SparkSQL的3种Join实现
引言
Join是SQL语句中的常用操作,良好的表结构能够将数据分散在不同的表中,使其符合某种范式,减少表冗余、更新容错等。而建立表和表之间关系的最佳方式就是Join操作。
对于Spark来说有3中Join的实现,每种Join对应着不同的应用场景:
- Broadcast Hash Join : 适合一张较小的表和一张大表进行join
- Shuffle Hash Join : 适合一张小表和一张大表进行join,或者是两张小表之间的join
- Sort Merge Join : 适合两张较大的表之间进行join
前两者都基于的是Hash Join,只不过在hash join之前需要先shuffle还是先broadcast。下面将详细的解释一下这三种不同的join的具体原理
Hash Join
先来看看这样一条SQL语句:select * from order,item where item.id = order.i_id,很简单一个Join节点,参与join的两张表是item和order,join key分别是item.id以及order.i_id。现在假设这个Join采用的是hash join算法,整个过程会经历三步:
1. 确定Build Table以及Probe Table:这个概念比较重要,Build Table使用join key构建Hash Table,而Probe Table使用join key进行探测,探测成功就可以join在一起。通常情况下,小表会作为Build Table,大表作为Probe Table。此事例中item为Build Table,order为Probe Table;
2. 构建Hash Table:依次读取Build Table(item)的数据,对于每一行数据根据join key(item.id)进行hash,hash到对应的Bucket,生成hash table中的一条记录。数据缓存在内存中,如果内存放不下需要dump到外存;
3. 探测:再依次扫描Probe Table(order)的数据,使用相同的hash函数映射Hash Table中的记录,映射成功之后再检查join条件(item.id = order.i_id),如果匹配成功就可以将两者join在一起。
基本流程可以参考上图,这里有两个小问题需要关注:
1. hash join性能如何?很显然,hash join基本都只扫描两表一次,可以认为o(a+b),较之最极端的笛卡尔集运算a*b,不知甩了多少条街;
2. 为什么Build Table选择小表?道理很简单,因为构建的Hash Table最好能全部加载在内存,效率最高;这也决定了hash join算法只适合至少一个小表的join场景,对于两个大表的join场景并不适用。
上文说过,hash join是传统数据库中的单机join算法,在分布式环境下需要经过一定的分布式改造,说到底就是尽可能利用分布式计算资源进行并行化计算,提高总体效率。hash join分布式改造一般有两种经典方案:
1. broadcast hash join:将其中一张小表广播分发到另一张大表所在的分区节点上,分别并发地与其上的分区记录进行hash join。broadcast适用于小表很小,可以直接广播的场景;
2. shuffler hash join:一旦小表数据量较大,此时就不再适合进行广播分发。这种情况下,可以根据join key相同必然分区相同的原理,将两张表分别按照join key进行重新组织分区,这样就可以将join分而治之,划分为很多小join,充分利用集群资源并行化。
Broadcast Hash Join
大家知道,在数据库的常见模型中(比如星型模型或者雪花模型),表一般分为两种:事实表和维度表。维度表一般指固定的、变动较少的表,例如联系人、物品种类等,一般数据有限。而事实表一般记录流水,比如销售清单等,通常随着时间的增长不断膨胀。
因为Join操作是对两个表中key值相同的记录进行连接,在SparkSQL中,对两个表做Join最直接的方式是先根据key分区,再在每个分区中把key值相同的记录拿出来做连接操作。但这样就不可避免地涉及到shuffle,而shuffle在Spark中是比较耗时的操作,我们应该尽可能的设计Spark应用使其避免大量的shuffle。
