从CK+库提取标记点信息
1.CK+动态表情库介绍
The Extended Cohn-Kanade Dataset(CK+)
这个数据库是在 Cohn-Kanade Dataset 的基础上扩展来的,发布于2010年。这个数据库比起JAFFE 要大的多。而且也可以免费获取,包含表情的label和Action Units 的label。
这个数据库包括123个subjects, 593 个 image sequence,每个image sequence的最后一张 Frame 都有action units 的label,而在这593个image sequence中,有327个sequence 有 emotion的 label。这个数据库是人脸表情识别中比较流行的一个数据库,很多文章都会用到这个数据做测试。
In this Phase there are 4 zipped up files. They relate to:
下载数据库后有以下四个文件
1) The Images (cohn-kanade-images.zip) - there are 593 sequences across 123 subjects which are FACS coded at the peak frame. All sequences are from the neutral face to the peak expression.
2) The Landmarks (Landmarks.zip) - All sequences are AAM tracked with 68points landmarks for each image.
3) The FACS coded files (FACS_labels.zip) - for each sequence (593) there is only 1 FACS file, which is the last frame (the peak frame). Each line of the file corresponds to a specific AU and then the intensity. An example is given below.
4) The Emotion coded files (Emotion_labels.zip) - ONLY 327 of the 593 sequences have emotion sequences. This is because these are the only ones the fit the prototypic definition. Like the FACS files, there is only 1 Emotion file for each sequence which is the last frame (the peak frame). There should be only one entry and the number will range from 0-7 (i.e. 0=neutral, 1=anger, 2=contempt, 3=disgust, 4=fear, 5=happy, 6=sadness, 7=surprise). N.B there is only 327 files- IF THERE IS NO FILE IT MEANS THAT THERE IS NO EMOTION LABEL (sorry to be explicit but this will avoid confusion).
The Images (cohn-kanade-images.zip)图片库中包含了从平静到表情表现峰值的图片,实际使用中建议使用比较明显的图片,并进行相应的预处理。
Emotion_labels.zip标签压缩包中
0-中性
1-愤怒
2-蔑视
3-厌恶
4-恐惧
5-高兴
6-悲伤
7-惊讶
2.特征点分析
因为我们自己建立的表情库是用RealSense摄像头采集的,我们想验证我们的识别方法在在CK+库上的识别效果,所以需要做的是对CK库进行特征点提取。
在提取之前我们先要分析CK库中特征点的ID,这样方便我们找到RealSense中对应的点。
选择CK库中的一张图片,读数据,将标记点在图片中画出来。
def drawLandmarkPoint(img,color):
draw = ImageDraw.Draw(img)
myfont = ImageFont.truetype("C:\\WINDOWS\\Fonts\\SIMYOU.TTF", 10) file_txt = open("S035_003_00000001_landmarks.txt", "a+")
lines = file_txt.readlines()
t=1 #特征点标号
for line in lines:
line_object=line.split(" ")
x=float(line_object[3]) #原始数据是科学记数法,这里转换成浮点型
y=float(line_object[-1])
print x,y
#draw.ellipse((0, 0, 200, 200), fill="red", outline="red")
draw.text((x,y), bytes(t), font=myfont, fill=color)
t+=1
file_txt.close()
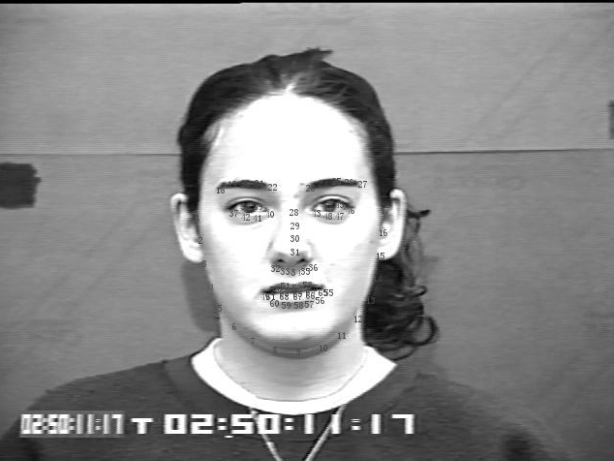
CK库中的标记点共有68个。
3.特征点转换CK_to_RealSense
可以看出特征点的顺序和RealSense是不一样的。相比RealSense的78个标记点,CK+中只有68个,且CK库中有几个点RealSense中没有,所以,我们最后存下来的点在66个。
