机器学习框架ML.NET学习笔记【3】文本特征分析
一、要解决的问题
问题:常常一些单位或组织召开会议时需要录入会议记录,我们需要通过机器学习对用户输入的文本内容进行自动评判,合格或不合格。(同样的问题还类似垃圾短信检测、工作日志质量分析等。)
处理思路:我们人工对现有会议记录进行评判,标记合格或不合格,通过对这些记录的学习形成模型,学习算法仍采用二元分类的快速决策树算法,和上一篇文章不同,这次输入的特征值不再是浮点数,而是中文文本。这里就要涉及到文本特征提取。
为什么要进行文本特征提取呢?因为文本是人类的语言,符号文字序列不能直接传递给算法。而计算机程序算法只接受具有固定长度的数字矩阵特征向量(float或float数组),无法理解可变长度的文本文档。
常用的文本特征提取方法有如下几种:

以上只是需要了解大致的含义,我们不需要去实现一个文本特征提取的算法,只需要使用平台自带的方法就可以了。
系统自带的文本特征处理的方法,输入是一个字符串,要求将一个语句中的词语用空格分开,英语的句子中词汇是天生通过空格分割的,但中文句子不是,所以我们需要首先进行分词操作,具体流程如下:
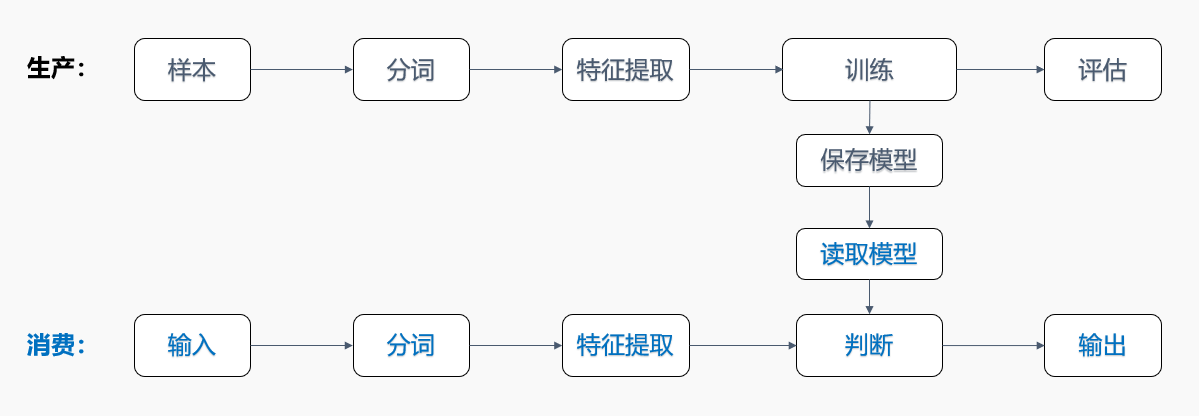
二、代码
代码整体流程和上一篇文章描述的基本一致,为简便起见,我们省略了模型存储和读取的过程。
先看一下数据集:

代码如下:
namespace BinaryClassification_TextFeaturize
{
class Program
{
static readonly string DataPath = Path.Combine(Environment.CurrentDirectory, "Data", "meeting_data_full.csv"); static void Main(string[] args)
{
MLContext mlContext = new MLContext();
var fulldata = mlContext.Data.LoadFromTextFile<MeetingInfo>(DataPath, separatorChar: ',', hasHeader: false);
var trainTestData = mlContext.Data.TrainTestSplit(fulldata, testFraction: 0.15);
var trainData = trainTestData.TrainSet;
var testData = trainTestData.TestSet; var trainingPipeline = mlContext.Transforms.CustomMapping<JiebaLambdaInput, JiebaLambdaOutput>(mapAction: JiebaLambda.MyAction, contractName: "JiebaLambda")
.Append(mlContext.Transforms.Text.FeaturizeText(outputColumnName: "Features", inputColumnName: "JiebaText"))
.Append(mlContext.BinaryClassification.Trainers.FastTree(labelColumnName: "Label", featureColumnName: "Features"));
ITransformer trainedModel = trainingPipeline.Fit(trainData); //评估
var predictions = trainedModel.Transform(testData);
var metrics = mlContext.BinaryClassification.Evaluate(data: predictions, labelColumnName: "Label");
Console.WriteLine($"Evalution Accuracy: {metrics.Accuracy:P2}"); //创建预测引擎
var predEngine = mlContext.Model.CreatePredictionEngine<MeetingInfo, PredictionResult>(trainedModel); //预测1
MeetingInfo sampleStatement1 = new MeetingInfo { Text = "支委会。" };
var predictionresult1 = predEngine.Predict(sampleStatement1);
Console.WriteLine($"{sampleStatement1.Text}:{predictionresult1.PredictedLabel}"); //预测2
MeetingInfo sampleStatement2 = new MeetingInfo { Text = "开展新时代中国特色社会主义思想三十讲党员答题活动。" };
var predictionresult2 = predEngine.Predict(sampleStatement2);
Console.WriteLine($"{sampleStatement2.Text}:{predictionresult2.PredictedLabel}"); Console.WriteLine("Press any to exit!");
Console.ReadKey();
} } public class MeetingInfo
{
[LoadColumn()]
public bool Label { get; set; }
[LoadColumn()]
public string Text { get; set; }
} public class PredictionResult : MeetingInfo
{
public string JiebaText { get; set; }
public float[] Features { get; set; }
public bool PredictedLabel;
public float Score;
public float Probability;
}
}
三、代码分析
和上一篇文章中相似的内容我就不再重复解释了,重点介绍一下学习管道的建立。
