5 Logistic回归(二)
5.2.4 训练算法:随机梯度上升
梯度上升算法:在每次更新回归系数时都需要遍历整个数据集,在数十亿样本上该算法复杂度太高。
改进方法:随机梯度上升算法:一次仅用一个样本点更新回归系数。
由于可以在新样本到来时对分类器进行增量式更新,因此随机梯度上升算法是一个在线学习算法。与“在线学习”相对应,一次处理所有数据被称作“批处理”。
#5-3:随机梯度上升算法
def stocGradAscent0(dataMatrix, classLabels):
m, n = shape(dataMatrix)
alpha = 0.01
weights = ones(n)
for i in range(m):
h = sigmoid(sum(dataMatrix[i] * weights))
error = classLabels[i] - h
weights = weights + alpha * error * dataMatrix[i]
return weights
随机梯度上升与梯度上升的区别:1.前者变量h和error都是数值,后者都是向量;2.前者没有矩阵转换过程,所有变量数据类型都是Numpy数组。


拟合效果没有梯度上升算法完美。这里的分类器错分了三分之一的样本。梯度上升算法的结果是在整个数据集上迭代了500次才得到的。
判断优化算法优劣的可靠方法:看它是否收敛,也就是说参数是否达到稳定值,是否不断地变化。
对此,在程序5-3中随机梯度上升做些修改,使其在整个数据集上运行200次。最终绘制的三个回归系数变化情况如下图:

图5-6
X2经过50次迭代达到稳定值,但X0和X1需要更多次迭代。产生这种现象原因:存在一些不能正确分类的样本点(数据集并非线性可分),在每次迭代时会引发系数的剧烈改变。我们希望算法能避免来回波动,从而收敛到某个值。另外,收敛速度也需要加快。
#5-4:改进的随机梯度上升算法
def stocGradAscent1(dataMatrix, classLabels, numIter = 150):
m, n = shape(dataMatrix)
weights = ones(n)
for j in range(numIter):#j迭代次数
dataIndex = range(m)
for i in range(m):#i样本点下标
alpha = 4/(1.0 + j + i) + 0.01#alpha每次迭代时需要调整
randIndex = int(random.uniform(0, len(dataIndex)))#randIndex编号:样本在矩阵中的位置
h = sigmoid(sum(dataMatrix[randIndex] * weights))
error = classLabels[randIndex] - h
weights = weights + alpha * error * dataMatrix[randIndex]
del(dataIndex[randIndex])
return weights
改进之处:1.alpha每次迭代时需要调整,缓解上图数据波动或者高频波动。虽然alpha随迭代次数不断减小,但永远不会小于0,因为存在常数项(0.01)。这样做的原因:保证多次迭代后新数据仍有一定的影响。alpha每次减少1/(j+i),j是迭代次数,i是样本点下标。当j<<max(i),alpha就不是严格下降。2.通过随机选取样本更新回归系数,减少周期性波动。具体实现方法与第3章类似,每次随机从列表中选出一个值,然后从列表中删掉该值(再进行下一次迭代)。

图5-7
该方法比采用固定的alpha收敛速度更快。主要归功于:1.stocGradAscent1()的样本随机机制避免周期性波动;2.stocGradAscent1()收敛更快。这次仅对数据集做了20次遍历,而之前的方法是500次。
5.3 示例:从疝气病症预测病马的死亡率
(1)收集数据
(2)准备数据
(3)分析数据
(4)训练算法:使用优化算法,找到最佳系数
(5)测试算法:为了量化回归的效果,需要观察错误率。根据错误率决定是否退到训练阶段,通过改变迭代次数和步长等参数得到更好的回归系数。
(6)使用算法
5.3.1 准备数据:处理数据中的缺失值
预处理需要做2件事:
1.缺失值必须用一个实数值来替换,因为Numpy类型不允许包含缺失值。这里选择0替换所有缺失值,恰好适用于Logistic回归。这样做原因:需要一个在更新时不会影响系数的值。
2.如果数据集中类别标签已缺失,则丢弃该数据。
5.3.2 测试算法:用Logistic回归进行分类
使用Logistic回归需要做的事情:将测试集上每个特征向量乘以最优化方法得来的回归系数,再将该乘积结果求和,最后输入到Sigmoid函数中。如果对应的Sigmoid值大于0.5则预测类别标签为1,否则为0.
