Celery-4.1 用户指南: Extensions and Bootsteps (扩展和Bootsteps)
自定义消息消费者
你可能想要嵌入自定义的 Kombu 消费者来手动处理你的消息。
为了达到这个目的,celery 提供了一个 ConsumerStep bootstep 类,你只需要定义 get_consumers 方法,它必须返回一个 kombu.Consumer 对象的列表,当连接建立时,这些对象将会启动。
- from celery import Celery
- from celery import bootsteps
- from kombu import Consumer, Exchange, Queue
- my_queue = Queue('custom', Exchange('custom'), 'routing_key')
- app = Celery(broker='amqp://')
- class MyConsumerStep(bootsteps.ConsumerStep):
- def get_consumers(self, channel):
- return [Consumer(channel,
- queues=[my_queue],
- callbacks=[self.handle_message],
- accept=['json'])]
- def handle_message(self, body, message):
- print('Received message: {0!r}'.format(body))
- message.ack()
- app.steps['consumer'].add(MyConsumerStep)
- def send_me_a_message(who, producer=None):
- with app.producer_or_acquire(producer) as producer:
- producer.publish(
- {'hello': who},
- serializer='json',
- exchange=my_queue.exchange,
- routing_key='routing_key',
- declare=[my_queue],
- retry=True,
- )
- if __name__ == '__main__':
- send_me_a_message('world!')
注意:
Kombu Consumer 使用了两种不同的消息回掉分发机制。第一种是接收一个回调函数列表,回调函数签名是 (body, message),另一种接收一个 on_message 参数,一个签名为 (message,) 的回调函数。后一种不是自动解码和反序列化负载。
- def get_consumers(self, channel):
- return [Consumer(channel, queues=[my_queue],
- on_message=self.on_message)]
- def on_message(self, message):
- payload = message.decode()
- print(
- 'Received message: {0!r} {props!r} rawlen={s}'.format(
- payload, props=message.properties, s=len(message.body),
- ))
- message.ack()
Blueprints
Bootsteps 是一个给工作单元添加功能的技术。一个 bootstep 是一个自定义的类,它自定义了一些在工作单元的不同阶段执行的操作。每个 bootstep 属于一个 blueprint,并且工作单元当前定义了两个 blueprints: Worker 和 Consumer。
图A: Worker 和 Consumer 中的 Bootsteps。从底至上,Worker blueprint 中的第一步是 Timer,最后一步是启动 Consumer blueprint,然后是建立与消息中间件的连接并且开始消费消息。
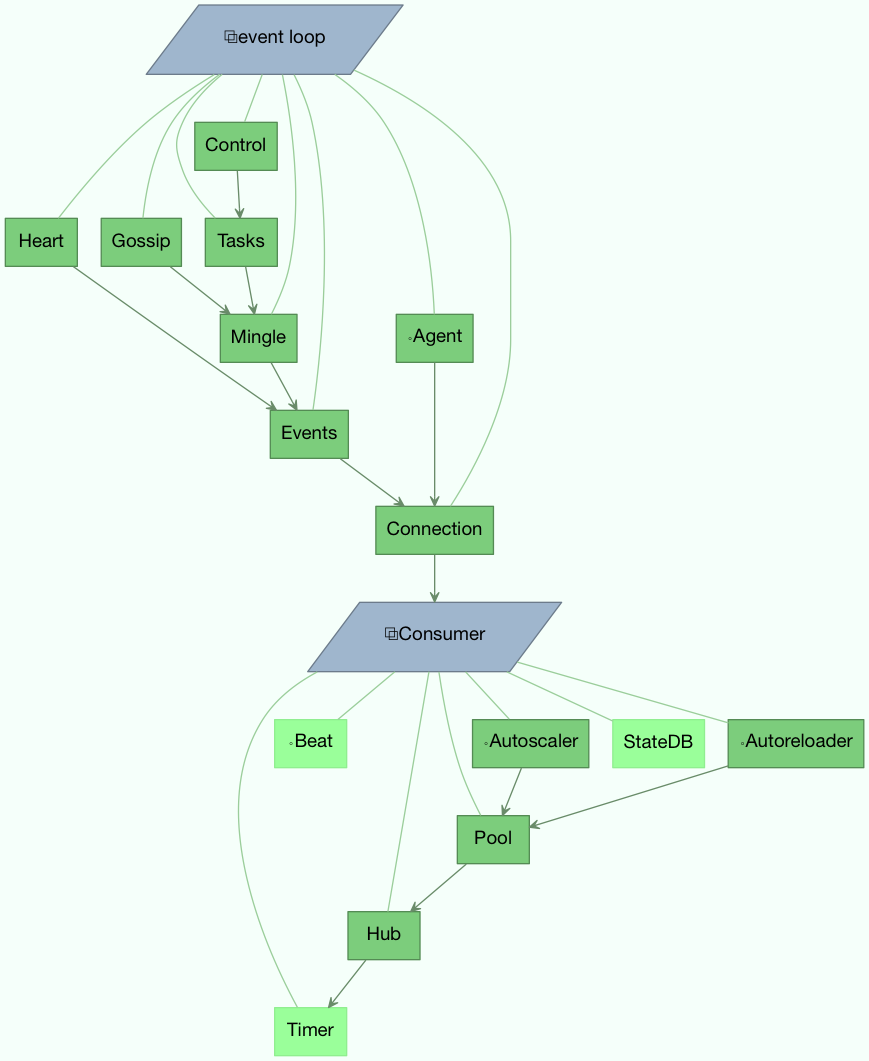
工作单元
工作单元是开启的第一个blueprint,并且随着它启动一些主要组件,如 event loop, processing pool, ETA任务的定时器以及其他定时事件。
