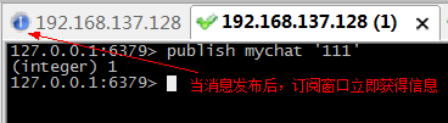
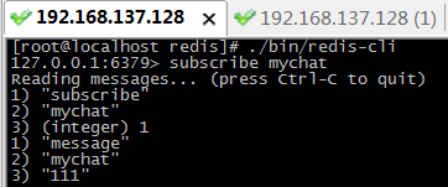
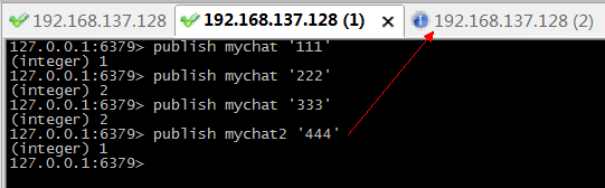
l 步骤3:再第三个窗口,批量订阅以my开头所有频道。
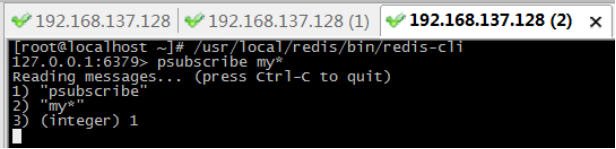
l 步骤4:在第二个窗口,分别在“mychat”和“mychat2”发布消息
1.1.1 redis事务特征
1、 在事务中的所有命令都将会被串行化的顺序执行,事务执行期间,Redis不会再为其它客户端的请求提供任何服务,从而保证了事物中的所有命令被原子的执行
2、 和关系型数据库中的事务相比,在Redis事务中如果有某一条命令执行失败,其后的命令仍然会被继续执行。
3、 我们可以通过MULTI命令开启一个事务,有关系型数据库开发经验的人可以将其理解为"BEGIN TRANSACTION"语句。在该语句之后执行的命令都将被视为事务之内的操作,最后我们可以通过执行EXEC/DISCARD命令来提交/回滚该事务内的所有操作。这两个Redis命令可被视为等同于关系型数据库中的COMMIT/ROLLBACK语句。
4、 在事务开启之前,如果客户端与服务器之间出现通讯故障并导致网络断开,其后所有待执行的语句都将不会被服务器执行。然而如果网络中断事件是发生在客户端执行EXEC命令之后,那么该事务中的所有命令都会被服务器执行。
1.1.1 优势
1、 该机制可以带来更高的数据安全性,即数据持久性。Redis中提供了3中同步策略,即每秒同步、每修改同步和不同步。事实上,每秒同步也是异步完成的,其效率也是非常高的,所差的是一旦系统出现宕机现象,那么这一秒钟之内修改的数据将会丢失。而每修改同步,我们可以将其视为同步持久化,即每次发生的数据变化都会被立即记录到磁盘中。可以预见,这种方式在效率上是最低的。至于无同步,无需多言,我想大家都能正确的理解它。
2、 由于该机制对日志文件的写入操作采用的是append模式,因此在写入过程中即使出现宕机现象,也不会破坏日志文件中已经存在的内容。然而如果我们本次操作只是写入了一半数据就出现了系统崩溃问题,不用担心,在Redis下一次启动之前,我们可以通过redis-check-aof工具来帮助我们解决数据一致性的问题。
3、 如果日志过大,Redis可以自动启用rewrite机制。即Redis以append模式不断的将修改数据写入到老的磁盘文件中,同时Redis还会创建一个新的文件用于记录此期间有哪些修改命令被执行。因此在进行rewrite切换时可以更好的保证数据安全性。
4、 AOF包含一个格式清晰、易于理解的日志文件用于记录所有的修改操作。事实上,我们也可以通过该文件完成数据的重建。
1.1.2 劣势
1、 对于相同数量的数据集而言,AOF文件通常要大于RDB文件
2、 根据同步策略的不同,AOF在运行效率上往往会慢于RDB。总之,每秒同步策略的效率是比较高的,同步禁用策略的效率和RDB一样高效。
第1章 redis使用场景(了解)
1、 取最新N个数据的操作
比如典型的取你网站的最新文章,通过下面方式,我们可以将最新的5000条评论的ID放在Redis的List集合中,并将超出集合部分从数据库获取
(1)使用LPUSH latest.comments <ID>命令,向list集合中插入数据
(2)插入完成后再用LTRIM latest.comments 0 5000命令使其永远只保存最近5000个ID
(3)然后我们在客户端获取某一页评论时可以用下面的逻辑(伪代码)
# 伪代码
FUNCTION get_latest_comments(start, num_items):
id_list = redis.lrange("latest.comments", start, start+num_items-1)
IF id_list.length < num_items
id_list = SQL_DB("SELECT ... ORDER BY time LIMIT ...")
