初学Hadoop之WordCount词频统计
1、WordCount源码
将源码文件WordCount.java放到Hadoop2.6.0文件夹中。
import java.io.IOException;
import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount { public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1);
private Text word = new Text(); public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
} public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
2、编译源码
$ bin/hadoop com.sun.tools.javac.Main WordCount.java #将WordCount.java编译成三个.class文件
$ jar cf wc.jar WordCount*.class #将三个.class文件打包成jar文件
3、运行
新建input文件夹,用于存放需要统计的文本。
cd /opt/hadoop-2.6.0
mkdir input
复制hadoop-2.6.0文件夹下的txt文件到input文件夹下。
cp *.txt /opt/hadoop-2.6.0/input
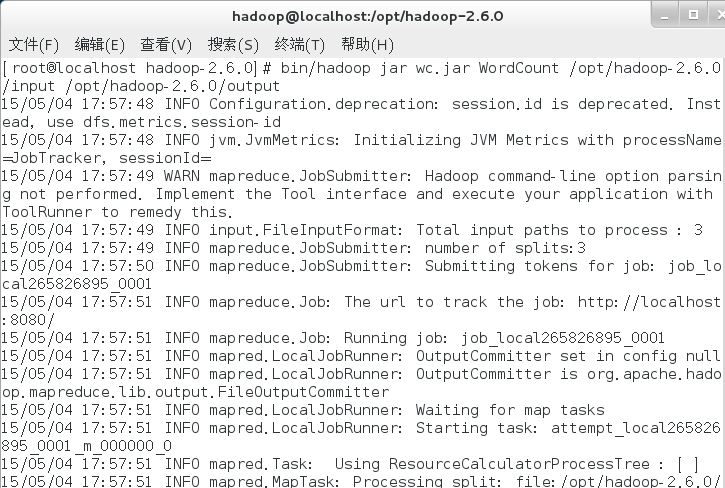
运行命令。
bin/hadoop jar wc.jar WordCount /opt/hadoop-2.6.0/input /opt/hadoop-2.6.0/output #自动生成output文件夹,用于存放分词统计结果。
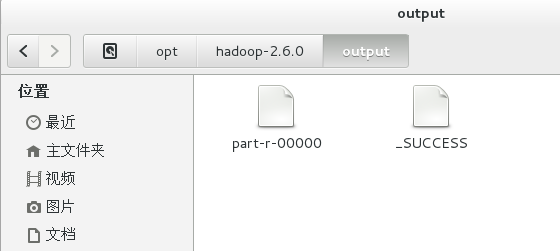
4、查看结果
bin/hdfs dfs -cat /opt/hadoop-2.6.0/output/part-r-00000
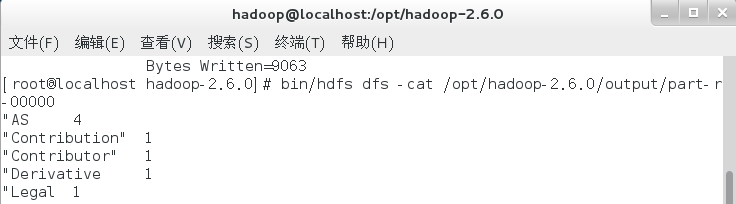
至此,WordCount词频统计运行成功,Hadoop单机模式环境搭建成功。
初学Hadoop之WordCount词频统计的更多相关文章
- 初学Hadoop之中文词频统计
1.安装eclipse 准备 eclipse-dsl-luna-SR2-linux-gtk-x86_64.tar.gz 安装 1.解压文件. 2.创建图标. ln -s /opt/eclipse/ec ...
- Hadoop基础学习(一)分析、编写并执行WordCount词频统计程序
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/jiq408694711/article/details/34181439 前面已经在我的Ubuntu ...
- 使用HDFS完成wordcount词频统计
任务需求 统计HDFS上文件的wordcount,并将统计结果输出到HDFS 功能拆解 读取HDFS文件 业务处理(词频统计) 缓存处理结果 将结果输出到HDFS 数据准备 事先往HDFS上传需要进行 ...
