css三种布局方式
预览
在高层次上,每一个Spark应用(application)都包含一个驱动程序(driver program),该程序运行用户的主函数(main function),并在集群上执行各种并行操作。
Spark提供的主要抽象是一个弹性分布式数据集(resilient distributed dataset,简称RDD),它是在集群节点间进行分区的元素集合,可以并行操作。RDD是通过Hadoop文件系统中的文件创建或者由驱动程序中现有的集合转换得到的,用户可以要求Spark将RDD持久化到内存中,以便在并行操作中有效地重用它。
Spark中的第二个抽象是可以在并行操作中使用的共享变量(shared variables)。默认情况下,Spark以一组任务(a set of tasks)的形式在不同节点上并行执行一个函数时,会将该函数中使用的每个变量的副本传送给每个任务。有时,一个变量需要在任务间、或者任务与驱动程序间共享。Spark支持两种类型的共享变量:广播变量,可用于在所有节点上缓存一个值到内存中。累加器,这些变量只能进行累加操作,比如计数器和求和(counters和sums)。
本指南显示了Spark支持的各种语言中的每个功能。
Linking with Spark
Java语言
要用Java语言编写Spark应用,你需要引入spark-core_2.11依赖。此外,如果想访问hdfs集群,还需要添加一个hadoop-client依赖,版本同hdfs集群版本相同。
初始化Spark
Java语言
在Spark程序中首先需要创建一个JavaSparkContext对象(org.apache.spark.api.java.JavaSparkContext类,在org.apache.spark.api.java包中),它告诉Spark如何访问一个集群。为了创建一个JavaSparkContext对象,你必须先创建一个SparkConf对象,它包含应用相关的信息。
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName(appName).setMaster(master);
JavaSparkContext sc = new JavaSparkContext(conf);
}
appName是应用名。master可以是Spark集群URL、Mesos集群URL或者"yarn",或者是"local"。其中yarn表示运行在yarn集群上,即spark on yarn。local表示运行在本地,仅在本地开发时使用。
在实际生产中,都是通过spark-submit脚本来启动应用,master值是从脚本参数中获取的。
弹性分布式数据集(RDD)
Spark围绕弹性分布式数据集(RDD)的概念展开,RDD是可以并行操作的元素集合。
有两种方式来创建RDD:
1、并行化驱动程序中现有的集合
2、从外部存储系统中引用数据集
并行化集合
Java语言
并行化集合可以通过在驱动程序中的现有集合上调用JavaSparkContext实例的parallelize()方法来创建。例如,下面创建了一个包含数字1到5的并行化集合:
List<Integer> data = new ArrayList<>();
for (int i = 0; i < 10000 * 10000; i++) {
data.add(i);
}
int processors = Runtime.getRuntime().availableProcessors();
JavaRDD<Integer> rdd = sc.parallelize(data, processors * 4);
分布式数据集创建后就可以进行并行操作。例如,我们可以调用distData.reduce((a,b) -> (a+b))来将list中的元素相加。我们稍后再详细介绍分布式数据集上的可用操作。
并行化集合的一个重要参数是将数据集切分成多少个分区,Spark会为集群中的每个分区运行一个任务(task),一般需要为集群中的每个CPU分配2-4个分区。在调用parallelize()方法时,传入第二个参数numSlices来手动设置分区数量。如果不传第二个参数,则Spark会根据集群自动设置分区数量。启动程序,在日志中搜partitions,发现输出有Got job 0 (reduce at SparkdemoApplication.java:34) with 48 output partitions,说明的确将数据集切分成了48个分区。