var trainingPipeline = mlContext.Transforms.CustomMapping<JiebaLambdaInput, JiebaLambdaOutput>(mapAction: JiebaLambda.MyAction, contractName: "JiebaLambda")
.Append(mlContext.Transforms.Text.FeaturizeText(outputColumnName: "Features", inputColumnName: "JiebaText"))
.Append(mlContext.BinaryClassification.Trainers.FastTree(labelColumnName: "Label", featureColumnName: "Features"));
首先,在进行文本特征转换之前,我们需要对文本进行分词操作,您可以对样本数据进行预处理,形成分词的结果再进行学习,我们没有采用这个方法,而是自定义了一个分词处理的数据处理管道,通过这个管道进行分词,其定义如下:
namespace BinaryClassification_TextFeaturize
{
public class JiebaLambdaInput
{
public string Text { get; set; }
} public class JiebaLambdaOutput
{
public string JiebaText { get; set; }
} public class JiebaLambda
{
public static void MyAction(JiebaLambdaInput input, JiebaLambdaOutput output)
{
JiebaNet.Segmenter.JiebaSegmenter jiebaSegmenter = new JiebaNet.Segmenter.JiebaSegmenter();
output.JiebaText = string.Join(" ", jiebaSegmenter.Cut(input.Text));
}
}
}
最后我们新建了两个对象进行实际预测:
//预测1
MeetingInfo sampleStatement1 = new MeetingInfo { Text = "支委会。" };
var predictionresult1 = predEngine.Predict(sampleStatement1);
Console.WriteLine($"{sampleStatement1.Text}:{predictionresult1.PredictedLabel}"); //预测2
MeetingInfo sampleStatement2 = new MeetingInfo { Text = "开展新时代中国特色社会主义思想三十讲党员答题活动。" };
var predictionresult2 = predEngine.Predict(sampleStatement2);
Console.WriteLine($"{sampleStatement2.Text}:{predictionresult2.PredictedLabel}");
预测结果如下:

四、调试
上一篇文章提到,当我们运行Transform方法时,会对所有记录进行转换,转换后的数据集是什么样子呢,我们可以写一个调试程序看一下。
var predictions = trainedModel.Transform(testData);
DebugData(mlContext, predictions); private static void DebugData(MLContext mlContext, IDataView predictions)
{
var trainDataShow = new List<PredictionResult>(mlContext.Data.CreateEnumerable<PredictionResult>(predictions, false, true)); foreach (var dataline in trainDataShow)
{
dataline.PrintToConsole();
}
} public class PredictionResult
{
public string JiebaText { get; set; }
public float[] Features { get; set; }
public bool PredictedLabel;
public float Score;
public float Probability;
public void PrintToConsole()
{
Console.WriteLine($"JiebaText={JiebaText}");
Console.WriteLine($"PredictedLabel:{PredictedLabel},Score:{Score},Probability:{Probability}");
Console.WriteLine($"TextFeatures Length:{Features.Length}");
if (Features != null)
{
foreach (var f in Features)
{
Console.Write($"{f},");
}
Console.WriteLine();
}
Console.WriteLine();
}
}
通过对调试结果的分析,可以看到整个数据处理管道的工作流程。
五、资源获取
源码下载地址:https://github.com/seabluescn/Study_ML.NET
工程名称:BinaryClassification_TextFeaturize
机器学习框架ML.NET学习笔记【3】文本特征分析的更多相关文章
- 机器学习框架ML.NET学习笔记【4】多元分类之手写数字识别
一.问题与解决方案 通过多元分类算法进行手写数字识别,手写数字的图片分辨率为8*8的灰度图片.已经预先进行过处理,读取了各像素点的灰度值,并进行了标记. 其中第0列是序号(不参与运算).1-64列是像 ...
- 机器学习框架ML.NET学习笔记【1】基本概念与系列文章目录
一.序言 微软的机器学习框架于2018年5月出了0.1版本,2019年5月发布1.0版本.期间各版本之间差异(包括命名空间.方法等)还是比较大的,随着1.0版发布,应该是趋于稳定了.之前在园子里也看到 ...