- Eclipse上运行第一个Hadoop实例 - WordCount(单词统计程序)
需求 计算出文件中每个单词的频数.要求输出结果按照单词的字母顺序进行排序.每个单词和其频数占一行,单词和频数之间有间隔. 比如,输入两个文件,其一内容如下: hello world hello had ...
- 第六篇:Eclipse上运行第一个Hadoop实例 - WordCount(单词统计程序)
需求 计算出文件中每个单词的频数.要求输出结果按照单词的字母顺序进行排序.每个单词和其频数占一行,单词和频数之间有间隔. 比如,输入两个文件,其一内容如下: hello world hello had ...
- Hadoop上的中文分词与词频统计实践 (有待学习 http://www.cnblogs.com/jiejue/archive/2012/12/16/2820788.html)
解决问题的方案 Hadoop上的中文分词与词频统计实践 首先来推荐相关材料:http://xiaoxia.org/2011/12/18/map-reduce-program-of-rmm-word-c ...
- Hadoop之词频统计小实验
声明: 1)本文由我原创撰写,转载时请注明出处,侵权必究. 2)本小实验工作环境为Ubuntu操作系统,hadoop1-2-1,jdk1.8.0. 3)统计词频工作在单节点的伪分布上,至于真正实 ...
- Hadoop的改进实验(中文分词词频统计及英文词频统计)(4/4)
声明: 1)本文由我bitpeach原创撰写,转载时请注明出处,侵权必究. 2)本小实验工作环境为Windows系统下的百度云(联网),和Ubuntu系统的hadoop1-2-1(自己提前配好).如不 ...
- 词频统计小程序-WordCount.exe
一. 背景 最近顶哥为了完成学历提升学业中的小作业,做了一个词频统计的.exe小程序.因为当时做的时候网上的比较少,因此顶哥决定把自己拙略的作品发出来给需要的人提供一种思路,希望各位看官不要dis ...
随机推荐
- 单链表倒数第K个节点的查找和显示
1.使用一个固定长度队列装链表段,当遍历到链表根时,返回队列头元素. class Node{ int value; Node next; public Node(int value){ this.va ...
- python—Celery异步分布式
python—Celery异步分布式 Celery 是一个python开发的异步分布式任务调度模块,是一个消息传输的中间件,可以理解为一个邮箱,每当应用程序调用celery的异步任务时,会向brok ...
- DRF 的解析器和渲染器
一.解析器 解析器作用 解析器的作用就是服务端接收客户端传过来的数据,把数据解析成自己可以处理的数据.本质就是对请求体中的数据进行解析. 在了解解析器之前,我们要先知道Accept以及ContentT ...
- redis源码分析(3)sds
sds是redis中用来处理字符串的数据结构.sds的定义在sds.h中: typedef char *sds; 简洁明了!简明扼要!(X,玩我呢是吧!这特么不就是c中的字符串么?!).像redis这 ...
- jq学习笔记(一)
1 .attr() 与 .removeAttr()方法 - atr()方法用来获取和设置元素属性 attr()有4个表达式: attr(传入属性名):获取属性的值 attr(属性名, 属性值):设置属 ...
- Linux硬件信息采集
dmidecode: 简介: dmidecode命令通过读取DMI数据库获取硬件信息并输出.由于DMI信息可以人为修改,因此里面的信息不一定是系统准确的信息 dmidecode遵循SMBIOS/DMI ...
- python怎样在一行中捕获多个异常
所属网站分类: python基础 > 异常处理 作者:浮沉 链接:http://www.pythonheidong.com/blog/article/71/ 来源:python黑洞网,专注pyt ...
- java 实现在线阅读 .pdf
1.资源的本地地址 2.设置响应头 3.代码实现 @ResponseBody @RequestMapping(value = "/read") @ApiOperation(valu ...
- let 和 var 的区别笔记
参考文章:阮一峰 ECMAScript 6 入门 ES6中新增加了 let 声明,它跟 var 的区别如下: 1.作用域不同,let 只在代码块中有效 { var a = '123'; le ...
- [转] Java @interface 自定义注解
[From] http://blog.csdn.net/afterlife_qiye/article/details/53748973 1. 注解的好处 注解可以替代配置文件完成对某些功能的描述,减少 ...