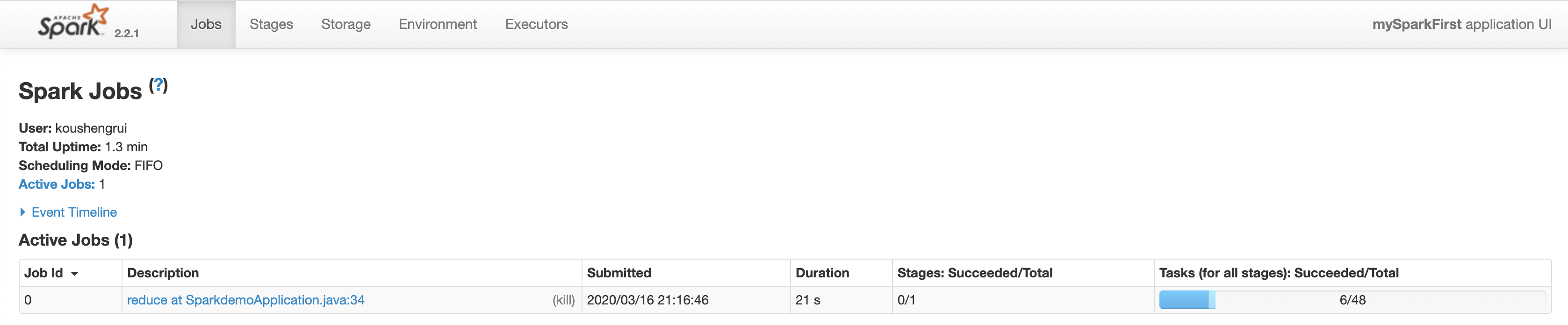
在程序未执行完时,访问127.0.0.1:4040/,
在Jobs菜单可以看到Jobs。什么是Job?1个job可以理解为1个操作,如reduce等。可以看到这个job分为1个stage,48个task,已经成功了6个task。
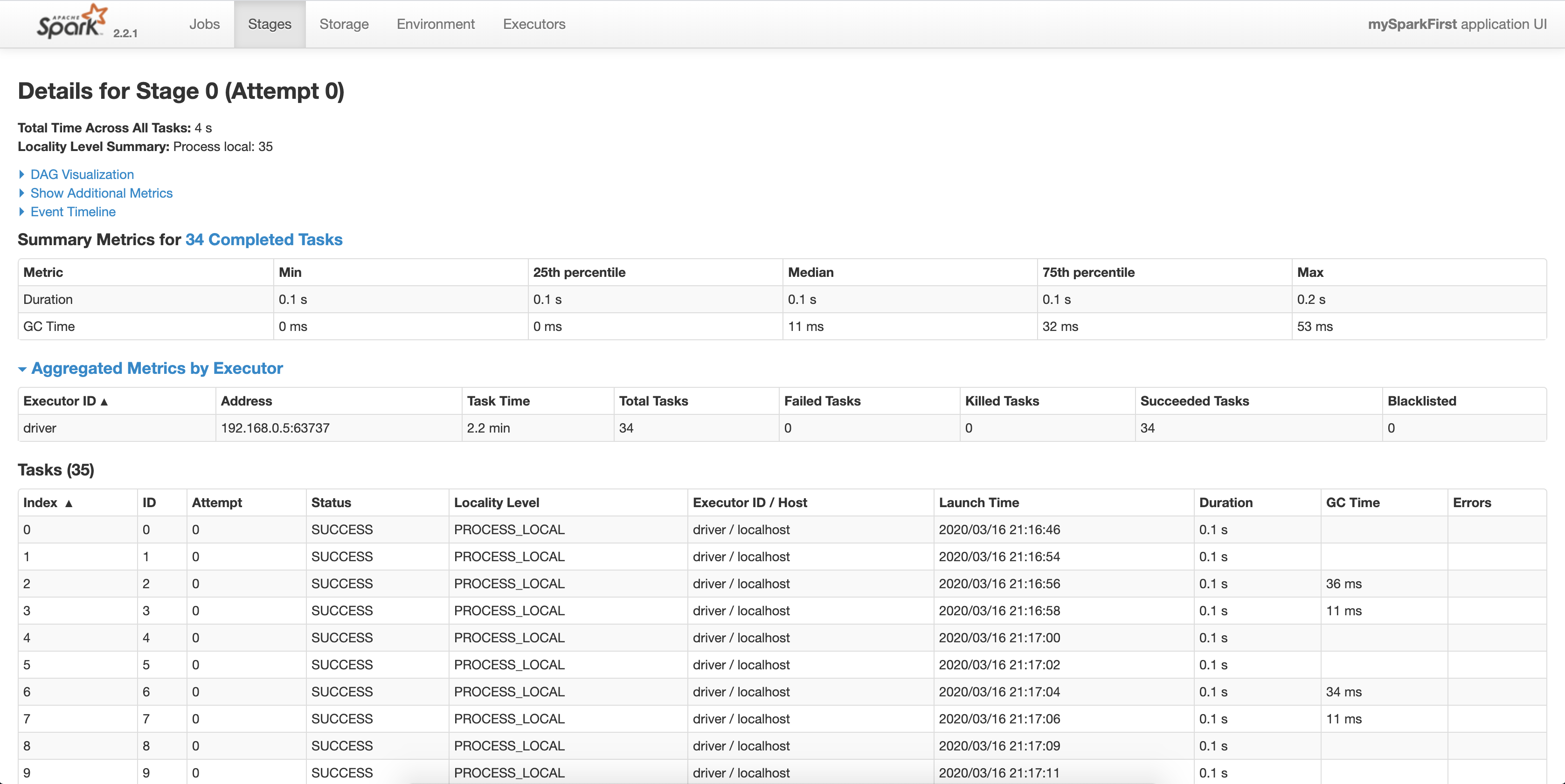
 在Stages菜单,可以看到stages。什么是stage?可以理解为阶段,或者步骤。一个job可以分为多个stage,每个stage可以有多个task。
在Stages菜单,可以看到stages。什么是stage?可以理解为阶段,或者步骤。一个job可以分为多个stage,每个stage可以有多个task。
 从Description点进去,可以看到这个stage每个task的执行情况,包括执行状态、执行起止时间、耗费时间等。
从Description点进去,可以看到这个stage每个task的执行情况,包括执行状态、执行起止时间、耗费时间等。
外部数据集
常见的数据源:
1、文件系统
文本文件RDD可以使用JavaSparkContext实例的textFile()方法来创建,可以读取存储在本地文件系统或者分布式文件系统(如hdfs等)中的数据。这个方法接收一个文件URI(一个本地路径或者一个hdfs://),并把它作为一个行集合(集合中的每个元素都是一行字符串)来读取。示例:
JavaRDD<String> distFile = sc.textFile("data.txt");
一旦创建,distFile可以进行数据集操作。例如,我们可以通过map和reduce操作来计算出所有行的单词的总数,如下所示:
distFile.map(s -> s.length()).reduce((a, b) -> a + b);
使用Spark读取文件时的一些注意事项:
如果使用一个本地文件系统的路径,则该文件必须可以在所有工作节点(worker nodes)上的相同路径上访问。我们可以将文件复制到所有工作节点上,或者使用共享文件系统。
Spark所有基于文件的输入方法(textFile()、wholeTextFiles()、hadoopFile()、newAPIHadoopFile()、objectFile()、sequenceFile()、binaryFiles()等),既可以传单个文件,也可以传一个目录,还支持通配符。例如,textFile("/my/directory/1.txt")、textFile("/my/directory/*.text")、textFile("/my/directory")。
textFile()还可以使用可选的第二个参数来控制文件的分区数量。如果是hdfs文件的话,Spark默认会为文件的每个块创建一个分区(hdfs文件128M每块),自定义分区数可以比块数大,但是不能比块数小。
JavaSparkContext的wholeTextFiles()方法让你读取一个包含多个小文本文件的目录,并将他们作为文件名-内容对返回。这与textFile()方法不同,textFile()方法返回每个文件的每一行的记录。
JavaRDD的savaAsObjectFile()方法以及JavaSparkContext的objectFile()方法支持以包含序列化Java对象的简单格式来保存RDD。虽然不像Avro的格式那么有效率,但它提供了一种简单的方法来保存任何RDD。
2、Spark SQL中的结构化数据
主要是包括JSON和Apache Hive在内的结构化数据源
Spark SQL支持多种结构化数据源作为输入,如hive。