转化之后主要缺失的点是眉毛下眉的2x3=6个点,左右眼睛2x2=4个点。
多出的2个点是鼻子2侧,CK有5个,RealSense只有3个。所以最后保存了66个点。
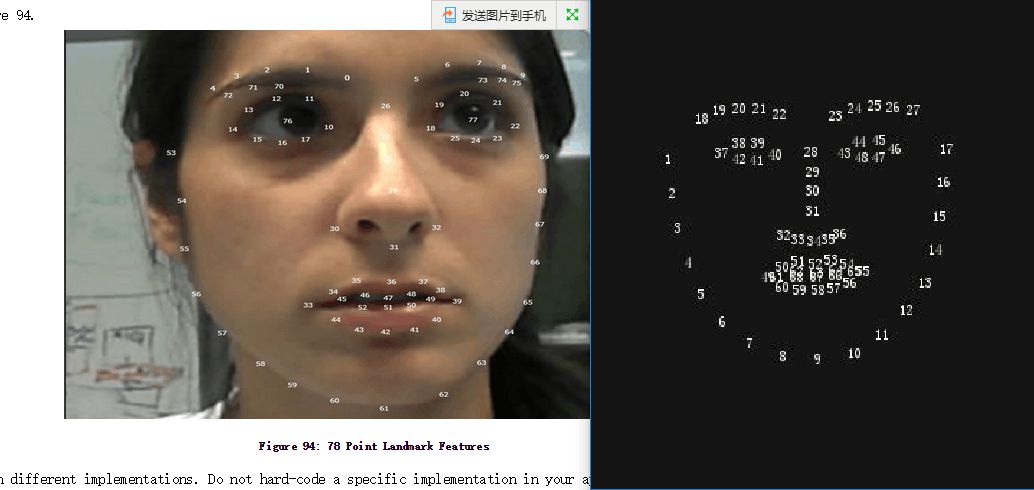
在程序里面建立元祖,标注转化的对应关系。
依次是,左眉,右眉,左眼,右眼,鼻子,外嘴唇,内嘴唇,脸轮廓
#将ck点转换成realsense的点 r:ck 共66个点。
CK_to_RealSense={0:22,1:21,2:20,3:19,4:18,
5:23,6:24,7:25,8:26,9:27,
10:10,11:39,12:38,14:37,16:42,17:41,
18:43,19:44,20:45,22:46,24:47,25:48,
26:28,27:29,28:30,29:31,30:32,31:34,32:36,
33:49,34:50,35:51,36:52,37:53,38:54,39:55,40:56,41:57,42:58,43:59,44:60,
45:61,46:62,47:63,48:64,49:65,50:66,51:67,52:68,
53:1,54:2,55:3,56:4,57:5,58:6,59:7,60:8,61:9,62:10,63:11,64:12,65:13,66:14,67:15,68:16,69:17
}
RealSenseID=[0,1,2,3,4,
5,6,7,8,9,
10,11,12,14,16,17,
18,19,20,22,24,25,
26,27,28,29,30,31,32,
33,34,35,36,37,38,39,40,41,42,43,44,
45,46,47,48,49,50,51,52,
53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69
]
4.进行处理
CK+库中的动态表情是通过动态序列来展示的,所以一个表情会有多张图片,需要的是将一个表情的多张图片进行处理,提取特征点信息,然后存到一个txt中,表现出动态的变化。
所以open操作的模式要写成
fCK_image = open(CKDataDir, "a"),可以多次写入,这样对同一个目录下多个图片的数据写入一个文件。
def readFile(filepath):
f1 = open(filepath, "r")
nowDir = os.path.split(filepath)[0] #获取路径中的父文件夹路径
fileName = os.path.split(filepath)[1] #获取路径中文件名
#对新生成的文件进行命名的过程
CKDataDir = os.path.join(nowDir, "CKData.txt") fCK_image = open(CKDataDir, "a")
fCK_image.write(os.path.splitext(fileName)[0]+"\t") lines = f1.readlines()
for n in range(0,66):
#for n in range(1, lines_count+1):
line = lines[CK_to_RealSense[RealSenseID[n]]-1]
line_object = line.split(' ') id=RealSenseID[n]
if n==63:
time=4
image_x = float(line_object[3])
image_y = float(line_object[-1])
pointData = bytes(id) + "\t" + bytes(image_x) + "\t" + bytes(image_y) +"\t"
fCK_image.write(pointData)
print pointData fCK_image.write("\n")
f1.close()
fCK_image.close() global picturecount
picturecount+=1
5.递归批量处理数据
对CK库中,标记点的文件夹进行递归操作。
需要注意的是,打开文件操作的时候,需要在路径前面加上字符r。
eachFile(r"E:\RealSense\CK+\Landmarks_track")
因为在过程中存在这样的路径,里面有\0,程序会认为是这个字符串结束了,然后运行不下去。
E:\RealSense\CK+\Landmarks\S010\001\S010_001_00000001_landmarks.txt
def eachFile(filepath):
global emotioncount pathDir = os.listdir(filepath) #获取当前路径下的文件名,返回List
for s in pathDir:
newDir=os.path.join(filepath,s) #将文件命加入到当前文件路径后面
if os.path.isfile(newDir) : #如果是文件
if os.path.splitext(newDir)[1]==".txt": #判断是否是txt
readFile(newDir) #读文件
pass
else:
eachFile(newDir) #如果不是文件,递归这个文件夹的路径
emotioncount += 1
最后的将处理的图片数量和表情个数打印输出。
从CK+库提取标记点信息的更多相关文章
- 从APNIC提取IP信息
从APNIC提取IP信息 https://blog.csdn.net/nullzeng/article/details/17538009 Apnic介绍简而言之,Apnic是全球5个地区级的Inter ...
