Hadoop实战:明星搜索指数统计,找出人气王
项目介绍
本项目我们使用明星搜索指数数据,分别统计出搜索指数最高的男明星和女明星。
数据集
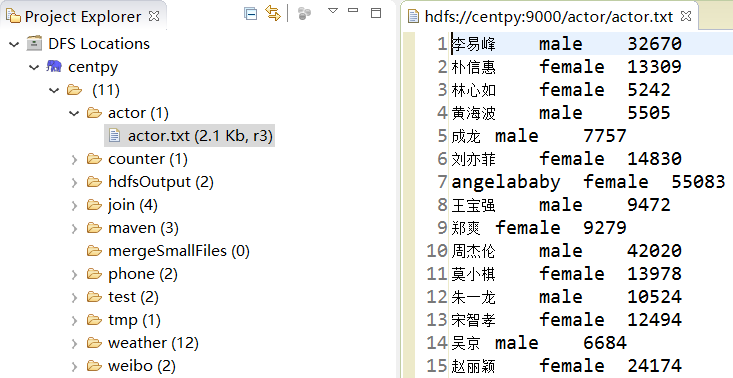
明星搜索指数数据集,如下图所示。猛戳此链接下载数据集
思路分析
基于项目的需求,我们通过以下几步完成:
1、编写 Mapper类,按需求将数据集解析为 key=gender,value=name+hotIndex,然后输出。
2、编写 Combiner 类,合并 Mapper 输出结果,然后输出给 Reducer。
3、编写 Partitioner 类,按性别,将结果指定给不同的 Reduce 执行。
4、编写 Reducer 类,分别统计出男、女明星的最高搜索指数。
5、编写 run 方法执行 MapReduce 任务。
MapReduce Java 项目
设计的MapReduce如下所示:
Map = {key = gender, value = name+hotIndex}
Reduce = {key = name, value = gender+hotIndex}
Map
每次调用map(LongWritable key, Text value, Context context)解析一行数据。每行数据存储在value参数值中。然后根据'\t'分隔符,解析出明星姓名,性别和搜索指数。
public static class ActorMapper extends Mapper< Object, Text, Text, Text> {
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
//value=name+gender+hotIndex
String[] tokens = value.toString().split("\t");
String gender = tokens[].trim();//性别
String nameHotIndex = tokens[] + "\t" + tokens[];//名称和搜索指数
context.write(new Text(gender), new Text(nameHotIndex));
}
}
map()函数期望的输出结果Map = {key = gender, value = name+hotIndex}
Combiner
对 map 端的输出结果,先进行一次合并,减少数据的网络输出。
public static class ActorCombiner extends Reducer< Text, Text, Text, Text> {
private Text text = new Text();
@Override
public void reduce(Text key, Iterable< Text> values, Context context) throws IOException, InterruptedException {
int maxHotIndex = Integer.MIN_VALUE;
int hotIndex = ;
String name="";
for (Text val : values) {
String[] valTokens = val.toString().split("\\t");
hotIndex = Integer.parseInt(valTokens[]);
if(hotIndex>maxHotIndex){
name = valTokens[];
maxHotIndex = hotIndex;
}
}
text.set(name+"\t"+maxHotIndex);
context.write(key, text);
}
}
Partitioner
根据明星性别对数据进行分区,将 Mapper 的输出结果均匀分布在 reduce 上。
public static class ActorPartitioner extends Partitioner< Text, Text> {
@Override
public int getPartition(Text key, Text value, int numReduceTasks) {
String sex = key.toString();
if(numReduceTasks==)
return ;
//性别为male 选择分区0
if(sex.equals("male"))
return ;
//性别为female 选择分区1
if(sex.equals("female"))
return % numReduceTasks;
//其他性别 选择分区2
else
return % numReduceTasks;
}
}
Reduce
调用reduce(key, Iterable< Text> values, context)方法来处理每个key和values的集合。我们在values集合中,计算出明星的最大搜索指数。
public static class ActorReducer extends Reducer< Text, Text, Text, Text> {