hive可以在hdfs内或者其他存储系统上存储多种格式的表,Spark SQL可以读取hive支持的任何表。要把Spark SQL连接到已有的hive上,需要把hive的配置文件hive-site.xml复制到Spark的conf目录下。在spark2.0.0版本以前,需要创建HiveContext实例作为Spark SQL的入口,并调用其sql(String sqlText)方法查询hive创建数据集。在Spark2.0.0及之后版本,需要创建SparkSession实例,并调用其enableHiveSupport()方法启用hive支持。之后再调用SparkSession的sqlContext()方法拿到SqlContext实例,进而通过SqlContext的多个方法来操作hive。详细介绍见Spark SQL章节。
Spark SQL也能操作JSON文件。2.0.0版本以前,使用HiveContext的jsonFile()方法。2.0.0及之后版本,使用SqlContext的jsonFile()方法。
3、数据库与键值存储
主要是Cassandra、HBase、Elasticsearch、传统关系型数据库。
与Hbase交互、与Elasticsearch、与数据库交互,详见Spark SQL章节。
RDD操作
RDD支持两种类型的操作:转换操作(从现有数据集创建新数据集)和行为操作(在数据集上运行计算后将值返回给驱动程序)。例如,map()方法是一个转换操作,它在数据集的每个元素上都应用一个函数,并返回一个包含这些新元素的数据集。另一方面,reduce()方法是一个行为操作,它用一个函数聚合数据集中所有的元素,并返回最终结果给驱动程序(除了reduceByKey()方法,它返回一个分布式数据集)。
Spark中的所有转换操作都是懒加载的,他们不会马上计算结果。相反,他们仅记住应用于某些基础数据集的转换。只有在行为操作要将结果返回给驱动程序时,转换操作才会执行。这种设计能使得Spark更高效地运行。例如,我们可以认识到,通过map()方法创建的数据集将被用于reduce,而且只返回reduce()方法的结果给驱动程序,而不是大得多的map()方法得到的结果集。
默认情况下,每执行一次行为操作,都要执行一次转换操作。我们可以使用persist()方法(或者cache()方法)将RDD持久化到内存中,这样,下次查询时会快一点。还支持将数据集持久化到硬盘上及在多个节点上创建副本。
基础
Java语言
为了说明RDD的基础,请考虑下面的简单程序:
JavaRDD<String> lines = sc.textFile("data.txt");
JavaRDD<Integer> lineLengths = lines.map(s -> s.length());
int totalLength = lineLengths.reduce((a, b) -> a + b);
第一行定义了一个来自于外部文件的基础RDD。这个数据集不会加载到内存中,lines只是一个指向文件的指针。第二行对lines执行map()转换操作,并将转换结果赋值给一个新的数据集变量lineLengths。同样,lineLengths由于转换操作的懒加载还没有计算。最后,我们执行reduce()方法,它是一个行为操作。此时,Spark将运算分解成在不同机器上运行的任务,每台机器在其分配到的数据集分区上既运行map()方法,又运行局部reduce()方法,返回其结果给驱动程序。如果我们想稍后再使用lineLengths,我们可以在reduce()方法之前添加:
lineLengths.persist(StorageLevel.MEMORY_ONLY());
这将导致lineLengths在它第一次计算之后被保存到内存中。
将函数传递给Spark
Spark的API在很大程度上依赖于将驱动程序中的函数传递到集群上运行。推荐使用lambda表达式。
理解闭包
Spark的难点之一是在集群中执行代码时理解变量和方法的作用域和生命周期。修改作用域之外的变量的RDD操作经常引起混淆。在下面的例子中,我们将看看使用foreach()方法来增加计数器的代码,但其他操作也会出现类似的问题。
例子
考虑以下RDD元素的总和,根据执行是否发生在同一个JVM中,这可能会有不同的表现。一个常见的例子是在本地模式下运行Spark(--master = local[n])与将Spark应用部署到集群(例如,通过spark-submit提交到YARN)做对比。
Java语言
int sum = 0;
JavaRDD<Integer> rdd = sc.parallelize(data); // Wrong: Don't do this!!
