Spark架构解析(转)
Application:
Application是创建了SparkContext实例对象的Spark用户,包含了Driver程序,
Spark-shell是一个应用程序,因为spark-shell在启动的时候创建了一个SparkContext对象,其名称为sc,也就是说只要创建一个SparkContext就有对应的application,而一个action对应一个driver.相对应的transformation只产生元数据。
Job:
和action相对应,每一个action例如count、saveAsTextFile等都会对应一个job实例,该job实例包含多任务的并行计算。
Stage:
一个job会被拆分成很多任务,每一组任务被称为stage,这个MapReduce的map和reduce任务很像,划分stage的依据在于:stage开始一般是由于读取外部数据或者shuffle数据、一个stage的结束一般是由于发生shuffle(例如reduceByKey操作)或者整个job结束时,例如要把数据放到hdfs等存储系统上
Driver Program:
运行main函数并且创建SparkContext实例的程序
Cluster Manager:
在集群上获取资源的外部服务 (如:standalone,Mesos,yarn)。集群资源的管理外部服务,在spark上现在有standalone、yarn、mesos等三种集群资源管理器,spark自带的standalone模式能够满足大部分的spark计算环境对集群资源管理的需求,基本上只有在集群中运行多套计算框架的时候才考虑yarn和mesos
Worker Node:
集群中可以运行应用代码的工作节点,相当于Hadoop的slave节点
Executor:
在一个Worker Node上为应用启动的工作进程,在进程中赋值任务的运行,并且负责将数据存放在内存或磁盘上,必须注意的是,每个应用在一个Worker Node上只会有一个Executor,在Executor内部通过多线程的方式并发处理应用的任务。每个应用对应独立的executor.运行在不同的jvm.
Task:
被Driver送到Executor上的工作单元,通常情况下一个task会处理一个split的数据,每个split一般就是一个Block块的大小。split即内存槽
stage:
一个job会被拆分成多组任务,每组任务叫做stage(就像mapreduce分为map任务和reduce任务)。一般stage起始于从外部读数据,结束于shuffle阶段,或任务结束。
spark架构
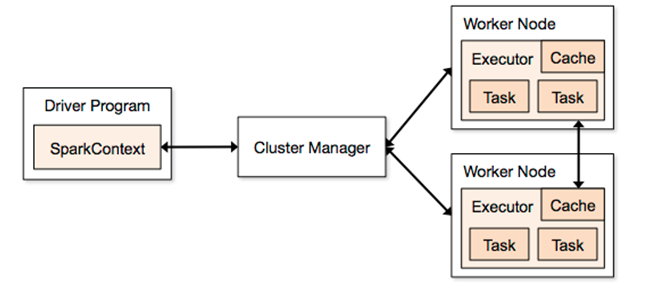
任何Spark的进程都是一个JVM进程,既然是一个JVM进程,那么就可以配置它的堆大小(-Xmx和-Xms),但是进程怎么使用堆内存和为什么需要它呢?下面是一个JVM堆空间下Spark的内存分配情况 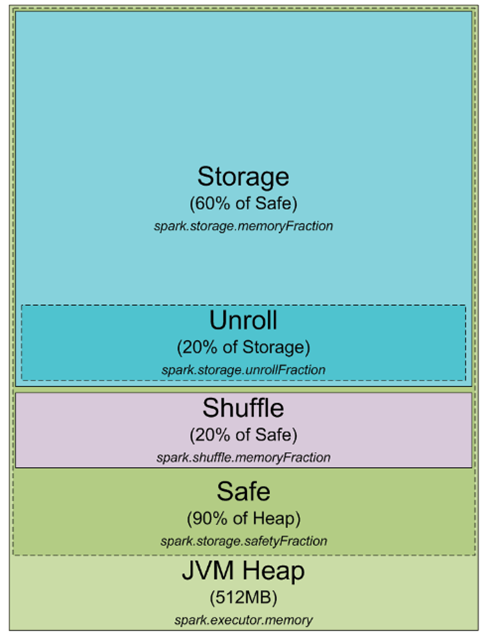
默认情况下,Spark进程的堆空间是512mb,为了安全考虑同时避免OOM,Spark只允许利用90%的堆空间,spark中使用spark.storage.safetyFraction用来配置该值(默认是0.9). Spark作为一个内存计算工具,Spark可以在内存中存储数据,它只是把内存作为他的LRU缓存,这样大量的内存被用来缓存正在计算的数据,该部分占safe堆的60%,Spark使用spark.storage.memoryFraction控制该值,如果想知道Spark中能缓存了多少数据,可以统计所有Executor的堆大小,乘上safeFraction和memoryFraction,默认是54%,这就是Spark可用缓存数据使用的堆大小。