当维度表和事实表进行Join操作时,为了避免shuffle,我们可以将大小有限的维度表的全部数据分发到每个节点上,供事实表使用。executor存储维度表的全部数据,一定程度上牺牲了空间,换取shuffle操作大量的耗时,这在SparkSQL中称作Broadcast Join,如下图所示:
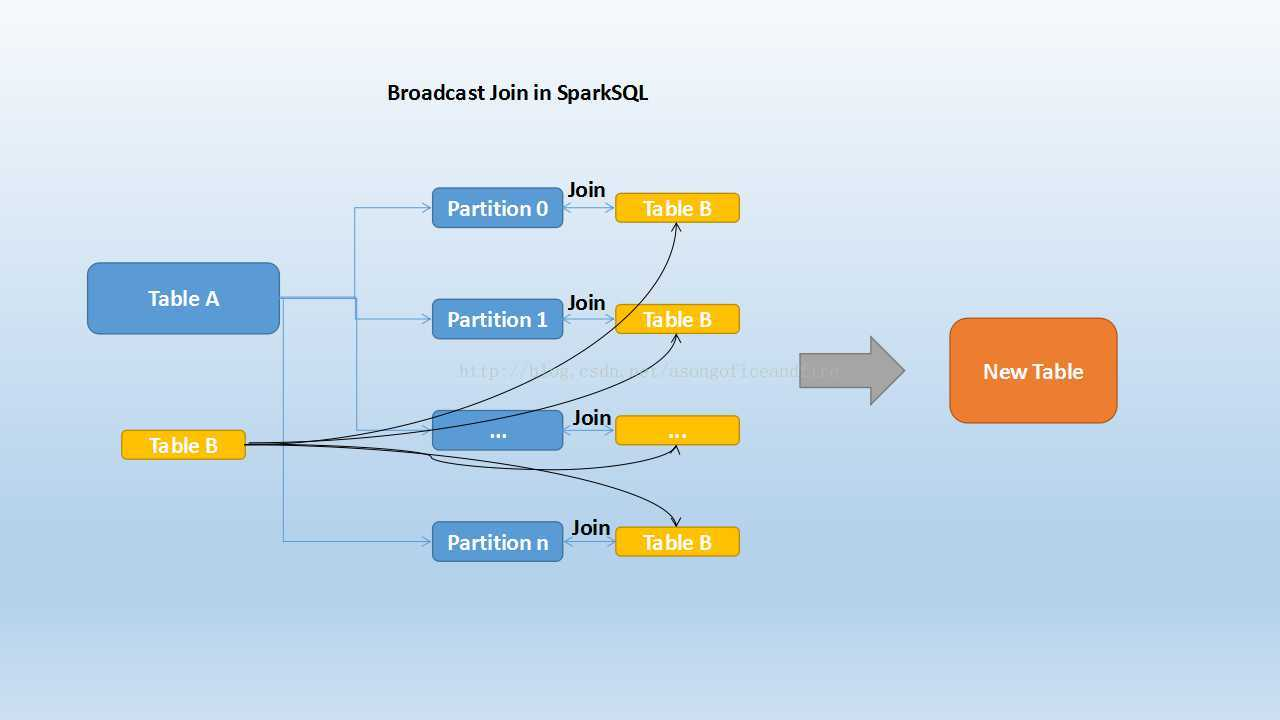
Table B是较小的表,黑色表示将其广播到每个executor节点上,Table A的每个partition会通过block manager取到Table A的数据。根据每条记录的Join Key取到Table B中相对应的记录,根据Join Type进行操作。这个过程比较简单,不做赘述。
Broadcast Join的条件有以下几个:
1. 被广播的表需要小于spark.sql.autoBroadcastJoinThreshold所配置的值,默认是10M (或者加了broadcast join的hint)
2. 基表不能被广播,比如left outer join时,只能广播右表
看起来广播是一个比较理想的方案,但它有没有缺点呢?也很明显。这个方案只能用于广播较小的表,否则数据的冗余传输就远大于shuffle的开销;另外,广播时需要将被广播的表现collect到driver端,当频繁有广播出现时,对driver的内存也是一个考验。
如下图所示,broadcast hash join可以分为两步:
1. broadcast阶段:将小表广播分发到大表所在的所有主机。广播算法可以有很多,最简单的是先发给driver,driver再统一分发给所有executor;要不就是基于bittorrete的p2p思路;
2. hash join阶段:在每个executor上执行单机版hash join,小表映射,大表试探;
SparkSQL规定broadcast hash join执行的基本条件为被广播小表必须小于参数spark.sql.autoBroadcastJoinThreshold,默认为10M。
Shuffle Hash Join
当一侧的表比较小时,我们选择将其广播出去以避免shuffle,提高性能。但因为被广播的表首先被collect到driver段,然后被冗余分发到每个executor上,所以当表比较大时,采用broadcast join会对driver端和executor端造成较大的压力。
但由于Spark是一个分布式的计算引擎,可以通过分区的形式将大批量的数据划分成n份较小的数据集进行并行计算。这种思想应用到Join上便是Shuffle Hash Join了。利用key相同必然分区相同的这个原理,SparkSQL将较大表的join分而治之,先将表划分成n个分区,再对两个表中相对应分区的数据分别进行Hash Join,这样即在一定程度上减少了driver广播一侧表的压力,也减少了executor端取整张被广播表的内存消耗。其原理如下图:

Shuffle Hash Join分为两步:
1. 对两张表分别按照join keys进行重分区,即shuffle,目的是为了让有相同join keys值的记录分到对应的分区中
2. 对对应分区中的数据进行join,此处先将小表分区构造为一张hash表,然后根据大表分区中记录的join keys值拿出来进行匹配
Shuffle Hash Join的条件有以下几个:
1. 分区的平均大小不超过spark.sql.autoBroadcastJoinThreshold所配置的值,默认是10M
2. 基表不能被广播,比如left outer join时,只能广播右表
3. 一侧的表要明显小于另外一侧,小的一侧将被广播(明显小于的定义为3倍小,此处为经验值)
我们可以看到,在一定大小的表中,SparkSQL从时空结合的角度来看,将两个表进行重新分区,并且对小表中的分区进行hash化,从而完成join。在保持一定复杂度的基础上,尽量减少driver和executor的内存压力,提升了计算时的稳定性。