rdd.foreach(x -> sum += x); println("sum value: " + sum);
本地模式与集群模式对比
上面代码的行为是不明确的,可能无法按预期工作。为了执行作业,Spark将RDD操作的处理分解成任务(tasks),每个task由一个executor执行。在执行之前,Spark计算任务的闭包。闭包是executor在RDD上执行计算(在本例中是foreach()方法)时必须可见的那些变量和方法。闭包被序列化并被发送给每一个executor。
发送给每一个executor的闭包中的变量都是副本,因此,当sum在foreach()方法中被引用时,它不再是驱动程序节点上的sum。在驱动程序节点的内存中还有一个sum,但它对executor不再可见。executors只能看见序列化闭包中的sum的副本。所以,sum的最终值仍然是0,因为对sum的所有的操作都引用了序列化闭包中的值。
在本地模式下,在某些情况下,foreach()方法实际上将在与驱动程序相同的JVM上执行,并将引用相同的原始sum,并可能更新它。
为了保证这种情况下行为是明确的,我们应该使用一个累加器Accumulator。Spark中的累加器是专门用来提供一种机制,在这种机制下,在集群的所有工作节点上更新一个变量是安全的。
通常,闭包--像循环或者本地定义的方法,不应该用来改变一些全局状态。Spark没有定义或者保证从闭包外引用的对象的改变行为。这样做的一些代码可能在本地模式下正常工作,但这是偶然的,在分布式模式下是不会像预期的一样工作的。如果需要全局聚合,请使用累加器。
如上,可以改成:
JavaRDD<Integer> rdd = sc.parallelize(data, Runtime.getRuntime().availableProcessors() * 4);
LongAccumulator longAccumulator = sc.sc().longAccumulator();
rdd.foreach(longAccumulator::add);
System.out.println("sum value: " + longAccumulator.value());
在rdd操作外定义一个Accumulator变量,调用其add()方法。
打印RDD中的元素
另一个常见的操作是试图用rdd.foreach(println)或者rdd.map(println)来打印RDD中的元素。在单节点上,这将打印RDD的所有的元素,符合预期。然而,在集群模式下,被executors调用的打印输出会打印输出到executor中的stdout,而不是driver的stdout,所以驱动程序上的stdout不会显示打印信息的。为了在驱动程序上打印所有的元素,我们可以调用collect()方法来首先把所有的RDD元素带到驱动程序节点上:rdd.collect().foreach(println)。然而,这样做很可能导致driver内存不足,因为collect()方法会把RDD所有的元素都带到了一个机器上。如果你只是想打印RDD的一些元素,一个更加安全的方法是使用take()方法:rdd.take(100).foreach(println)。禁止使用collect()方法。在平安就踩到了坑,写的spark任务一直报内存不足。
使用键值对
Java语言
尽管大多数Spark操作是在包含一些对象类型的RDD上运行的,但是有一些操作仅在键值对的RDD上可用。最常见的就是分布式的shuffle操作,比如按照键来对元素进行分组或者聚合操作。
在Java中,键值对是用Scala标准库中的scala.Tuple2类来表示的。你可以通过调用new Tuple2(a, b)来创建一个tuple对象,并通过tuple._1及tuple._2来访问它的属性。
键值对的RDD由JavaPariRDD类来表示。由JavaRDD构造JavaPair,需要一些特殊的map操作,有mapToPair()方法、flatMapToPair()、mapPartitionsToPair()。
JavaPairRDD既支持标准的RDD操作,又支持键值对RDD的特殊操作。
例如,以下代码通过对键值对RDD进行reduceByKey操作来计算文本中每行文本出现的次数:
JavaRDD<String> lines = sc.textFile("data.txt");
JavaPairRDD<String, Integer> pairs = lines.mapToPair(s -> new Tuple2(s, 1));