当工作单元完全启动,它将继续启动 Consumer blueprint,用来设置任务怎么被执行、连接到消息中间件以及启动消息消费者。
WorkController 是核心的工作单元实现,并且包含了一些你能在自定义的bootstep中使用的方法和属性。
属性
app
当前 app 应用实例hostname
工作单元节点名称 (例如: worker1@example.com)blueprint
工作单元 Blueprinthub
消息循环对象(Hub)。你可以用来在事件循环中注册回调函数。
这只在启用了异步IO的传输层(amqp, redis)上有支持,此时 worker.use_eventloop 属性应该被设置。
你的工作单元 bootstep 必须需要 Hub bootstep 来使用它:
- class WorkerStep(bootsteps.StartStopStep):
- requires = {'celery.worker.components:Hub'}
- pool
当前的process/eventlet/gevent/thread池。查看celery.concurrency.base.BasePool。
你的工作单元 bootstep 必须需要 Pool bootstep 来使用它:
- class WorkerStep(bootsteps.StartStopStep):
- requires = {'celery.worker.components:Pool'}
- timer
调度函数的定时器。
你的工作单元 bootstep 必须需要 Timer bootstep 来使用它:
- class WorkerStep(bootsteps.StartStopStep):
- requires = {'celery.worker.components:Timer'}
- statedb
数据库<celery.worker.state.Persistent>用来在工作单元重启之间持久化状态。
statedb 参数被启用时它才被定义。
你的工作单元 bootstep 必须需要 State bootstep 来使用它:
- class WorkerStep(bootsteps.StartStopStep):
- requires = {'celery.worker.components:Statedb'}
- autoscacler
Autoscaler用来自动扩展和收缩池中的进程数。
autoscaler参数被启用时它才被定义。
你的工作单元 bootstep 必须需要 Autoscaler bootstep 来使用它:
- class WorkerStep(bootsteps.StartStopStep):
- requires = ('celery.worker.autoscaler:Autoscaler',)
- autoreloader
Autoreloader用来在文件系统发生改变时自动重新加载代码。
autoreloader参数被启用时它才被定义。
你的工作单元 bootstep 必须需要 Autoreloader bootstep 来使用它:
- class WorkerStep(bootsteps.StartStopStep):
- requires = ('celery.worker.autoreloader:Autoreloader',)
工作单元bootstep示例
工作单元bootstep 示例:
- from celery import bootsteps
- class ExampleWorkerStep(bootsteps.StartStopStep):
- requires = {'celery.worker.components:Pool'}
- def __init__(self, worker, **kwargs):
- print('Called when the WorkController instance is constructed')
- print('Arguments to WorkController: {0!r}'.format(kwargs))
- def create(self, worker):
- # this method can be used to delegate the action methods
- # to another object that implements ``start`` and ``stop``.
