Flink资料(5) -- Job和调度
该文档翻译自Jobs and Scheduling
-----------------------------------------------
该文档简单描述了Flink是如何调度Job的,以及如何在JobManager上表现并跟踪Job状态。
一、调度
Flink通过任务槽(Task Slot)定义执行资源。每个TaskManager都有一或多个任务槽,每个任务槽都可以运行一个流水线并行任务。一个流水线包括多个连续的任务,如一个MapFunction的第n个并行实例与一个ReduceFunction的第n个并行实例的连续任务。注意,Flink通常会并发执行连续的任务,对于流数据程序来说,任何情况都如此执行;而对批处理程序,多数情况也如此执行。
图1中是具有一个数据源、一个MapFunction和一个ReduceFunction的程序。数据源和MapFunction的执行并发度都为4,而ReduceFunction的执行并发度为3。在图1中,程序以Source-Map-Reduce的执行顺序,在具有2个TaskManager的集群上运行,每个TaskManager都有3个任务槽,则程序执行情况图所述。
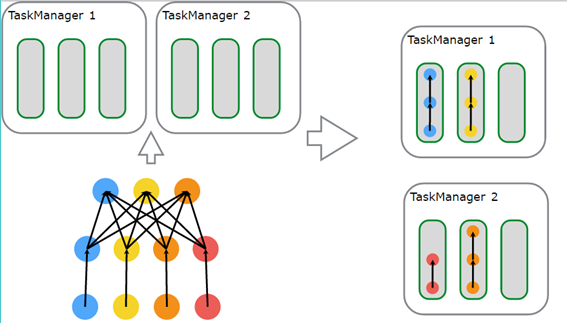
图1Flink并发运行和SlotSharing
Flink内通过SlotSharingGroup和CoLocationGroup来定义任务在共享任务槽的行为,可定义自由共享,或是严格定义某些任务部署到同一个任务槽中。
二、JobManager数据结构
在Job执行期间,JobManager将持续耿总分布式任务的执行,来决定什么时候调度下一个/下一批问题,并且对完成的或失败的任务进行响应。
JobManager接收JobGraph,JobGraph是数据流的表现形式,包括Operator(JobVertex)和中间结果(intermediateDataSet)。每个Operator都有诸如并行度和执行代码等属性。此外,JobGraph拥有一些附加的库,这些库都是在Operator执行代码时所需要的。
JobManager将JobGraph转换为ExecutionGraph。ExecutionGraph是JobGraph的并行版本:对每个JobVertex,它针对每个并行子任务都有一个ExecutionVertex。一个并行度为100的Operator将拥有一个JobVertex和100个ExecutionVertex。ExecutionVertex会跟踪其特定子任务的执行状态。来自一个JobVertex的所有ExecutionVertex都由一个ExecutionJobVertex管理,ExecutionJobVertex跟踪Operator总体的状态。除了这些节点之外,ExecutionGraph同样包括了IntermediateResult和IntermediateResultPartition,前者跟踪IntermediateDataSet的状态,后者跟踪每个它的partition的状态。
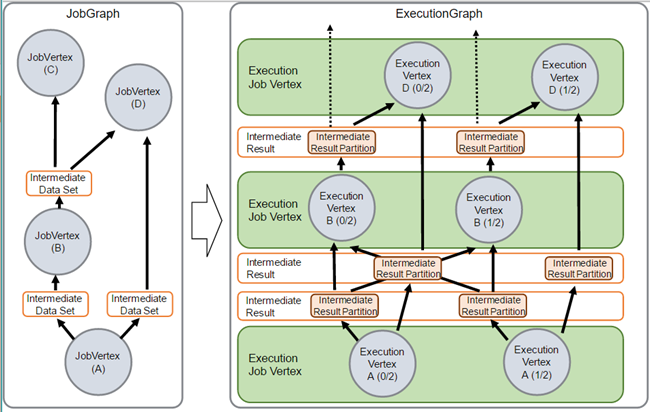
图2
JobGraph(Vertex) - ExecutionGraph(Vertex)
在程序执行期间,每个并行任务要经过多个阶段,从created到finished或failed。图3为各个状态以及它们之间可能的转换。一个任务可能被多次执行(如在失效恢复的过程中),所以我们以一个Exection跟踪一个ExecutionVertex。每个ExecutionVertex都有一个当前Execution(current execution)和一个前驱Execution(prior execution)。
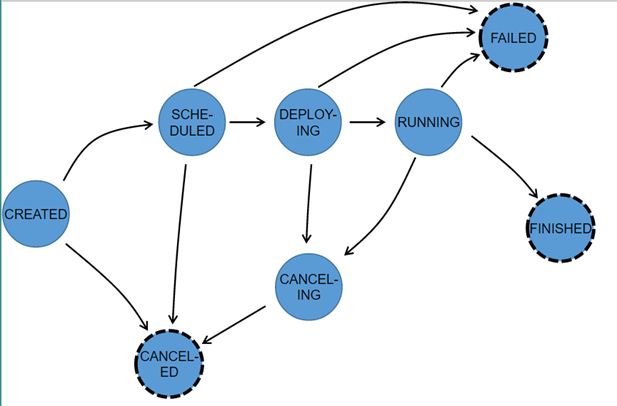
图3 执行阶段及跳转
Flink资料(5) -- Job和调度的更多相关文章
- Flink资料(1)-- Flink基础概念(Basic Concept)
Flink基础概念 本文描述Flink的基础概念,翻译自https://ci.apache.org/projects/flink/flink-docs-release-1.0/concepts/con ...