- 机器学习框架ML.NET学习笔记【2】入门之二元分类
一.准备样本 接上一篇文章提到的问题:根据一个人的身高.体重来判断一个人的身材是否很好.但我手上没有样本数据,只能伪造一批数据了,伪造的数据比较标准,用来学习还是蛮合适的. 下面是我用来伪造数据的代码 ...
- 机器学习框架ML.NET学习笔记【5】多元分类之手写数字识别(续)
一.概述 上一篇文章我们利用ML.NET的多元分类算法实现了一个手写数字识别的例子,这个例子存在一个问题,就是输入的数据是预处理过的,很不直观,这次我们要直接通过图片来进行学习和判断.思路很简单,就是 ...
- 机器学习框架ML.NET学习笔记【6】TensorFlow图片分类
一.概述 通过之前两篇文章的学习,我们应该已经了解了多元分类的工作原理,图片的分类其流程和之前完全一致,其中最核心的问题就是特征的提取,只要完成特征提取,分类算法就很好处理了,具体流程如下: 之前介绍 ...
- 机器学习框架ML.NET学习笔记【7】人物图片颜值判断
一.概述 这次要解决的问题是输入一张照片,输出人物的颜值数据. 学习样本来源于华南理工大学发布的SCUT-FBP5500数据集,数据集包括 5500 人,每人按颜值魅力打分,分值在 1 到 5 分之间 ...
- 机器学习框架ML.NET学习笔记【8】目标检测(采用YOLO2模型)
一.概述 本篇文章介绍通过YOLO模型进行目标识别的应用,原始代码来源于:https://github.com/dotnet/machinelearning-samples 实现的功能是输入一张图片, ...
- 机器学习框架ML.NET学习笔记【9】自动学习
一.概述 本篇我们首先通过回归算法实现一个葡萄酒品质预测的程序,然后通过AutoML的方法再重新实现,通过对比两种实现方式来学习AutoML的应用. 首先数据集来自于竞赛网站kaggle.com的UC ...
- ML.NET学习笔记 ---- 系列文章
机器学习框架ML.NET学习笔记[1]基本概念与系列文章目录 机器学习框架ML.NET学习笔记[2]入门之二元分类 机器学习框架ML.NET学习笔记[3]文本特征分析 机器学习框架ML.NET学习笔记 ...
随机推荐
- 一个有关Golang变量作用域的坑
转自:http://tonybai.com/2015/01/13/a-hole-about-variable-scope-in-golang/ 临近下班前编写和调试一段Golang代码,但运行结果始终 ...
- FATFS 文件系统
转载请注明出处:http://blog.csdn.net/qq_26093511/article/details/51706228 1.文件系统是什么? 负责管理和存储文件信息的软件机构称为文件管理系 ...
- keil5编译时出现 MDK-Pro middleware is not allowed with this license
转载请注明出处:http://blog.csdn.net/qq_26093511/article/details/51700961 最近在用MDK编译一个别人的工程时,有如上提示: 1.原因是没有注册 ...
- [.net] 无法创建虚拟目录。已将URL“XXX”映射到IIS Express网站上的一个不同的文件夹
工作时,在修改项目属性,Web中服务器时,出现了下面的错误: 各种折腾后,找到下面的解决方法: 1.找到项目在本地的目录,目录下有当前项目的项目文件,文件名以.csproj为后缀名. 2.用文本编辑软 ...
- [jQuery] 按回车键实现登录
Jquery按回车键提交实现登录的方式分为两种: 1.按钮提交 2.表单提交 1.按钮提交 $("#LoginIn").off('click').on('click', funct ...
- 关于KMeans 最外围点移除实验(其中心保持不变)
import matplotlib.pyplot as plt from sklearn.datasets import make_blobs import numpy as np X,labels ...
- WPF dataGrid下的ComboBox的绑定
WPF dataGrid下的ComboBox的绑定 Wpf中dataGrid中的某列是comboBox解决这个问题费了不少时间,不废话了直接上代码 xaml 代码 <DataGridTempla ...
- 第六篇 elasticsearch express 删除索引数据
express 框架删除elasticsearch索引数据 1.在elasticsearch.js文件下添加 function deleteDocument(id) { return elasticC ...
- Flask15 远程开发环境搭建、安装虚拟机、导入镜像文件、创建开发环境、pycharm和远程开发环境协同工作
1 安装VM虚拟机 待更新... 2 导入镜像文件 待更新... 3 启动虚拟机 4 远程连接虚拟机 4.1 安装xShell软件 待更新... 4.2 创建一个新的连接 4.2.1 在虚拟机中获取虚 ...
- [原创]SQL表值函数:把用逗号分隔的字符串转换成表格数据
我们日常开发过程中,非常常见的一种需求,把某一个用逗号或者/或者其他符号作为间隔的字符串分隔成一张表数据. 在前面我们介绍了 [原创]SQL 把表中字段存储的逗号隔开内容转换成列表形式,当然按照这 ...