- return self
- def start(self, worker):
- print('Called when the worker is started.')
- def stop(self, worker):
- print('Called when the worker shuts down.')
- def terminate(self, worker):
- print('Called when the worker terminates')
每个方法都将 WorkController 实例作为第一个参数进行传递。
另一个示例使用定时器在规定的时间间隔进行唤醒:
- from celery import bootsteps
- class DeadlockDetection(bootsteps.StartStopStep):
- requires = {'celery.worker.components:Timer'}
- def __init__(self, worker, deadlock_timeout=3600):
- self.timeout = deadlock_timeout
- self.requests = []
- self.tref = None
- def start(self, worker):
- # run every 30 seconds.
- self.tref = worker.timer.call_repeatedly(
- 30.0, self.detect, (worker,), priority=10,
- )
- def stop(self, worker):
- if self.tref:
- self.tref.cancel()
- self.tref = None
- def detect(self, worker):
- # update active requests
- for req in worker.active_requests:
- if req.time_start and time() - req.time_start > self.timeout:
- raise SystemExit()
消费者
消费者blueprint建立一个与消息中间件的连接,并且每次连接丢失时将重新开始。消费者bootsteps 包括工作单元心跳、远程控制命令消费者,以及最重要的任务消费者。
当你创建自定义的消费者 bootsteps,你必须考虑到它必须能够重启你的blueprint。一个附加的shutdown方法必须在每一个消费者 bootstep 中定义,这个方法在工作单元被关闭时调用。
属性
app
当前 app 应用实例hostname
工作单元节点名称 (例如: worker1@example.com)blueprint
工作单元 Blueprinthub
消息循环对象(Hub)。你可以用来在事件循环中注册回调函数。
这只在启用了异步IO的传输层(amqp, redis)上有支持,此时 worker.use_eventloop 属性应该被设置。
你的工作单元 bootstep 必须需要 Hub bootstep 来使用它:
- class WorkerStep(bootsteps.StartStopStep):
- requires = {'celery.worker.components:Hub'}
- connection
当前的消息中间件连接kombu.Connection
一个消费者bootstep必须需要Connection bootstep来使用它:
- class Step(bootsteps.StartStopStep):
- requires = {'celery.worker.consumer.connection:Connection'}
- event_dispatcher
一个app.events.Dispatcher对象可以用来发送事件。
一个消费者bootstep必须需要Events bootstep来使用它:
- class Step(bootsteps.StartStopStep):
- requires = {'celery.worker.consumer.events:Events'}
- gossip
工作单元到工作单元的广播通信(Gossip)
一个消费者bootstep必须需要Gossip bootstep来使用它:
- class RatelimitStep(bootsteps.StartStopStep):
- """Rate limit tasks based on the number of workers in the
- cluster."""
- requires = {'celery.worker.consumer.gossip:Gossip'}
- def start(self, c):
- self.c = c
- self.c.gossip.on.node_join.add(self.on_cluster_size_change)
- self.c.gossip.on.node_leave.add(self.on_cluster_size_change)
- self.c.gossip.on.node_lost.add(self.on_node_lost)
- self.tasks = [
- self.app.tasks['proj.tasks.add']
- self.app.tasks['proj.tasks.mul']
- ]
- self.last_size = None
- def on_cluster_size_change(self, worker):
- cluster_size = len(list(self.c.gossip.state.alive_workers()))
- if cluster_size != self.last_size:
- for task in self.tasks:
- task.rate_limit = 1.0 / cluster_size
- self.c.reset_rate_limits()
- self.last_size = cluster_size
- def on_node_lost(self, worker):
- # may have processed heartbeat too late, so wake up soon
- # in order to see if the worker recovered.
