机器学习之K-近邻(KNN)算法
一 . K-近邻算法(KNN)概述
最简单最初级的分类器是将全部的训练数据所对应的类别都记录下来,当测试对象的属性和某个训练对象的属性完全匹配时,便可以对其进行分类。但是怎么可能所有测试对象都会找到与之完全匹配的训练对象呢,其次就是存在一个测试对象同时与多个训练对象匹配,导致一个训练对象被分到了多个类的问题,基于这些问题呢,就产生了KNN。
KNN是通过测量不同特征值之间的距离进行分类。它的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别,其中K通常是不大于20的整数。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
下面通过一个简单的例子说明一下:如下图,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。
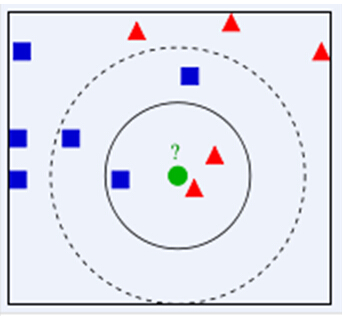
由此也说明了KNN算法的结果很大程度取决于K的选择。
在KNN中,通过计算对象间距离来作为各个对象之间的非相似性指标,避免了对象之间的匹配问题,在这里距离一般使用欧氏距离或曼哈顿距离:

同时,KNN通过依据k个对象中占优的类别进行决策,而不是单一的对象类别决策。这两点就是KNN算法的优势。
接下来对KNN算法的思想总结一下:就是在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对应的特征进行相互比较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类,其算法的描述为:
1)计算测试数据与各个训练数据之间的距离;
2)按照距离的递增关系进行排序;
3)选取距离最小的K个点;
4)确定前K个点所在类别的出现频率;
5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
二 .python实现
首先呢,需要说明的是我用的是python3.4.3,里面有一些用法与2.7还是有些出入。
建立一个KNN.py文件对算法的可行性进行验证,如下:
#coding:utf-8 from numpy import *
import operator ##给出训练数据以及对应的类别
def createDataSet():
group = array([[1.0,2.0],[1.2,0.1],[0.1,1.4],[0.3,3.5]])
labels = ['A','A','B','B']
return group,labels ###通过KNN进行分类
def classify(input,dataSe t,label,k):
dataSize = dataSet.shape[0]
####计算欧式距离
diff = tile(input,(dataSize,1)) - dataSet
sqdiff = diff ** 2
squareDist = sum(sqdiff,axis = 1)###行向量分别相加,从而得到新的一个行向量
dist = squareDist ** 0.5 ##对距离进行排序
sortedDistIndex = argsort(dist)##argsort()根据元素的值从大到小对元素进行排序,返回下标 classCount={}
for i in range(k):
voteLabel = label[sortedDistIndex[i]]
###对选取的K个样本所属的类别个数进行统计
classCount[voteLabel] = classCount.get(voteLabel,0) + 1
###选取出现的类别次数最多的类别
maxCount = 0
for key,value in classCount.items():
if value > maxCount:
maxCount = value
classes = key return classes
接下来,在命令行窗口或新建一个python文件输入如下代码:
#-*-coding:utf-8 -*-
import sys
sys.path.append("...文件路径...")
import KNN
from numpy import *
dataSet,labels = KNN.createDataSet()
input = array([1.1,0.3])
K = 3
output = KNN.classify(input,dataSet,labels,K)
print("测试数据为:",input,"分类结果为:",output)
回车之后的结果为:
测试数据为: [ 1.1 0.3] 分类为: A
答案符合我们的预期,要证明算法的准确性,势必还需要通过处理复杂问题进行验证,之后另行说明。
三 实战
之前,对KNN进行了一个简单的验证,今天我们使用KNN改进约会网站的效果,个人理解,这个问题也可以转化为其它的比如各个网站迎合客户的喜好所作出的推荐之类的,当然,今天的这个例子功能也实在有限。
在这里根据一个人收集的约会数据,根据主要的样本特征以及得到的分类,对一些未知类别的数据进行分类,大致就是这样。
我使用的是python 3.4.3,首先建立一个文件,例如date.py,具体的代码如下:
#coding:utf-8 from numpy import *
import operator
from collections import Counter
import matplotlib
import matplotlib.pyplot as plt ###导入特征数据
def file2matrix(filename):
fr = open(filename)
contain = fr.readlines()###读取文件的所有内容
count = len(contain)
returnMat = zeros((count,3))
classLabelVector = []
index = 0
for line in contain:
line = line.strip() ###截取所有的回车字符
listFromLine = line.split('\t')
returnMat[index,:] = listFromLine[0:3]###选取前三个元素,存储在特征矩阵中
classLabelVector.append(listFromLine[-1])###将列表的最后一列存储到向量classLabelVector中
index += 1 ##将列表的最后一列由字符串转化为数字,便于以后的计算
