xpath模块
W3School官方文档:http://www.w3school.com.cn/xpath/index.asp
我们使用xpath主要是获取网页数据的,之前一直是使用bs4,xpath也是最近了解到的,找了很多资料,感觉写的都不是很明白,这里我就把我的理解写一下。
首先,lxml是一款高性能的 Python HTML/XML 解析器,我们可以利用XPath,来快速的定位特定元素以及获取节点信息,效率也要别bs4(关于bs4我有一篇beautifulshou的博客可以参考一下)高些。
使用这个就是快速的将html中我们需要的数据找出来。
在使用之前我们需要安装lxml解析器
- pip install lxml
安装了之后,我们要对需要获取数据的网页数据进行解析
网页数据的解析
解析分为两种方式
解析html字符串
使用“lxml.etree.HTML( )”进行解析。etree.tostring( )方法可以将htmlelement元素转化成字符串,可以正常打印出来。示例代码如下:
- from lxml import etree
- html = '''
- <html>
- <head>
- <meta name="content-type" content="text/html; charset=utf-8" />
- <title>友情链接查询 - 站长工具</title>
- <!-- uRj0Ak8VLEPhjWhg3m9z4EjXJwc -->
- <meta name="Keywords" content="友情链接查询" />
- <meta name="Description" content="友情链接查询" />
- </head>
- <body>
- <h1 class="heading">Top News</h1>
- <p style="font-size: 200%">World News only on this page</p>
- Ah, and here's some more text, by the way.
- <p>... and this is a parsed fragment ...</p>
- <a href="http://www.cydf.org.cn/" rel="nofollow" target="_blank">青少年发展基金会</a>
- <a href="http://www.4399.com/flash/32979.htm" target="_blank">洛克王国</a>
- <a href="http://www.4399.com/flash/35538.htm" target="_blank">奥拉星</a>
- <a href="http://game.3533.com/game/" target="_blank">手机游戏</a>
- <a href="http://game.3533.com/tupian/" target="_blank">手机壁纸</a>
- <a href="http://www.4399.com/" target="_blank">4399小游戏</a>