JavaPairRDD<String, Integer> counts = pairs.reduceByKey((a, b) -> a + b);
接下来可以用counts.sortByKey()方法按照字母顺序来对键值对RDD进行排序,然后取first。
注意:当使用自定义的类型作为键值对RDD的键时,你必须确保自定义的equals()方法和hashCode()方法匹配。有关完整的详细信息,请参阅Object.hashCode()文档。
转换操作
以下列出了Spark常用的转换操作。
map(Function func),返回一个转换后的数据集。
filter(Function func),返回一个过滤后的数据集。
flatMap(FlatMapFunction func)
mapPartitions(FlatMapFunction func)
mapPartitionsWithIndex(Function2 func, boolean preservesPartitioning)
union(JavaRDD rdd)、union(JavaPairRDD pairRDD)
intersection(JavaRDD rdd)、intersection(JavaPairRDD pairRDD)
distinct()
reduceByKey(Function2 func),仅可由JavaPairRDD调用
aggregateByKey(U zeroValue, Function2 seqFunc, Function2 combFunc)
sortByKey(Comparator comparator),注意这里的Comparator实例不能简单的由lambda表达式赋值,因为Comparator接口没有继承序列化接口,所以这里必须自定义一个类,即实现Comparator接口,又实现Serializable接口,创建其实例,作为sortByKey()方法参数。
join(JavaPairRDD other),只能由pairRDD调用,RDD没有join方法。
cogroup(JavaPairRDD other),也可以传两个JavaPairRDD实例,甚至三个JavaPairRDD实例。
coalesce(int numPartitions, boolean shuffle),减少分区数量。比如将有10个分区的结果集转换成只有5个分区,通常用在filter()后。
repartition(int numPartitions),将结果集重新分区,中间有shuffle操作。等同于coalesce(numPartitions, true)。
行为操作
以下列出了Spark常用的行为操作。
reduce(Function2 func)
collect(),返回一个List对象。
collectAsMap(),仅可由pairRDD调用,返回一个Map对象。注意,如果pairRDD有多个值对应一个键的话,前面的键值对会被后面的键值对覆盖掉。
count()
countByKey(),仅可由pairRDD调用,返回一个Map对象。对键一样的键值对求总个数。countByKey在byKey算子里算是及其特殊的存在,其他byKey算子都是转换操作,而countByKey算子是行为操作。
first()
foreach(VoidFunction func),对RDD或者pairRDD的每一个元素应用一个函数
foreachPartition(VoidFunction func),对RDD或者pairRDD的每个分区应用一个函数
take(int num)
takeOrdered(int num, Comparator comparator)
saveAsTextFile(String path)
saveAsObjectFile(String path)
saveAsHadoopFile(String path, Class keyClass, Class valueClass, Class outputFormatClass),仅可由pairRDD调用。
saveAsNewAPIHadoopFile(String path, Class keyClass, Class valueClass, Class outputFormatClass),仅可由pairRDD调用。
Spark API为一些行为操作也提供了异步的版本,具体有collectAsync()、countAsync()、foreachAsync()、foreachPartitionAsync()、takeAsync(),这些方法都是异步的。
Shuffle