dictClassLabel = Counter(classLabelVector)
classLabel = []
kind = list(dictClassLabel)
for item in classLabelVector:
if item == kind[0]:
item = 1
elif item == kind[1]:
item = 2
else:
item = 3
classLabel.append(item)
return returnMat,classLabel#####将文本中的数据导入到列表 ##绘图(可以直观的表示出各特征对分类结果的影响程度)
datingDataMat,datingLabels = file2matrix('D:\python\Mechine learing in Action\KNN\datingTestSet.txt')
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(datingDataMat[:,0],datingDataMat[:,1],15.0*array(datingLabels),15.0*array(datingLabels))
plt.show() ## 归一化数据,保证特征等权重
def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))##建立与dataSet结构一样的矩阵
m = dataSet.shape[0]
for i in range(1,m):
normDataSet[i,:] = (dataSet[i,:] - minVals) / ranges
return normDataSet,ranges,minVals ##KNN算法
def classify(input,dataSet,label,k):
dataSize = dataSet.shape[0]
####计算欧式距离
diff = tile(input,(dataSize,1)) - dataSet
sqdiff = diff ** 2
squareDist = sum(sqdiff,axis = 1)###行向量分别相加,从而得到新的一个行向量
dist = squareDist ** 0.5 ##对距离进行排序
sortedDistIndex = argsort(dist)##argsort()根据元素的值从大到小对元素进行排序,返回下标 classCount={}
for i in range(k):
voteLabel = label[sortedDistIndex[i]]
###对选取的K个样本所属的类别个数进行统计
classCount[voteLabel] = classCount.get(voteLabel,0) + 1
###选取出现的类别次数最多的类别
maxCount = 0
for key,value in classCount.items():
if value > maxCount:
maxCount = value
classes = key
return classes ##测试(选取10%测试)
def datingTest():
rate = 0.10
datingDataMat,datingLabels = file2matrix('D:\python\Mechine learing in Action\KNN\datingTestSet.txt')
normMat,ranges,minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
testNum = int(m * rate)
errorCount = 0.0
for i in range(1,testNum):
classifyResult = classify(normMat[i,:],normMat[testNum:m,:],datingLabels[testNum:m],3)
print("分类后的结果为:,", classifyResult)
print("原结果为:",datingLabels[i])
if(classifyResult != datingLabels[i]):
errorCount += 1.0
print("误分率为:",(errorCount/float(testNum))) ###预测函数
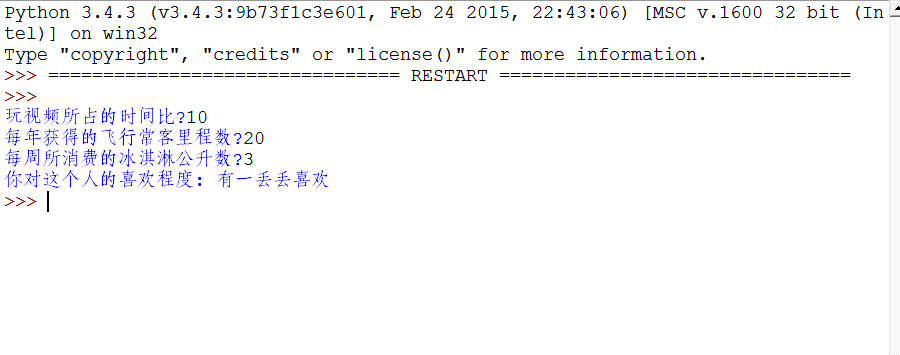
def classifyPerson():
resultList = ['一点也不喜欢','有一丢丢喜欢','灰常喜欢']
percentTats = float(input("玩视频所占的时间比?"))
miles = float(input("每年获得的飞行常客里程数?"))
iceCream = float(input("每周所消费的冰淇淋公升数?"))
datingDataMat,datingLabels = file2matrix('D:\python\Mechine learing in Action\KNN\datingTestSet2.txt')
normMat,ranges,minVals = autoNorm(datingDataMat)
inArr = array([miles,percentTats,iceCream])
classifierResult = classify((inArr-minVals)/ranges,normMat,datingLabels,3)
print("你对这个人的喜欢程度:",resultList[classifierResult - 1])
新建test.py文件了解程序的运行结果,代码:
#coding:utf-8 from numpy import *
import operator
from collections import Counter
import matplotlib
import matplotlib.pyplot as plt import sys
sys.path.append("D:\python\Mechine learing in Action\KNN")
import date
date.classifyPerson()
运行结果如下图:
机器学习之K-近邻(KNN)算法的更多相关文章
- 机器学习经典算法具体解释及Python实现--K近邻(KNN)算法
(一)KNN依旧是一种监督学习算法 KNN(K Nearest Neighbors,K近邻 )算法是机器学习全部算法中理论最简单.最好理解的.KNN是一种基于实例的学习,通过计算新数据与训练数据特征值 ...