- self.c.timer.call_after(10.0, self.on_cluster_size_change)
回调
- gossip.on.node_join
当一个新的节点加入到集群中时调用,提供一个工作单元实例参数
- gossip.on.node_leave
当一个新的节点离开到集群中时调用(关闭时),提供一个工作单元实例参数
gossip.on.node_lost
当集群中工作单元的心跳丢失(心跳没有及时收到或者处理),提供一个工作单元实例参数pool
当前 process/eventlet/gevent/thread 池
查看celery.concurrency.base.BasePool
timer
定时器celery.utils.timer2.Schedule用来调度函数heart
负责发送工作单元事件心跳 (Heart)
消费者bootstep必须需要Heartbeat bootstep来使用它:
- class Step(bootsteps.StartStopStep):
- requires = {'celery.worker.consumer.heart:Heart'}
- task_consumer
kombu.Consumer对象用来消费任务消息
消费者bootstep必须需要Tasks bootstep来使用它:
- class Step(bootsteps.StartStopStep):
- requires = {'celery.worker.consumer.tasks:Tasks'}
- strategies
每个已经注册的任务在这个映射中都有一项, 值用来执行一个进来的该类型的消息 (任务执行策略)。这个映射是在消费者启动时由 Tasks bootstep 产生的:
- for name, task in app.tasks.items():
- strategies[name] = task.start_strategy(app, consumer)
- task.__trace__ = celery.app.trace.build_tracer(
- name, task, loader, hostname
- )
消费者bootstep必须需要Tasks bootstep来使用它:
- class Step(bootsteps.StartStopStep):
- requires = {'celery.worker.consumer.tasks:Tasks'}
- task_buckets
一个根据任务类型查找速率限制的defaultdict。这个字典中的项可以为None(没有限制),或者TokenBucket实例,实现了 consume(tokens) 和 expected_time(tokens)。
TokenBucket实现了 token bucket 算法,只要遵循相同接口并且定义了者两个方法的任何算法都可以被使用。
- qos
QoS对象可以用来修改任务通道当前的 prefetch 值:
- # increment at next cycle
- consumer.qos.increment_eventually(1)
- # decrement at next cycle
- consumer.qos.decrement_eventually(1)
- consumer.qos.set(10)
方法
consumer.reset_rate_limits()
为所有注册的任务类型更新 task_buckets 映射consumer.bucket_for_task(type, Bucket=TokenBucket)
使用task.rate_limit属性为一个任务创建速率限制bucket。consumer.add_task_queue(name, exchange=None, exchange_type=None,
routing_key=None, **options):
添加新的被消费队列。当连接重启这也存在consumer.cancel_task_queue(name)
停止从指定名称的队列消费消息。当连接重启这也存在apply_eta_task(request)
基于request.eta attribute属性调度一个 ETA 任务。(Request)
安装步骤
可以通过修改 app.steps['worker'] 和 app.steps['consumer'] 添加新的 bootstep:
- >>> app = Celery()
- >>> app.steps['worker'].add(MyWorkerStep) # < add class, don't instantiate
- >>> app.steps['consumer'].add(MyConsumerStep)
- >>> app.steps['consumer'].update([StepA, StepB])
- >>> app.steps['consumer']
- {step:proj.StepB{()}, step:proj.MyConsumerStep{()}, step:proj.StepA{()}
因为执行顺序是由结果图(Step.requires)决定,所以在这里步骤的顺序不重要。
为了说明你这么安装 bootsteps 以及他么如何工作,如下示例step打印一些无用的调试信息。它可以作为工作单元bootstep和消费者bootstep被添加:
- from celery import Celery
- from celery import bootsteps
- class InfoStep(bootsteps.Step):
- def __init__(self, parent, **kwargs):
- # here we can prepare the Worker/Consumer object
- # in any way we want, set attribute defaults, and so on.