一些Spark操作会触发Shuffle事件。Shuffle是Spark重新分配数据的机制,旨在不同分区之间重新分组。这通常涉及在executors之间复制数据,使得shuffle成为复杂而昂贵的操作。
背景
要理解shuffle过程中发生了什么,我们可以考虑reduceByKey操作的例子。reduceByKey操作生成一个新的RDD,其中单个键的所有值都组合到一个元组中--键和对与该键相关的所有值执行reduce函数的结果。面临的挑战是,对应一个键的所有的值并不都在一个分区上,甚至是同一机器上,但是它们必须位于同一地点才能计算出结果。
在Spark中,数据通常不是跨分区分布的,而是在特定操作的必要位置(In Spark, data is generally not distributed across partitions to be in the necessary place for a specific operation)。在计算过程中,单个任务在单个分区上运行--因此,要组织单个reduceByKey任务执行所需要的所有数据,Spark需要执行一个多对多的操作(all-to-all operation)。它必须从所有分区中读取所有键的值,然后将各个分区上的值汇总在一起以计算每个键的最终结果--这就是所谓的shuffle。
可能导致shuffle的操作包括重新分区操作(repartition()方法和coalesce()方法)、byKey操作(除countByKey外),以及连接操作(如cogroup()方法和join()方法)。
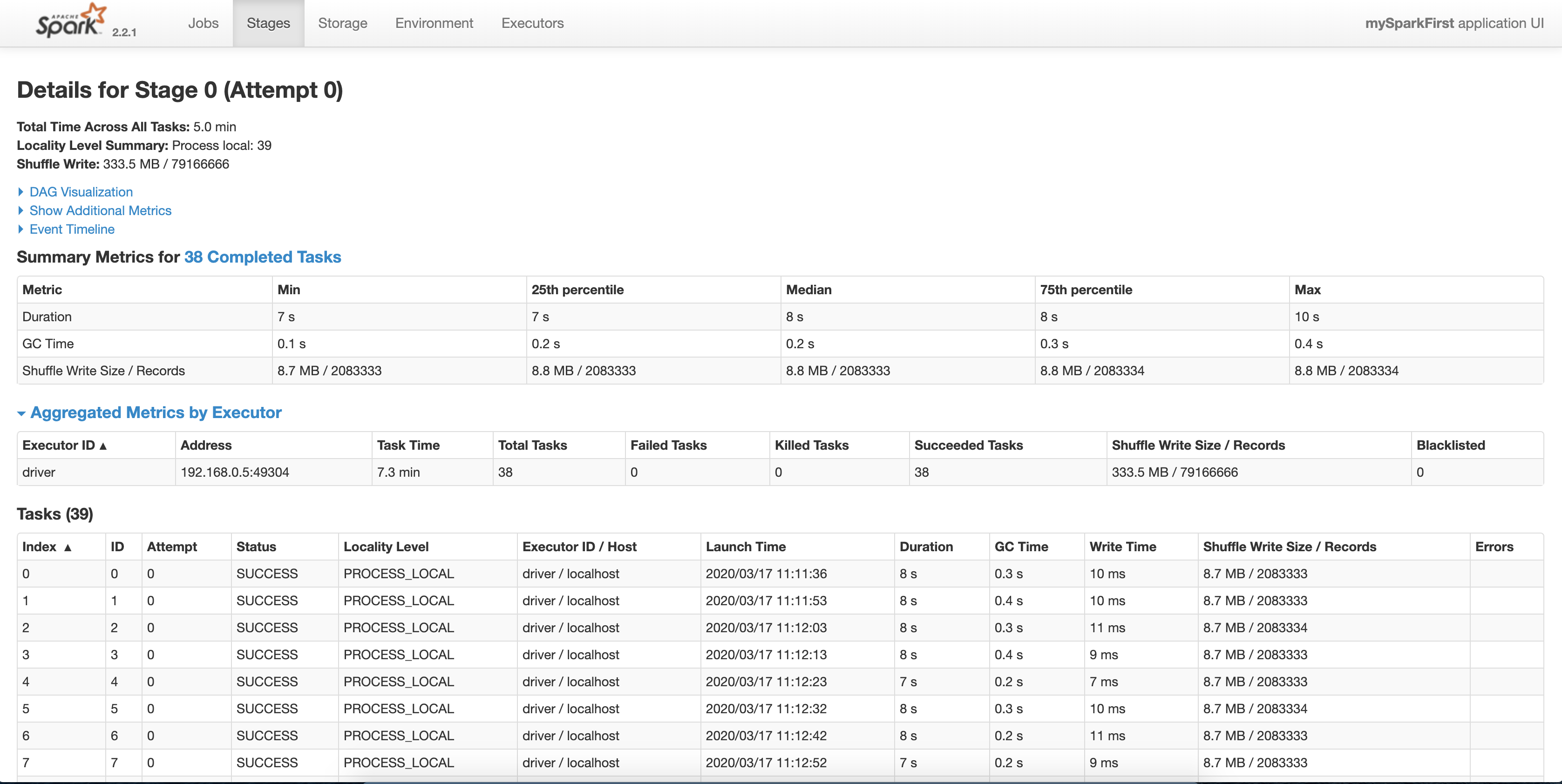
调用reduceByKey操作后的监控页。可以看到的确有shuffle。
性能影响
Shuffle是一个昂贵的操作,因为它涉及到磁盘I/O,数据序列化和网络I/O。为了组织数据,Spark生成一组任务--map任务来组织数据,以及一组reduce任务来聚合它。Shuffle术语来自MapReduce,并不直接与Spark的map操作和reduce操作有关。
在内部,独立的map任务的结果会被保存在内存中,直到它们不合适为止。然后,它们会根据目标分区排序并写入单个文件。在reduce端,任务读取相关的排序块。
某些shuffle操作会消耗大量的堆内存,因为它们使用内存中的数据结构在传输之前或之后组织记录。当数据不适合存储在内存中时,Spark会将这些表刷到磁盘上,导致额外的磁盘I/O开销和垃圾回收开销。
Shuffle也会在磁盘上生成大量的中间文件。从Spark1.3开始,这些文件将被保留,直到相应的RDD不再使用并被垃圾回收。这样做是为了在重新计算谱系时不需要重新创建shuffle文件(This is done so the shuffle files do not need to be re-created if the lineage is re-computed)。如果应用程序保留对这些RDD的引用,或者GC不经常引入,垃圾收集可能会在很长一段时间后才会发生。这意味着长时间运行的Spark作业可能会消耗大量的磁盘空间。在配置SparkContext时,临时存储目录由spark.local.dir参数指定。
Shuffle行为可以通过一系列配置参数调整。请参阅Spark Configuration Guide中的Shuffle Behavior部分。
RDD持久化
Spark最重要的功能之一就是持久化(或者缓存)一个数据集到内存中。当持久化RDD时,每个节点存储它在内存计算中的所有分区,并且在该数据集的其他操作中重用它们。这使得未来的行动更快(通常超过10倍)。缓存是迭代算法和快速交互式使用的关键工具。
你可以通过调用persist()或者cache()方法来持久化一个RDD。第一次在行为操作中计算时,它将被保存在节点的内存中。Spark的缓存是容错的--如果RDD的任何分区丢失,它将会自动使用最初创建它的转换重新计算。
另外,每个持久化的RDD可使用不同的存储级别进行存储。这些级别通过传递一个StorageLevel对象给persist()方法来设置。cache()方法是使用默认存储级别的简写,即StorageLevel.MEMORY_ONLY(将反序列化的对象存储在内存中)。所有的存储级别可见StorageLevel的源码注释。
Spark自动持久化shuffle操作的一些中间数据,即使用户没有手动调用persist()方法。这样做是避免在shuffle过程中节点失败时重新计算整个输入。我们仍然建议用户对打算重复使用的RDD调用persist()方法进行持久化。
选择哪个存储级别?