在大数据条件下如果一张表很小,执行join操作最优的选择无疑是broadcast hash join,效率最高。但是一旦小表数据量增大,广播所需内存、带宽等资源必然就会太大,broadcast hash join就不再是最优方案。此时可以按照join key进行分区,根据key相同必然分区相同的原理,就可以将大表join分而治之,划分为很多小表的join,充分利用集群资源并行化。如下图所示,shuffle hash join也可以分为两步:
1. shuffle阶段:分别将两个表按照join key进行分区,将相同join key的记录重分布到同一节点,两张表的数据会被重分布到集群中所有节点。这个过程称为shuffle
2. hash join阶段:每个分区节点上的数据单独执行单机hash join算法。
看到这里,可以初步总结出来如果两张小表join可以直接使用单机版hash join;如果一张大表join一张极小表,可以选择broadcast hash join算法;而如果是一张大表join一张小表,则可以选择shuffle hash join算法;那如果是两张大表进行join呢?
Sort Merge Join
上面介绍的两种实现对于一定大小的表比较适用,但当两个表都非常大时,显然无论适用哪种都会对计算内存造成很大压力。这是因为join时两者采取的都是hash join,是将一侧的数据完全加载到内存中,使用hash code取join keys值相等的记录进行连接。
当两个表都非常大时,SparkSQL采用了一种全新的方案来对表进行Join,即Sort Merge Join。这种实现方式不用将一侧数据全部加载后再进星hash join,但需要在join前将数据排序,如下图所示:

可以看到,首先将两张表按照join keys进行了重新shuffle,保证join keys值相同的记录会被分在相应的分区。分区后对每个分区内的数据进行排序,排序后再对相应的分区内的记录进行连接,如下图示:

看着很眼熟吧?也很简单,因为两个序列都是有序的,从头遍历,碰到key相同的就输出;如果不同,左边小就继续取左边,反之取右边。
可以看出,无论分区有多大,Sort Merge Join都不用把某一侧的数据全部加载到内存中,而是即用即取即丢,从而大大提升了大数据量下sql join的稳定性。
SparkSQL对两张大表join采用了全新的算法-sort-merge join,如下图所示,整个过程分为三个步骤:
1. shuffle阶段:将两张大表根据join key进行重新分区,两张表数据会分布到整个集群,以便分布式并行处理;
2. sort阶段:对单个分区节点的两表数据,分别进行排序;
3. merge阶段:对排好序的两张分区表数据执行join操作。join操作很简单,分别遍历两个有序序列,碰到相同join key就merge输出,否则取更小一边,见下图示意:
经过上文的分析,可以明确每种Join算法都有自己的适用场景,数据仓库设计时最好避免大表与大表的join查询,SparkSQL也可以根据内存资源、带宽资源适量将参数spark.sql.autoBroadcastJoinThreshold调大,让更多join实际执行为broadcast hash join。
参考:
http://blog.csdn.net/asongoficeandfire/article/details/53574034
https://mp.weixin.qq.com/s/7ohGjdaTC56T4U3ISxGwIw
SparkSQL的3种Join实现的更多相关文章
- sparksql的三种join实现
join 是sql语句中的常用操作,良好的表结构能够将数据分散在不同的表中,使其符合某种范式,减少表冗余,更新容错等.而建立表和表之间关系的最佳方式就是Join操作. sparksql作为大数据领域的 ...
- MapReduce三种join实例分析
本文引自吴超博客 实现原理 1.在Reudce端进行连接. 在Reudce端进行连接是MapReduce框架进行表之间join操作最为常见的模式,其具体的实现原理如下: Map端的主要工作:为来自不同 ...