该部分介绍shuffle的内存使用情况,它通过 堆大小 * spark.shuffle.safetyFraction * spark.shuffle.memoryFraction。 spark.shuffle.safetyFraction的默认值是0.8, spark.shuffle.memoryFraction的默认值是0.2,所以最终只能最多使堆空间的16%用于shuffle。,但是通常spark会使用这块内存用于shuffle中一些别的任务,当执行shuffle时,有时对数据进行排序,当进行排序时,需要缓冲排完序后的数据(注意不能改变LRU缓冲中的数据,因为后面可能要重用),这样就需要大量的RAM存储排完序后的数据块,当没有足够的内存用于排序,参考外排的实现,可以一块一块的排序,然后最终合并。
最后要讲到的一块内存是”unroll”,该快内存用于unroll计算如下:spark.storage.unrollFraction * spark.storage.memoryFraction * spark.storage.safetyFraction 。当我们需要在内存展开数据块的时候使用,那么为什么需要展开呢?因为spark允许以序列化和非序列化两种方式存储数据,序列化后的数据无法直接使用,所以使用时必须要展开。该部分内存占用缓存的内存,所以如果需要内存用于展开数据时,如果这个时候内存不够,那么Spark LRU缓存中的数据会删除一些快。
此时应该清楚知道spark怎么使用JVM中堆内存了,现在切换到集群模式,当你启动一个spark集群,如何看待它,下图是YARN模式下的 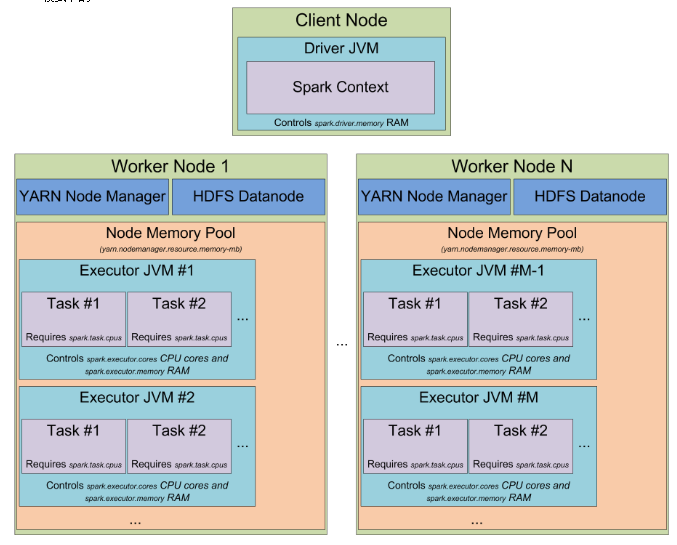
当运行在yarn集群上时,Yarn的ResourceMananger用来管理集群资源,集群上每个节点上的NodeManager用来管控所在节点的资源,从yarn的角度来看,每个节点看做可分配的资源池,当向ResourceManager请求资源时,它返回一些NodeManager信息,这些NodeManager将会提供execution container给你,每个execution container就是满足请求的堆大小的JVM进程,JVM进程的位置是由ResourceMananger管理的,不能自己控制,如果一个节点有64GB的内存被yarn管理(通过yarn.nodemanager.resource.memory-mb配置),当请求10个4G内存的executors时,这些executors可能运行在同一个节点上。
当在yarn上启动spark集群上,可以指定executors的数量(-num-executors或者spark.executor.instances),可以指定每个executor使用的内存(-executor-memory或者spark.executor.memory),可以指定每个executor使用的cpu核数(-executor-cores或者spark.executor.cores),指定每个task执行使用的core数(spark.task.cpus),也可以指定driver应用使用的内存(-driver-memory和spark.driver.memory)
当在集群上执行应用时,job会被切分成stages,每个stage切分成task,每个task单独调度,可以把executor的jvm进程看做task执行池,每个executor有 spark.executor.cores / spark.task.cpus execution 个执行槽,这里有个例子:集群有12个节点运行Yarn的NodeManager,每个节点有64G内存和32的cpu核,每个节点可以启动2个executor,每个executor的使用26G内存,剩下的内用系统和别的服务使用,每个executor有12个cpu核用于执行task,这样整个集群有12 machines * 2 executors per machine * 12 cores per executor / 1 core = 288 个task执行槽,这意味着spark集群可以同时跑288个task,整个集群用户缓存数据的内存有0.9 spark.storage.safetyFraction * 0.6 spark.storage.memoryFraction * 12 machines * 2 executors per machine * 26 GB per executor = 336.96 GB.
