TextRank 自动文摘
前不久做了有关自动文摘的学习,采用方法是TextRank算法,整理和大家分享。
一. 关于自动文摘
利用计算机将大量的文本进行处理,产生简洁、精炼内容的过程就是文本摘要,人们可通过阅读摘要来把握文本主要内容,这不仅大大节省时间,更提高阅读效率。但人工摘要耗时又耗力,已不能满足日益增长的信息需求,因此借助计算机进行文本处理的自动文摘应运而生。近年来,自动文摘、信息检索、信息过滤、机器识别、等研究已成为了人们关注的热点。
自动文摘(Automatic Summarization)的方法主要有两种:Extraction和Abstraction。其中Extraction是抽取式自动文摘方法,通过提取文档中已存在的关键词,句子形成摘要;Abstraction是生成式自动文摘方法,通过建立抽象的语意表示,使用自然语言生成技术,形成摘要。由于生成式自动摘要方法需要复杂的自然语言理解和生成技术支持,应用领域受限。所以本人学习的也是抽取式的自动文摘方法。
目前主要方法有:
- 基于统计:统计词频,位置等信息,计算句子权值,再简选取权值高的句子作为文摘,特点:简单易用,但对词句的使用大多仅停留在表面信息。
- 基于图模型:构建拓扑结构图,对词句进行排序。例如,TextRank/LexRank
- 基于潜在语义:使用主题模型,挖掘词句隐藏信息。例如,采用LDA,HMM
- 基于整数规划:将文摘问题转为整数线性规划,求全局最优解。(~.~我也不懂)
二. TextRank算法
TextRank算法是一种用于文本的基于图的排序算法。其基本思想来源于谷歌的 PageRank算法, 通过把文本分割成若干组成单元(单词、句子)并建立图模型, 利用投票机制对文本中的重要成分进行排序, 仅利用单篇文档本身的信息即可实现关键词提取、文摘。和 LDA、HMM 等模型不同, TextRank不需要事先对多篇文档进行学习训练, 因其简洁有效而得到广泛应用。
TextRank 一般模型可以表示为一个有向有权图 G =(V, E), 由点集合 V和边集合 E 组成, E 是V ×V的子集。图中任两点 Vi , Vj 之间边的权重为 wji , 对于一个给定的点 Vi, In(Vi) 为 指 向 该 点 的 点 集 合 , Out(Vi) 为点 Vi 指向的点集合。点 Vi 的得分定义如下:
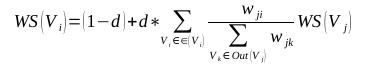 其中, d 为阻尼系数, 取值范围为 0 到 1, 代表从图中某一特定点指向其他任意点的概率, 一般取值为 0.85。使用TextRank 算法计算图中各点的得分时, 需要给图中的点指定任意的初值, 并递归计算直到收敛, 即图中任意一点的误差率小于给定的极限值时就可以达到收敛, 一般该极限值取 0.0001。
其中, d 为阻尼系数, 取值范围为 0 到 1, 代表从图中某一特定点指向其他任意点的概率, 一般取值为 0.85。使用TextRank 算法计算图中各点的得分时, 需要给图中的点指定任意的初值, 并递归计算直到收敛, 即图中任意一点的误差率小于给定的极限值时就可以达到收敛, 一般该极限值取 0.0001。
1. 基于TextRank的关键词提取
关键词抽取的任务就是从一段给定的文本中自动抽取出若干有意义的词语或词组。TextRank算法是利用局部词汇之间关系(共现窗口)对后续关键词进行排序,直接从文本本身抽取。其主要步骤如下:
(1)把给定的文本T按照完整句子进行分割,即
(2)对于每个句子 ,其中
,其中
(3)构建候选关键词图G = (V,E),其中V为节点集,由(2)生成的候选关键词组成,然后采用共现关系(co-occurrence)构造任两点之间的边,两个节点之间存在边仅当它们对应的词汇在长度为K的窗口中共现,K表示窗口大小,即最多共现K个单词。
(4)根据上面公式,迭代传播各节点的权重,直至收敛。
(5)对节点权重进行倒序排序,从而得到最重要的T个单词,作为候选关键词。
(6)由(5)得到最重要的T个单词,在原始文本中进行标记,若形成相邻词组,则组合成多词关键词。例如,文本中有句子“Matlab code for plotting ambiguity function”,如果“Matlab”和“code”均属于候选关键词,则组合成“Matlab code”加入关键词序列。
2. 基于TextRank的自动文摘
基于TextRank的自动文摘属于自动摘录,通过选取文本中重要度较高的句子形成文摘,其主要步骤如下:
(1)预处理:将输入的文本或文本集的内容分割成句子得
(2)句子相似度计算:构建图G中的边集E,基于句子间的内容覆盖率,给定两个句子

若两个句子之间的相似度大于给定的阈值,就认为这两个句子语义相关并将它们连接起来,即边的权值
(3)句子权重计算:根据公式,迭代传播权重计算各句子的得分;
(4)抽取文摘句:将(3)得到的句子得分进行倒序排序,抽取重要度最高的T个句子作为候选文摘句。
(5)形成文摘:根据字数或句子数要求,从候选文摘句中抽取句子组成文摘。
三. 其它
分析研究可知,相似度的计算方法好坏,决定了关键词和句子的重要度排序,如果在相似度计算问题上有更好的解决方案,那么结果也会更加有效。其它计算相似度的方法有:基于编辑距离,基于语义词典,余弦相似度等。这里不一一描述。
本人实现了一个简单的文摘系统,代码可参考ASExtractor,代码风格比较坑爹,注释也没写好,将就看看,请见谅。
由于知识不够完备,若有出错的地方,欢迎指导,谢谢!