Spark的存储级别旨在提供内存使用率和CPU效率之间的不同权衡。我们建议通过以下过程来选择一个:
如果你的RDD适合默认的存储级别,那么就这样吧。这是CPU效率最高的选项,允许RDD上的操作尽可能快地运行。
如果不是,请尝试使用MEMORY_ONLY_SER并选择一个快速序列化库来使对象更加节省空间,但是访问速度仍然相当快。
除非计算你的数据集的函数很昂贵,或者会过滤大量数据,否则不要把数据刷到磁盘上。否则,重新计算一个分区可能和从磁盘上读取一样快。
如果你想快速故障恢复的话,请使用副本存储级别。所有的存储级别都可通过重新计算丢失的数据来提供完整的容错能力,但是副本数据可以让你继续在RDD上运行任务,而不需要等待重新计算丢失的分区。
删除数据
Spark会自动监视每个节点上的缓存使用情况,并以最近最少使用(LRU)方式删除旧的数据集。如果你想手动删除一个RDD的话,可以调用其unpersist()方法。
共享变量
通常,当一个传递给Spark的函数在远程集群节点上执行时,它将在函数中使用的所有变量的单独副本上运行。这些变量被复制到每台机器上,它们的更新都不会传播到驱动程序。Spark为两种常见使用模式提供了两种有限类型的共享变量:广播变量和累加器。
广播变量
广播变量允许程序员在每台机器上保存一个只读变量,而不是用任务发送一个变量的副本。例如,可以使用它们以有效的方式为每个节点提供大的输入数据集的副本。Spark还试图使用高效的广播算法来分发广播变量,以降低通信成本。
Spark的行为是通过一系列的阶段执行的,由分散的shuffle操作分开。Spark会自动广播每个阶段中任务所需的通用数据。以这种方式广播的数据以序列化形式缓存,并在运行每个任务之前反序列化。这意味着只有跨多个阶段的任务需要相同的数据或以反序列化形式缓存数据很重要时,显示创建广播变量才是有用的。
广播变量是通过调用SparkContext的broadcast(v)从变量v创建的。广播变量是v的一个包装,它的值可以通过Broadcast实例的value()方法获取。下面的代码显示了这一点:
Java语言
Broadcast<int[]> broadcastVar = sc.broadcast(new int[] {1, 2, 3});
broadcastVar.value();
// returns [1, 2, 3]
广播变量创建之后,应该在集群上运行的任何函数中使用广播变量而不是原始变量v,来防止v被多次传送到节点上。此外,变量v在广播之后不应该做更改,以确保所有节点获得的广播变量的值相同。
累加器
累加器是只能通过关联和交换操作累加的变量,因此可以在并行情况下有效地支持。它们可以用来实现计数器或者求和。Spark本身仅支持数字类型的累加器,我们可以自定义新类型的累加器。
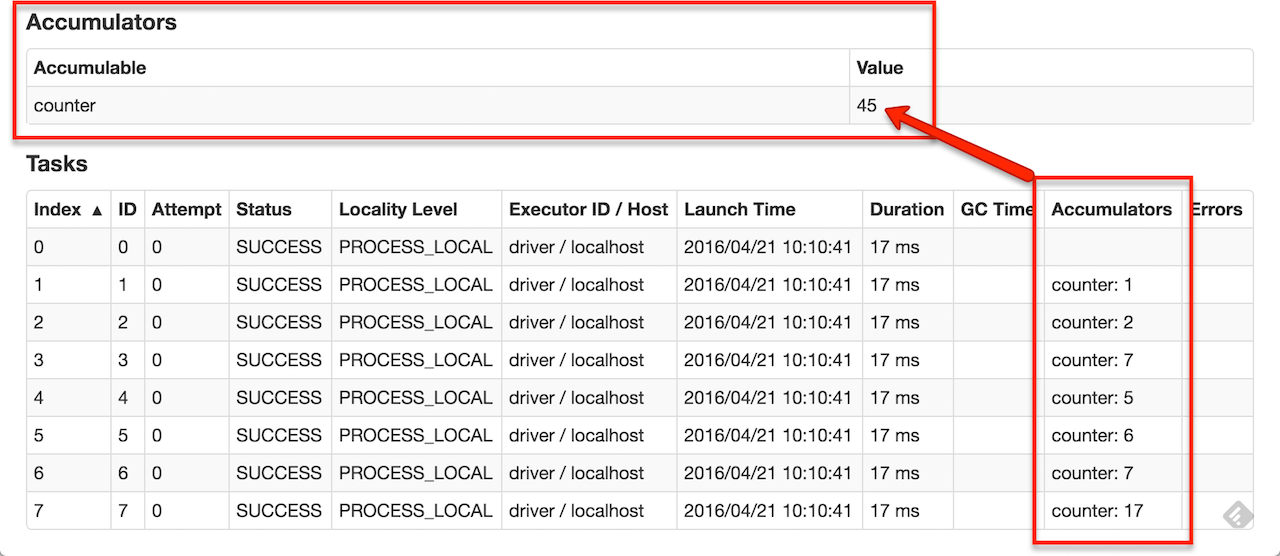
作为用户,你可以创建一个命名的或者匿名的累加器。如下图所示,一个命名的累加器将显示在修改该累加器的阶段(stage)的web ui中。Spark会在任务(Tasks)表中展示由任务更改的每一个累加器的值。
Java语言
一个数字类型的累加器可以通过调用SparkContext的longAccumulator()方法或者doubleAccumulator()方法来生成,它们都继承了AccumulatorV2抽象类,分别累加Long型的值、Double类型的值。在集群工作节点上运行的任务通过调用AccumulatorV2实例的add()方法来更改累加器的值,但它们无法获取累加器的值,只有驱动程序可以通过调用AccumulatorV2实例的value()方法来获取累加器的值。
下面的代码显示了一个累加器用来累加一个数组的元素:
LongAccumulator accum = jsc.sc().longAccumulator(); sc.parallelize(Arrays.asList(1, 2, 3, 4)).foreach(x -> accum.add(x));
// ...