- Flink资料(8) -- Flink代码贡献的指导及准则
本文翻译自Contributing Code ----------------------------------------- Apache Flink是由自愿的代码贡献者维护.优化及扩展的.Apa ...
- Flink资料(7) -- 背压监控
背压(backpressure)监控 本文翻译自Back Pressure Monitoring --------------------------------------------------- ...
- Flink资料(4) -- 类型抽取和序列化
类型抽取和序列化 本文翻译自Type Extraction and Serialization Flink处理类型的方式比较特殊,包括它自己的类型描述,一般类型抽取和类型序列化框架.该文档描述这些概念 ...
- Flink资料(3)-- Flink一般架构和处理模型
Flink一般架构和处理模型 本文翻译自General Architecture and Process Model ----------------------------------------- ...
- Flink资料(2)-- 数据流容错机制
数据流容错机制 该文档翻译自Data Streaming Fault Tolerance,文档描述flink在流式数据流图上的容错机制. ------------------------------- ...
- Flink资料(6) -- 如何添加一个新的Operator
false false false false EN-US ZH-CN X-NONE /* Style Definitions */ table.MsoNormalTable {mso-style-n ...
- Flink学习笔记-新一代Flink计算引擎
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- Dijkstra 调度场算法 Python实现 一
调度场算法(Shunting Yard Algorithm)是一个用于将中缀表达式转换为后缀表达式的经典算法,由 Edsger Wybe Dijkstra 引入,因其操作类似于火车编组场而得名. — ...
随机推荐
- 在.NET中使用iTextSharp创建/读取PDF报告: Part I [翻译]
原文地址:Create/Read Advance PDF Report using iTextSharp in C# .NET: Part I By Debopam Pal, 27 Nov 20 ...
- Linux命令--链接文件的那些事
linux 链接ln的使用 linux操作系统下ln的使用方式: ln [option] source_file dest_file #source_file是待建立链接文件的文件,dest_file ...
- ASP.Net引用类库出现问题 二
一:引用mysql.data.dll出现,问题? error: Package MySql.Data (.NETCoreApp,Version=v1.). Package MySql.Data sup ...
- CentOS上编译安装Git
1. 安装(编译安装)软件 # 先安装git依赖的包 yum install zlib-devel yum install openssl-devel yum install perl yum ins ...
- mysqli扩展库的 预处理技术 mysqli stmt
问题的提出? 现在需要向mysql数据库添加100个用户,请问如何实现? 思路: 使用for循环100次,向数据库中添加100个用户. 使用批量添加 $sql1=”insert xxx”; $ssql ...
- PHP学习日记(一)——类、函数的使用
一.自定义函数 function add($a,$b){ $c=$a+$b; echo 'add test:'; echo $c; return $c; } add(1,2); 输出结果: add t ...
- jcSQL简明执行流程图
赶着"黑色七月"的最后一天发一篇记点东西,这个月一共掉了三架飞机,我一直很害怕坐着一架人造的东西飞在几万米的高空,相比自己长出一对翅膀,前者应该要脆弱很多.这些人每个人都因为不同的 ...
- eclipse android sdk javadoc
sdk 的函数不提示帮助信息 查了下是现在adt版本没有doc文件夹,拷贝了早期的版本docs过来 其他具体操作如下:http://blog.csdn.net/lyh7736362/article/d ...
- Oracle EBS-SQL (WIP-8):检查期间任务下达记录数.sql
select WE.DESCRIPTION 任 ...
- 解决svn: Cannot negotiate authentication mechanism错误问题
解决svn: Cannot negotiate authentication mechanism错误问题 作者:wangzz 原文地址:http://blog.csdn.net/wzzvictory/ ...