- <a href="http://www.91wan.com/" target="_blank">91wan游戏</a>
- </body>
- </html>
- '''
- html_element = etree.HTML(html)
- print(etree.tostring(html_element, encoding='utf-8').decode('utf-8'))
解析html文件
使用“lxml.etree.parse( )”进行解析,该方法默认使用的是“XML”解析器。
- from lxml import etree
- html_element = etree.parse('./demo.html')
- print(etree.tostring(html_element, encoding='utf-8').decode('utf-8'))
如果碰到不规范的html文件时就会解析错误,报错代码如下:

这个时候就要自己创建html解析器,增加参数‘parser',示例如下
- from lxml import etree
- parser = etree.HTMLParser(encoding="utf-8")
- html_element = etree.parse('./demo.html', parser=parser)
- print(etree.tostring(html_element, encoding='utf-8').decode('utf-8'))
数据提取
在上面完成了数据的解析,下面就要开始主要的内容取数据了。再开始之前,给大家推荐一个Chrome的一个插件:XPath Helper,可以到谷歌商城中下载。这个在分析阶段能够很方便地去查找。
下面列一下最常使用的
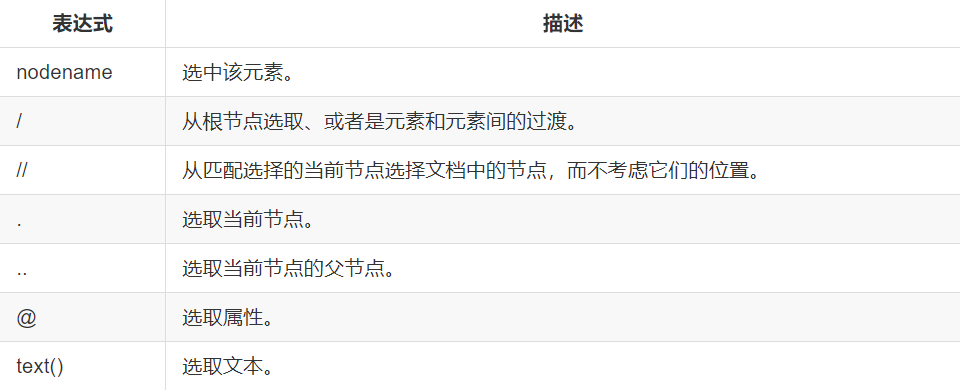
例子:

查找指定节点
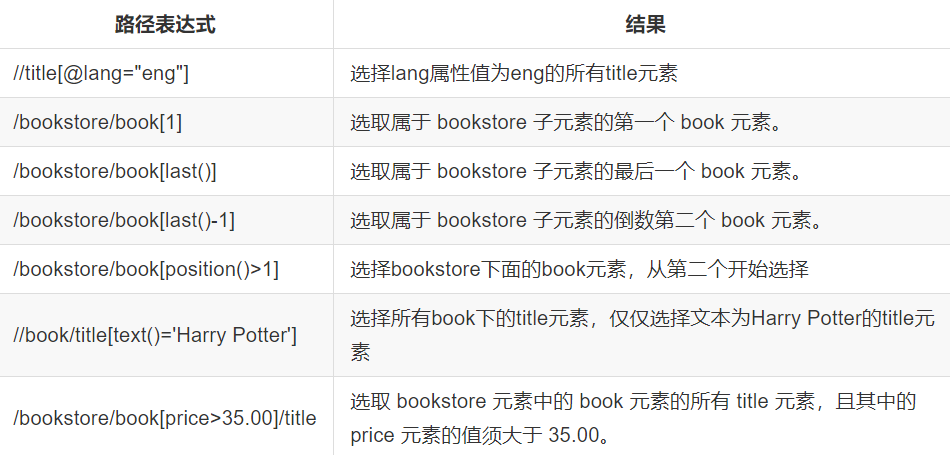
注意点: 在xpath中,第一个元素的位置是1,最后一个元素的位置是last(),倒数第二个是last()-1
选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
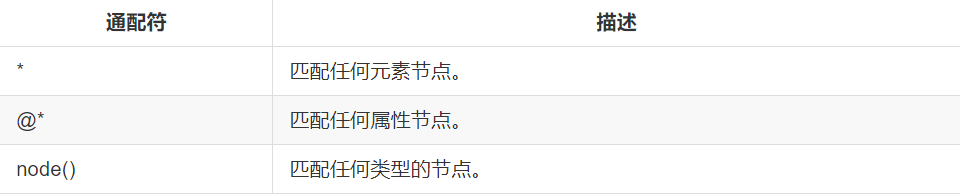
例如

选取若干条路径
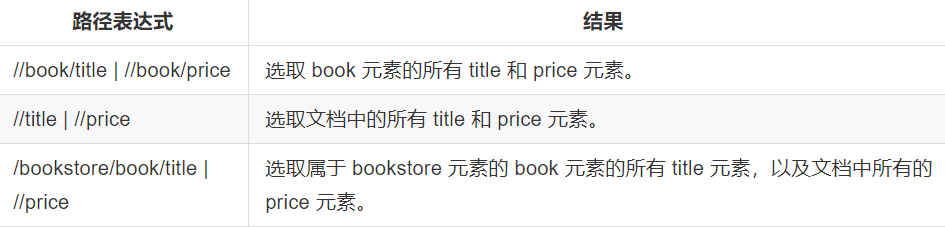
xpath模块的更多相关文章
- python 全栈开发,Day135(爬虫系列之第2章-BS和Xpath模块)
一.BeautifulSoup 1. 简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: ''' Beautiful Soup提供一些简单 ...
- xpath模块使用
xpath模块使用 一.什么是xml(百度百科解释如下) 可扩展标记语言,标准通用标记语言的子集,简称XML.是一种用于标记电子文件使其具有结构性的标记语言. 在电子计算机中,标记指计算机所能理解的信 ...