- tika提取pdf信息异常
org.apache.tika.sax.WriteOutContentHandler$WriteLimitReachedException: Your document contained more ...
- java 反射提取类信息, 动态代理 和过滤某些方法演示
java 反射提取类信息, 动态代理 和过滤某些方法演示 package org.rui.classts.reflects; import java.lang.reflect.Constructor; ...
- 论文系统Step1:从日志记录中提取特定信息
论文系统Step1:从日志记录中提取特定信息 前言 论文数据需要,需要实现从服务器日志中提取出用户的特定交互行为信息.日志内容如下: 自己需要获取"请求数据包一行的信息"及&quo ...
- python调用mediainfo工具批量提取视频信息
写了2个脚本,分别是v1版本和v2版本 都是python调用mediainfo工具提取视频元数据信息 v1版本是使用pycharm中测试运行的,指定了视频路径 v2版本是最终交付给运营运行的,会把v2 ...
- JDBC程序优化--提取配置信息放到属性文件中
JDBC程序优化--提取配置信息放到属性文件中 此处仅仅优化JDBC连接部分,代码如下: public class ConnectionFactory { private static String ...
- extract_by_one 根据二维数组中某字段来提取数组信息,查看有无重复信息
public function tt(){ $param = array( array ( 'hykno' => '2222222-CB', 'tcdk_fid' => '458B6D70 ...
- 【BioCode】Elm格式中提取位点信息
说明: ①Elm格式: PLMD ID Uniprot Accession Position Type Sequence Species PMIDsPlMD编号 ...
- 在Scrapy中如何利用Xpath选择器从HTML中提取目标信息(两种方式)
前一阵子我们介绍了如何启动Scrapy项目以及关于Scrapy爬虫的一些小技巧介绍,没来得及上车的小伙伴可以戳这些文章: 手把手教你如何新建scrapy爬虫框架的第一个项目(上) 手把手教你如何新建s ...
随机推荐
- 转:Selenium中的几种等待方式,需特别注意implicitlyWait的用法
最近在项目过程中使用selenium 判断元素是否存在的时候 遇到一个很坑爹的问题, 用以下方法执行的时候每次都会等待很长一段时间,原因是因为对selenium实现方法了解不足导致一直找不到解决方法. ...
- Windows下MongoDB安装及创建用户名和密码
下载MongoDB的安装文件https://www.mongodb.com/download-center#community,选择合适的版本(注:本人选择的是3.2.6) 下载完MongoDB.ms ...
- jQuery两种扩展插件的方式
<!DOCTYPE HTML> <html> <head> <meta http-equiv="Content-Type" content ...
- 在linux下用tomcat部署java web项目的过程与注意事项
在linux下用tomcat部署java web项目的过程与注意事项 一.安装JDK 到http://www.oracle.com/technetwork/java/javase/downloads/ ...
- 理解用requireJs 来实现javascript的模块化加载
这是我看到的一片关于requirejs的初学者的文章,写的不错,下面结合自己的理解记录一下: 原文:http://www.sitepoint.com/understanding-requirejs-f ...
- struts1.x中web.xml文件的配置
1.配置欢迎文件清单 当客户访问Web应用时,如果仅仅给出Web应用的Root URL,没有指定具体的文件名.Web容器会自动调用Web应用的欢迎文件.<welcome-file-li ...
- MFC-----在MFC中使用Picture控件加载任意图片
对于刚刚接触OpenCV的童鞋来说,如何在MFC中加载并显示一张图片.应该是初期必定会碰到的问题之一.因此本文在分享这方面经验的同时,也相当于是写给自己的一份备忘录. 本文使用的是OpenCV2.1+ ...
- nginx的内页跳转总结
刚进公司的时候老大一直在要求php做内页跳转,当时也不太了解细节所以一直没有说话.后来php问我你会不会做内页跳转,我说会一点就做了几个,从此搞内页跳转搞了两个星期.至于为什么做内页跳转哪就暂时不 ...
- 安卓图表引擎AChartEngine(六) - 框架源码结构图
包结构: org.achartengine: org.achartengine.model: org.achartengine.renderer: org.achartengine.tools: 安卓 ...
- 【HighCharts系列教程】一、认识Highcharts
一.什么是HighCharts HighCharts是网页报表工具,开发语言是Javascript HighCharts是一个简单易用.美观.跨平台.跨浏览器的图表工具 HighCharts支持图表的 ...