- print('{0!r} is in init'.format(parent))
- def start(self, parent):
- # our step is started together with all other Worker/Consumer
- # bootsteps.
- print('{0!r} is starting'.format(parent))
- def stop(self, parent):
- # the Consumer calls stop every time the consumer is
- # restarted (i.e., connection is lost) and also at shutdown.
- # The Worker will call stop at shutdown only.
- print('{0!r} is stopping'.format(parent))
- def shutdown(self, parent):
- # shutdown is called by the Consumer at shutdown, it's not
- # called by Worker.
- print('{0!r} is shutting down'.format(parent))
- app = Celery(broker='amqp://')
- app.steps['worker'].add(InfoStep)
- app.steps['consumer'].add(InfoStep)
启动安装了这个步骤的工作单元将显示如下日志:
- <Worker: w@example.com (initializing)> is in init
- <Consumer: w@example.com (initializing)> is in init
- [2013-05-29 16:18:20,544: WARNING/MainProcess]
- <Worker: w@example.com (running)> is starting
- [2013-05-29 16:18:21,577: WARNING/MainProcess]
- <Consumer: w@example.com (running)> is starting
- <Consumer: w@example.com (closing)> is stopping
- <Worker: w@example.com (closing)> is stopping
- <Consumer: w@example.com (terminating)> is shutting down
工作单元初始化后, print语句将被重定向到日志子系统,所以is starting这一行打上了时间戳。你可以注意到在关闭时将不会出现这种现象,因为stop和shutdown方法在一个信号处理函数中被调用,并且在其中使用日志是不安全的。使用python日志模块记录日志不是可重入的:意味着你不能中断这个函数之后又调用它。有一点重要的是stop和shutdown方法是可重入的。
启动工作单元时使用 --loglevel=debug选项将显示给我们关于启动过程的更详细的信息:
- [2013-05-29 16:18:20,509: DEBUG/MainProcess] | Worker: Preparing bootsteps.
- [2013-05-29 16:18:20,511: DEBUG/MainProcess] | Worker: Building graph...
- <celery.apps.worker.Worker object at 0x101ad8410> is in init
- [2013-05-29 16:18:20,511: DEBUG/MainProcess] | Worker: New boot order:
- {Hub, Pool, Timer, StateDB, Autoscaler, InfoStep, Beat, Consumer}
- [2013-05-29 16:18:20,514: DEBUG/MainProcess] | Consumer: Preparing bootsteps.
- [2013-05-29 16:18:20,514: DEBUG/MainProcess] | Consumer: Building graph...