到目前为止,我们已经了解了spark怎么使用JVM的内存以及集群上执行槽是什么,目前为止还没有谈到task的一些细节,这将在另一个文章中提高,基本上就是spark的一个工作单元,作为exector的jvm进程中的一个线程执行,这也是为什么spark的job启动时间快的原因,在jvm中启动一个线程比启动一个单独的jvm进程块(在hadoop中执行mapreduce应用会启动多个jvm进程)
下面将关注spark的另一个抽象:partition, spark处理的所有数据都会切分成partion,一个parition是什么以及怎么确定,partition的大小完全依赖数据源,spark中大部分用于读取数据的方法都可以指定生成的RDD中partition的个数,当从hdfs上读取一个文件时,会使用Hadoop的InputFormat来处理,默认情况下InputFormat返回每个InputSplit都会映射RDD中的一个Partition,大部分存储在HDFS上的文件每个数据块会生成一个InputSplit,每个数据块大小为64mb和128mb,因为HDFS上面的数据的块边界是按字节来算的(64mb一个块),但是当数据被处理是,它又要按记录进行切分,对于文本文件来说切分的字符就是换行符,对于sequence文件来说,他是块结束,如果是压缩文件,整个文件都被压缩了,它不能按行进行切分了,整个文件只有一个inputsplit,这样spark中也会只有一个parition,在处理的时候需要手动的repatition。
Spark架构与作业执行流程简介
Client:客户端进程,负责提交作业到Master。
Master:Standalone模式中主控节点,负责接收Client提交的作业,管理Worker,并命令Worker启动Driver和Executor。
Worker:Standalone模式中slave节点上 的 守护进程 ,负责管理本节点的资源,定期向 Master汇报心跳,接收Master的命令,启动Driver和Executor
Driver: 一个Spark作业运行时包括一个Driver进程,也是作业的主进程,负责作业的解析、生成Stage并调度Task到Executor上。包括DAGScheduler,TaskScheduler。
Executor:即真正执行作业的地方,一个集群一般包含多个Executor,每个Executor接收Driver的命令Launch Task,一个Executor可以执行一到多个Task。
Stage:一个Spark作业一般包含一到多个Stage。
Task:一个Stage包含一到多个Task,通过多个Task实现并行运行的功能
DAGScheduler: 实现将Spark作业分解成一到多个Stage,每个Stage根据RDD的Partition个数决定Task的个数,然后生成相应的Task set放到TaskScheduler中。
TaskScheduler:实现Task分配到Executor上执行。
提交作业有两种方式,分别是Driver(作业的master,负责作业的解析、生成stage并调度task到,包含DAGScheduler)运行在Worker上,Driver运行在客户端。接下来分别介绍两种方式的作业运行原理。
Driver运行在Worker上
通过org.apache.spark.deploy.Client类执行作业,作业运行命令如下:
./bin/spark-class org.apache.spark.deploy.Client launch spark://host:port file:///jar_url org.apache.spark.examples.SparkPi spark://host:port- 1
