Python之tornado框架实现翻页功能
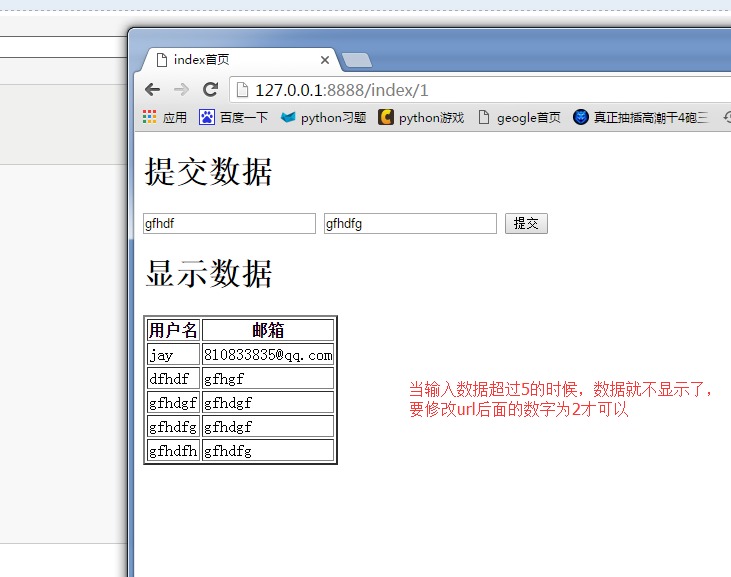
1、结果如图所示,这里将html页面与网站的请求处理放在不同地方了

start.py代码
import tornado.ioloop
import tornado.web
from controllers import home settings = { 'static_path':'statics',#静态文件配置,需要特殊处理
'static_url_prefix':'/sss/',#标记文件开始的名字
} #路由映射,根据不同url对应到不同的类里面
application = tornado.web.Application([
(r"/index/(?P<page>\d*)", home.IndexHandler),
],**settings)#基于正则的路由,?P<page>表示为正则匹配到的内容起了一个名字 if __name__=='__main__':
application.listen(8888)
tornado.ioloop.IOLoop.instance().start()
home.py里面的代码
import tornado.web List_Info=[
{'username':'jay','email':'810833835@qq.com'}
] class IndexHandler(tornado.web.RequestHandler):
def get(self,page): #每页显示五条数据
#page是当前页
#第一页: 0:5 List_Info[0:5]
#第二页:5:10
#start: (page-1)*5
#end: (page)*5 try:page=int(page)
except:page=1
print(page)
if page <1:
page =1
start = (page - 1)*5
end = page * 5
current_ist = List_Info[start:end] self.render('E:\\练习2\\tornado_day2\\views\\home\\index.html',list= current_ist,page=page)
#E:\\练习2\\tornado_day2\\views\\home\\index.html
def post(self,page):
user = self.get_argument('username')
email = self.get_argument('email')
temp = {'username':user,'email':email}
List_Info.append(temp)
self.redirect('/index/'+page)
home文件里面的index.html代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>index首页</title>
</head>
<body>
<h1>提交数据</h1>
<form method="post" action="/index/{{page}}">
<input name="username" type="text">
<input name="email" type="text">
<input value="提交" type="submit">
</form>
<h1>显示数据</h1>
<table border="2">
<thead><tr>
<th>用户名</th>
<th>邮箱</th>
</tr></thead>
<tbody>
{% for line in list %}
<tr>
<td>{{line['username']}}</td>
<td>{{line['email']}}</td>
</tr>
{% end %}
</tbody>
</table>
</body>
</html>
运行结果如图
最后我们修改一下home里面的代码,实现选择页面功能
import tornado.web List_Info=[
{'username':'jay','email':'810833835@qq.com'}
] for i in range(1000):
data = {'username': i, 'email': i * 2}
List_Info.append(data)
class IndexHandler(tornado.web.RequestHandler):
def get(self,page): #每页显示五条数据
#page是当前页
#第一页: 0:5 List_Info[0:5]
#第二页:5:10
#start: (page-1)*5
#end: (page)*5 try:page=int(page)
except:page=1 if page <1:
page =1
start = (page - 1)*5
end = page * 5#每页最多显示五条数据
current_ist = List_Info[start:end]
all_page ,c = divmod(len(List_Info),5)#每五条数据一页,判断多少页
if c>0:#有余数则多一页
all_page +=1
list_page =[]
print(all_page)
if page <5:
for p in range(9):
if p+1 == page:
temp = '<a class="active" href="/index/%s">%s</a>' % (p+1,p+1)
else:
temp = '<a href="/index/%s">%s</a>' % (p + 1, p + 1)
list_page.append(temp)
elif page >all_page-5:#判断页数是否在最前或者最后五页 for p in range(all_page-9,all_page):
if p + 1 == page:
temp = '<a class="active" href="/index/%s">%s</a>' % (p + 1, p + 1)
else:
temp = '<a href="/index/%s">%s</a>' % (p + 1, p + 1)
list_page.append(temp)
else:
for p in range(page-5,page+4):
if p+1 == page:
temp = '<a class="active" href="/index/%s">%s</a>' % (p+1,p+1)
else:
temp = '<a href="/index/%s">%s</a>' % (p + 1, p + 1)