- <celery.worker.consumer.Consumer object at 0x101c2d8d0> is in init
- [2013-05-29 16:18:20,515: DEBUG/MainProcess] | Consumer: New boot order:
- {Connection, Mingle, Events, Gossip, InfoStep, Agent,
- Heart, Control, Tasks, event loop}
- [2013-05-29 16:18:20,522: DEBUG/MainProcess] | Worker: Starting Hub
- [2013-05-29 16:18:20,522: DEBUG/MainProcess] ^-- substep ok
- [2013-05-29 16:18:20,522: DEBUG/MainProcess] | Worker: Starting Pool
- [2013-05-29 16:18:20,542: DEBUG/MainProcess] ^-- substep ok
- [2013-05-29 16:18:20,543: DEBUG/MainProcess] | Worker: Starting InfoStep
- [2013-05-29 16:18:20,544: WARNING/MainProcess]
- <celery.apps.worker.Worker object at 0x101ad8410> is starting
- [2013-05-29 16:18:20,544: DEBUG/MainProcess] ^-- substep ok
- [2013-05-29 16:18:20,544: DEBUG/MainProcess] | Worker: Starting Consumer
- [2013-05-29 16:18:20,544: DEBUG/MainProcess] | Consumer: Starting Connection
- [2013-05-29 16:18:20,559: INFO/MainProcess] Connected to amqp://guest@127.0.0.1:5672//
- [2013-05-29 16:18:20,560: DEBUG/MainProcess] ^-- substep ok
- [2013-05-29 16:18:20,560: DEBUG/MainProcess] | Consumer: Starting Mingle
- [2013-05-29 16:18:20,560: INFO/MainProcess] mingle: searching for neighbors
- [2013-05-29 16:18:21,570: INFO/MainProcess] mingle: no one here
- [2013-05-29 16:18:21,570: DEBUG/MainProcess] ^-- substep ok
- [2013-05-29 16:18:21,571: DEBUG/MainProcess] | Consumer: Starting Events
- [2013-05-29 16:18:21,572: DEBUG/MainProcess] ^-- substep ok
- [2013-05-29 16:18:21,572: DEBUG/MainProcess] | Consumer: Starting Gossip
- [2013-05-29 16:18:21,577: DEBUG/MainProcess] ^-- substep ok
- [2013-05-29 16:18:21,577: DEBUG/MainProcess] | Consumer: Starting InfoStep
- [2013-05-29 16:18:21,577: WARNING/MainProcess]
- <celery.worker.consumer.Consumer object at 0x101c2d8d0> is starting
- [2013-05-29 16:18:21,578: DEBUG/MainProcess] ^-- substep ok
- [2013-05-29 16:18:21,578: DEBUG/MainProcess] | Consumer: Starting Heart
- [2013-05-29 16:18:21,579: DEBUG/MainProcess] ^-- substep ok
- [2013-05-29 16:18:21,579: DEBUG/MainProcess] | Consumer: Starting Control
- [2013-05-29 16:18:21,583: DEBUG/MainProcess] ^-- substep ok
- [2013-05-29 16:18:21,583: DEBUG/MainProcess] | Consumer: Starting Tasks
- [2013-05-29 16:18:21,606: DEBUG/MainProcess] basic.qos: prefetch_count->80
- [2013-05-29 16:18:21,606: DEBUG/MainProcess] ^-- substep ok
- [2013-05-29 16:18:21,606: DEBUG/MainProcess] | Consumer: Starting event loop
- [2013-05-29 16:18:21,608: WARNING/MainProcess] celery@example.com ready.
命令行程序
添加新的命令行选项
Command-specific 选项
通过修改应用实例的 user_options 属性,你可以给 worker、beat和events 添加命令行选项。
Celery 使用 argparse 模块来解析命令行参数,所以要添加自定义命令行参数,你需要声明一个回调函数,参数为 argparse.ArgumentParser 实例,然后添加参数。请查看 argparse 文档获取更多关于支持字段的信息。
给 celery worker 添加一个自定义的选项的示例:
- from celery import Celery
- app = Celery(broker='amqp://')
- def add_worker_arguments(parser):
- parser.add_argument(
- '--enable-my-option', action='store_true', default=False,
- help='Enable custom option.',
- ),
- app.user_options['worker'].add(add_worker_arguments)