#5-5:Logistic回归分类函数
def classifyVector(inX, weights):#(特征向量,回归系数)
prob = sigmoid(sum(inX * weights))
if prob > 0.5: return 1.0
else: return 0.0 def colicTest():#打开测试集、训练集
frTrain = open('horseColicTraining.txt')
frTest = open('horseColicTest.txt')
trainingSet = []; trainingLabels = []
for line in frTrain.readlines():
currLine = line.strip().split('\t')
lineArr = []
for i in range(21):#0-20:20个特征,1个类标签
lineArr.append(float(currLine[i]))
trainingSet.append(lineArr)
trainingLabels.append(float(currLine[21]))
trainWeights = stocGradAscent1(array(trainingSet), trainingLabels, 500)#计算回归系数 errorCount = 0; numTestVec = 0.0
for line in frTest.readlines():#导入测试集,计算分类错误率
numTestVec += 1.0
currLine = line.strip().split('\t')
lineArr = []
for i in range(21):
lineArr.append(float(currLine[i]))
if int(classifyVector(array(lineArr), trainWeights)) != int(currLine[21]):
errorCount += 1
errorRate = float(errorCount) / numTestVec
print "the error rate of this test is: %f" % errorRate
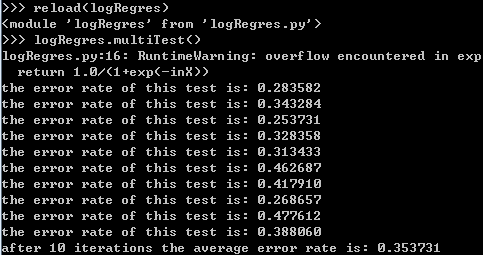
return errorRate def multiTest():#调用colicTest()10次求平均值
numTests = 10; errorSum = 0.0
for k in range(numTests):
errorSum += colicTest()
print "after %d iterations the average error rate is: %f" % (numTests, errorSum/float(numTests))
5.4 总结
Logistic回归的目的是寻找一个非线性函数sigmoid的最佳拟合参数,求解过程可以由最优化算法来完成。在最优化算法中,最常用的就是梯度上升算法,而梯度上升算法又可以简化为随机梯度上升算法。
随机梯度上升算法和梯度上升算法的效果相当,但占用更少的计算资源。此外,随机梯度是一种在线算法,可以在数据到来时就完成参数的更新,而不需要重新读取整个数据集来进行批处理运算。
5 Logistic回归(二)的更多相关文章
- Logistic回归二分类Winner or Losser----台大李宏毅机器学习作业二(HW2)
一.作业说明 给定训练集spam_train.csv,要求根据每个ID各种属性值来判断该ID对应角色是Winner还是Losser(0.1分类). 训练集介绍: (1)CSV文件,大小为4000行X5 ...
- 机器学习 —— 基础整理(五)线性回归;二项Logistic回归;Softmax回归及其梯度推导;广义线性模型
本文简单整理了以下内容: (一)线性回归 (二)二分类:二项Logistic回归 (三)多分类:Softmax回归 (四)广义线性模型 闲话:二项Logistic回归是我去年入门机器学习时学的第一个模 ...
- Logistic回归Cost函数和J(θ)的推导(二)----梯度下降算法求解最小值
前言 在上一篇随笔里,我们讲了Logistic回归cost函数的推导过程.接下来的算法求解使用如下的cost函数形式: 简单回顾一下几个变量的含义: 表1 cost函数解释 x(i) 每个样本数据点在 ...