END
RETURN id_list
END
如果你还有不同的筛选维度,比如某个分类的最新N条,那么你可以再建一个按此分类的List,只存ID的话,Redis是非常高效的。
2、 排行榜应用,取TOP N操作
这个需求与上面需求的不同之处在于,前面操作以时间为权重,这个是以某个条件为权重,比如按顶的次数排序,这时候就需要我们的sorted set出马了,将你要排序的值设置成sorted set的score,将具体的数据设置成相应的value,每次只需要执行一条ZADD命令即可。
3、 需要精准设定过期时间的应用
比如你可以把上面说到的sorted set的score值设置成过期时间的时间戳,那么就可以简单地通过过期时间排序,定时清除过期数据了,不仅是清除Redis中的过期数据,你完全可以把 Redis里这个过期时间当成是对数据库中数据的索引,用Redis来找出哪些数据需要过期删除,然后再精准地从数据库中删除相应的记录。
4、 计数器应用
Redis的命令都是原子性的,你可以轻松地利用INCR,DECR命令来构建计数器系统。
5、 Uniq操作,获取某段时间所有数据排重值
这个使用Redis的set数据结构最合适了,只需要不断地将数据往set中扔就行了,set意为集合,所以会自动排重。
6、 实时系统,反垃圾系统
通过上面说到的set功能,你可以知道一个终端用户是否进行了某个操作,可以找到其操作的集合并进行分析统计对比等。没有做不到,只有想不到。
7、 Pub/Sub构建实时消息系统
Redis的Pub/Sub系统可以构建实时的消息系统,比如很多用Pub/Sub构建的实时聊天系统的例子。
8、 构建队列系统
使用list可以构建队列系统,使用sorted set甚至可以构建有优先级的队列系统。
第1章 redis持久化(了解)
1.1 概述
Redis的高性能是由于其将所有数据都存储在了内存中,为了使Redis在重启之后仍能保证数据不丢失,需要将数据从内存中同步到硬盘中,这一过程就是持久化。
Redis支持两种方式的持久化,一种是RDB方式,一种是AOF方式。可以单独使用其中一种或将二者结合使用。
1、 RDB持久化(默认支持,无需配置)
该机制是指在指定的时间间隔内将内存中的数据集快照写入磁盘。
2、 AOF持久化
该机制将以日志的形式记录服务器所处理的每一个写操作,在Redis服务器启动之初会读取该文件来重新构建数据库,以保证启动后数据库中的数据是完整的。
3、 无持久化
我们可以通过配置的方式禁用Redis服务器的持久化功能,这样我们就可以将Redis视为一个功能加强版的memcached了。
4、 redis可以同时使用RDB和AOF
1.2 RDB
1.2.1 优势
1、 一旦采用该方式,那么你的整个Redis数据库将只包含一个文件,这对于文件备份而言是非常完美的。比如,你可能打算每个小时归档一次最近24小时的数据,同时还要每天归档一次最近30天的数据。通过这样的备份策略,一旦系统出现灾难性故障,我们可以非常容易的进行恢复。
2、 对于灾难恢复而言,RDB是非常不错的选择。因为我们可以非常轻松的将一个单独的文件压缩后再转移到其它存储介质上
3、 性能最大化。对于Redis的服务进程而言,在开始持久化时,它唯一需要做的只是fork(分叉)出子进程,之后再由子进程完成这些持久化的工作,这样就可以极大的避免服务进程执行IO操作了。
4、 相比于AOF机制,如果数据集很大,RDB的启动效率会更高。
1.2.2 劣势
1、 如果你想保证数据的高可用性,即最大限度的避免数据丢失,那么RDB将不是一个很好的选择。因为系统一旦在定时持久化之前出现宕机现象,此前没有来得及写入磁盘的数据都将丢失。
2、 由于RDB是通过fork子进程来协助完成数据持久化工作的,因此,如果当数据集较大时,可能会导致整个服务器停止服务几百毫秒,甚至是1秒钟
5、 当使用Append-Only模式时,Redis会通过调用系统函数write将该事务内的所有写操作在本次调用中全部写入磁盘。然而如果在写入的过程中出现系统崩溃,如电源故障导致的宕机,那么此时也许只有部分数据被写入到磁盘,而另外一部分数据却已经丢失。Redis服务器会在重新启动时执行一系列必要的一致性检测,一旦发现类似问题,就会立即退出并给出相应的错误提示。此时,我们就要充分利用Redis工具包中提供的redis-check-aof工具,该工具可以帮助我们定位到数据不一致的错误,并将已经写入的部分数据进行回滚。修复之后我们就可以再次重新启动Redis服务器了。
redis 有用 Sorted-Set 应用场景的更多相关文章
- 国内外三个不同领域巨头分享的Redis实战经验及使用场景
Redis不是比较成熟的memcache或者Mysql的替代品,是对于大型互联网类应用在架构上很好的补充.现在有越来越多的应用也在纷纷基于Redis做架构的改造.首先简单公布一下Redis平台实际情况 ...