list_page.append(temp)
str_page = ''.join(list_page)
# str_page = list_page,不写join则会在页面上显示逗号 self.render('E:\\练习2\\tornado_day2\\views\\home\\index.html',list= current_ist,page=page,str_page=str_page)
#E:\\练习2\\tornado_day2\\views\\home\\index.html
def post(self, page):
user = self.get_argument('username')
email = self.get_argument('email')
temp = {'username':user,'email':email}
List_Info.append(temp)
self.redirect('/index/'+page)
print(List_Info)
对于index.html文件也要做少少修改
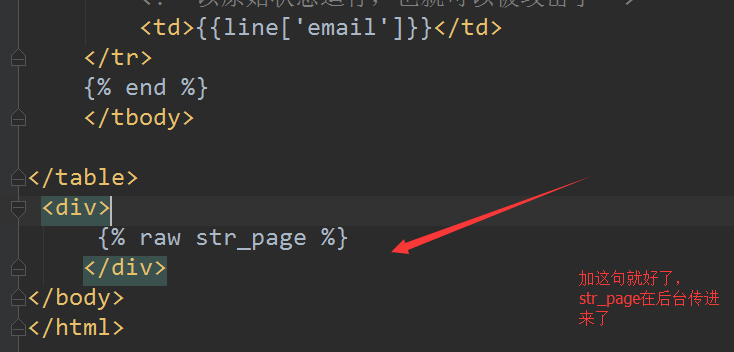
最后把home里面的代码封装一下,如图
import tornado.web List_Info=[
{'username':'jay','email':'810833835@qq.com'}
] for i in range(1000):
data = {'username': i, 'email': i * 2}
List_Info.append(data)#认为创建1000条数据 class Pagination:
def __init__(self,current_page,all_item):
all_page, c = divmod(len(all_item), 5) # 每五条数据一页,判断多少页
self.all_page=all_page if c > 0: # 有余数则多一页
all_page += 1 self.all_page = all_page#获取最大页面
try:
current_page=int(current_page)
except:
current_page=1 if current_page <1:
current_page =1 self.current_page = current_page @property
def strat(self):
return (self.current_page-1)*5 @property
def end(self):
return self.current_page * 5 def get_page(self,base_url):
self.all_page, c = divmod(len(List_Info), 5) # 每五条数据一页,判断多少页
if c > 0: # 有余数则多一页
self.all_page += 1 list_page = [] if self.current_page < 5:
for p in range(9):
if p + 1 == self.current_page:
temp = '<a class="active" href="%s %s">%s</a>' % (base_url,p + 1, p + 1)
else:
temp = '<a href="%s%s">%s</a>' % (base_url,p + 1, p + 1)
list_page.append(temp)
elif self.current_page > self.all_page - 5: # 判断页数是否在最前或者最后五页 for p in range(self.all_page - 9, self.all_page):
if p == self.current_page:
temp = '<a class="active" href="%s %s">%s</a>' % (base_url, p , p )
else:
temp = '<a href="%s%s">%s</a>' % (base_url, p, p )
list_page.append(temp)
else:
for p in range(self.current_page - 5, self.current_page + 4):
if p == self.current_page:
temp = '<a class="active" href="%s %s">%s</a>' % (base_url, p , p)
else:
temp = '<a href="%s%s">%s</a>' % (base_url, p , p )
list_page.append(temp)
str_page = ''.join(list_page)
return str_page
# str_page = list_page,不写join则会在页面上显示逗号 class IndexHandler(tornado.web.RequestHandler):
def get(self,page): page_obj =Pagination(page,List_Info)#把当前访问页以及要传给前端的数据传给类里面 current_ist =List_Info[page_obj.strat:page_obj.end]#以访问字段的方式访问方法,获取数据
str_page = page_obj.get_page('/index/')#底下的页数码 self.render('E:\\练习2\\tornado_day2\\views\\home\\index.html',list= current_ist,page=page_obj.current_page,str_page=str_page)
#page_obj.current_page表示把处理过的页数传进去
def post(self, page):
user = self.get_argument('username')
email = self.get_argument('email')
temp = {'username':user,'email':email}
List_Info.append(temp)
self.redirect('/index/'+page)
print(List_Info)
运行如图
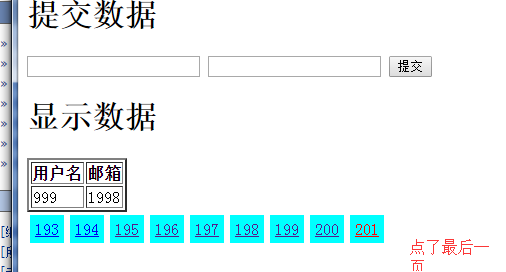
Python之tornado框架实现翻页功能的更多相关文章
- pyspider示例代码五:实现自动翻页功能
实现自动翻页功能 示例代码一 #!/usr/bin/env python # -*- encoding: utf- -*- # Created on -- :: # Project: v2ex fro ...