- 机器学习-K近邻(KNN)算法详解
一.KNN算法描述 KNN(K Near Neighbor):找到k个最近的邻居,即每个样本都可以用它最接近的这k个邻居中所占数量最多的类别来代表.KNN算法属于有监督学习方式的分类算法,所谓K近 ...
- 机器学习之K近邻算法(KNN)
机器学习之K近邻算法(KNN) 标签: python 算法 KNN 机械学习 苛求真理的欲望让我想要了解算法的本质,于是我开始了机械学习的算法之旅 from numpy import * import ...
- 【机器学习】k近邻算法(kNN)
一.写在前面 本系列是对之前机器学习笔记的一个总结,这里只针对最基础的经典机器学习算法,对其本身的要点进行笔记总结,具体到算法的详细过程可以参见其他参考资料和书籍,这里顺便推荐一下Machine Le ...
- 机器学习之K近邻算法
K 近邻 (K-nearest neighbor, KNN) 算法直接作用于带标记的样本,属于有监督的算法.它的核心思想基本上就是 近朱者赤,近墨者黑. 它与其他分类算法最大的不同是,它是一种&quo ...
- 机器学习中 K近邻法(knn)与k-means的区别
简介 K近邻法(knn)是一种基本的分类与回归方法.k-means是一种简单而有效的聚类方法.虽然两者用途不同.解决的问题不同,但是在算法上有很多相似性,于是将二者放在一起,这样能够更好地对比二者的异 ...
- 机器学习实战-k近邻算法
写在开头,打算耐心啃完机器学习实战这本书,所用版本为2013年6月第1版 在P19页的实施kNN算法时,有很多地方不懂,遂仔细研究,记录如下: 字典按值进行排序 首先仔细读完kNN算法之后,了解其是用 ...
- TensorFlow实现knn(k近邻)算法
首先先介绍一下knn的基本原理: KNN是通过计算不同特征值之间的距离进行分类. 整体的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于 ...
- 【机器学习】K近邻算法——多分类问题
给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该类输入实例分为这个类. KNN是通过测量不同特征值之间的距离进行分类.它的的思路是:如 ...
- k近邻(KNN)复习总结
摘要: 1.算法概述 2.算法推导 3.算法特性及优缺点 4.注意事项 5.实现和具体例子 6.适用场合内容: 1.算法概述 K近邻算法是一种基本分类和回归方法:分类时,根据其K个最近邻的训练实例的类 ...
随机推荐
- 《从零开始学Swift》学习笔记(Day4)——用Playground工具编写Swift
Swift 2.0学习笔记(Day4)——用Playground工具编写Swift 原创文章,欢迎转载.转载请注明:关东升的博客 用Playground编写Swift代码目的是为了学习.测试算法.验证 ...
- NET Framework 4.5新特性 (一) 数据库的连接加密保护。
NET Framework 4.5 ado.net数据库连接支持使用SecureString内存流方式保密文本. 一旦使用这类操作,文本加密是私有不能共享的,并在不再需要时从计算机内存中删除. S ...
- SharePoint服务器端对象模型 之 对象模型概述(Part 1)
在一个传统的ASP.NET开发过程中,我们往往会把开发分为界面展现层.逻辑业务层和数据访问层这三个层面.作为一个应用开发平台,SharePoint是微软在直观的开发能力和自由的扩展能力之间,取到的一个 ...
- influxDB聚合类函数
1)count()函数 返回一个(field)字段中的非空值的数量. SELECT COUNT(<field_key>) FROM <measurement_name> [WH ...
- python——random模块
用法示例: import random # 1)随机小数 print(random.random()) # 获取大于0且小于1 之间的小数 random.random() print(random.u ...
- mysql用户授权以及权限收回
语法 GRANT privileges [(columns)] ON DATABASE.TABLE TO 'username'@'hostname' [IDENTIFIED BY [PASSWORD] ...
- python面试题(三)
1 一行代码实现9*9乘法表 print ("\n".join("\t".join(["%s*%s=%s" %(x,y,x*y) for y ...
- Linux中的环境变量配置文件及其作用
登录相关的配置文件: /etc/profile 范围:对所有用户生效 作用: a.定义USER变量 b.定义LOGNAME变量 c.定义MAIL变量 d.定义PATH变量 e.定义HOSTNAME变量 ...
- LATEX教程(二)
插入图片 \documentclass{article} \usepackage{graphicx} \usepackage{Ctex} \title{插入图片} \author{yif} \begi ...
- mysql-5.7.16-linux-glibc2.5-x86_64精简后的主从配置
1.创建复制账号,并授予复制权限CREATE USER 'fansik'@'10.%' IDENTIFIED BY 'fansik';GRANT REPLICATION SLAVE ON *.* TO ...