- Spark SQL中的几种join
1.小表对大表(broadcast join) 将小表的数据分发到每个节点上,供大表使用.executor存储小表的全部数据,一定程度上牺牲了空间,换取shuffle操作大量的耗时,这在SparkSQ ...
- 061 hive中的三种join与数据倾斜
一:hive中的三种join 1.map join 应用场景:小表join大表 一:设置mapjoin的方式: )如果有一张表是小表,小表将自动执行map join. 默认是true. <pro ...
- Hive的三种Join方式
Hive的三种Join方式 hive Hive中就是把Map,Reduce的Join拿过来,通过SQL来表示. 参考链接:https://cwiki.apache.org/confluence/dis ...
- PostgreSQL EXPLAIN执行计划学习--多表连接几种Join方式比较
转了一部分.稍后再修改. 三种多表Join的算法: 一. NESTED LOOP: 对于被连接的数据子集较小的情况,嵌套循环连接是个较好的选择.在嵌套循环中,内表被外表驱动,外表返回的每一行都要在内表 ...
- SQL Server中的三种Join方式
1.测试数据准备 参考:Sql Server中的表访问方式Table Scan, Index Scan, Index Seek 这篇博客中的实验数据准备.这两篇博客使用了相同的实验数据. 2.SQ ...
- sql server几种Join的区别测试方法与union表的合并
/* sql server几种Join的区别测试方法 主要来介绍下Inner Join , Full Out Join , Cross Join , Left Join , Right Join的区别 ...
- MySQL逻辑架构、SQL加载执行顺序、七种JOIN模式图解
逻辑架构 存储引擎 查看当前安装的mysql提供的存储引擎 查看当前mysql默认的存储引擎 MyISAM和InnoDB SQL加载执行顺序 sql书写顺序 mysql解析器执行的顺序 考点:m ...
随机推荐
- 实时流处理Storm、Spark Streaming、Samza、Flink孰优孰劣
对于一个成熟的消息中间件而言,消息格式不仅关系到功能维度的扩展,还牵涉到性能维度的优化.随着Kafka的迅猛发展,其消息格式也在不断的升级改进,从0.8.x版本开始到现在的1.1.x版本,Kafka的 ...
- 使AD域控服务器Administrator的密码永不过期方法。
在安装完AD域后,管理员密码会42天就要更新一次,这样对测试比较不方便, 如果要让域控管理员账号密码永远不过期,就照着下面的方法执行: open a Command Prompt as the adm ...
- 转:LinkedHashMap使用(可以用来实现LRU缓存)
1. LinkedHashMap概述: LinkedHashMap是HashMap的一个子类,它保留插入的顺序,如果需要输出的顺序和输入时的相同,那么就选用LinkedHashMap. LinkedH ...
- bzoj1382 1935: [Shoi2007]Tree 园丁的烦恼
1935: [Shoi2007]Tree 园丁的烦恼 Time Limit: 15 Sec Memory Limit: 357 MBSubmit: 1261 Solved: 578[Submit] ...
- Error:Execution failed for task ':app:transformClassesWithDexForDebug'. > com.android.build.api.transform.TransformException: com.android.ide.common.process.ProcessException: java.util.concurrent.Exec
Error:Execution failed for task ':app:transformClassesWithDexForDebug'.> com.android.build.api.tr ...
- Vim文字编辑
首先说明发现的vim编辑器的一个特点:vim编辑只有按[ENTER]键或命令模式下[o]才会换行,否则虽然在vim编辑器里显示的内容换行了,但事实上没有换行.如果你发现自己测试的效果和下面描述的不符, ...
- IE浏览器对虚拟主机配置域名的问题
之前一直搞不明白web开发做本地调试的时候IE浏览器老是无法登陆,而谷歌和其他内核浏览器能正常登陆的问题,后来发现IE浏览器对WEB服务器配置的虚拟主机域名规则是不能包含这个'_'下划线符号的,否则会 ...
- 在 Flask 项目中解决 CSRF 攻击
#转载请留言联系 1. CSRF是什么? CSRF全拼为Cross Site Request Forgery,译为跨站请求伪造. CSRF指攻击者盗用了你的身份,以你的名义发送恶意请求.包括:以你名义 ...
- Android AutoCompleteTextView控件实现类似百度搜索提示,限制输入数字长度
Android AutoCompleteTextView 控件实现类似被搜索提示,效果如下 1.首先贴出布局代码 activity_main.xml: <?xml version="1 ...
- android okhttp3
一. 传键值对 public String webLogin() { String responseData = null; OkHttpClient client = new OkHttpClien ...