- [Qt] CFlip 翻页功能实现
由于需要给table制作翻页功能,所以写了一个翻页的类. 看上去总体效果感觉还是不错的,哈哈. //flip.h #ifndef CFLIP_H #define CFLIP_H #include &l ...
- jsp实现上一页下一页翻页功能
前段时间一直忙于期末考试和找实习,好久没写博客了. 这段时间做了个小项目,包含了翻页和富文本编辑器Ueditor的两个知识点,Ueditor玩的还不是很深,打算玩深后再写篇博客. 要实现翻页功能,只需 ...
- Web测试——翻页功能测试用例
参考:https://wenku.baidu.com/view/e6462707de80d4d8d15a4f1e.html?rec_flag=default&mark_pay_doc=2&am ...
- Atitit 翻页功能的解决方案与版本历史 v4 r49
Atitit 翻页功能的解决方案与版本历史 v4 r49 1. 版本历史与分支版本,项目版本记录1 1.1. 主干版本历史1 1.2. 分支版本 项目版本记录.1 2. Easyui 的翻页组件2 ...
- Atitit.pagging 翻页功能解决方案专题 与 目录大纲 v3 r44.docx
Atitit.pagging 翻页功能解决方案专题 与 目录大纲 v3 r44.docx 1.1. 翻页的重要意义1 1.2. Dep废弃文档 paip.js翻页分页pageing组件.txt1 ...
- PyQt—QTableWidget实现翻页功能
主要使用QTableWidget中的三个函数实现: verticalScrollBar().setSliderPosition() 设置当前滑动条的位置 verticalScrollBar().max ...
- jsp实现翻页功能
jsp实现翻页功能 要实现翻页功能,只需要设置一个pageIndex即可,然后每次加载页面时通过pageIndex去加载数据就行. 那么我们可以设置一个隐藏的input框,用于传递pageIndex给 ...
- jquery.Table实现的翻页功能比较完整漂亮,本想扩展个模版DIV
jquery.dataTable实现的翻页功能比较完整漂亮,本想提取其的翻页部分,再结合模版DIV,bootstrop实现聊天记息的展示. jquery.Table 与table结合的较紧,不能在很下 ...
随机推荐
- JavaWeb遗漏的知识点
1. String javax.servlet.ServletContext.getRealPath(String path)方法 官方文档解释:Gets the real path correspo ...
- Java虚拟机垃圾回收(三): 7种垃圾收集器(转载)
1.垃圾收集器概述 垃圾收集器是垃圾回收算法(标记-清除算法.复制算法.标记-整理算法.火车算法)的具体实现,不同商家.不同版本的JVM所提供的垃圾收集器可能会有很在差别,本文主要介绍HotSpot虚 ...
- 史上最简单的SpringCloud教程 | 第四篇:断路器(Hystrix)(Finchley版本)
转载请标明出处: 原文首发于:https://www.fangzhipeng.com/springcloud/2018/08/30/sc-f4-hystrix/ 本文出自方志朋的博客 在微服务架构中, ...
- 安装sass遇到的坑
一.安装Sass https://www.sass.hk/install/ 根据网站的步骤进行安装 Ruby版本的选择 我第一次下载是在Ruby官网上下的2.5.0版本得ruby.然而下载了之后无(不 ...
- kali linux (Raspberry Pi 3b) 更新失败 出现上面的问题
Invalid signature for Kali Linux repositories : “The following signatures were invalid: EXPKEYSIG ED ...
- let's encrypt部署免费泛域名证书
环境说明 [root@localhost ~]# cat /etc/redhat-release CentOS Linux release 7.5.1804 (Core) [root@localhos ...
- 利用nginx使ftp可以通过http访问
./nginx 启动服务./nginx -s stop 关闭服务./nginx -s reload 重新加载配置文件 搭建nginx映射ftp服务:打开nginx的配置文件nginx.conf(位于n ...
- 【c学习-14】
/*练习*/ #include int testFeiunction(b[],n){ b[1]=1; n=10; } int main(){ int a[10]={1,2,3,4,5}; int n= ...
- Excel学习路径总结
本片涉及从入门到Excel的各个方向,包含众多资料和自己学习的心得,希望您可以仔细阅之: 入门篇: 无论是软件,还是编程,最好的入门就是通过看视频来学习,视频优点为很容易看清楚,手把手教授,不容易 ...
- 【转】mysql索引最左匹配原则的理解
作者:沈杰 链接:https://www.zhihu.com/question/36996520/answer/93256153 来源:知乎 CREATE TABLE `student` ( `id` ...