所有的bootsteps都将会收到这个参数作为Bootstep.__init__函数的关键字参数。
- from celery import bootsteps
- class MyBootstep(bootsteps.Step):
- def __init__(self, worker, enable_my_option=False, **options):
- if enable_my_option:
- party()
- app.steps['worker'].add(MyBootstep)
预加载选项
celery 总命令支持预加载的概念。这些特殊的选项将传递给所有的子命令,并且在main解析步骤之外被解析。
一个默认的预加载选项的列表可以在 API 引用中找到:celery.bin.base
你也可以添加新的预加载选项,例如声明一个配置模板:
- from celery import Celery
- from celery import signals
- from celery.bin import Option
- app = Celery()
- def add_preload_options(parser):
- parser.add_argument(
- '-Z', '--template', default='default',
- help='Configuration template to use.',
- )
- app.user_options['preload'].add(add_preload_options)
- @signals.user_preload_options.connect
- def on_preload_parsed(options, **kwargs):
- use_template(options['template'])
添加新的celery 子命令
新的子命令可以被添加进celery 总命令,只要使用 setuptools entry-points 即可。
Entry-points 是一个特殊的元信息,它可以添加到你的包 setup.py 程序,安装后,使用 pkg_resources 模块从系统中读取。
celery 会识别 celery.commands entry-points 来安装额外的子命令,entry-point的值必须指向一个合法的 celery.bin.base.Command 子类。很不幸的是,文档有限,但是你可以celery.bin包中的各种命令中找到灵感。
下面是 Flower 监控扩展如何添加子命令 celery flower 的示例,通过在 setup.py 中添加一个 entry-point:
- setup(
- name='flower',
- entry_points={
- 'celery.commands': [
- 'flower = flower.command:FlowerCommand',
- ],
- }
- )
命令的定义是用等号分隔的两部分组成,第一个部分是子明了的名称(flower),第二部分是一个全限定的命令实现类的符号路径:
- flower.command:FlowerCommand
模块路径和属性名称应该使用冒号分隔,如上所示。
在模块 flower/command.py 中,命令类如下定义所示:
- from celery.bin.base import Command
- class FlowerCommand(Command):
- def add_arguments(self, parser):
- parser.add_argument(
- '--port', default=8888, type='int',
- help='Webserver port',
- ),
- parser.add_argument(
- '--debug', action='store_true',
- )
- def run(self, port=None, debug=False, **kwargs):
- print('Running our command')
工作单元 API
Hub - 工作单元异步消息循环
supported transports: amqp, redis
3.0版本新特性。
当使用amqp或者redis消息中间件时,工作单元使用异步I/O。最终的目的是所有的传输中间件都使用事件循环,但是这需要时间,所以其他的传输中间件仍然使用基于线程的解决方案。
hub.add(fd, callback, flags)
hub.add_reader(fd, callback, *args)
添加回调函数,当fd可读时调用
回调函数将保持注册状态直到使用 hub.remove(fd)显示的移除,或者由于文件描述符不在合法而被自动删除。
注意对于一个给定的文件描述符一次只能注册一个回调函数,所以第二次调用 add 方法将自动移除掉前面为这个文件描述符注册的回调函数。
文件描述符是一个类似文件的对象,支持 fileno 方法,后者它也可以是文件描述符数字(int)。
hub.add_writer(fd, callback, *args)
添加回调函数,当fd可写时被调用。查看上述hub.add_reader()hub.remove(fd)
从循环中移除掉文件描述符fd的所有回调函数。
定时器 - 调度事件
- timer.call_after(secs, callback, args=(), kwargs=(),
priority=0) - timer.call_repeatedly(secs, callback, args=(), kwargs=(),
priority=0) - timer.call_at(eta, callback, args=(), kwargs=(),
priority=0)
转自:https://blog.csdn.net/libing_thinking/article/details/78623766
Celery-4.1 用户指南: Extensions and Bootsteps (扩展和Bootsteps)的更多相关文章
- Celery-4.1 用户指南: Calling Tasks(调用任务)
基础 本文档描述 Celery 中任务实例和 Canvas 使用的统一 “Calling API”. API 中定义了一个执行选项的标准集,以及三个方法: - apply_async(args[, k ...
- Gradle用户指南(1)-Gradle安装
前置条件 Gradle 需要 Java JDK 或者 JRE,版本是 6 及以上.Gradle 将会装载自己的 Groovy 库,因此,Groovy 不需要被安装.任何存在的 Groovy 安装都会被 ...
- Gradle用户指南(章9:Groovy快速入门)
Gradle用户指南(章9:Groovy快速入门) 你可以使用groovy插件来构建groovy项目.这个插件继承了java插件的功能,且扩展了groovy编译.你的项目可以包含groovy代码.ja ...