参考资料
1. Automatic Summarization , TextRank , PageRank
2. someus github:TextRank4ZH
3. David Adamo: TextRank
4. 结巴分词
TextRank 自动文摘的更多相关文章
- Textrank算法介绍
先说一下自动文摘的方法.自动文摘(Automatic Summarization)的方法主要有两种:Extraction和Abstraction.其中Extraction是抽取式自动文摘方法,通过提取 ...
- 关键词抽取:pagerank,textrank
摘抄自微信公众号:AI学习与实践 TextRank,它利用图模型来提取文章中的关键词.由 Google 著名的网页排序算法 PageRank 改编而来的算法. PageRank PageRank 是一 ...
- 自动文档摘要评价方法:Edmundson,ROUGE
自动文档摘要评价方法大致分为两类: (1)内部评价方法(Intrinsic Methods):提供参考摘要,以参考摘要为基准评价系统摘要的质量.系统摘要与参考摘要越吻合, 质量越高. (2)外部评价方 ...
- 实现自动文本摘要(python,java)
参考资料:http://www.ruanyifeng.com/blog/2013/03/automatic_summarization.html http://joshbohde.com/blog/d ...
- 使用Python自动提取内容摘要
https://www.biaodianfu.com/automatic-text-summarizer.html 利用计算机将大量的文本进行处理,产生简洁.精炼内容的过程就是文本摘要,人们可通过阅读 ...
- 和textrank4ZH代码一模一样的算法详细解读
前不久做了有关自动文摘的学习,采用方法是TextRank算法,整理和大家分享. 一. 关于自动文摘 利用计算机将大量的文本进行处理,产生简洁.精炼内容的过程就是文本摘要,人们可通过阅读摘要来把握文本主 ...
- [IR] Extraction-based Text Summarization
文本自动摘要 - 阅读笔记 自动文摘要解决的问题描述很简单,就是用一些精炼的话来概括整篇文章的大意,用户通过阅读文摘就可以了解到原文要表达的意思. 问题包括两种解决思路, 一种是extractive, ...
- 自然语言处理(NLP)之个人小结
一 概述 1.1 自然语言处理四大任务 序列标注 分词 词性标注 命名实体识别 分类任务 文本分类 情感分析 判断句子关系 问答系统 对话系统 阅读理解 生成任务 机器翻译 自动文摘 图像描述生成 1 ...
- NLP之TF-IDF与BM25原理探究
前言 本文主要是对TF-IDF和BM25在公式推演.发展沿革方面的演述,全文思路.图片基本来源于此篇公众号推文<搜索中的权重度量利器: TF-IDF和BM25>,侵删. 一 术语 TF: ...
随机推荐
- Ganglia安装搭建
Ganglia的安装部署 前言 1 一.Ganglia组件 1 二.安装依赖 2 三.安装expat依赖 2 四.安装confuse 3 五.安装ganglia 4 六. 服务端配置(gmetad 节 ...
- ubuntu 下安装mysql,以及配置远程登录
安装MysQL 在Ubuntu14.04下安装MySQL比较简单,只需下面这条命令就行了: 1.输入 sudo apt-get install mysql-server 2.继续执行后,需要设定MyS ...
- mysql 自动备份导出到sql
创建一个sh文件 vi mysql_auto.sh写入如下代码 导出单个数据库 /www/wdlinux/mysql/bin/mysqldump -uroot -p123456 database &g ...
- 使用AjaxPro实现无刷新更新数据
需求 在一个页面动态无刷新的更新后台得到的数据.要想无刷新的更新数据,需要使用Javascript能够获取后台返回的数据,然后通过第三方Javascript库(JQuery等)动态更新web页面DOM ...
- OC内存管理
内存问题 野指针异常:访问所有权的内存,如果想要安全访问,必须确保空间还在(确保访问的内存不是僵尸对象) 内存泄露:空间使用完之后没有及时释放 过度释放:对一块空间释放多次,立刻crash 内存溢出: ...
- angular初步认识一
最近比较流行MVC前端框架开发,最近研究了一个框架AngularJS框架 不说那么多,先上例子,我是个代码控 <!DOCTYPE html> <html lang="en& ...
- java mysql 日期类型
mysql(版本:5.1.50)的时间日期类型如下: datetime 8bytes xxxx-xx-xx xx:xx:xx 1000-01-01 00:00:00到9999-12-31 23:59: ...
- SYS与SYSTEM、DBA与SYSDBA的区别
SYS与SYSTEM: 1. sys 的角色是sysdba system 的角色是sysoper 2. sys 具有create database的权限 system没有该权限 3. sys可以建数据 ...
- 012 VS2013常用快捷键
2016-01-28 1.回到上一个光标位置/前进到下一个光标位置 1)回到上一个光标位置:使用组合键“Ctrl + -”: 2)前进到下一个光标位置:“Ctrl + Shift + - ”. 2. ...
- 2.4G/5G频段WLAN的模式、带宽、协商速率
2.4G频段 5G频段