- 吴恩达机器学习笔记(二) —— Logistic回归
主要内容: 一.回归与分类 二.Logistic模型即sigmoid function 三.decision boundary 决策边界 四.cost function 代价函数 五.梯度下降 六.自 ...
- 二分类Logistic回归模型
Logistic回归属于概率型的非线性回归,分为二分类和多分类的回归模型.这里只讲二分类. 对于二分类的Logistic回归,因变量y只有“是.否”两个取值,记为1和0.这种值为0/1的二值品质型变量 ...
- SPSS数据分析—二分类Logistic回归模型
对于分类变量,我们知道通常使用卡方检验,但卡方检验仅能分析因素的作用,无法继续分析其作用大小和方向,并且当因素水平过多时,单元格被划分的越来越细,频数有可能为0,导致结果不准确,最重要的是卡方检验不能 ...
- matlab-逻辑回归二分类(Logistic Regression)
逻辑回归二分类 今天尝试写了一下逻辑回归分类,把代码分享给大家,至于原理的的话请戳这里 https://blog.csdn.net/laobai1015/article/details/7811321 ...
- logistic回归具体解释(二):损失函数(cost function)具体解释
有监督学习 机器学习分为有监督学习,无监督学习,半监督学习.强化学习.对于逻辑回归来说,就是一种典型的有监督学习. 既然是有监督学习,训练集自然能够用例如以下方式表述: {(x1,y1),(x2,y2 ...
- logistic回归
logistic回归 回归就是对已知公式的未知参数进行估计.比如已知公式是$y = a*x + b$,未知参数是a和b,利用多真实的(x,y)训练数据对a和b的取值去自动估计.估计的方法是在给定训练样 ...
随机推荐
- <转>Java的一些历史
Java是一种固执己见的语言,它具有很好的可读性,初级程序员很容易上手,具有长期稳定性和可支持性.但这些设计决定也付出了一定的代价:冗长的代码,类型系统与其它语言相比显得缺乏弹性. 然而,Java ...
- Metafunction
Metafunction is a more general idiom than type generator. Metafunctions that produce type(s) as a re ...
- aspnetpager分页,不使用存储过程
一.前台显示界面代码Default.aspx(注意,代码运行环境是VS.2005) <%@ Page Language="C#" AutoEventWireup=" ...
- Android 自定义shape圆形按钮
Shape的属性: solid 描述:内部填充 属性:android:color 填充颜色 size 描述:大小 属性: android:width 宽 android:height 高 gradie ...
- UML--用例图
一.UML概述 1.UML的作用:a 把复杂的问题分解 b 实现了可视化 UML是由Rational公司创建的 2.UML是什么:是一种语言,有属于自己的标准表达规则,是一种分析设计语言, ...
- Oracle EBS-SQL (PO-2):检查当月到货补单的记录数.sql
SELECT DECODE(PLLA.FROM_LINE_ID,'-1','手工','','自动创建') 下达方式, rsh.receipt_num ...
- yum 安装 5.6
http://www.cnblogs.com/XBlack/p/5178758.html
- chroot_local_user和chroot_list_enable含义
很多情况下,我们希望限制ftp用户只能在其主目录下(root dir)下活动,不允许他们跳出主目录之外浏览服务器上 的其他目录,这时候我就需要使用到chroot_local_user,chroot_l ...
- O2O领域添新军,正品网加快布局的战略考量
前不久.正品网採购虚拟运营商30万170号码的招标公告引发了业界的广泛关注.一方面,虚拟运营商正处于"徘徊不定"的十字路口.据业内知情人士透露,眼下12家虚拟运营商企业共放号在20 ...
- ruby中输入命令行编译sass(ruby小白)
Ruby(或cmd中)输入命令行编译sass步骤如下: (1)举例而言:首先在F盘下建立一个总文件夹,比如test文件夹:其次在该文件夹下建立html,images,js,sass等文件夹. (2)在 ...