- (转)国内外三个不同领域巨头分享的Redis实战经验及使用场景
随着应用对高性能需求的增加,NoSQL逐渐在各大名企的系统架构中生根发芽.这里我们将为大家分享社交巨头新浪微博.传媒巨头Viacom及图片分享领域佼佼者Pinterest带来的Redis实践,首先我们 ...
- 一:Redis的7个应用场景
Redis的7个应用场景 一:缓存——热数据 热点数据(经常会被查询,但是不经常被修改或者删除的数据),首选是使用redis缓存,毕竟强大到冒泡的QPS和极强的稳定性不是所有类似工具都有的,而且相 ...
- Redis各个数据类型的使用场景
Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合). Redis列表命令 参考:http://www.r ...
- Redis实战经验及使用场景
随着应用对高性能需求的增加,NoSQL逐渐在各大名企的系统架构中生根发芽.这里我们将为大家分享社交巨头新浪微博.传媒巨头Viacom及图片分享领域佼佼者Pinterest带来的Redis实践,首先我们 ...
- Redis各种数据类型的使用场景
Redis的六种特性 l Strings l Hashs l Lists l Sets l Sorted Sets l Pub/Sub Redis各特性的应用场景 Strings Strings 数据 ...
- Redis高级特性及应用场景
Redis高级特性及应用场景 redis中键的生存时间(expire) redis中可以使用expire命令设置一个键的生存时间,到时间后redis会自动删除它. 过期时间可以设置为秒或者毫秒精度. ...
- Redis作为消息队列服务场景应用案例
NoSQL初探之人人都爱Redis:(3)使用Redis作为消息队列服务场景应用案例 一.消息队列场景简介 “消息”是在两台计算机间传送的数据单位.消息可以非常简单,例如只包含文本字符串:也可以更 ...
- 细说Redis(一)之 Redis的数据结构与应用场景
这一篇文章主要介绍Redis的数据结构与应用场景 NOSQL之Redis Redis是一款由key-value存储的软件.说起NOSQL,有文档型.键值型.列型存储.图形数据库.其中,在简单的读写性能 ...
- Redis常见7种使用场景(PHP)
转发:https://www.jianshu.com/p/2f3add45351b Redis是一个开源的使用ANSI C语言编写.支持网络.可基于内存亦可持久化的日志型.Key-Value数据库,并 ...
随机推荐
- 每天一个Linux命令(16)which命令
which命令用于查找并显示给定命令的绝对路径. 环境变量PATH中保存了查找命令时需要遍历的目录.which指令会在环境变量$PATH设置的目录里查找符合条件的文件.也就是说,使用which命令,就 ...
- ios中文模糊搜索兼容问题
$(function(){ var cpLock = true; $("input[name='name']").off().on({ compositionstart: func ...
- 【leetcode刷题笔记】Remove Duplicates from Sorted List II
Given a sorted linked list, delete all nodes that have duplicate numbers, leaving only distinct numb ...
- 【九】MongoDB管理之安全性
要保证一个安全的MongoDB运行环境,DBA需要实施一些控制保证用户或应用程序仅仅访问它们需要的数据.这些措施包括但不限于: 认证机制 基于角色的访问控制 加密 审计 一.认证机制 认证是验证客户端 ...
- 双向链表(C++实现)
////////////////////////////////////////////////////////////////////////////////////// /////// 这里建立两 ...
- AdobeFlashPlayer.资料
1.chrome 设置 chrome-->设置-->高级-->内容设置-->Flash 2. 3. 4. 5.
- HDU 2089 不要62:数位dp
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=2089 题意: 问你在区间[n,m]中,有多少个数字不含"4"且不含"62 ...
- window.onload 添加多个函数绑定
window.onload = function(){alert(2)} function addEvent (fun) { var old = window.onload; if(typeof ol ...
- 各数据库连接配置与maven依赖安装
maven用的比较多,所以自己去捣鼓了一下:以下是关于数据库配置的一块,把相关的内容张贴出来,以备不时之需 //MySql 配置文件(maven):pom.xml <dependency> ...
- java:安装tomcat8/tomcat9(简单安装配置)
java:安装tomcat8/tomcat9(简单安装配置) pache-tomcat-8.5.23(免安装板) 1.安装完成后右击我的电脑—属性—高级系统设置—环境变量, 在系统变量中添加以下变量 ...