@Override
public void reduce(Text key, Iterable< Text> values, Context context) throws IOException, InterruptedException {
int maxHotIndex = Integer.MIN_VALUE;
String name = " ";
int hotIndex = ;
for (Text val : values) {
String[] valTokens = val.toString().split("\\t");
hotIndex = Integer.parseInt(valTokens[]);
if (hotIndex > maxHotIndex) {
name = valTokens[];
maxHotIndex = hotIndex;
}
}
context.write(new Text(name), new Text( key + "\t"+ maxHotIndex));
}
}
reduce()函数期望的输出结果Reduce = {key = name, value = gender+max(hotIndex)}
Run 驱动方法
在 run 方法中,设置任务执行各种信息。
public int run(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf = new Configuration();//读取配置文件
Path mypath = new Path(args[]);
FileSystem hdfs = mypath.getFileSystem(conf);
if (hdfs.isDirectory(mypath)) {
hdfs.delete(mypath, true);
}
Job job = new Job(conf, "star");//新建一个任务
job.setJarByClass(Star.class);//主类
job.setNumReduceTasks();//reduce的个数设置为2
job.setPartitionerClass(ActorPartitioner.class);//设置Partitioner类
job.setMapperClass(ActorMapper.class);//Mapper
job.setMapOutputKeyClass(Text.class);//map 输出key类型
job.setMapOutputValueClass(Text.class);//map 输出value类型
job.setCombinerClass(ActorCombiner.class);//设置Combiner类
job.setReducerClass(ActorReducer.class);//Reducer
job.setOutputKeyClass(Text.class);//输出结果 key类型
job.setOutputValueClass(Text.class);//输出结果 value类型
FileInputFormat.addInputPath(job, new Path(args[]));// 输入路径
FileOutputFormat.setOutputPath(job, new Path(args[]));// 输出路径
job.waitForCompletion(true);//提交任务
return ;
}
编译和执行 MapReduce作业
1、myclipse将项目编译和打包为star.jar,使用SSH将 star.jar上传至hadoop的$HADOOP_HOME目录下。
2、使用cd $HADOOP_HOME切换到当前目录,通过命令行执行Hadoop作业
hadoop jar star.jar zimo.hadoop.Star.Star
运行结果
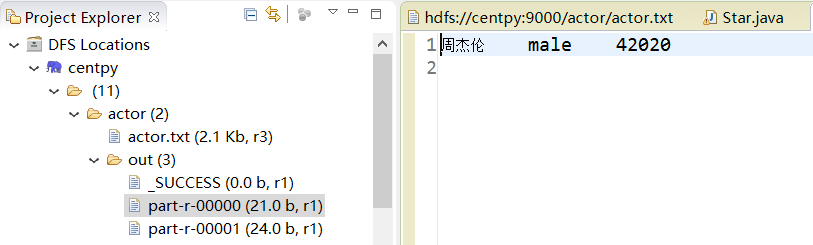
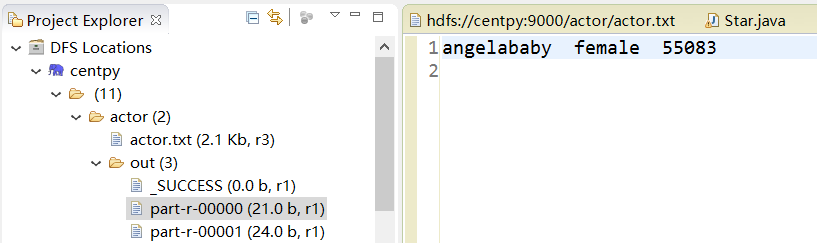
你可以在DFS Locations界面下查看输出目录。
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
版权声明:本文为博主原创文章,未经博主允许不得转载。
Hadoop实战:明星搜索指数统计,找出人气王的更多相关文章
- MapReduce明星搜索指数统计,找出人气王
我们继续通过项目强化掌握Combiner和Partitioner优化Hadoop性能 1.项目介绍 本项目我们使用明星搜索指数数据,分别统计出搜索指数最高的男明星和女明星. 2.数据集 3.分析 基于 ...
- 通过代码审计找出网站中的XSS漏洞实战(三)
一.背景 笔者此前录制了一套XSS的视频教程,在漏洞案例一节中讲解手工挖掘.工具挖掘.代码审计三部分内容,准备将内容用文章的形式再次写一此,前两篇已经写完,内容有一些关联性,其中手工XSS挖掘篇地址为 ...