- Python网络爬虫-xpath模块
一.正解解析 单字符: . : 除换行以外所有字符 [] :[aoe] [a-w] 匹配集合中任意一个字符 \d :数字 [0-9] \D : 非数字 \w :数字.字母.下划线.中文 \W : 非\ ...
- python 全栈开发,Day134(爬虫系列之第1章-requests模块)
一.爬虫系列之第1章-requests模块 爬虫简介 概述 近年来,随着网络应用的逐渐扩展和深入,如何高效的获取网上数据成为了无数公司和个人的追求,在大数据时代,谁掌握了更多的数据,谁就可以获得更高的 ...
- python中BeautifulSoup模块
BeautifulSoup模块是干嘛的? 答:通过html标签去快速匹配标签中的内容.效率相对比正则会好的多.效率跟xpath模块应该差不多. 一:解析器: BeautifulSoup(html,&q ...
- 从0开始学爬虫3之xpath的介绍和使用
从0开始学爬虫3之xpath的介绍和使用 Xpath:一种HTML和XML的查询语言,它能在XML和HTML的树状结构中寻找节点 安装xpath: pip install lxml HTML 超文本标 ...
- 《Python 数据科学实践指南》读书笔记
文章提纲 全书总评 C01.Python 介绍 Python 版本 Python 解释器 Python 之禅 C02.Python 基础知识 基础知识 流程控制: 函数及异常 函数: 异常 字符串 获 ...
- 爬虫-requests
一.爬虫系列之第1章-requests模块 爬虫简介 概述 近年来,随着网络应用的逐渐扩展和深入,如何高效的获取网上数据成为了无数公司和个人的追求,在大数据时代,谁掌握了更多的数据,谁就可以获得更高的 ...
- javascript中DOM0,DOM2,DOM3级事件模型解析
DOM 即 文档对象模型. 文档对象模型是一种与编程语言及平台无关的API(Application programming Interface),借助于它,程序能够动态地访问和修改文档内容.结构或显示 ...
随机推荐
- ubuntu 16.04下搜狗输入法不能输入中文解决
之前一段时间正常使用的搜狗输入法突然无法输出中文(具体现象是,可以呼出搜狗输入法界面,但是候选词列表无显示),解决之后记录下来,希望能为同样遇到这个问题的人提供参考.同时附linux下常见软件崩溃问题 ...
- CentOS 6.5 & 7 的网络YUM源配置
中国科技大学CentOS 6.5的网络源 [base]name=CentOS-$releasever - Base#mirrorlist=http://mirrorlist.centos.org/?r ...
- C语言测试int型数据的最大值最小值
#include<stdio.h> int int_min(){ int i=0; int j=0; while(i>=j) { i=j; ...
- css内容整理1
1.css引入的四种方式1.行内2.内嵌3.链接 <link href="1.css" rel="stylesheet">4.导入@import u ...
- 轮播图jq版
轮播图的需求 1:图片自己轮播,并且下面的tabs小图标跟着显示 2.鼠标hover到tabs上面显示对应的图片 3.点击左右按钮,显示下一张图片. <div id="oLunbo&q ...
- 《Google软件测试之道》之学习笔记01
Google软件测试介绍 软件测试团队->工程生产力(Engineering Productivity) http://googletesting.blogspot.com/2011/01/ho ...
- Objective-C #define 用法解析 (转)
原文地址: http://blog.csdn.net/kindazrael/article/details/8108868 Objective-C : #define 用法解析 在 C 语言中,预处理 ...
- 最小白的webpack+react环境搭建
本文也同步发表在我的公众号“我的天空” 从零开始,用最少的配置.最少的代码.最少的依赖来搭建一个最简单的webpack+react环境. 最近在玩webpack+react+移动端,那么第一步自然是搭 ...
- 各种推导式<"一行能解决的事,为什么要用那么多行">
一.推导式 1.列表:[结果 for循环 条件筛选] 2.字典:{k:v for循环 条件筛选} 3.集合推导式{k for循环 条件筛选} ???为什么没有元组推导式 二.生成器表达式(元组表达式) ...
- aliyun maven repository
<mirrors> <mirror> <id>alimaven</id> <name>aliyun maven</name> & ...