- Gradle用户指南
下载安装gradle 2.1 下载地址:http://www.gradle.org/learn 安装先决条件:gradle安装需要1.6或者更高版本的jdk(jre)(可以使用java –versio ...
- scons用户指南翻译(附gcc/g++参数详解)
scons用户指南 翻译 http://blog.csdn.net/andyelvis/article/category/948141 官网文档 http://www.scons.org/docume ...
- 阿里云 EDAS-HSF 用户指南
阿里云 EDAS-HSF 用户指南 针对 EDAS v2.3.0©Alibaba EDAS 项目组2015/8/19 1 前言本文档旨在描述阿里云 EDAS 产品中应用服务化模块的基本概念,以及如何使 ...
- 【Flume NG用户指南】(1)设置
作者:周邦涛(Timen) Email:zhoubangtao@gmail.com 转载请注明出处: http://blog.csdn.net/zhoubangtao/article/details ...
- Android官方技术文档翻译——Gradle 插件用户指南(1-3)
不知道是什么网络问题,上午一直发不了博客,其它页面基本正常,就是在写博客这里,每次打开都是响应超时.刚才用了VPN,顺便试了一下,竟然能够编辑.想是CDN之类的问题吧. 这次翻译的是Gradle 插件 ...
- 【Flume NG用户指南】(2)构造
作者:周邦涛(Timen) Email:zhoubangtao@gmail.com 转载请注明出处: http://blog.csdn.net/zhoubangtao/article/details ...
随机推荐
- 【bzoj4765】普通计算姬(双重分块)
题目传送门:http://www.lydsy.com/JudgeOnline/problem.php?id=4765 这道题已经攒了半年多了...因为懒,一直没去写...所以今天才把这道题写出来... ...
- org.apache.flume.ChannelException: Take list for MemoryTransaction, capacity 100 full, consider committing more frequently, increasing capacity, or increasing thread count
flume在抽取MySQL数据到kafka时报错,如下 [SinkRunner-PollingRunner-DefaultSinkProcessor] ERROR org.apache.flume.s ...
- HDFS数据完整性
数据完整性 Hadoop用户肯定都希望系统在存储和处理数据时不会丢失或损坏任何数据.尽管磁盘或网络上的每个I/O操作不太可能将错误引入自己正在读/写的数据中,但是如果系统中需要处理的数据量大到Hado ...
- MVC 控件系列
下拉框:@Html.DropDownList("GroupId"); 文本框:@Html.TextBox("RoleCode", "", n ...
- RtlWerpReportException failed with status code :-1073741823
在release下程序运行总是崩溃:debugView输出了这个崩溃信息, 1. 一开始是release看崩溃,各种二分法找崩溃点,太玄没找到: 2. 终于想到可以调试,我草,调试一下瞬间发现某个cl ...
- Spring Boot入门——多文件上传大小超限问题解决
多文件上传中遇到上传文件大小的问题 org.apache.tomcat.util.http.fileupload.FileUploadBase$FileSizeLimitExceededExcepti ...
- java RC4加密解密
package com.dgut.app.utils; import java.lang.Byte; import java.util.UUID; public class RC4 { public ...
- 英语发音规则---U字母-[复习中]
英语发音规则---U字母 一.总结 一句话总结:(注:本文所有//的音标为英音音标,[]的音标为美音音标) 1.U在开音节中发[ju ]/ ju: /? duty /'djuːtɪ/ ['dʊti] ...
- 在express中提供静态文件笔记
在express中提供静态文件 要在express框架中提供静态文件,如:css.javascript等文件,就要使用到他的内置中间件功能express.static,将包含静态文件目录文件传递给ex ...
- swagger 在apache CXF 中的使用——JAX-RS Swagger2Feature
The CXF Swagger2Feature allows you to generate Swagger 2.0 documents from JAX-RS service endpoints w ...