- 通过Web安全工具Burp suite找出网站中的XSS漏洞实战(二)
一.背景 笔者6月份在慕课网录制视频教程XSS跨站漏洞 加强Web安全,里面需要讲到很多实战案例,在漏洞挖掘案例中分为了手工挖掘.工具挖掘.代码审计三部分内容,手工挖掘篇参考地址为快速找出网站中可能存 ...
- Dijkstra 算法,用于对有权图进行搜索,找出图中两点的最短距离
Dijkstra 算法,用于对有权图进行搜索,找出图中两点的最短距离,既不是DFS搜索,也不是BFS搜索. 把Dijkstra 算法应用于无权图,或者所有边的权都相等的图,Dijkstra 算法等同于 ...
- C语言:对传入sp的字符进行统计,三组两个相连字母“ea”"ou""iu"出现的次数,并将统计结果存入ct所指的数组中。-在数组中找出最小值,并与第一个元素交换位置。
//对传入sp的字符进行统计,三组两个相连字母“ea”"ou""iu"出现的次数,并将统计结果存入ct所指的数组中. #include <stdio.h& ...
- Python list去重及找出,统计重复项
http://bbs.chinaunix.net/thread-1680208-1-1.html 如何找出 python list 中有重复的项 http://www.cnblogs.com/feis ...
- 机器学习进阶-项目实战-信用卡数字识别 1.cv2.findContour(找出轮廓) 2.cv2.boudingRect(轮廓外接矩阵位置) 3.cv2.threshold(图片二值化操作) 4.cv2.MORPH_TOPHAT(礼帽运算突出线条) 5.cv2.MORPH_CLOSE(闭运算图片内部膨胀) 6. cv2.resize(改变图像大小) 7.cv2.putText(在图片上放上文本)
7. cv2.putText(img, text, loc, text_font, font_scale, color, linestick) # 参数说明:img表示输入图片,text表示需要填写的 ...
- [leetcode] 230. Kth Smallest Element in a BST 找出二叉搜索树中的第k小的元素
题目大意 https://leetcode.com/problems/kth-smallest-element-in-a-bst/description/ 230. Kth Smallest Elem ...
- 海量数据处理 - 10亿个数中找出最大的10000个数(top K问题)
前两天面试3面学长问我的这个问题(想说TEG的3个面试学长都是好和蔼,希望能完成最后一面,各方面原因造成我无比想去鹅场的心已经按捺不住了),这个问题还是建立最小堆比较好一些. 先拿10000个数建堆, ...
随机推荐
- POJ1365:素数
Prime Land Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 3552 Accepted: 1609 Descri ...
- VijosP1274:神秘的咒语
描述 身为拜月教的高级间谍,你的任务总是逼迫你出生入死.比如这一次,拜月教主就派你跟踪赵灵儿一行,潜入试炼窟底. 据说试炼窟底藏着五行法术的最高法术:风神,雷神,雪妖,火神,山神的咒语.为了习得这些法 ...
- hdu 1506 单调栈问题
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1506 题目的意思其实就是要找到一个尽可能大的矩形来完全覆盖这个矩形下的所有柱子,只能覆盖柱子,不能留空 ...
- HTML input 标签不可编辑的 readonly 属性
1 <form action="form_action.asp" method="get"> Name:<input type="t ...
- top查看CPU情况
Linux查看CPU情况 在系统维护的过程中,随时可能有需要查看 CPU 使用率,并根据相应信息分析系统状况的需要.在 CentOS 中,可以通过 top 命令来查看 CPU 使用状况.运行 top ...
- Remove all the html Tag in String
在用Umbraco开发项目的过程中,由于在Umbraco Back office 中有用到 rich text editor, 而它返回的值是HtmlString类型,也就是说是包含Html Tag的 ...
- ps&CPU
#include <pthread.h> void f();int main() { f(); return 0;} void f() { int ...
- 在Ionic Framework 退出APP
使用以下代码: ionic.Platform.exitApp(); 在控制器中增加: $scope.Quit = function(){ ionic.Platform.exitApp(); }
- HN669打包工具--打包工具使用文档
打包工具主要包含下载更新资源文件以及打包两个部分 一.下载更新资源文件 1.终端进入工具根目录,即HN669SDK_iOS目录,并运行./api.sh脚本 2.输入游戏id (note:此游戏id为我 ...
- 【redis对象,集合序列化Demo】
package org.seckill.dao.cache; import java.io.ByteArrayInputStream;import java.io.ByteArrayOutputStr ...