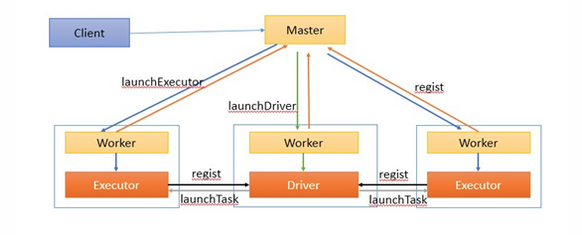
作业执行流程描述:
1、客户端提交作业给Master
2、Master让一个Worker启动Driver,即SchedulerBackend。Worker创建一个DriverRunner线程,DriverRunner启动SchedulerBackend进程。
3、另外Master还会让其余Worker启动Exeuctor,即ExecutorBackend。Worker创建一个ExecutorRunner线程,ExecutorRunner会启动ExecutorBackend进程。
4、ExecutorBackend启动后会向Driver的SchedulerBackend注册。SchedulerBackend进程中包含DAGScheduler,它会根据用户程序,生成执行计划,并调度执行。对于每个stage的task,都会被存放到TaskScheduler中,ExecutorBackend向SchedulerBackend汇报的时候把TaskScheduler中的task调度到ExecutorBackend执行。
5、所有stage都完成后作业结束。
Driver运行在客户端
./bin/run-example org.apache.spark.examples.SparkPi spark://host:port- 1
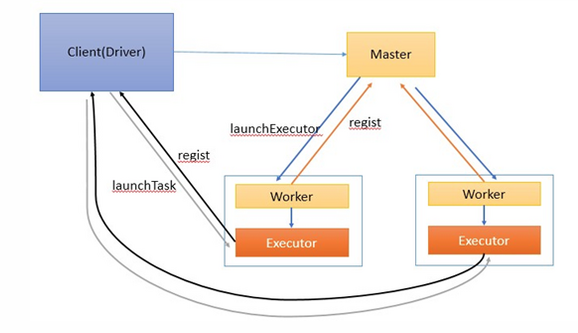
1、客户端启动后直接运行用户程序,启动Driver相关的工作:DAGScheduler和BlockManagerMaster等。
2、客户端的Driver向Master注册。
3、Master还会让Worker启动Exeuctor。Worker创建一个ExecutorRunner线程,ExecutorRunner会启动ExecutorBackend进程。
4、ExecutorBackend启动后会向Driver的SchedulerBackend注册。Driver的DAGScheduler解析作业并生成相应的Stage,每个Stage包含的Task通过TaskScheduler分配给Executor执行。
5、所有stage都完成后作业结束。
基于Yarn的Spark架构与作业执行流程
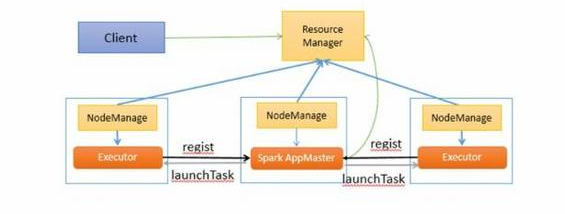
这里Spark AppMaster相当于Standalone模式下的SchedulerBackend,Executor相当于standalone的ExecutorBackend,spark AppMaster中包括DAGScheduler和YarnClusterScheduler。
refrences:
http://www.tuicool.com/articles/qaEVFb
http://www.cnblogs.com/gaoxing/p/5041806.html
http://blog.csdn.net/stark_summer/article/details/42833609
Spark架构解析(转)的更多相关文章
- Spark MLlib架构解析(含分类算法、回归算法、聚类算法和协同过滤)
Spark MLlib架构解析 MLlib的底层基础解析 MLlib的算法库分析 分类算法 回归算法 聚类算法 协同过滤 MLlib的实用程序分析 从架构图可以看出MLlib主要包含三个部分: 底层基 ...
- 从spark架构中透视job
本博文的主要内容如下: 1.通过案例观察Spark架构 2.手动绘制Spark内部架构 3.Spark Job的逻辑视图解析 4.Spark Job的物理视图解析 1.通过案例观察Spark架构 sp ...