// 10/09/29 18:41:08 INFO SparkContext: Tasks finished in 0.317106 s accum.value();
// returns 10
部署应用到集群
参考application submission guide
从Java/Scala启动Spark工作
org.apache.spark.launcher包提供了启动Spark工作的API,主要是SparkLauncher类。也就是说,我们不仅仅可以通过spark-submit脚本来启动Spark应用,还可以以代码的方式启动Spark应用。
参考http://blog.csdn.net/knowledgeaaa/article/details/54730915
css三种布局方式的更多相关文章
- Python 45 css三种引入方式以及优先级
一:css三种引入方式 三种方式为:行间式 | 内联式 | 外联式 行间式 1.在标签头部的style属性内 2.属性值满足的是css语法 3.属性值用key:value形式赋值,value具 ...
- css三种引入方式以及其优先级的说法
css 三种引入方式 方式一:行间式 1.在标签头部的style属性内 2.属性值满足css语法 3.属性值用key:value形式赋值,value具有单位 4.属性值之间用 分号 : ...
- 前端 CSS 三种引入方式
CSS三种引入方式 行内样式 内接样式 外部样式 链接式 导入式 行内样式 就是在标签加上style属性设置样式 <!DOCTYPE html> <html lang="e ...
- 006 CSS三种引入方式
CSS三种引入方式 一.三种方式的书写规范 1.行间式 <div style="width: 100px; height: 100px; background-color: red&q ...
- CSS三种布局模型是什么?
在网页中,元素有三种布局模型:流动模型(Flow) 默认的.浮动模型 (Float).层模型(Layer).下面我们来看一下这三种布局模型. 三种布局模型介绍: 1.流动模型(Flow) 流动(Flo ...
- css 三种引用方式
内联式 代码 <!doctype html> <html lang="en"> <head> <meta charset="UT ...
- CSS三种引入方式:内联、页级、外联
1.内联CSS 内联CSS也可称为行内CSS或者行级CSS,它直接在标签内部引入,显著的优点是十分的便捷.高效:但是同时也造成了不能够重用样式的缺点,如果代码行数到达一定长度不建议采用.通常内联CSS ...
- (一)CSS三种插入方式
CSS概述 CSS(Cascading Style Sheets)指层叠样式表,样式定义了如何显示HTML元素. 样式通常存储在样式表中,样式与HTML分离解决了内容与表现分离的问题. 多个样式表可以 ...
- css-1,css的三种引入方式 基本选择器
<!-- (1)CSS 层叠样式表 作用:修饰网页结构 (2)css的三种引入方式 权重: 优先级高 权重大 谁在页面谁的权重大 - 行内样式 注意:行内样式的优先级是最高的 - 内接样式 - ...
随机推荐
- 【Chrome】如何在C++中增加给JavaScript调用的API
本文示例说明了如何在Chrome浏览器中增加JavaScript API.为了简化,先假设是在已有的namespace中增加一个新的API,文章的最后将指出如果增加一下全新的namespace所需注意 ...
- ZOJ 3529 A Game Between Alice and Bob 博弈好题
A Game Between Alice and Bob Time Limit: 5 Seconds Memory Limit: 262144 KB Alice and Bob play t ...
- sphinx2.8.8的配置文件
# # Sphinx configuration file sample # # WARNING! While this sample file mentions all available opti ...
- wubi安装ubuntu后,增加swap大小,优化swap的使用参数-----------让ubuntu健步如飞,为编译android源码准备
wubi安装ubuntu后,终端输入free -m可以查到如下信息: total used free shared buffers cached Mem: 1944 1801 143 0 557 70 ...
- Liferay的架构:缓存(第一部分)
这次,我将要涉及到一个非常重要的概念:缓存.在当今的web应用中,如果没有设计一个比较好的缓存系统,在web中就不可能有一个良好的性能.所以我将要 提到的缓存不仅仅能够更好地理解Liferay架构,而 ...
- mysql数据库 触发器简单实例
触发器(trigger):监视某种情况,并触发某种操作. 触发器创建语法四要素:1.监视地点(table) 2.监视事件(insert/update/delete) 3.触发时间(after/befo ...
- 结构-行为-样式-PS笔记
1.矩形选框,按住Shift就可以成为正圆或者正方形.按住ALt就可以控制圆心的位置: 2.美颜:滤镜--模糊--回到开始--历史记录工具,去掉不要的地方. 3.套索工具双击闭合:4.钢笔工具是做选区 ...
- Mysql连表查询
http://blog.csdn.net/qmhball/article/details/8000003 可以参考这篇文章
- hdu1041
#include <iostream> #include <string> using namespace std; const int SIZE = 1001; const ...
- SQL sever 创建定时执行任务
在SQL的使用过程中,我们经常要做些数据备份以及定时执行的任务. 这些任务能够帮助我们简化工作过程. 下面我们了解下如何创建一个定时执行的存储过程. 首先我们要打开 SQL server 代理服务 选 ...