- 【大数据】Spark内核解析
1. Spark 内核概述 Spark内核泛指Spark的核心运行机制,包括Spark核心组件的运行机制.Spark任务调度机制.Spark内存管理机制.Spark核心功能的运行原理等,熟练掌握Spa ...
- Spark 概念学习系列之从spark架构中透视job(十六)
本博文的主要内容如下: 1.通过案例观察Spark架构 2.手动绘制Spark内部架构 3.Spark Job的逻辑视图解析 4.Spark Job的物理视图解析 1.通过案例观察Spark架构 s ...
- 【Spark 内核】 Spark 内核解析-上
Spark内核泛指Spark的核心运行机制,包括Spark核心组件的运行机制.Spark任务调度机制.Spark内存管理机制.Spark核心功能的运行原理等,熟练掌握Spark内核原理,能够帮助我们更 ...
- 【Spark 内核】 Spark 内核解析-下
Spark内核泛指Spark的核心运行机制,包括Spark核心组件的运行机制.Spark任务调度机制.Spark内存管理机制.Spark核心功能的运行原理等,熟练掌握Spark内核原理,能够帮助我们更 ...
- Spark内核解析
Spark内核概述 Spark内核泛指Spark的核心运行机制,包括Spark核心组件的运行机制.Spark任务调度机制.Spark内存管理机制.Spark核心功能的运行原理等,熟练掌握Spark内核 ...
- HDFS 架构解析
本文以 Hadoop 提供的分布式文件系统(HDFS)为例来进一步展开解析分布式存储服务架构设计的要点. 架构目标 任何一种软件框架或服务都是为了解决特定问题而产生的.还记得我们在 <分布式存储 ...
- Spark 架构
本文转之Pivotal的一个工程师的博客.觉得极好. 作者本人经常在StackOverflow上回答一个关系Spark架构的问题,发现整个互联网都没有一篇文章能对Spark总体架构进行很好的描述, ...
随机推荐
- Atitit.得到网络邻居列表java php c#.net python
Atitit.得到网络邻居列表java php c#.net python 1. 获取workgroup net view /domain1 2. 得到网络邻居列表1 3. 得到机器的ip 通过p ...
- I2S与pcm的区别
I2S仅仅是PCM的一个分支,接口定义都是一样的, I2S的采样频率一般为44.1KHZ和48KHZ做,PCM采样频率一般为8K,16K.有四组信号: 位时钟信号,同步信号,数据输入,数据输出. I2 ...
- 李洪强iOS开发之OC[004] - OC和C的差异的学习
- IOS设计模式的六大设计原则之接口隔离原则(ISP,Interface Segregation Principle)
定义 客户端不应该依赖它不需要的接口: 一个类对另一个类的依赖应该建立在最小的接口上. 定义解读 定义包含三层含义: 一个类对另一个类的依赖应该建立在最小的接口上: 一个接口代表一个角色,不应该将不同 ...
- linux IP动态变动之后 , 需要做的杂项操作
linux的动态ip经常变来变去,目前还没找到固定它不变化的方法.所以每次变动之后都需要做以下的操作,极其麻烦.(必须找到让linux IP 固定的方法) 1.先找到变化之后的动态ip地址 ifcon ...
- CMake 简介与使用
cross platform make的缩写. 是一个比make更高级的编译配置工具,它可以根据不同平台.不同的编译器,生成相应的Makefile或者vcproj项目文件.通过编写CMakeLists ...
- linux 个人测试用例
1. 我想在某个目录下, 找到某个文件中有某个字符(leon)的文件, 并列出来? (如果是在windows下, 可能需要一个文件一个文件的看, 但是在 linux 下可以实现) find . –ma ...
- Android startActivity()和onActivityResult()使用总结(转载)
有三个Activity: A.java ,B.java ,C.java Activity之间的跳转常用方法: 1. startActivity(Intent intent); 该方法只用于启动新的Ac ...
- Servlet 表单数据
很多情况下,需要传递一些信息,从浏览器到 Web 服务器,最终到后台程序.浏览器使用两种方法可将这些信息传递到 Web 服务器,分别为 GET 方法和 POST 方法. GET 方法 GET 方法向页 ...
- 005 android jni 一个简单的报错
在android中使用ndk开发需要使用到jni. 1. java.lang.UnsatisfiedLinkError: No implementation found for void com.fr ...